Linux 网络编程从入门到进阶 学习指南
前言
大家好,我是小康。在上一篇文章中,我们探讨了 Linux 系统编程的诸多基础构件,包括文件操作、进程管理和线程同步等,接下来,我们将视野扩展到网络世界。在这个新篇章里,我们要让应用跳出单机限制,学会在网络上跨机器交流信息。
接下来,我们要深入套接字(sockets)和 TCP/IP 协议,揭示如何在 Linux 下构建通信和网络服务。我们会从基础说起,逐步深入。目标是为初学者提供一个 Linux 网络编程从入门到进阶的学习指南!
网络通信基础
思考一下,如果计算机想要“交朋友”,它们需要怎样互相沟通?正如人们交流需要使用语言一样,计算机通信也必须遵守一套规则 — 这就是网络协议。
协议确保信息可以在不同的设备和平台之间清晰、准确地传递。要深入理解协议,我们首先要熟悉两个基础的通信模型:OSI 和 TCP/IP 模型。
OSI 模型和 TCP/IP 模型
在网络通信的世界里,OSI(开放式系统互联通信参考模型)和 TCP/IP(传输控制协议/网际协议)模型扮演着基础框架的角色。它们各自描述了网络通信的多个层次和阶段,但以不同的方式来分类和处理数据传输的细节。
OSI模型
OSI(Open Systems Interconnection)模型是一个概念性框架,用于描述网络中不同操作层次的功能。由七层组成,从物理硬件的电气信号(物理层),到应用层(如网页浏览器),每一层都有其独特的功能和协议。
TCP/IP模型
TCP/IP 模型,则更加贴近实际网络中的运作。Linux 的网络协议栈就是基于该模型实现的。它是基于四层架构,将网络通信过程简化并集中在协议族上,如传输控制协议(TCP)和互联网协议(IP),这两种协议是现代网络通信中最为核心的部分。
简单图示:

基本概念
地址簿:IP地址和MAC地址
想象一下,互联网是一个巨大的数字城市,而每台计算机或网络设备就像是住在这个城市里的居民。
IP地址:数字世界的“家庭住址”
每台设备的 IP 地址就像是它在这个数字城市里的家庭住址。当计算机需要发送信息或访问网络资源时,它会使用目的地设备的 IP 地址来确保信息正确地送达。这个地址有点像是我们现实世界中的邮寄地址,可以根据网络环境的变化而变化(例如,当设备从家庭网络移动到办公室网络时)。
MAC地址:网络中的“身份证”
然后,我们有 MAC 地址,这是网络设备的另一个关键标识。每台设备的 MAC 地址都是独一无二的,类似于每个人的身份证号码。它是在设备制造时就被分配的,并且在大多数情况下,这个地址是固定不变的。MAC 地址在本地网络(如家庭或办公室网络)内起着重要作用,它帮助确保信息被准确地送达到特定设备,就像邮递员需要知道收件人的详细身份信息才能将包裹准确递交。
总结一下:ip 地址可以让数据包找到目的主机所在的网络,而 MAC 地址确保数据包能准确送到目的主机上。
导航路线:子网掩码和网关
子网掩码:定位网络的“区域地图”
子网掩码可以被视为定位网络内部和外部地址的“区域地图”。就像在一个大城市中,你需要知道哪些街道属于你的社区,哪些通往城市的其他部分。子网掩码帮助计算机确定一个 IP 地址是属于本地网络(即同一个子网)还是位于外部网络。
- 内部导航:如果目的地IP地址与计算机所在的子网相匹配(根据子网掩码判断),则数据包在本地网络内传送。
- 外部导航:如果目的地不在本地子网内,计算机知道它需要将数据发送到更远的目的地。
网关:网络间的“中转站”
网关在网络通信中扮演中转站的角色。当你的数据包需要从一个网络(比如你的家庭网络)发送到另一个网络(比如你的工作地点的网络)时,网关是这个旅程的第一站。
- 路由决策:网关检查数据包的目的 IP 地址,然后使用它的路由表来决定最佳的路径将数据包发送到目标网络。
总结: 子网掩码和网关共同协作,帮助数据包在复杂的网络结构中找到最有效的路径。子网掩码确定数据包是否在本地网络内,而网关指导跨网络的数据传输。
端口 :确保数据到达正确的“应用程序门牌号”
好了,现在我们的数据包已经知道了去哪里,但它如何确保被正确的程序接收呢?这就是端口登场的时候了。端口号就像是收件人的门牌号,确保数据不只是送到了正确的地址,而且被正确的应用程序接收。
Linux 套接字编程
套接字是什么
在网络编程中,套接字就像是网络世界的通信端口。每一个联网的应用程序,为了能够互发消息,都会使用到这样一个端口。这个端口允许数据从一个程序流向另一个程序。简而言之,套接字是应用程序用来在网络上交流的桥梁。
想象一下,你要用手机给朋友发一条信息。你只需要知道他们的手机号码,这样信息就可以直接发送到他们的手机上。在网络编程中,套接字的作用类似。它使用IP地址 (类似于手机号码) 来确定数据发送的目标位置,而端口号则像是确定信息应该送达到对方手机中的哪个应用程序。这样,套接字(使用 ip 地址和端口)确保了数据能够准确地发送给正在监听那个特定端口的程序。
套接字的工作原理:
套接字的工作原理就像是电话通话的过程。首先,你需要拨打一个号码(即IP地址+端口号)来建立连接。一旦连接建立,电话线(网络连接)就激活了,你的声音(数据)就可以通过它传送。
在这个过程中:
拨号对应于网络编程中的连接建立,这是通过调用套接字API来完成的,比如 connect( )函数。
通话对应于数据传输,你可以通过套接字发送 send( ) 和接收 recv( )数据。
挂断对应于结束连接,完成通信后,你需要关闭套接字 close( )函数,以结束会话并清理资源。
在整个通信过程中,套接字保证了数据从一个程序准确地传送到另一个程序,无论这两个程序是在同一台计算机上还是跨越了广阔的互联网。
在 Linux 中,套接字其实就是一系列的编程接口,Linux 提供了很多特定的 API 来创建和使用套接字,接下来,让我们学习如何使用 Linux 套接字 api 来编写各种网络服务程序。
套接字类型
在 Linux 中,有三种套接字类型,前两种是重点掌握的,第三种了解即可。
TCP套接字 (SOCK_STREAM):
- 这是一种可靠的套接字连接,保证数据传输的完整性和顺序。
- 必须先建立连接,才能传输数据。
- 常用于需要准确数据传输的应用,如网页浏览和文件传输。
UDP套接字 (SOCK_DGRAM):
- 不需要建立连接,但是数据传输可能会丢失,没有先后顺序。
- 适用于视频流和在线游戏,这些应用可以容忍一定的数据丢失。
原始套接字 (SOCK_RAW):
- 允许直接对较低层次的协议如 IP 或 ICMP 进行访问和操作,它绕过了 TCP 和 UDP 的处理。
- 开发者可以使用原始套接字来构建自定义的协议或直接处理来自网络的数据包。
- 通常用于需要进行网络诊断或网络安全应用,如自定义的ping实现,或者网络嗅探器。
选择哪种类型取决于你的应用需求—是否需要可靠传输(TCP),还是速度更快但可能丢失数据也没关系(UDP)。
选择使用原始套接字通常意味着你需要对网络协议有深入的理解,因为你将直接与网络层面的数据交互。这比处理 TCP 和 UDP 套接字更复杂,通常只在特殊情况下使用,例如网络工具的开发或定制协议的实现。
套接字常用 API
接下来,看下常用的套接字 API:
socket() : 创建套接字
bind() : 绑定套接字到本地地址
listen() : 监听网络连接
accept() : 接受网络连接
connect() : 连接到远程主机
send(), recv() : 发送和接收数据(面向连接的套接字)
sendto(), recvfrom() : 发送和接收数据(无连接的套接字)
close() ,shutdown() : 关闭套接字
getsockopt(), setsockopt() : 获取和设置套接字选项
套接字地址结构以及地址转换 API
/*
sockaddr 是一个通用的套接字地址结构,它通常与特定的地址族结构(如 sockaddr_in )一起使用。
这是因为多数套接字函数,如 bind(), connect(), 和 accept(),需要使用指向 sockaddr 结构的指针的参数。
*/
struct sockaddr {
sa_family_t sa_family; /* Address family */
char sa_data[]; /* Socket address */
};
// 套接字地址结构(适用于IPv4网络通信的地址结构)
struct sockaddr_in
{
sa_family_t sin_family; # address family: AF_INET
in_port_t sin_port; # port in network byte order
struct in_addr sin_addr; # ip address
};
struct in_addr
{
uint32_t s_addr; # address in network byte order
};
/*
网络地址转换函数 (用于将IP地址在可打印的格式和二进制结构之间转换)
将点分十进制的IP地址(如"192.168.1.1")转换成网络字节顺序的二进制形式
inet_pton()
将网络字节顺序的二进制IP地址转换为点分十进制字符串格式
inet_ntop()
*/
# demo 示例:
#define INET_ADDRSTRLEN 16;
char str[INET_ADDRSTRLEN];
struct in_addr ipv4addr;
inet_pton(AF_INET, "192.168.1.1", &ipv4addr);
inet_ntop(AF_INET, &ipv4addr, str, INET_ADDRSTRLEN);
printf("The IPv4 address is: %s\n", str);
字节序转换 API
在网络编程中,字节序(也称为端序)指的是数值在内存中保存的顺序。不同的计算机体系结构可能会采用不同的字节序来表示数据。最常见的两种字节序是大端字节序(Big-Endian)和小端字节序(Little-Endian)。在网络通信中,为了确保数据在不同的系统间正确传输和解释,定义了一个统一的字节序,即:网络字节序,它采用大端字节序。
由于主机字节序与网络字节序可能不同,因此在发送数据前,发送方需要将其主机字节序的数值转换为网络字节序;接收方收到数据后,需要将网络字节序的数值转换回主机字节序。
Linux 提供了一组 API 来处理字节序的转换:
// 将无符号长整型数/无符号短整型数从主机字节顺序转换为网络字节顺序。
htonl() 和 htons()
// 将一个无符号长整型数/无符号短整型数从网络字节顺序转换为主机字节顺序。
ntohl() 和 ntohs()
/*
为了方便记忆,大家可以这样理解:h 代表 host(主机),n 代表 network(网络),
l 代表 long(四字节:代表ip),s 代表 short(两字节:代表端口) 。
以 htons() 举例,host to network short 即:将端口从主机字节序转成网络字节序。
*/
注意:htonl 和 ntohl 一般处理的是 IP 地址,而 htons 和 ntohs 一般处理的是端口。
Linux 常见的 IO 模型
前面我们已经学习了 Linux 基础的 socket API,这样我们便可以编写简单的网络服务程序。但现在,我们面临一个新挑战:如何利用有限的服务器资源,来同时高效处理大量的并发请求呢?
传统的单线程处理方式在现代网络服务中已不合时宜,因为它无法同时处理多个请求,导致效率低下。为了突破这一限制,我们需探究 Linux 提供的各种 I/O 模型。这些模型提供了从阻塞到非阻塞,从多路复用到完全异步的不同解决方案,以适应各种网络应用场景,确保服务器在面对大量请求时也能保持高效运行。
在讨论这些 IO 模型之前,我们先简单回顾一下 I/O 是什么:
在计算机中,“I/O”就是输入和输出的简称,它描述了数据在计算机系统和外部世界之间的流动。具体来说:
输入:数据进入计算机,比如你在键盘上敲击字母时,字母被读入计算机。
输出:数据离开计算机,例如屏幕上显示信息。
当提到网络时,“I/O”扩展了含义:
网络输入:从外部网络接收数据到你的本地计算机,如通过网络下载文件到你的计算机。
网络输出:这是指将数据从你的本地计算机发送到外部网络,比如通过计算机发送文件给你的好友。
简而言之,I/O 是数据在计算机和其他设备或网络之间传递的方式。
用户进程如何进行 IO 操作?
让我们通过一个示意图来直观展示用户进程如何从网络获取数据并将其存储到磁盘的整个过程:
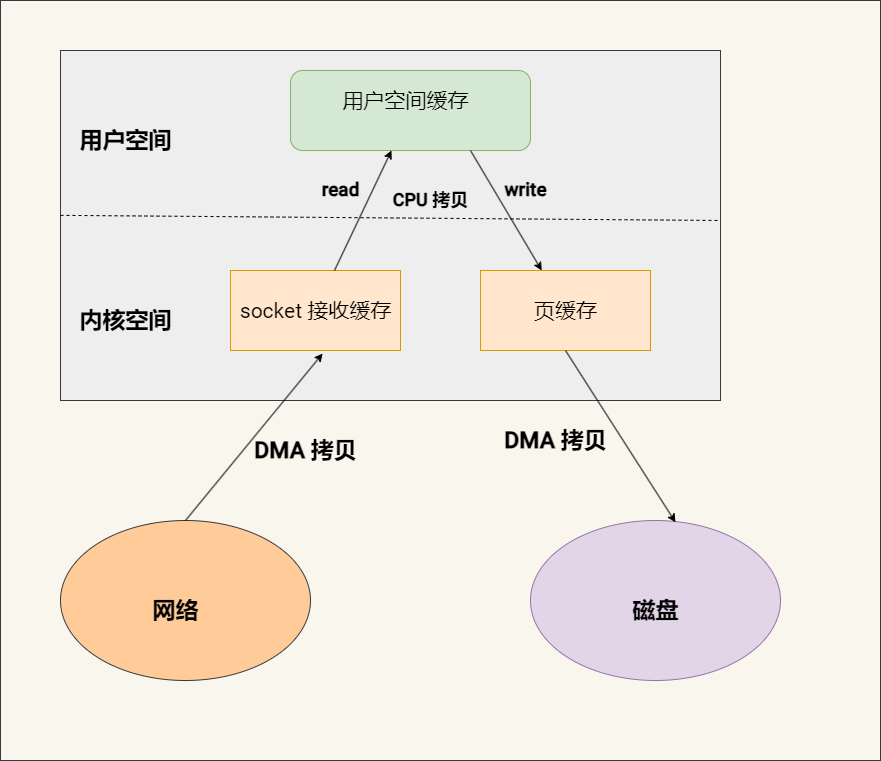
从上图我们也能够清楚的看到,进程进行一次 I/O 操作需要经过两个步骤:
以 read 读操作为例:
第一步:等待网络数据的到来
当网络数据到达时,网络接口卡(NIC)首先通过直接内存访问(DMA)将数据传输到内核空间分配的 socket 接收缓冲区中,无需 CPU 参与。
第二步:CPU 复制数据至用户空间
一旦数据通过 DMA 传输到内核的 socket 接收缓冲区,用户进程的 read 系统调用会被唤醒(如果它在等待数据的话)。接下来,CPU 会介入,将数据从内核缓冲区复制到用户空间提供的缓冲区中。
也就是说,在 I/O 操作的过程中,存在两个潜在的等待时间点 :一个是等待网络数据到达 socket 接收缓冲区,另一个是等待 CPU 复制数据至用户空间。
为了减少这些等待时间对应用程序性能的影响,Linux 提供了五种 I/O 模型,它们分别针对这两个步骤的效率问题提供不同的解决方案。
接下来,我们将深入了解 Linux 支持的五种 I/O 模型:
阻塞IO(Blocking I/O)
简单图示:
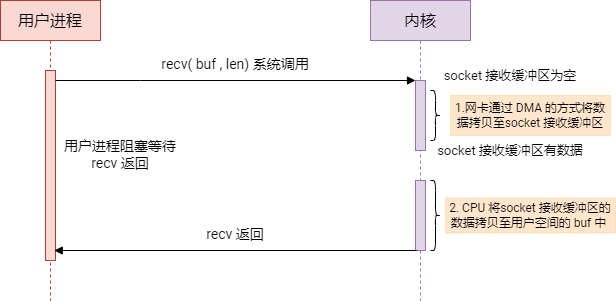
在阻塞 I/O 中,进程在等待网络数据到达和内核复制数据到用户空间这两个步骤中都需要等待。当一个进程发起 I/O 请求时,它会一直等待直到数据被复制到它的应用层缓冲区中,然后才继续执行。
非阻塞I/O(Non-blocking I/O)
简单图示:

在非阻塞 I/O 模型中,当进程尝试从 socket 读取数据时,如果数据尚未到达,read调用不会阻塞进程。相反,它会立即返回一个 EWOULDBLOCK 或 EAGAIN 错误。也就是说,进程不需要等待网络数据到达 socket 接收缓冲区就可以返回继续执行其他任务。
一旦数据到达并存储在内核缓冲区中,而当进程尝试再次读取,这次 read 操作将成功,并将数据从内核空间复制到用户空间,但这里的数据复制过程是需要等待的。
总结一下:在非阻塞 I/O 模型中,进程需要等待 socket 数据从内核空间复制到用户空间。 而在等待网络数据到达 socket 接收缓冲区这个时间点是不需要等待的。但是进程需要不断地“轮询”文件描述符,检查 socket 接收缓冲区是否有数据,频繁的轮询可能会导致 CPU 资源的浪费。
I/O多路复用(I/O Multiplexing)
简单图示:
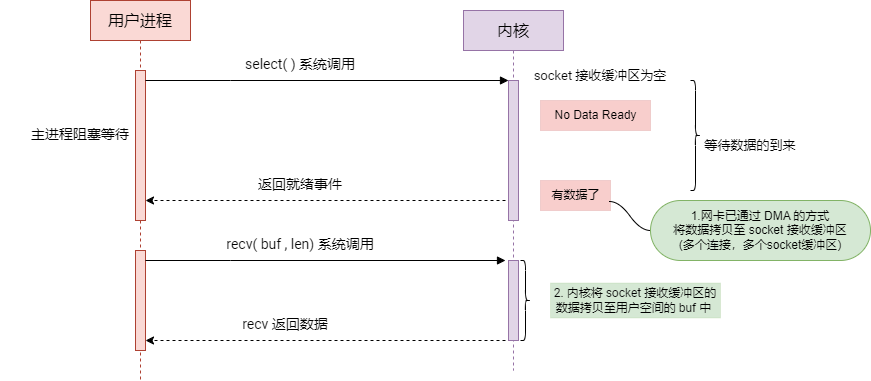
工作原理:
I/O 多路复用允许一个进程或线程同时监控多个网络 sockets 的状态。它通过单个系统调用(select)来检查多个 sockets 是否有数据可读、可写或是否有异常。Linux 提供了多种 I/O 复用技术,包括上面提到的 select、以及 poll、epoll。
那 I/O 多路复用是如何减少上述提到的两个潜在的等待时间的?
等待网络数据到达
在 I/O 多路复用模式下,进程不会在单个 socket 上阻塞等待数据到达。相反,当任何一个被监控的 socket 接收到数据,系统调用(如select)会返回。当 select 返回时,它指示一个或多个 sockets 已接收到数据。这意味着数据已经被网络接口卡(NIC)通过 DMA 操作传输到相应的 socket 接收缓冲区中。
这样,进程不必在每个 socket 上分别等待,而是在多个sockets上集中等待,提高了效率。
但是,在 I/O 多路复用中, select、poll 或 epoll 系统调用依然会阻塞等待网络数据的到达
等待CPU复制数据至用户空间
进程随后可以立即对准备就绪的 socket fd 进行 read 操作。因为数据已经在内核的缓冲区中,CPU 只需要将数据从内核空间复制到用户空间。但这个拷贝数据的完成
也就是说在 I/O 多路复用中,select、poll 或 epoll 系统调用依然会阻塞等待网络数据的到达,但是他的优势在于可以监控多个 sockets 的接收缓冲区是否有数据到来。当多个 sockets 的接收缓冲区有数据到来,进程会一直等待 CPU 复制数据至用户空间才能干其他任务。
信号驱动I/O(Signal-driven I/O)
简单图示:
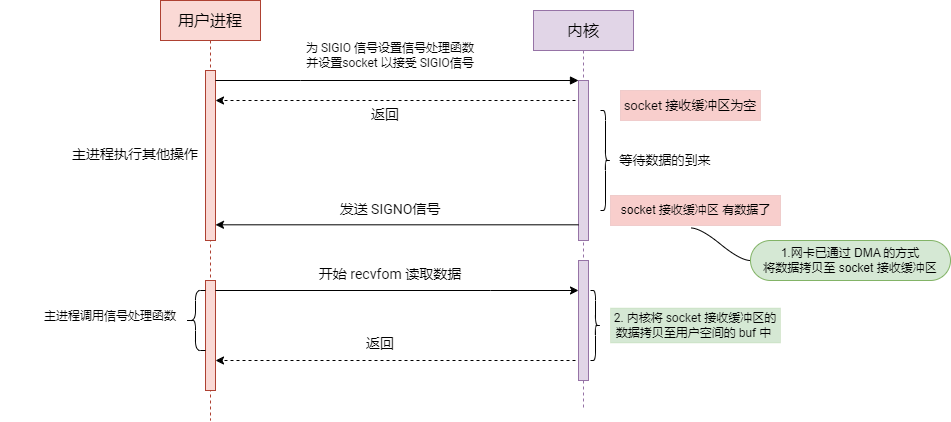
信号驱动 I/O 也是属于Linux 中的一种 IO 模型,它允许应用程序在不阻塞等待 I/O 操作完成的情况下继续执行其他任务。当 I/O 操作(如数据的读取或写入)准备就绪时,操作系统会向应用程序发送一个信号,通知它可以开始执行 I/O 操作了。这种模式主要通过使用信号(如 SIGIO)来实现。
两个等待时间点对信号驱动 I/O 的影响 :
等待网络数据到达:在信号驱动 I/O 模型中,应用程序在等待数据到达时不需要阻塞等待。它可以继续执行其他任务或处于休眠状态,直到操作系统发出数据已准备就绪的信号(如 SIGIO)。
等待内核复制数据到用户空间:当应用程序收到信号并开始实际的 I/O 操作(如 read)时,它仍然需要等待操作系统将数据从内核空间复制到用户空间。
尽管信号驱动 I/O 提供了一种异步通知机制,使得应用程序能够在I/O事件准备好时接收通知,但它在实践中不如其他模型(如IO复用)那么广泛使用,原因包括:
编程复杂性:使用信号驱动I/O要求程序员熟悉信号处理和非阻塞I/O操作,这增加了编程的复杂性。
信号合并和丢失
Linux 信号处理机制通常不会为同一类型的信号排队。这意味着如果在处理一个信号时另一个相同类型的信号发生,后者可能不会触发额外的信号处理调用,导致应用程序可能错过一些I/O事件的通知。这种信号的合并行为限制了信号驱动I/O模型在高并发场景下准确响应每个I/O事件的能力。更好的替代方案:对于需要处理多个并发I/O操作的应用程序,I/O复用(特别是epoll)提供了更高的效率和更好的控制。epoll特别适用于高并发场景,并且相对于信号驱动I/O更易于管理和使用。
异步I/O(Asynchronous I/O)
简单图示:
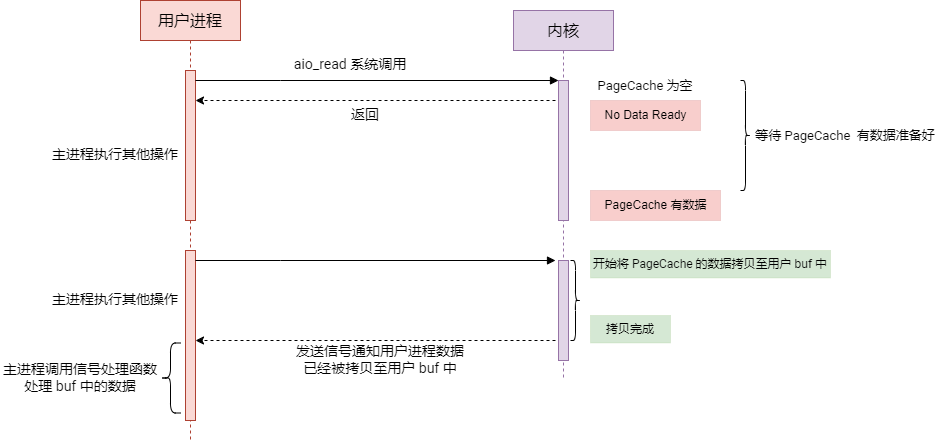
aio_read 是 POSIX 异步 I/O 接口的一部分,它专门用于执行异步文件读取操作。不太适用于网络 I/O 。因此上面的图示是基于文件读取对异步 IO 的工作过程进行说明的。
工作原理:
在异步 I/O 模型中,当应用程序发起一个I/O操作(例如 aio_read 读取)时,它不需要等待操作完成就可以继续执行其他任务。应用程序仅仅是向操作系统发出 I/O 请求,并且当 I/O 操作真正完成时,操作系统会通知应用程序。这种方式允许应用程序更有效地利用 CPU 时间,因为它不需要在 I/O 操作完成前空闲等待。
那前面提到的两个潜在等待时间对异步 IO 是否会有影响呢?
等待内核 PageCache 数据准备好:
在异步 I/O 中,应用程序在发出读写请求后立即返回,不需要等待数据在内核中准备好。这意味着应用程序可以继续执行其他任务,而内核会异步的从磁盘读取数据至内核缓存 PageCache 中。
注意: 上面我是通过 aio_read 系统调用来说明异步 I/O 的工作原理的,aio_read 是 Linux 的 POSIX 异步 I/O (AIO) 库提供的接口,主要设计用于文件和块设备的异步读写操作,而不支持网络 I/O。因此这里是等待内核的 PageCache 数据准备好而不是等待网络数据准备好,但都可以归纳为等待数据准备好。
等待CPU复制数据至用户空间:
一旦数据在 pagecache 中准备好,操作系统负责将这些数据从内核空间复制到用户空间指定的缓冲区。这个复制过程是由内核自动执行的,而不是由用户进程主动复制的。 用户程序不需要等待这一过程的完成,可以继续进行其他工作。只有在数据完全复制到用户空间后,应用程序才会收到一个完成的信号或通知。进而处理拷贝至用户空间的数据。
也就是说:在异步 IO 中,不管是等待数据准备好还是等待 CPU 复制数据至用户空间,用户进程都不需要等待。
Linux 网络 I/O 性能优化
在前面的部分,我们探讨了 Linux的 各种I/O模型。每种模型都有其独特的使用场景和性能特点。特别是在网络编程中,选择合适的I/O模型对于提高服务器的处理能力至关重要。但是,仅仅选择合适的I/O模型并不足以确保最佳性能。实际上,网络I/O性能还受到许多其他因素的影响,比如网卡配置、带宽、服务器的并发处理能力等。因此,我们需要进一步优化 Linux 网络 I/O 性能,以确保我们的应用可以充分利用服务器资源,提供更快、更可靠的服务。
那么,如何优化 Linux 网络 I/O 性能呢?
网络 I/O 性能优化主要就是从硬件和软件两个方面来进行:
首先来看下硬件优化:
硬件优化无非就是提升服务器硬件性能,包括 CPU、网卡配置升级、内存配置升级等。
- 使用多核 CPU :确保服务器有足够的CPU核心来处理高网络负载。
- 内存升级:增加足够的内存以支持高速网络操作,特别是对于需要大量内存缓存的应用。
- 网络接口卡:升级NIC:使用更高速率的NIC,例如从1Gbps升级到10Gbps或更高。
或者使用 NIC 多队列(Multi-queue):使用支持多队列的NIC,以便分散处理负载到多个CPU核心。
接下来来看下软件优化:
1.首先来看下应用程序设计,应用程序本身的设计对网络 I/O 性能有着重大影响:
选择合适的 I/O 模型:
选择合适的 I/O 模型,根据应用的特点和需求选择合适的 I/O 模型。对于高并发的网络服务,I/O 多路复用(如 epoll、kqueue)通常是最佳选择。它们允许单个线程高效地监控和处理多个网络连接,减少了线程切换的开销。而对于 I/O 密集型的应用,异步 I/O模型可能会更高效,异步 I/O (如 io_uring、libaio)提供了一种不阻塞应用程序主逻辑的方式来处理 I/O 请求。这种模型允许应用程序在 I/O 请求正在处理时继续执行其他任务。使用零拷贝技术:
传统的数据传输过程涉及多次数据拷贝,包括从内核缓冲区到用户缓冲区。零拷贝技术(如 sendfile)可以减少这些拷贝操作,直接在内核中处理数据,从而减少 CPU 使用和提高效率。批量处理和缓冲 : 聚集数据,以减少网络交互和磁盘操作的次数。
a:聚集数据:通过累积数据到达一定量后再进行处理,而不是每次接收到数据就立即处理。以读取网络数据下载至本地磁盘为例:可以等待数据积累到一定量的时候在写入磁盘,这样可以减少磁盘 I/O 次数。
b.缓冲区管理:需要合理管理缓冲区,以避免溢出,并在适当的时候重置或清空缓冲区。
c.适用场景:这种模式适合于数据量大、数据频繁到达的场景,如日志收集、批量数据处理等。
并发和并行处理:利用多核处理器的优势,通过多线程或多进程来提高并发处理能力。
2. 接下来看下关于操作系统方面的调整,操作系统级别的调整对于优化网络 I/O 也是至关重要的
增加文件描述符限制:对于高并发的网络服务器,提高文件描述符的限制是必要的,以避免因达到文件描述符上限而无法接受新连接。你可以通过 ulimit -n 命令或修改 /etc/security/limits.conf 文件来增加这个限制。
调整 TCP 协议栈参数:常见的 TCP协议栈参数有如下的几类:
a:缓冲区大小和资源管理:
这些参数控制 TCP 缓冲区的大小和整体 TCP 缓冲区的资源管理,以优化数据传输性能和内存使用。tcp_rmem 和 tcp_wmem :分别控制 TCP 接收和发送缓冲区的大小。
tcp_mem :控制整体 TCP 缓冲区在系统范围内的使用情况。
b: 连接建立和终止:
这类参数涉及 TCP 连接的建立过程和连接终止时的行为。tcp_syn_retries 和 tcp_synack_retries : 分别控制 TCP SYN 连接请求和 SYN-ACK 包的重试次数。
tcp_fin_timeout : tcp_fin_timeout 参数设置了 TCP 连接在 FIN-WAIT-2 状态下的超时时间。这个参数定义了在一个 TCP 连接被本地端关闭后,系统等待对方发送 FIN 包以完成连接终止过程的最长时间。如果在这个超时时间内没有收到对方的 FIN 包,连接将被强制关闭。
c :连接保活和状态管理:
这些参数用于检测和维持空闲连接,以及管理连接状态。tcp_keepalive_time :设置在开始发送 keepalive 探测之前,一个 TCP 连接必须处于空闲状态的时间。
tcp_keepalive_probes :设置在断开连接之前,最多发送多少个 keepalive 探测包。
tcp_keepalive_intvl : 设置两个连续 keepalive 探测包之间的时间间隔。
tcp_tw_reuse : 设置允许在 TIME_WAIT 状态的套接字上的端口被重新用于新的连接。
d:性能优化 : 这些参数用于提升网络性能,减少延迟。
tcp_nodelay : 禁用 Nagle 算法,减少发送小块数据的延迟。(Nagle 算法是一种为了减少网络上小数据包数量而设计的 TCP 特性。它通过累积较小的数据包并将它们组合成更大的数据块来发送,从而减少了网络上的总数据包数量)。
tcp_max_syn_backlog : 设置 SYN 接收队列的最大长度,优化高并发连接的接收。
除了 SYN 接收队列,TCP 连接还涉及到一个“已连接队列”(也称为 accept 队列),该队列用于存储已经完成三次握手、等待应用程序 accept 的连接。
/proc/sys/net/core/somaxconn: 该参数控制着已连接队列的最大长度。
调整方法:
这些参数通常通过修改 /etc/sysctl.conf 文件或使用 sysctl 命令进行调整。例如:sysctl -w net.ipv4.tcp_rmem='4096 87380 6291456'
sysctl -w net.ipv4.tcp_wmem='4096 16384 4194304'
注意: 调整这些参数时,应谨慎考虑系统的整体资源和应用的具体需求。不恰当的设置可能导致性能下降或系统资源耗尽。在生产环境中应用更改前,最好在测试环境中进行充分的测试。
Linux 常见的服务器模型
服务器模型是网络服务器程序设计的基石,它决定了服务器如何管理多个客户端的连接和请求。接下来,让我们来看看 Linux 下的几种常见的服务器模型是怎样工作的?
单进程服务器:一对一服务
在单进程服务器模型中。服务器使用一个主进程来逐个处理客户端的连接请求。这意味着,当服务器正在服务一个客户端时,其他客户端必须等待直到当前客户端服务结束。
图示:
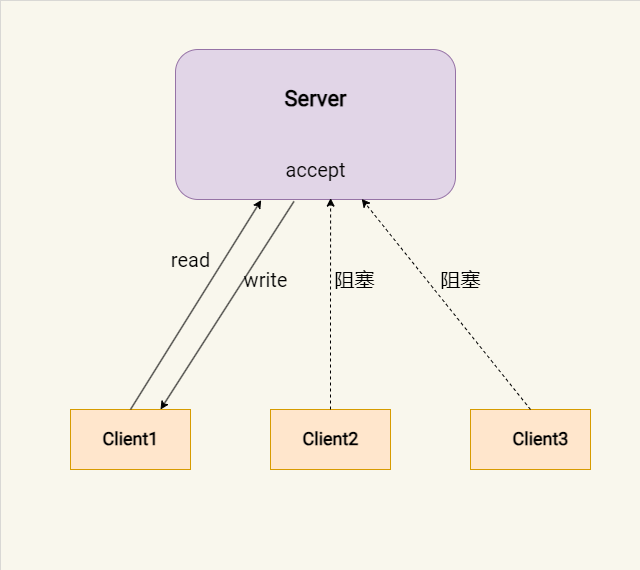
单进程回射服务器示例:
server_fd = socket();
bind();
listen();
// The main server loop
while (1) {
newsockfd = accept(server_fd,...);
memset(buffer, 0, 256);
// Read and write to the connection in a loop
while (1) {
n = read(newsockfd, buffer, 255);
if (n == 0) break; // If read returns 0, the client has closed the connection
// printf("Client: %s\n", buffer);
write(newsockfd, buffer, strlen(buffer));
}
close(newsockfd);
}
缺点:
无法实现并发: 单进程服务器在任何时刻只能处理一个客户端的请求。这意味着如果有多个客户端同时请求服务,除了第一个之外的所有请求都必须等待,这限制了服务器的并发处理能力。
性能瓶颈: 由于服务器在处理当前请求时无法接受新的连接,这会导致服务器对其他客户端的响应时间延长,特别是在高流量的情况下,效率低下。
资源利用不充分: 在多核心处理器上,单进程模型无法充分利用多核的优势,因为它只在一个核心上运行,没有并行处理能力。
多进程服务器
了解了单进程服务器模型的缺点后,我们自然会寻求更高效的方案来处理多客户端并发的情况。这就引出了多进程服务器模型,它是解决单进程模型限制的常见方案。
在多进程模型中,服务器为每个新的客户端连接创建一个独立的进程。这允许服务器同时处理多个客户端请求,极大地提高了并发处理能力和资源利用率。
图示:
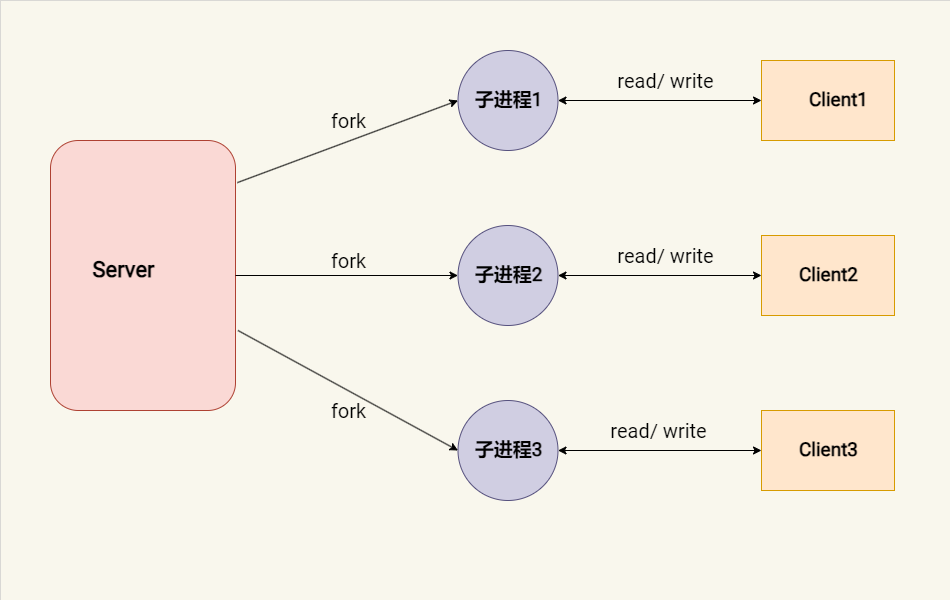
多进程回射服务器示例:
server_fd = socket();
bind();
listen();
while(1) {
int new_socket =accept(server_fd, ...);
int pid = fork();
if(pid < 0) {
close(new_socket);
} else if(pid == 0) {
close(server_fd); // Child does not need the listener
handle_client(new_socket);
} else {
close(new_socket); // Parent does not need this socket
}
}
void handle_client(int new_socket) {
char buffer[1024];
int bytes_read;
while(1) {
bytes_read = read(new_socket, buffer, sizeof(buffer));
if (bytes_read <= 0) {
break; // Break the loop if read error or end of file
}
write(new_socket, buffer, bytes_read);
}
close(new_socket);
exit(0);
}
多进程服务器优点:
稳定性: 多进程服务器中,每个进程是独立的。如果一个进程崩溃,通常不会影响到其他进程,从而提高了服务器的整体稳定性。
隔离性: 每个进程有自己的地址空间,这意味着进程之间的内存是隔离的。这样可以防止某个进程的错误操作影响到其他进程。
利用多核优势: 多进程模型能够在多核处理器上运行,每个进程可以被操作系统调度到不同的CPU核心上,充分利用硬件资源。
缺点:
资源消耗: 每个进程都需要一定量的内存和系统资源,如果进程数过多,会占用大量的系统资源,这可能导致服务器的性能下降。
上下文切换开销: 多进程意味着操作系统需要频繁地在进程之间进行上下文切换,这个过程涉及到保存和加载寄存器、更新各种表等操作,会消耗一定的CPU时间。
多线程服务器
虽然多进程模型提高了服务器的稳定性和隔离性,但它也带来了资源消耗、上下文切换开销等限制。针对多进程模型的这些限制,多线程服务器模型提供了一个更为高效的解决方案。
多线程服务器模型在同一个进程内创建多个线程来处理客户端请求,每个线程能够独立执行,它们共享进程的资源,如内存空间等资源。而且上下文切换也更快。
图示:
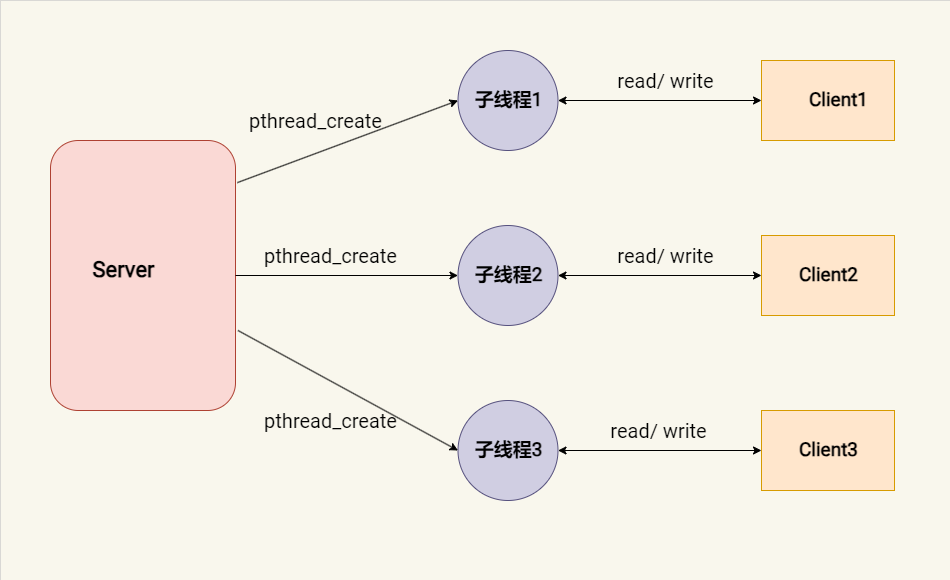
多线程回射服务器的示例:
server_fd = socket();
bind(server_fd, ...);
listen(server_fd, ...);
while (1) {
int new_socket = accept(server_fd, ...);
pthread_t thread_id;
if (pthread_create(&thread_id, NULL, handle_client, (void*)&new_socket) != 0) {
// Handle error
}
}
void* handle_client(void* socket) {
int new_socket = *(int*)socket;
char buffer[1024];
int bytes_read;
while (1) {
bytes_read = read(new_socket, buffer, sizeof(buffer));
if (bytes_read <= 0) {
break; // Break the loop if read error or end of file
}
write(new_socket, buffer, bytes_read);
}
close(new_socket);
pthread_exit(NULL);
}
多线程服务器优缺点:
- 资源效率: 线程共享进程的内存空间,相较于多进程模型,多线程服务器在内存和资源上的开销更小。
- 上下文切换效率: 线程间的上下文切换比进程间的切换要快,因为线程共享许多资源,切换时所需的资源较少(线程切换一般只需要切换各自寄存器和栈上的数据)。
- 利用多核优势: 线程可以分布在多个 CPU 核心上运行,这使得多线程服务器能够充分利用多核 CPU 的计算能力。
缺点:
- 同步复杂性: 因为线程共享内存和资源,所以必须仔细设计同步机制来避免竞态条件和其他并发问题。
- 稳定性风险: 一个线程的错误可能影响整个进程,因为它们共享同一内存空间。这可能导致整个服务器程序崩溃。
- 资源限制: 虽然线程比进程轻量,但大量线程仍然会消耗大量系统资源,尤其是在高并发情况下。
- 调试困难: 多线程程序的调试较为复杂,尤其是当出现了线程安全问题时,这些问题可能难以重现和定位。
线程池模型
在多线程服务器模型中,每个客户端请求都由一个新的线程来处理。这种方法虽然有效,但在面对大量并发请求时,频繁地创建和销毁线程会导致服务器的性能下降。 特别是在请求数量剧增的情况下,线程创建和销毁的开销会变得显著,同时过多的活跃线程也会竞争有限的CPU和内存资源,进一步影响服务的响应时间和吞吐量。
而在线程池模型中,服务器启动时会预先创建一定数量的线程,这些线程存放在池中,并不立即执行任务。当客户端请求到达时,请求会被分配给线程池中的一个空闲线程,该线程负责处理整个请求过程。处理完毕后,线程并不销毁,而是返回到池中等待处理下一个请求。
图示:
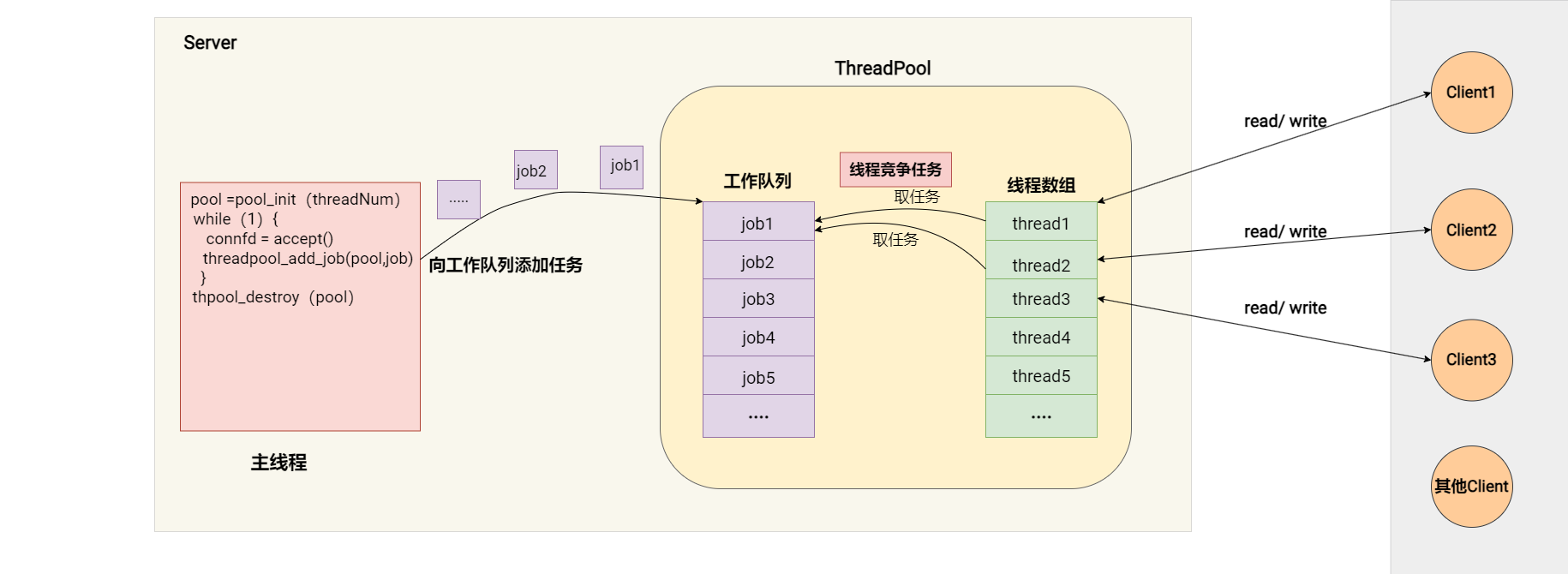
说明:
服务器(Server):这是整个流程开始的地方。服务器初始化一个线程池,并不断监听客户端的连接请求。当一个客户端连接请求到来时,服务器接受这个连接(accept()),然后把相应的任务(job:一般是读写客户端数据的逻辑)添加到线程池的任务队列中去。最终,当服务器不再需要线程池时,会销毁它。
线程池(ThreadPool):线程池是预先创建的线程集合,用于执行多个任务。它分为两个主要部分:
- 任务队列(Job Queue):这里存放所有待处理的任务(jobs)。当服务器接受一个客户端的连接,它会创建一个任务,并将其添加到这个队列中。
- 线程队列(Thread Queue):这里存放的是线程池中所有可用的线程。当任务队列中有任务时,线程池会分配一个线程去执行这个任务。
客户端(Clients):客户端通过网络连接与服务器进行通信。
I/O多路复用服务器
什么是 I/O 多路复用?
在 Linux 中,I/O 多路复用是一种允许单个进程或线程同时监控多个文件描述符(通常是网络套接字)上的读写就绪状态的技术。这使得程序能够在一个或多个文件描述符上发生 I/O 事件时被通知,从而对这些事件作出响应(比如进行读写操作)。这种机制极大地提高了处理多个并发网络连接的效率,因为它允许使用较少的系统资源(如进程和线程)来管理大量的连接。
上面我们在讲解 I/O 模型的时候,提到了 IO 多路复用,而在讲解服务器模型我们又再次提到了IO 多路复用。可能大家会有疑问:IO 多路复用到底属于 I/O 模型还是服务器模型?
其实 I/O 多路复用技术是两者之间的桥梁:它是一种有效的 I/O 处理方式,同时也是构建服务器模型的基础。
- I/O 多路复用作为 I/O 模型,关注的是如何有效地管理和执行 I/O 操作,特别是在涉及多个 I/O 源(如网络套接字)时。
- I/O 多路复用作为服务器模型,则是在这种 I/O 操作的管理方式基础上构建整个服务器的架构,决定如何接收和处理多个客户端请求,如何分配处理程序来响应这些请求,以及如何利用系统资源。
简单来说,I/O 模型是关于"如何执行 I/O"的,而服务器模型是基于某种 I/O 模型来构建服务的,以及如何组织服务器程序以响应客户端请求。
常见的 I/O 多路复用技术:
Linux 提供了多种 I/O 多路复用的机制,如 select, poll, 和 epoll。这些技术的主要区别在于它们处理大量文件描述符的方式和效率。
IO 复用之 Select:
基本概念:
Linux 中的 select 函数是一种常用的 I/O 复用技术。它允许程序监视多个文件描述符(FDs),以检测是否有任何一个或多个 FD 准备好进行读取、写入或是否有异常发生。这种技术特别适用于同时处理多个网络连接或其他类型的 I/O 操作(如:文件I/O)。
函数声明
select 函数的基本声明如下:
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
/*
参数结构
nfds:监视的文件描述符集合中最大的文件描述符加一。
readfds:一个指向 fd_set 结构的指针,用于监视哪些 FD 准备好进行读操作。
writefds:一个指向 fd_set 结构的指针,用于监视哪些 FD 准备好进行写操作。
exceptfds:一个指向 fd_set 结构的指针,用于监视哪些 FD 有异常发生。
timeout:指定 select 等待准备就绪的 FD 的最长时间。
*/
fd_set 结构图解展示:
fd_set 是一个文件描述符数组,用于指示 select 函数应该监视的 FDs。
fd_set 结构图解展示:
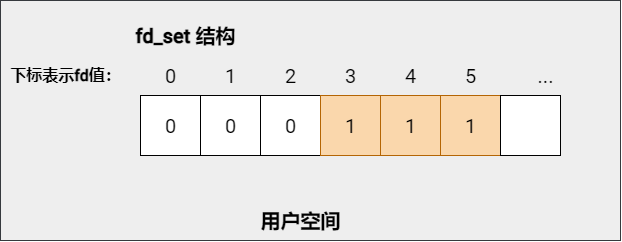
说明:
参数 readfds、writefds、exceptfds 从用户空间传入内核空间和从内核空间返回用户空间,文件描述符数组中的值代表的含义不同:
以可读事件 readfds 为例:
从用户空间传入内核空间:数组值为 0 代表不监控该文件描述符(fd),数组值为 1 代表要监控该文件描述符(fd)。
从内核空间返回用户空间:数组值为 0 代表该文件描述符数据未准备就绪,数组值为 1 代表该文件描述符数据准备就绪。用户进程可以进行读操作了。
select 并发回射服务器程序示例:
#define PORT 8080
#define MAX_CLIENTS 30
int main() {
int server_fd, new_socket, client_socket[MAX_CLIENTS];
struct sockaddr_in address;
int addrlen = sizeof(address);
fd_set readfds;
int max_sd, sd, activity, i, valread;
char buffer[1025]; // 数据缓冲区
// 初始化所有客户端套接字
for (i = 0; i < MAX_CLIENTS; i++) {
client_socket[i] = 0;
}
// 创建套接字
server_fd = socket(AF_INET, SOCK_STREAM, 0)
// 绑定套接字
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(PORT);
bind(server_fd, (struct sockaddr *)&address, sizeof(address))<0
// 监听套接字
listen(server_fd, 3)
while (1) {
FD_ZERO(&readfds);// 清空 fd_set
FD_SET(server_fd, &readfds); // 添加 server_fd 到 fd_set
max_sd = server_fd;
// 添加客户端套接字到 fd_set
for (i = 0; i < MAX_CLIENTS; i++) {
sd = client_socket[i];
if (sd > 0) {
FD_SET(sd, &readfds);
}
if (sd > max_sd) {
max_sd = sd;
}
}
// 使用 select 监听套接字
activity = select(max_sd + 1, &readfds, NULL, NULL, NULL);
// 接受新连接
if (FD_ISSET(server_fd, &readfds)) {
if ((new_socket = accept(server_fd, (struct sockaddr *)&address, (socklen_t*)&addrlen))<0) {
// 错误处理并退出
}
// 将新套接字添加到数组
for (i = 0; i < MAX_CLIENTS; i++) {
if (client_socket[i] == 0) {
client_socket[i] = new_socket;
break;
}
}
}
// 其他套接字的数据处理
for (i = 0; i < MAX_CLIENTS; i++) {
sd = client_socket[i];
if (FD_ISSET(sd, &readfds)) {
// 检查是否是断开连接,否则接收数据
if ((valread = read(sd, buffer, 1024)) == 0) {
close(sd);
client_socket[i] = 0;
} else {
buffer[valread] = '\0';
// 将接收到的数据发送回客户端
send(sd, buffer, strlen(buffer), 0);
}
}
}
return 0;
}
select优缺点:
优点:
能够同时监视多个套接字: select 允许服务器以单线程的方式监视多个套接字,来检测它们是否有可读、可写或异常条件发生。
无需多线程或多进程:select 采用单线程的处理方式,使用 select 可以避免复杂的多线程或多进程管理,减少了上下文切换的开销,简化了并发处理。
适用于小到中等规模的负载:对于不是很高的并发连接数(几百的连接数),select 通常可以满足需求,且效率不错。
缺点:
文件描述符限制:select 可以监视的文件描述符数量是有限的,通常由 FD_SETSIZE 常量决定,这在很多系统上默认是1024。这限制了服务器可以处理的最大并发连接数。当然 select 也会受限于系统级别的文件描述符数量限制。
效率问题:随着文件描述符数量的增加,select 的性能会线性下降。每次调用select时,都需要重新传入整个文件描述符集合,内核需要遍历这个集合来更新状态,这在文件描述符很多时会成为瓶颈。
响应时间变长:在 select 返回的文件描述符列表集合中,如果有多个文件描述符同时变为活跃状态,服务器通常会按顺序处理它们。这可能导致对列表前面的连接有偏见,使得后面的连接等待时间较长。
IO 复用之 Poll:
基本概念:
poll 也是一种 IO 复用技术,用于监视多个文件描述符(通常是网络套接字)的可读性、可写性和异常状态。与 select 类似,poll 允许您的程序监视多个文件描述符,直到一个或多个文件描述符准备好进行 IO 操作。这使得您可以同时管理多个网络连接,而不是逐个阻塞地处理它们。
函数声明
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
参数说明:
/*
fds:指向一个 pollfd 结构数组的指针,该数组包含要监视的文件描述符及其请求的事件(如 POLLIN 表示可读,POLLOUT 表示可写)。
nfds:指定数组 fds 中的元素数量。
timeout:指定等待时间(毫秒)。特殊值有:0 立即返回(非阻塞),-1 无限等待直到某个事件发生。
*/
pollfd 结构
poll 函数使用 pollfd 结构来指定要监视的文件描述符和事件类型:
struct pollfd {
int fd; // 文件描述符
short events; // 请求的事件
short revents; // 实际发生的事件
};
fd:文件描述符
events:要监视的事件,如 POLLIN、POLLOUT
revents:由 poll 函数设置,表明哪些事件实际发生了
Poll 底层采用的数据结构图解
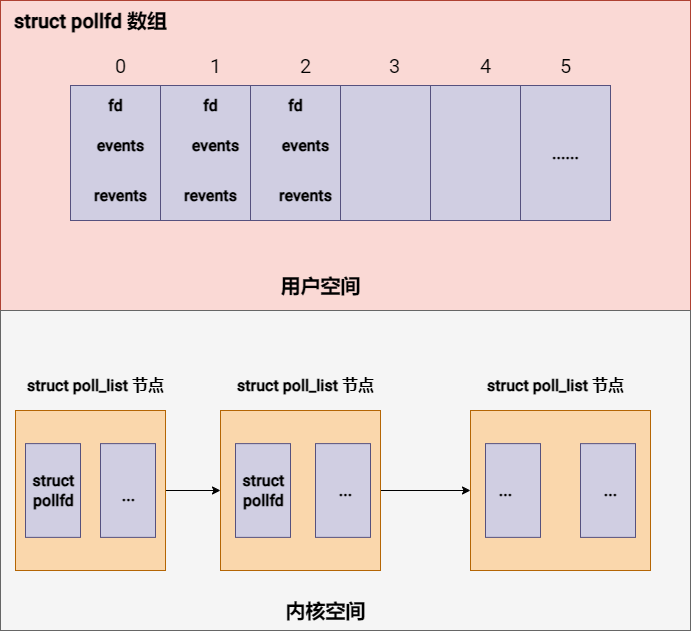
底层数据结构:
用户空间数组:用户空间程序使用数组(类型为 struct pollfd)来提供要监视的文件描述符及其感兴趣的事件
但在内核中,为了有效地处理这些文件描述符,poll 的实现转而使用链表。
内核空间链表:
- 当 poll 系统调用被执行时,内核首先将这个数组中的数据复制到内核空间。
- 在内核中,为了更灵活地处理可能的大量文件描述符,这些 pollfd 结构被组织成链表形式。
- 链表的每个节点可能包含一个或多个 pollfd 结构,具体取决于可用的内存和文件描述符的数量。
poll 优缺点:
优点:
无内置文件描述符限制:与 select 不同,poll 不受文件描述符数量的限制。select 通常受限于 FD_SETSIZE,这在处理大量并发连接时可能成为瓶颈。但它仍然受限于系统级别的文件描述符限制。
简化的接口:poll 使用单个结构体数组来表示所有监视的文件描述符和相关事件,相比 select 需要使用三个文件描述符集(读、写、异常),接口更为简洁。
更直观的事件模型:poll 使用位字段来表示不同的事件类型,这使得事件模型比 select 的方式更直观和易于理解。
缺点:
线性扫描开销:poll 在处理文件描述符时,需要对整个数组进行线性扫描。当监视的文件描述符数量非常大时,这可能导致性能下降。
总的来说,poll 是 select 的一种改进,特别是在可处理的文件描述符数量上没有限制,但在高性能和大规模并发处理方面,epoll 在现代 Linux 系统上通常是更佳的选择。
poll 并发回射服务器程序示例:
#define PORT 8080
#define MAX_CLIENTS 30
#define BUFFER_SIZE 1024
int main() {
int listen_fd, new_socket, valread;
struct sockaddr_in address;
int opt = 1;
int addrlen = sizeof(address);
char buffer[BUFFER_SIZE];
struct pollfd client_fds[MAX_CLIENTS];
// 创建监听套接字
listen_fd = socket(AF_INET, SOCK_STREAM, 0);
// 绑定套接字
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(PORT);
bind(listen_fd, (struct sockaddr *)&address, sizeof(address)
listen(listen_fd, 3); // 开始监听
// 初始化 pollfd 结构
for (int i = 0; i < MAX_CLIENTS; i++) {
client_fds[i].fd = -1;
}
client_fds[0].fd = listen_fd;
client_fds[0].events = POLLIN;
// 主循环
while (1) {
int activity = poll(client_fds, MAX_CLIENTS, -1);
if (activity < 0) {
//出错处理并退出
}
// 检查是否有新的连接
if (client_fds[0].revents & POLLIN) {
if ((new_socket = accept(listen_fd, (struct sockaddr *)&address, (socklen_t*)&addrlen)) < 0) {
//出错处理并退出
}
// 添加新的套接字到数组
for (int i = 1; i < MAX_CLIENTS; i++) {
if (client_fds[i].fd == -1) {
client_fds[i].fd = new_socket;
client_fds[i].events = POLLIN;
break;
}
}
}
// 检查客户端活动
for (int i = 1; i < MAX_CLIENTS; i++) {
if (client_fds[i].fd > 0 && (client_fds[i].revents & POLLIN)) {
if ((valread = read(client_fds[i].fd, buffer, BUFFER_SIZE)) > 0) {
buffer[valread] = '\0';
send(client_fds[i].fd, buffer, valread, 0);
} else {
close(client_fds[i].fd);
client_fds[i].fd = -1; // 标记为可用
}
}
}
}
return 0;
}
IO 复用之 Epoll
基本概念:
epoll 是 Linux 系统中一种高效的 I/O 事件通知机制,特别适用于处理大量并发网络连接。与传统的 select 或 poll 方法相比,epoll 的独特之处在于其对活跃连接的高效处理能力。它通过维护一个活跃事件集合,避免了对所有文件描述符的遍历,显著提升了性能。这使得 epoll 成为构建高性能网络应用程序的理想选择。
函数声明
epoll 主要涉及三个系统调用:epoll_create、epoll_ctl 和 epoll_wait。
// epoll_create:创建一个 epoll 实例。
int epoll_create(int size);
// poll_ctl:管理(添加、修改或删除)监视的文件描述符。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
/*
epfd:由 epoll_create 返回的 epoll 实例文件描述符。
op:要执行的操作,如 EPOLL_CTL_ADD(添加)、EPOLL_CTL_MOD(修改)、EPOLL_CTL_DEL(删除)。
fd:关联的文件描述符。
event:指向 epoll_event 结构的指针,指定感兴趣的事件和任何关联的用户数据。
*/
// 待在 epoll 文件描述符上注册的事件发生
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
/*
epfd:epoll 实例的文件描述符。
events:用于从内核获取事件的 epoll_event 结构数组。
maxevents:指示数组中可以返回的最大事件数。
timeout:等待事件的最大时间(毫秒),-1 表示无限等待。
*/
epoll_event 结构
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
/*
events 字段用于指定感兴趣的事件类型,例如 EPOLLIN(可读)、EPOLLOUT(可写)等。
data 字段通常用于存储用户定义的数据,如文件描述符、指向对象的指针等。
*/
//epoll_data_t 是一个联合(union),它用于存储用户定义的数据,可以是文件描述符、指针或任何其他用户需要的数据类型。
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
/*
例如,您可以在 epoll_ctl 调用时,使用 epoll_data_t 的 fd 字段来存储正在监视的文件描述符,
或者使用 ptr 字段来存储指向某个对象或结构的指针。这样,在事件发生时,您可以快速访问与该事件相关联的数据。
*/
Epoll 的两种触发模式:
在 Linux 中,epoll 提供了两种触发模式:水平触发(Level-Triggered, LT)和边缘触发(Edge-Triggered, ET)。理解这两种模式对于使用 epoll 来说非常关键,因为它们决定了在文件描述符(FD)上发生事件时,epoll 如何通知应用程序。
水平触发(Level-Triggered, LT)
触发条件:只要文件描述符关联的 socket 缓冲区上有数据可读或有空间可写,epoll_wait 就会返回该文件描述符。这意味着,只要有未处理的数据(如缓冲区中还有数据未读),epoll_wait 会不断地通知应用程序去读数据至用户空间缓存,从而进行处理。
处理方式:这种模式更加容易处理,因为即使应用程序没有一次性处理所有的可用数据,epoll_wait 会再次通知你该文件描述符上仍有待处理的数据。
水平触发的优点:
简单易懂:水平触发的行为更直观,容易理解和实现,尤其是对于那些不太熟悉非阻塞 I/O 编程的开发者。
容错性高:在水平触发模式下,只要文件描述符的状态仍满足条件(如有数据可读),epoll_wait 会持续通知应用程序,减少了因遗漏事件处理导致的错误。
水平触发的缺点:
可能的性能开销:在高负载或大量并发连接的情况下,水平触发可能导致频繁的 epoll_wait 响应。因为只要文件描述符仍然处于活跃状态(例如,仍有数据可读),它就会不断地触发事件。
资源使用效率:由于频繁的事件触发,水平触发模式可能导致更高的CPU使用率,尤其是当有大量活跃的文件描述符时。
水平触发示例代码:
struct epoll_event event;
int epoll_fd, fd;
event.events = EPOLLIN; // LT 是默认模式
event.data.fd = fd;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, fd, &event);
// 事件循环
while (true) {
struct epoll_event events[MAX_EVENTS];
int n = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
for (int i = 0; i < n; i++) {
if (events[i].data.fd == fd) {
// 可以读取部分数据,即使不全部读取完,该 FD 仍然会再次报告
}
}
}
边缘触发(Edge-Triggered, ET)
触发条件:只有文件描述符的状态发生改变时,epoll_wait 才会通知应用进程来读写数据(只通知一次),直到文件描述符的状态再次发生变化。
那什么才是文件描述符的状态发生改变呢?
文件描述符的状态发生改变指的是 fd 从不可读的状态改变成可读的状态或者fd 从不可写的状态改变成可写的状态。
对于 socket 可读事件来说:
fd 从不可读的状态改变成可读的状态,简单理解就是:fd 对应的 socket 接收缓冲区从无数据到有数据。
具体点:就是当数据首次到达一个空的 socket 接收缓冲区时,epoll_wait 会通知应用程序一次。此时,缓冲区状态从“无数据可读”变为“有数据可读”。又或者应用程序开始读取数据,并将缓冲区中的数据读完(读操作返回 EAGAIN),然后又有新数据到达。这两种情况都是属于 socket 接收缓冲区从无数据到有数据的例子。
再来看个特殊情况:
在 ET 模式下,一旦应用程序开始读取数据,如果没有一次性将缓冲区中的所有数据都读取完(即仍有未读取的数据留在缓冲区中),此时不会触发新的 epoll_wait 通知。但是如果此时接收缓冲区又来了新数据,即使文件描述符的状态并没有发生改变,但也会触发新的 epoll_wait 通知的。
对于 socket 可写事件来说:
文件描述符的状态发生改变指的是:fd 从不可写的状态改变成可写的状态。简单理解就是:fd 对应的 socket 发送缓冲区从满到不满。 对于可写事件,存在以下两个场景:
场景一:持续有空间
假设你有一个socket连接,你正在向它发送数据。在边缘触发(ET)模式下:
- 初始状态:连接建立后,发送缓冲区为空,所以你可以开始发送数据。
- 持续发送:只要发送缓冲区有空间,你可以继续发送数据。在这个过程中,如果缓冲区从未真正变满过(即,你的发送速度不超过网络层处理和发送数据的速度),epoll_wait不会因为缓冲区有空间而特别通知你,因为从epoll的角度看,这不是一个“状态变化”。
场景二:缓冲区满后又有空间
现在,让我们看一个缓冲区实际变满的情况:
1.发送直至满:你继续发送数据,直到达到一个点,发送缓冲区满了,这时,尝试再发送数据会失败(通常返回EAGAIN或EWOULDBLOCK)。
2.等待可写:这时,你应该停止发送数据,等待 epoll_wait 通知你 socket 再次可写。
3.缓冲区部分清空:随着时间的推移,网络层将缓冲区中的数据发送出去,缓冲区从“满”变为“有空间”(即,部分数据被发送出去,为新数据腾出了空间)。
4.收到通知:因为缓冲区的状态从“满”变为“有空间”,这是一个状态变化,epoll_wait 会通知你 socket 现在可写。
处理方式:ET 模式要求你必须一次性处理所有可用的数据。如果处理不完全,epoll_wait 不会再次通知你该文件描述符上的事件,除非新的数据到达或再次变为可写。
边缘触发示例代码:
struct epoll_event event;
int epoll_fd, fd;
event.events = EPOLLIN | EPOLLET; // 启用 ET 模式
event.data.fd = fd;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, fd, &event);
// 事件循环
while (true) {
struct epoll_event events[MAX_EVENTS];
int n = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
for (int i = 0; i < n; i++) {
if (events[i].data.fd == fd) {
while (true) {
ssize_t count = read(fd, buf, sizeof(buf));
if (count == -1) {
if (errno != EAGAIN) {
// 处理非 EAGAIN 错误
}
break; // 没有更多数据可读
}
// 处理读取的数据
}
}
}
}
边缘触发的优缺点:
优点:
减少通知频率:
在 ET 模式中,epoll_wait 只在文件描述符(如套接字)的状态发生变化时通知一次(例如,从不可读变为可读)。这减少了系统不断检查状态的需要,尤其在管理大量连接时非常有效。
提高事件处理效率:
由于减少了频繁的事件通知,应用程序可以更集中地处理每次通知的事件。这在同时处理许多连接时提升了效率。每次事件都得到了充分的处理,而不是浪费资源在重复或不必要的检查上,从而整体提高了处理大量并发连接的效率。
降低资源占用:
ET 模式通过减少频繁的事件检查和处理,有助于减少 CPU 和内存的使用,尤其在高负载下。
更好的扩展性:
对于需要处理大量并发连接的高性能服务器,ET 模式能够更高效地利用资源,使服务器能够承载更多的连接,从而提升整体的扩展能力。
缺点:
处理逻辑更加复杂:
在 ET 模式下,必须在每次通知时尽可能完整地处理 I/O 事件(读取或写入所有数据),因为相同条件下不会再次收到通知。这要求程序能够有效地一次性处理大量数据。
可能会错过一些数据:
如果在处理通知时没有完全读取或写入所有数据,剩余的数据可能不会触发新的通知,导致程序错过一些重要数据。
依赖于非阻塞 I/O:
ET 模式通常和非阻塞 I/O 结合使用。在这种模式下,编程变得更复杂,因为需要处理非阻塞调用可能遇到的特殊情况,如 EAGAIN 或 EWOULDBLOCK。
总结:
水平触发:更易于使用和理解,但可能会导致更多的 epoll_wait 调用,尤其是在高负载下。
边缘触发:更高的性能潜力,减少了 epoll_wait 调用的次数,但需要更谨慎的缓冲区管理和错误处理。
Epoll 优缺点
优点:
1.高效的文件描述符管理
在 epoll 中,高效的文件描述符管理首先依赖于高效的数据结构(红黑树和链表)以及回调函数。epoll 使用红黑树来组织所有监控的文件描述符,提供快速的查找、插入和删除操作。链表则用于存储准备就绪的事件,使得 epoll_wait 能迅速返回这些事件。每当监控的文件描述符发生状态变化(例如,socket 上有数据到来)时,与之关联的回调函数被内核自动触发。这些回调函数直接将就绪的文件描述符事件添加到 epoll 的就绪链表中。使得 epoll_wait 快速返回,这种集成了回调机制和高效数据结构的方法,使 epoll 在处理大量并发连接时比传统的 select 和 poll 方法更高效。
相比之下,select 和 poll 每次调用时都需要遍历整个文件描述符集合,以检查每个描述符的状态。当文件描述符数量很大时,这种方法的效率显著降低。
2.更好的可扩展性
epoll 能够处理的文件描述符数量远超过 select 的 FD_SETSIZE 限制(通常为1024),使其能够更有效地处理成千上万的并发连接。这使 epoll 成为高并发网络应用的理想选择,例如大型网站的服务器。
3.减少复制操作
在传统的 select 和 poll 方法中,应用程序需要在每次调用时将整个文件描述符集合从用户空间复制到内核空间,内核处理完后再将结果复制回用户空间。这种来回复制操作效率比较低。
而在 epoll 中,只需要将就绪事件从内核空间的就绪链表复制到用户空间,而非整个被监控的文件描述符集合。这种机制大大减少了数据在用户空间和内核空间之间频繁来回复制的需求,特别是在只有少数文件描述符就绪的大规模并发连接场景中,显著降低了上下文切换和数据复制的开销,从而提高了整体的效率和性能。
4.支持边缘触发(ET)和水平触发(LT)
- 两种触发模式:epoll 提供了边缘触发(ET)和水平触发(LT)两种模式。边缘触发仅在文件描述符状态发生变化时通知一次,而水平触发则在描述符保持某状态时持续通知。
- 适应不同的使用场景:
这种灵活性使得开发者可以根据具体的应用需求和行为特点选择最合适的模式,以优化性能。
缺点:
平台依赖性: epoll 是 Linux 特有的,不具备 select 和 poll 那样的跨平台特性。这意味着基于 epoll 的应用程序不能在非 Linux 系统上直接运行,限制了其可移植性。
边缘触发模式的挑战
在边缘触发(ET)模式下,epoll 只在状态变化时通知一次。这意味着应用程序必须正确处理所有的数据,否则可能会丢失未处理的事件。
Epoll 并发回射服务器程序示例:
#define MAX_EVENTS 10
#define READ_BUF_SIZE 1024
#define PORT 8080
int main() {
int listen_fd, conn_fd, epoll_fd;
struct sockaddr_in server_addr;
struct epoll_event event, events[MAX_EVENTS];
int event_count, i;
char read_buf[READ_BUF_SIZE];
socket(AF_INET, SOCK_STREAM, 0);
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(PORT);
bind(listen_fd, (struct sockaddr *)&server_addr, sizeof(server_addr))
listen(listen_fd, SOMAXCONN)
epoll_fd = epoll_create1(0);
event.events = EPOLLIN;
event.data.fd = listen_fd;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &event)
while (1) {
event_count = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
for (i = 0; i < event_count; i++) {
if (events[i].data.fd == listen_fd) {
conn_fd = accept(listen_fd, NULL, NULL);
if (conn_fd == -1) {
perror("accept");
continue;
}
event.events = EPOLLIN | EPOLLET;
event.data.fd = conn_fd;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, conn_fd, &event) == -1) {
perror("epoll_ctl");
close(conn_fd);
continue;
}
} else {
int nbytes = read(events[i].data.fd, read_buf, READ_BUF_SIZE);
if (nbytes <= 0) {
close(events[i].data.fd);
} else {
write(events[i].data.fd, read_buf, nbytes);
}
}
}
}
close(listen_fd);
close(epoll_fd);
return 0;
}
异步I/O服务器模型
在讲述了 I/O 多路复用服务器模型后,我们看到它如何使单个进程能够有效地管理多个网络连接。通过 select、poll 或 epoll,进程可以在多个连接上同时等待数据,而无需为每个连接阻塞等待。这种方法提升了并发处理的效率,但它有一个局限性:一旦某个连接的 I/O 操作开始,该进程必须等待该操作完成才能继续处理下一个连接。 简单理解就是:处理各个连接的 IO 读写是同步的,是串行的。
为了解决这一问题,引入了异步I/O服务器模型。这种模型极大提升了服务器的任务处理能力,它允许进程在发起I/O操作后立即转而执行其他工作,而无需等待I/O操作的完成。这一过程由操作系统在后台管理,一旦I/O操作完成,进程便会收到通知。进程只需要去处理已被拷贝至应用层缓冲区的数据。
Linux中的异步I/O实现:
在Linux中,异步 IO 模型主要由 Linux aio(通过libaio库)和 io_uring 两种技术来实现。
Linux aio(libaio)
Linux aio 是 Linux 系统中较早支持的异步I/O机制。它通过 libaio 库提供了一系列的API,允许应用程序非阻塞地启动和管理I/O操作。当一个I/O请求被提交后,libaio负责将其发送到操作系统,应用程序可以继续执行而无需等待。一旦I/O操作完成,应用程序将通过回调函数或其他机制得到通知。
libaio提供的 API :
io_setup :创建一个异步I/O上下文。
io_submit :向异步I/O上下文提交一个或多个I/O请求。
io_getevents :从异步I/O上下文中获取已完成的事件。
io_destroy :销毁一个异步I/O上下文。
尽管 libaio 为异步 I/O 提供了基础支持,但它有一定的局限性,比如:它只适用于文件 I/O,并不适合用于网络 I/O。
以下是一个简洁的 libaio 使用示例,演示了如何在 Linux 系统中以异步方式进行文件读取。
#include <libaio.h>
#include <sys/eventfd.h>
#define FILE_PATH "example_file.txt"
#define BUFFER_SIZE 1024
int main() {
io_context_t ctx;
struct iocb cb;
struct iocb *cbs[1];
char buffer[BUFFER_SIZE];
int file_fd, efd, ret;
struct io_event events[1];
uint64_t u;
memset(&ctx, 0, sizeof(ctx));
io_setup(10, &ctx);
file_fd = open(FILE_PATH, O_RDWR | O_CREAT, 0644);
// 创建eventfd用于通知
efd = eventfd(0, 0);
// 准备异步读请求
memset(&cb, 0, sizeof(struct iocb));
io_prep_pread(&cb, file_fd, buffer, BUFFER_SIZE, 0);
// 设置eventfd作为完成事件的通知
cb.data = (void *)(uintptr_t)efd;
cbs[0] = &cb;
// 提交异步I/O请求
io_submit(ctx, 1, cbs)
// 在这里,主线程可以执行其他业务逻辑
// ...
read(efd, &u, sizeof(uint64_t)); // 在主线程中等待通知
io_getevents(ctx, 1, 1, events, NULL); // 读取异步I/O事件
// 处理完成的I/O事件
if(events[0].data == (void *)(uintptr_t)efd) {
printf("Read %zd bytes: %.*s\n", events[0].res, (int)events[0].res, buffer);
}
close(file_fd);
io_destroy(ctx);
close(efd);
return 0;
}
io_uring:
io_uring 是 Linux 内核 5.1 版本引入的全新异步 I/O 框架,io_uring 旨在提供一种高效、灵活且功能丰富的方式来执行异步 I/O 操作。与 libaio 相比,io_uring 提供了更低的系统调用开销,更简单的接口,以及更好的性能。
如何工作:
io_uring 的核心思想是通过两个队列来管理异步 I/O 请求。一个叫做提交队列(SQ),另一个叫完成队列(CQ)。
1.提交请求:当你的程序想要执行一个 I/O 操作,比如读取网络数据,它会创建一个请求并把它放到提交队列(SQ)中。
2.内核处理:Linux 内核会查看提交队列,取出请求并处理它们。你的程序不需要等待内核完成这个操作,它可以继续做其他事情。
3.完成通知:一旦内核完成了一个请求,它会把结果放入完成队列(CQ)中。这样程序就知道该操作已经完成,可以继续处理结果了。
io_uring 的优势:
- 性能:它允许应用程序一次性地批量提交多个 I/O 请求,减少了系统调用的数量,所以 io_uring 能够提供比传统的异步 I/O 更好的性能。
- 减少等待:应用程序不需要每次提交一个请求就等待结果,它可以继续执行其他任务,同时内核在背后处理这些 I/O 请求。
- 功能丰富:io_uring 支持各种类型的 I/O 操作,包括但不限于文件读写、网络操作等。
- 易用性:io_uring 提供了一个更为简洁和一致的接口,相比于旧的异步 I/O 接口,它更易于使用和理解。
关于异步 IO 服务器模型的学习,大家只需要理解异步IO的工作方式,以及了解在 Linux 中可以通过 libaio 和 io_uring 技术可以构建异步 IO 服务器模型。如果想深入学习 io_uring 的底层原理,则可以去官网或者谷歌搜索相关资料去深入学习。
这篇文章,大家可以去了解:
https://cloud.tencent.com/developer/article/2187655
关于具体的代码示例,则可以去了解 liburing 这个库的 example 代码示例:https://github.com/axboe/liburing
服务器架构模式
在前面的介绍中,我们了解了常见的服务器模型,但是这些模型在应对高并发场景都会遇到一些挑战,特别是在处理大量并发连接和高效率 I/O 操作方面。尽管模型如多线程、线程池和 I/O 多路复用提供了并发处理的基础架构,但它们各自都有局限性,特别是在高并发和低延迟要求的场景中。
这些挑战促使了对一种更高效、更可扩展的并发处理模式的需求— 这就是 Reactor 模式。Reactor 模式采用事件驱动的方法,结合同步 I/O 多路复用技术,如 select、poll 或 epoll,提供了一种不同于传统线程模型的并发处理机制。
为什么需要 Reactor 模式?
并发和 I/O 效率:传统的多线程和多进程模型在处理成千上万的并发连接时可能会遇到性能瓶颈。这些模型往往涉及重的上下文切换和资源分配,特别是在频繁的 I/O 操作下。
简化事件处理:在 I/O 多路复用模型中,虽然可以高效地监控多个 I/O 流,但在事件分发和处理方面往往缺乏组织和结构。Reactor 模式提供了一种清晰的框架来处理多个并发 I/O 事件,简化了事件驱动程序的开发。
Reactor 模式详解
Reactor 是什么?
Reactor 模式可以理解为一种在网络编程中常用的设计模式,用于高效地处理多个并发 I/O 事件,如用户请求或网络通信。它的核心概念是使用一个中心化的处理器(称为 Reactor)来监控所有的 I/O 请求。当一个 I/O 事件发生时(例如,新的客户端连接或者数据到达),Reactor 会捕获这个事件,并将其分派给相应的处理程序进行处理。
核心组件:
1.Handles (句柄):
定义:句柄是对操作系统资源的引用,通常是文件描述符(file descriptor)。在网络编程中,这通常是指代网络套接字(sockets)。
用途:它用于标识一个特定的网络连接或其他 I/O 资源,如打开的文件、管道等。
示例:当一个客户端连接到服务器,服务器会为这个连接创建一个套接字,并为其分配一个文件描述符,这个文件描述符就是一个句柄。
2.Synchronous Event Demultiplexer (事件多路分发器):
定义:事件多路分发器是负责等待多个句柄上事件发生的组件。它可以同时监控多个句柄,如网络套接字上的可读或可写事件。
实现:在 Linux 中,这通常通过系统调用如 select, poll 或 epoll 实现。
功能:当一个或多个句柄上发生事件时(例如,新的客户端连接、数据到达等),事件多路分发器通知 Reactor。
3.Event Handler (事件处理器):
定义: 它是一个定义了处理不同类型事件所需接口或协议的抽象概念。通常包含一系列的方法或函数,用于处理各种事件,如读取数据(可读事件)、写入数据(可写事件)或处理错误(错误事件)。事件处理器定义了在发生特定事件时应当调用哪些方法,但不涉及这些方法的具体实现。
例如: 一个事件处理器接口可能有一个 handle_read 方法用于处理可读事件,但它并不实现该方法。
4.Concrete Event Handlers (具体事件处理器):
定义: 具体事件处理器实现了定义在事件处理器接口中的所有方法,提供了如何处理特定事件的具体逻辑。
例如,一个具体事件处理器可能实现 handle_read 方法来从套接字中读取数据并处理这些数据。又或者实现 handle_accept 方法来处理客户端的连接请求。
具体事件处理器是实际工作的组件,每个具体的事件处理器实例通常与应用程序中的一个特定资源(一个socket 文件描述符)关联。
5.Initiation Dispatcher (初始化分发器):
定义:初始化分发器是 Reactor 模式的核心组件,负责管理事件循环、监听事件并将它们分发到相应的具体事件处理器。
职责:它初始化事件多路分发器,注册事件处理器,并在事件发生时调用相应的具体事件处理器。
事件循环:在整个应用程序的生命周期内,初始化分发器运行一个循环,等待和分发事件。
select 实现的 Reactor 网络服务器程序
这里只是提供一个简单示例,但以上的5个组件都包含。
#define PORT 8080
#define BUFFER_SIZE 1024
#define MAX_CLIENTS 1024
handler_t handlers[MAX_CLIENTS];
int num_clients = 0;
typedef struct handler_t {
int handle; //句柄:在我们的上下文中就是套接字描述符。
void (*handle_func)(int handle, void *arg); //事件处理器
} handler_t;
// 具体事件处理器 : 处理客户端的连接请求
void acceptor_handler_func(int handle, void *arg) {
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
int client_fd = accept(handle, (struct sockaddr*)&client_addr, &client_len);
if (client_fd < 0) {
}
printf("Accepted connection from %s\n", inet_ntoa(client_addr.sin_addr));
// 将新客户端加入到 handlers 中
handlers[num_clients].handle = client_fd;
handlers[num_clients].handle_func = client_handler_func;
num_clients++;
}
// 具体事件处理器:处理客户端的数据处理请求
void client_handler_func(int handle, void *arg) {
char buffer[BUFFER_SIZE];
int nbytes = recv(handle, buffer, sizeof(buffer), 0);
if (nbytes <= 0) {
close(handle);
// 将handle从handlers数组中移除
for (int i = 0; i < num_clients; i++) {
if (handlers[i].handle == handle) {
handlers[i] = handlers[num_clients - 1];
num_clients--;
break;
}
}
} else {
send(handle, buffer, nbytes, 0);
}
}
void event_demultiplexer() {
fd_set read_fds;
int fd_max = 0;
FD_ZERO(&read_fds);
for (int i = 0; i < num_clients; i++) {
FD_SET(handlers[i].handle, &read_fds);
if (handlers[i].handle > fd_max) {
fd_max = handlers[i].handle;
}
}
// 等待 socket 上的可读事件
if (select(fd_max + 1, &read_fds, NULL, NULL, NULL) == -1) {
perror("select");
exit(1);
}
// 分发事件
for (int i = 0; i < num_clients; i++) {
if (FD_ISSET(handlers[i].handle, &read_fds)) {
handlers[i].handle_func(handlers[i].handle, NULL);
}
}
}
/*
Initiation Dispatcher (初始化分发器)
Initiation Dispatcher 是 Reactor 模式的核心,允许应用程序注册事件、注销事件。并且它负责启动事件循环,等待事件并分发事件。
*/
void run_reactor(int listen_fd) {
// 注册事件
handlers[num_clients].handle = listen_fd;
handlers[num_clients].handle_func = acceptor_handler_func;
num_clients++;
// 启动事件循环
while (1) {
event_demultiplexer();
}
}
int main() {
int listen_fd;
struct sockaddr_in server_addr;
listen_fd = socket(AF_INET, SOCK_STREAM, 0)
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(PORT);
server_addr.sin_addr.s_addr = INADDR_ANY;
bind(listen_fd, (struct sockaddr*)&server_addr, sizeof(server_addr);
listen(listen_fd, 10);
run_reactor(listen_fd);
close(listen_fd);
return 0;
}
基于 epoll 的高效性,我们一般会基于 epoll 去实现 reactor。具体实现可参考这篇文章:
https://zhuanlan.zhihu.com/p/539556726
Reactor 事件处理流程
下面通过时序图来图示上述代码的执行过程,方便大家理解:
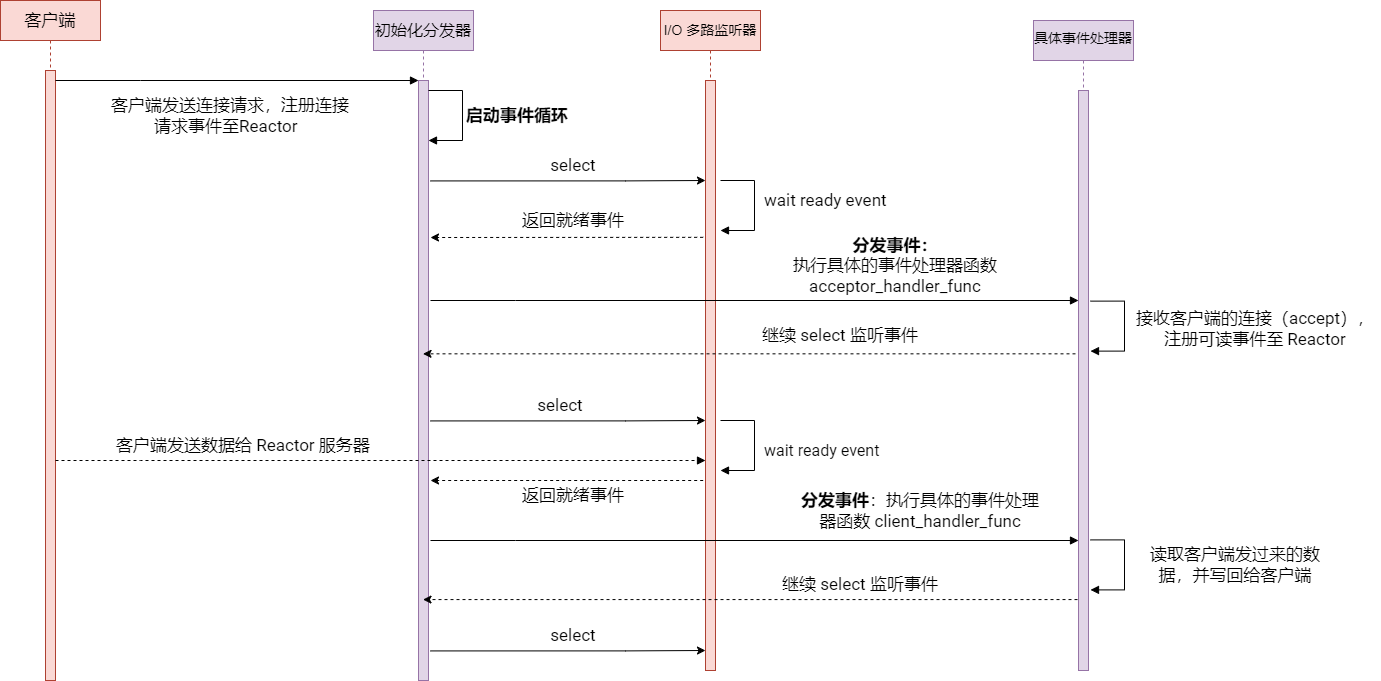
Reactor 模式的优势和应用场景
Reactor 模式的主要优势包括:
- 高效的资源利用:
通过单线程或少量线程来管理多个并发连接,减少了线程上下文切换和资源消耗,提高了资源利用效率。 - 快速响应能力:
非阻塞和事件驱动机制确保了快速响应外部事件,提高了程序的响应速度。 - 更好的可扩展性:
能够处理成千上万的并发连接,而不会遇到传统多线程或多进程模型中线程资源限制的问题。
应用场景
这种模式特别适合于需要高并发处理的网络服务器,如 Web 服务器、数据库服务器等。
结论:
Reactor 模式是现代高性能网络编程的基石之一。它通过事件驱动和非阻塞 I/O 机制有效地解决了传统并发模型在高并发环境下的限制,为构建可扩展的网络应用提供了强大的工具。
Proactor 模式详解
在前面的讲解中,我们探讨了 Reactor 模式。该模式主要依赖于同步 I/O,然而,随着并发需求的增加,尤其在高负载环境下,同步 I/O 的局限性逐渐凸显。
应对这一挑战,异步编程模型的 Proactor 模式提供了一种全新的解决方案。它区别于 Reactor 的同步等待,转而采用完全异步的 I/O 操作。在这个模式下,应用程序无需在 I/O 完成前等待,而是在 I/O 完成后接收通知。Proactor 模式有效减少了等待时间,提高了对并发连接的处理效率,尤其适合于构建高性能、I/O 密集型的网络应用。这一模式不仅提升了性能,也代表了网络编程范式的一次重要转变,为开发高效和可扩展的网络服务提供了新思路。
Proactor 是什么?
Proactor 模式是一种高级的异步编程模型,用于处理 I/O 操作。与传统的同步 I/O 操作(如 Reactor 模式)不同,Proactor 模式允许应用程序在不阻塞主执行线程的情况下执行 I/O 操作。应用程序发起异步 I/O 请求后可以继续执行其他任务,而无需阻塞等待 I/O 操作的完成。当 I/O 操作实际完成时,操作系统会通知应用程序,并触发预定义的回调函数或事件处理程序来处理 I/O 操作的结果。
核心组件
异步操作对象: 该对象代表了单个的异步 I/O 操作,如异步读取或写入。它 们通常封装了操作的细节,如操作类型、目标资源(文件描述符)、缓冲区地址等。
异步操作对象的定义
enum {
ADD_TYPE_ACCEPT,
ADD_TYPE_READ,
ADD_TYPE_WRITE
};
struct io_data {
int type; // ADD_TYPE_ACCEPT, ADD_TYPE_READ, ADD_TYPE_WRITE 等
int fd;
size_t bytes_read;
char buffer[BUFFER_SIZE];
};
Proactor 初始器(Proactor Initiator) :
Proactor 初始器是负责启动和配置异步 I/O 操作流程的组件。它通常由用户空间的代码执行,负责准备和提交异步 I/O 请求到内核。
在 io_uring 中,Proactor 初始器 对应的是用户空间代码,特别是负责初始化 io_uring 实例、以及提交异步 I/O 请求到内核的逻辑。
来看下在 io_uring 中, Proactor Initiator 的代码示例:
// 初始化 io_uring实例
int ret = io_uring_queue_init(256, &ring, 0);
// 提交一个异步读取请求
static void submit_async_read(struct io_uring *ring, int fd) {
struct io_data *data = malloc(sizeof(struct io_data));
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
data->fd = fd;
data->type = ADD_TYPE_READ;
io_uring_prep_read(sqe, fd, data->buffer, BUFFER_SIZE, 0); // 准备读取请求
io_uring_sqe_set_data(sqe, data); // 设置用户数据
io_uring_submit(ring); // 提交请求
}
异步操作处理器(Asynchronous Operation Processor):
异步操作处理器是 Proactor 模式的核心,在内核中执行,负责启动异步 I/O 操作并在操作完成时通知用户空间的 Proactor 实例。
在 io_uring 中,异步操作处理器 实际上是 io_uring 的内核组件。这包括提交队列(SQ)和完成队列(CQ),以及内核中负责处理这些队列的逻辑。
完成处理器(Completion Handler)
完成处理器是由应用程序定义的回调函数,它们在异步 I/O 操作完成时被调用以处理 I/O 操作的结果。
在 io_uring 中,完成处理器 对应于那些被提交到 io_uring 并在 I/O 操作完成后执行的回调函数。这些回调函数处理 io_uring 从完成队列中获取的 CQEs(多个完成队列条目)。
异步读取回调函数代码示例:
void handle_read(struct io_uring *ring, struct io_uring_cqe *cqe) {
struct io_data *data = io_uring_cqe_get_data(cqe);
if (!data) {
return; // 数据为空则直接返回
}
if (cqe->res <= 0) {
// 客户端断开连接或读取错误
close(data->fd);
} else {
// 读取数据,准备回写(data->buffer缓冲区已经有数据了)
data->bytes_read = cqe->res;
printf("Received: %.*s\n", (int)data->bytes_read, data->buffer);
// 可以在这里添加写回逻辑
}
free(data); // 释放内存
}
Proactor 实例:
Proactor 实例是负责管理整个异步 I/O 流程的组件,它管理着异步操作处理器和完成处理器,调度完成处理器,并处理所有的异步事件。
在 io_uring 中,Proactor 实例 对应的是用户空间中维护 io_uring 接口和逻辑的部分,其实就是一个事件循环,它负责监控完成队列(CQ),确定哪些 I/O 操作已经完成,并触发相应的完成处理器。
Proactor 实例代码示例:
// 运行事件循环以处理异步 I/O 操作
void run_io_uring_loop(struct io_uring *ring) {
struct io_uring_cqe *cqe;
unsigned head;
while (1) {
// 提交所有挂起的请求并等待至少一个请求完成
io_uring_submit_and_wait(ring, 1);
// 处理所有已完成的事件
io_uring_for_each_cqe(ring, head, cqe) {
if (cqe->res < 0) {
fprintf(stderr, "IO operation failed: %s\n", strerror(-cqe->res));
} else {
handle_read(ring, cqe); // 调用完成处理器
}
// 标记该事件已处理
io_uring_cqe_seen(ring, cqe);
}
}
}
Proactor 事件处理流程
启动异步操作(Proactor 初始器):
你的程序(通过 Proactor 初始器)准备一个异步 I/O 操作,比如说读取文件或接收网络数据。这个准备过程涉及指定要进行的操作类型(例如读取或写入)、哪个文件或网络连接,以及数据存放的位置。
一旦准备好,这个异步操作被提交给操作系统。如果使用 io_uring,这意味着将操作请求放入 io_uring 的提交队列(SQ)。操作系统内核处理异步操作(由异步操作处理器执行)。
一旦异步操作被提交,操作系统接管这个任务。在 io_uring 中,内核会处理这些 I/O 请求。与此同时,你的程序可以继续执行其他任务,不必等待 I/O 操作完成。
通知 Proactor实例 :
当操作系统完成了一个异步 I/O 操作,它会将此操作的结果放入完成队列(CQ)。
你的程序中的 Proactor 实例会定期检查这个完成队列,看看是否有任何操作已经完成。
处理完成的操作(完成处理器):
对于每一个已经完成的操作,Proactor 实例会调用相应的完成处理器。完成处理器是你事先定义好的,专门用来处理异步操作完成后的数据的函数。比如说,如果操作对象是网络套接字,处理器可能会处理读取到的数据。
清理和准备下一步操作:
一旦完成处理器运行完毕,Proactor 实例会进行必要的清理工作,并准备接收和处理更多的完成事件。
总结一下:Proactor 模式允许你的程序异步地执行 I/O 操作,同时继续进行其他任务。操作系统在后台处理这些 I/O 请求,当它们完成时,你的程序会得到通知,并调用相应的回调函数来处理结果。这个过程优化了资源的使用,提高了应用程序的响应性和效率。
Proactor 模式的优势
完全的异步处理:
Proactor 模式实现了真正的异步 I/O。在 Proactor 模式中,所有的 I/O 操作(包括读写)都是异步完成的。这意味着应用程序可以在 I/O 操作进行时继续执行其他任务,而无需等待 I/O 操作的完成。
相比之下,Reactor 模式通常只能异步地处理 I/O 请求的准备阶段(例如等待数据到达或可发送状态),而实际的读写操作仍然是同步进行的。
减少线程阻塞:
在 Proactor 模式中,由于 I/O 操作完全异步,应用程序线程不会因等待 I/O 操作而阻塞,这对于保持高性能和响应性是非常重要的。
Reactor 模式虽然减少了直接的 I/O 等待(例如等待数据到达),但在处理数据时仍然可能出现阻塞(如:数据处理操作耗时较长)。
简化编程模型:
Proactor 模式通过预定义的回调或事件处理器简化了异步 I/O 的编程模型,使得代码更加清晰和易于维护。
在 Reactor 模式中,编程者需要显式处理 I/O 事件的分发和响应,可能导致更复杂的事件处理逻辑。
Proactor 模式的应用场景
高性能网络服务器:
如 Web 服务器、数据库服务器等,特别是在需要处理大量并发网络请求的场景。
文件 I/O 密集型应用:
例如日志处理、大数据分析,以及任何需要频繁读写大型文件的应用。
总结
在本系列文章中,我们深入探讨了Linux下的套接字编程,一个在网络通信中不可或缺的核心技术-套接字。套接字作为网络通信的基石,使得不同主机间的数据交换变得可能。
套接字的本质
我们首先解析了套接字的概念,它是支持TCP/IP网络通信的基础API,为应用层与网络层之间提供了一个抽象层。通过套接字,应用程序可以不用关心底层的网络细节,就能进行网络通信。
套接字类型
接着,我们探讨了套接字的三种基本类型:
- 流式套接字(SOCK_STREAM):提供序列化的、可靠的、双向的连接通信。
- 数据报套接字(SOCK_DGRAM):提供非连接的、不可靠的通信。
- 原始套接字(SOCK_RAW):允许直接访问底层协议,用于需要细粒度控制的场景。
关键API与结构
我们详细介绍了套接字编程中的关键API,如 socket、bind、listen、accept、connect以及send和recv函数,以及套接字地址结构(如sockaddr)和地址转换API,这些是进行套接字编程的基础。
数据处理
字节序转换API的讨论,帮助我们处理跨平台的数据一致性问题。
Linux的IO模型
本系列文章还覆盖了Linux系统中的多种IO模型,包括阻塞IO、非阻塞IO、I/O多路复用、信号驱动IO和异步IO,它们各有优势,适用于不同的场景。
网络I/O性能优化
在网络I/O性能优化部分,我们讨论了硬件优化和软件优化策略,强调了应用程序设计的重要性和内核参数调整的作用。
服务器模型
最后,我们探讨了 Linux 环境下常见的服务器模型,包括单进程、多进程、多线程、线程池和I/O多路复用模型以及异步I/O服务器模型,每种模型都有其应用场景和优缺点。
架构模式
服务器架构模式,如 Reactor 和 Proactor,提供了高效处理并发网络事件的方法,是构建高性能网络应用的关键。
至此: 我们已经探索了 Linux 网络编程的核心领域,涵盖了从基本套接字类型与 API 的使用,到复杂的 I/O 模型和服务器架构设计等关键知识点。这些内容构成了搭建高可用网络服务的基础框架。本篇文章主要是帮助大家提供一个清晰的 Linux 网络编程学习指南,希望这篇文章能够为你们学习编程提供帮助。
如果你对 Linux 网络编程有更深的兴趣,或者想要探索更多关于Linux编程、以及计算机基础相关的知识,不妨关注我的公众号「跟着小康学编程」。这里不仅有丰富的学习资源,还有持续更新的技术文章。

另外,小康最近创建了一个技术交流群,专门用来探讨技术相关或者解答读者的问题。大家在阅读这篇文章的时候,如果觉得有问题的或者有不理解的知识点,欢迎大家加群或者评论区询问。我能够解决的,尽量给大家回复。

Linux 网络编程从入门到进阶 学习指南的更多相关文章
- Linux网络编程&内核学习
c语言: 基础篇 1.<写给大家看的C语言书(第2版)> 原书名: Absolute Beginner's Guide to C (2nd Edition) 原出版社: Sams 作者: ...
- Linux网络编程入门 (转载)
(一)Linux网络编程--网络知识介绍 Linux网络编程--网络知识介绍客户端和服务端 网络程序和普通的程序有一个最大的区别是网络程序是由两个部分组成的--客户端和服务器端. 客户 ...
- 【转】Linux网络编程入门
(一)Linux网络编程--网络知识介绍 Linux网络编程--网络知识介绍客户端和服务端 网络程序和普通的程序有一个最大的区别是网络程序是由两个部分组成的--客户端和服务器端. 客户 ...
- 《转》Linux网络编程入门
原地址:http://www.cnblogs.com/duzouzhe/archive/2009/06/19/1506699.html (一)Linux网络编程--网络知识介绍 Linux网络编程-- ...
- Linux网络编程学习计划
由于网络编程是很重要的一块,自己这一块也比较欠缺,只知道一些皮毛,从今天开始系统学习<Linux网络编程>一书,全书分为十四个章节: 第一章 概论 P1-16 第二章 UNIX ...
- Proxy源代码分析——谈谈如何学习Linux网络编程
Linux是一个可靠性非常高的操作系统,但是所有用过Linux的朋友都会感觉到, Linux和Windows这样的"傻瓜"操作系统(这里丝毫没有贬低Windows的意思,相反这应该 ...
- Linux网络编程学习路线
转载自:https://blog.csdn.net/lianghe_work/article 一.网络应用层编程 1.Linux网络编程01——网络协议入门 2.Linux网络编程02——无连接和 ...
- Proxy源代码分析--谈谈如何学习Linux网络编程
http://blog.csdn.net/cloudtech/article/details/1823531 Linux是一个可靠性非常高的操作系统,但是所有用过Linux的朋友都会感觉到,Linux ...
- Linux网络编程入门
(一)Linux网络编程--网络知识介绍 Linux网络编程--网络知识介绍客户端和服务端 网络程序和普通的程序有一个最大的区别是网络程序是由两个部分组成的--客户端和服务器端. 客户 ...
- 服务器编程入门(4)Linux网络编程基础API
问题聚焦: 这节介绍的不仅是网络编程的几个API 更重要的是,探讨了Linux网络编程基础API与内核中TCP/IP协议族之间的关系. 这节主要介绍三个方面的内容:套接字( ...
随机推荐
- 【Mysql】复合主键的索引
复合主键在where中使用查询的时候到底走不走索引呢?例如下表: create table index_test ( a int not null, b int not null, c int not ...
- 19.4 Boost Asio 远程命令执行
命令执行机制的实现与原生套接字通信一致,仅仅只是在调用时采用了Boost通用接口,在服务端中我们通过封装实现一个run_command函数,该函数用于发送一个字符串命令,并循环等待接收客户端返回的字符 ...
- 《字节码编程》PDF107页,11万字。既然市面缺少ASM、Javassist、Byte-buddy成体系的学习资料,那我来!
作者:小傅哥 博客:https://bugstack.cn - 汇总系列原创专题文章 沉淀.分享.成长,让自己和他人都能有所收获! 让人怪不好意思的,说是出书有点膨胀,毕竟这不是走出版社的流程,选题. ...
- 线程锁(Python)
一.多个线程对同一个数据进行修改 from threading import Thread,Lock n = 0 def add(lock): for i in range(500000): glob ...
- HarmonyOS 开发入门(一)
HarmonyOS 开发入门(一) 日常逼逼叨 因为本人之前做过一些Android相关的程序开发,对移动端的开发兴趣比较浓厚,近期也了解到了一些关于华为HarmonyOS 4.0 的事件热点,结合黑马 ...
- 【进阶篇】Java 实际开发中积累的几个小技巧(一)
目录 前言 一.枚举类的注解 二.RESTful 接口 三.类属性转换 四.Stream 流 五.判空和断言 5.1判空部分 5.2断言部分 文章小结 前言 笔者目前从事一线 Java 开发今年是第 ...
- 逆天的全排列函数next_permutation()
next_permutation 是算法库(<algorithm>)里的一个用于求全排列的函数,其定义为 next_permutation(_BidIt _First, _BidIt _L ...
- .NET 云原生架构师训练营(模块二 基础巩固 EF Core 介绍)--学习笔记
2.4.2 EF Core -- 介绍 ORM Repository 仓储 UnitOfWork 工作单元 DB Context 与 DB Set EF Core快速开始示例 ORM ORM:obje ...
- Hadoop集群常用组件的命令
1. Hadoop (1).HDFS:启动HDFS:start-dfs.sh关闭HDFS:stop-dfs.sh格式化NameNode:hdfs namenode -format查看文件系统状态:hd ...
- OGG常用运维命令
1. 管理(MGR)进程命令 INFO MANAGER 返回有关管理器端口和进程id的信息. START MANAGER 开启管理进程 STATUS MANAGER ...