Reactor 简介
官方的介绍如下:
Reactor is a fully non-blocking reactive programming foundation for the JVM, with efficient demand management (in the form of managing “backpressure”). It integrates directly with the Java 8 functional APIs, notably
CompletableFuture,Stream, andDuration. It offers composable asynchronous sequence APIs —Flux(for [N] elements) andMono(for [0|1] elements) — and extensively implements the Reactive Streams specification.
大致翻译如下:
Reactor 是一个完全非阻塞的 JVM 反应式编程基础,具有高效的需求管理(以管理“背压”的形式)。它直接整合了 Java 8 中的函数式编程的 API,尤其是
CompletableFuture、Stream和Duration。它提供了可组合的异步序列 API—Flux(用于 N 个元素)和Mono(用于0个或一个元素),并实现了Reactive Stream规范
使用 Reactor 的原因
Reactor Programming (响应式编程)是一种新的编程范式,可以通过使用类似于函数式编程的方式来构建异步处理管道。它是一个基于事件的模型,其中数据在可用时推送给消费者。
Reactor Programming 具有能够有效地利用资源并且增加应用程序为大量客户端提供服务的能力,相比较传统的创建一个单独的线程来处理请求,响应式编程能够降低编写并发代码的难度。
通过围绕完全异步和非阻塞的核心支柱构建,响应式编程是 JDK 中那些功能有限的异步处理 API (CallBack 和 Future 等)的更好的替代方案
关键概念
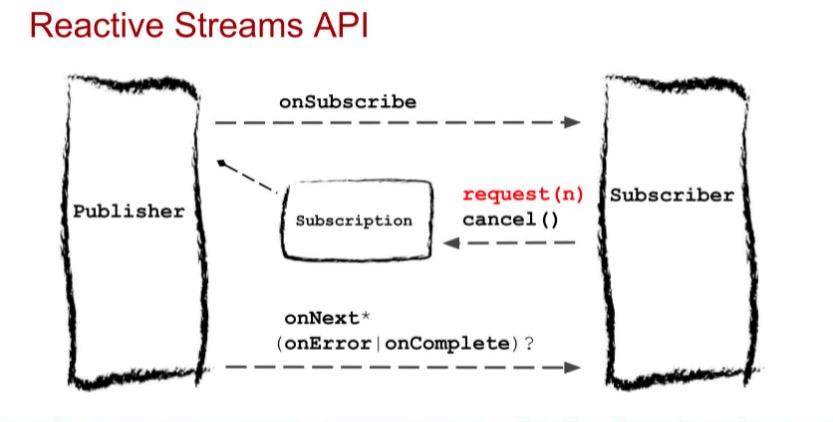
Publisher
数据的发布者,即数据产生的地方
Subscriber
数据的订阅者,即数据接受方
和
Publisher的关系如下: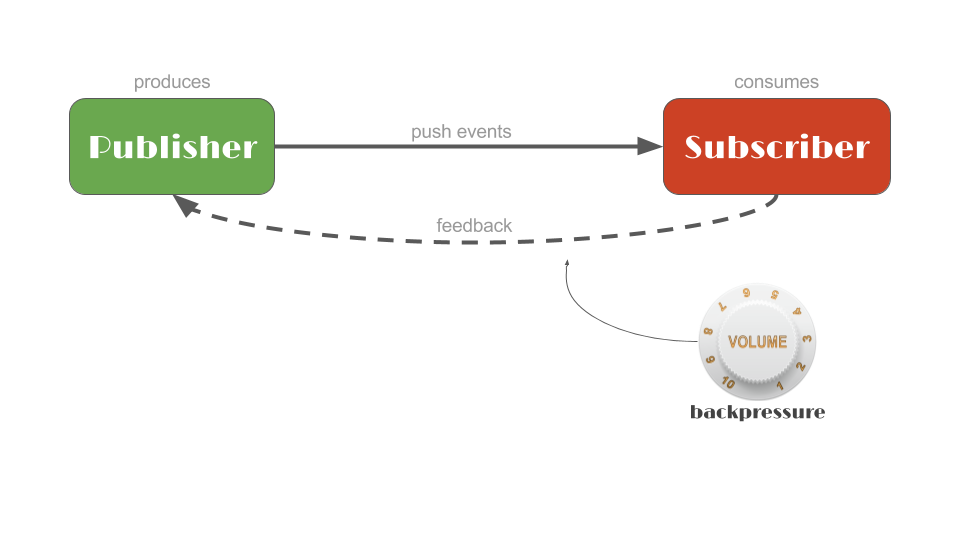
Processor
代表一个处理阶段,既是
Publisher,也是SubscriberSubscription
代表
Publisher和Subscriber 的一对一生命周期,只能由一个Subscriber使用一次
对应的关系图如下:
首先定义实体类:
public class User {
public static final User SKYLER = new User("swhite", "Skyler", "White");
public static final User JESSE = new User("jpinkman", "Jesse", "Pinkman");
public static final User WALTER = new User("wwhite", "Walter", "White");
public static final User SAUL = new User("sgoodman", "Saul", "Goodman");
private final String username;
private final String firstname;
private final String lastname;
public User(String username, String firstname, String lastname) {
this.username = username;
this.firstname = firstname;
this.lastname = lastname;
}
// 省略一部分 getter 和 Object 相关的代码
}
定义一个转换函数
// 这个函数的任务是将 User 的每个字段都转换成为对应的大写形式
Function<User, User> capital = user ->
new User(
user.getUsername().toUpperCase(),
user.getFirstname().toUpperCase(),
user.getLastname().toUpperCase()
);
Flux
Flux 是 Reactive Stream 中的 Publisher,增加了许多可用于生成、转换、编排 Flux 序列的运算符。Flux 用于发送 0 个或者多个元素(onNext() 事件触发),然后成功结束或者直到出现 error(onCompelete() 和 onError() 都是终止事件),如果没有终止事件的产生,那么 Flux 将会产生无穷无尽的元素

基本使用
静态方法
静态工厂方法
静态方法主要是用于创建元素流,或者通过几种回调类型来生成这些流的元素
创建
Flux主要有以下几种方法:// 创建一个空的 Flux
static <T> Flux<T> empty(); // 解析传入的参数值,将它们组合成一个 Flux
static <T> Flux<T> just(T... data); // 从一个 Iterable 对象中创建对应的 Flux
static <T> Flux<T> fromIterable(Iterable<? extends T> it); // 创建一个 Exception 元素,这是在 Reactor Stream 中处理异常的方式
static <T> Flux<T> error(Throwable error); // 每个一定时间间隔产生一个 Long 类型的元素到 Flux 的流中
static Flux<Long> interval(Duration period); // 通过一个 Consumer,每次在请求元素时调用这个函数
static <T> Flux<T> generate(Consumer<SynchronousSink<T>> generator); // 支持从
static <T> Flux<T> create(Consumer<? super FluxSink<T>> emitter); static <T> Flux<T> push(Consumer<? super FluxSink<T>> emitter);
generate通过响应请求,产生不同的元素。
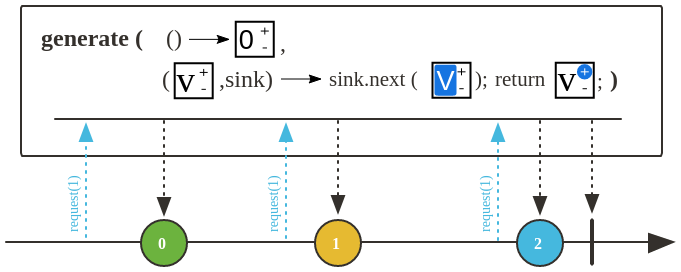
具体示例如下:
Scanner sc = new Scanner(System.in); // 从控制台获取输入,然后生成对应的流元素,将将这些元素转换为大写之后再输出到控制台
Flux.<String>generate(sink -> {
sink.next(sc.next()); // 这里的 sink 是同步的
})
.doFinally(any -> sc.close())
.map(String::toUpperCase)
.subscribe(System.out::println);
// 这种方式在响应客户的相关请求时比较有用
create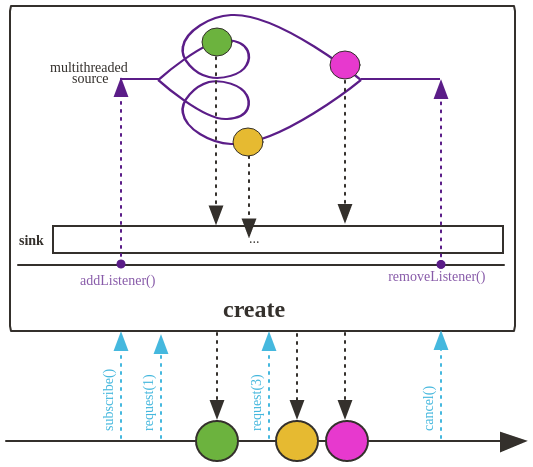
该方法将
Publisher的生产步骤暴露给外部,使得将产生元素的逻辑拆分到外部,而将元素的处理逻辑封装起来,减少系统的耦合merge方法签名如下:
// 将多个 Publisher 合并为一个 Flux,这样合并的 Flux 的元素组成将是交错(无顺序的)
static <I> Flux<I> merge(int prefetch, boolean delayError, Publisher<? extends I>... sources)
concat// 将多个 Publisher 合并为一个 Flux,这样得到的 Flux 是有序的
static <T> Flux<T> concat(Publisher<? extends T>... sources)
实例方法
map// 函数原型,该方法的主要任务是 Flux 中的每个元素进行通过转换函数进行转换。。。
public final <V> Flux<V> map(Function<? super T, ? extends V> mapper);
具体使用:
// 将 Flux 中的每个 User 对象执行对应的转换,得到转换之后的一个新的 Flux
Flux<User> capitalizeMany(Flux<User> flux) {
return flux.map(capital);
}
flatMap有的转换函数可能是阻塞的,由于
Reactor要求每个操作应当都是非阻塞的,为了解决这个问题,可以将相关的map操作放入一个Mono中进行异步处理以达到非阻塞的效果Flux的flatMap的函数原型如下:/*
将当前 Flux 中的元素以异步的方式发送到 Publisher 中,然后通过合并的方式将这些 Publisher
扁平化为单个的 Flux,这个操作允许 Flux 交错(不按顺序)地进行
*/
public final <R> Flux<R> flatMap(Function<? super T, ? extends Publisher<? extends R>> mapper);
具体的过程如下所示:

具体示例如下:
Flux<User> asyncCapitalizeMany(Flux<User> flux) {
/*
将 Flux 的每个元素以异步的方式放入到 Mono 中,最后再将这些 Mono 的元素整合到
一个 Flux 中
*/
return flux.flatMap(this::asyncCapitalizeUser);
} Mono<User> asyncCapitalizeUser(User u) {
return Mono.just(
new User(
u.getUsername().toUpperCase(),
u.getFirstname().toUpperCase(),
u.getLastname().toUpperCase()
)
);
}
Mono
Mono 和 FLux 类似,主要的区别在于 Mono 的元素个数只能是 0 个或一个,或者元素是一个异常

基本使用
静态方法
静态工厂方法
静态工厂方法主要用于创建
Mono// 创建一个空的 Mono
static <T> Mono<T> empty(); /*
创建一个不会产生任何数据的 Mono,与空的 Mono 不同,
这样得到的 Mono 不会产生任何 onComplete 事件
*/
static <T> Mono<T> never(); // 从单个的元素产生一个 Mono
static <T> Mono<T> just(T data); // 产生一个带有异常的 Mono
static <T> Mono<T> error(Throwable error);
fromSupplier
创建一个
Mono,产生的元素由对应的Supplier来提供,如果Supplier产生的是null,那么就会得到一个空的Mono方法原型如下:
public static <T> Mono<T> fromSupplier(Supplier<? extends T> supplier)
这个方法在结合
Flux实现异步处理的时候非常有用,类似的方法还有:fromCallable、fromRunnable、fromFuture等defer
创建一个
Mono,通过这种方式创建的Mono会为每个subscriber提供一个新的一致的Mono方法原型如下:
public static <T> Mono<T> defer(Supplier<? extends Mono<? extends T>> supplier)
实例方法
map方法原型如下:
// 将元素执行对应的转换。。。
public final <R> Mono<R> map(Function<? super T, ? extends R> mapper);
flatMap方法原型如下:
// 将当前的元素放入到一个 Publisher 中,以实现非阻塞的目标
final <R> Mono<R> flatMap(Function<? super T, ? extends Mono<? extends R>>

StepVerifier
Reactor Programming 和一般的编程不一样,由于它是完全非阻塞的,因此代码的调试可能会变得很困难,使用 StepVerifier 类能够有效地检测 Reactor Stream 是否时按照预期的定义进行的
首先,需要添加 reactor-test 相关的依赖
<!-- 在 Spring Boot 中由 SpringBoot Parent 管理,因此无须添加版本号 -->
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
</dependency>
基本使用
检测预期的元素
// 创建一个 Flux 元素流
Flux<Long> counter = Flux.interval(Duration.ofMillis(10)).take(5);
// 检测每一步得到的元素,如果不是预期的元素,则会得到一个断言失败的异常。。。
StepVerifier.create(counter)
.expectNext(0L)
.expectNext(1L)
.expectNext(2L)
.expectNext(3L)
.expectNext(4L)
.verifyComplete();
断言出现的元素
static class {
private final String username;
private final String firstname;
private final String lastname; public User(String username, String firstname, String lastname) {
this.username = username;
this.firstname = firstname;
this.lastname = lastname;
} // 省略一部分代码
} void expectSkylerJesseComplete(Flux<User> flux) {
StepVerifier.create(flux)
// 下一个到来的元素应当是 username 为 "swhite" 的 User 对象
.assertNext(user -> user.getUsername().equals("swhite"))
// ...............
.assertNext(user -> user.getUsername().equals("jpinkman"))
.verifyComplete(); // 此时元素流应当已经结束
}
检测出现的异常
StepVerifier.create(flux) // 从对应的 Flux 创建元素流
.expectError(RuntimeException.class) // 下一个到来的元素应当是一个 RuntimeException
.verify();
虚拟时间检测
使用
Flux的internal()方法将会按照一定的时间间隔产生一个元素,如果产生的元素很多,同时每个元素产生的间隔又很大,这个时候就会导致测试时间会变得很长,为了解决这个问题,StepVerifier提供了withVirtualTime的方法来解决这个问题Supplier<Flux<Long>> supplier = () -> Flux.interval(Duration.ofSeconds(1)).take(3600L); StepVerifier.withVirtualTime(supplier)
.thenAwait(Duration.ofHours(1)) // 使得当前的 Flux 元素流觉得 3600s 已经过去了
.expectNextCount(3600) // 此时应当已经接受了 3600 个元素
.verifyComplete(); // 测试结束
背压(backpressure)
前文介绍了有关 Publisher 和 Subscriber 之间的关系,在关系图中存在一个称为 “backpressure” 的轮子,这个组件的作用用于限制 Publisher 向 Subscriber 发送数据的速度,使得 Subscriber 能够正常地处理数据,不至于由于收到的数据过多无法处理而导致 Subscriber 宕机。
这是一种反馈机制,由 Subscriber 向 Publisher 发送一个 “反馈信息”,表示自己准备处理多少数据,而 Publisher 通过这一 “反馈信息” 限制自己的发送数据的速度(具体可以将多余的数据丢弃或放入缓冲区等),从而达到一个动态的平衡。
Flux.just(1, 2, 3, 4, 5)
.log() // 打印相关的记录信息。。。。
.subscribe(new Subscriber<Integer>() {
private Subscription subscription;
private int amt = 0;
@Override
public void onSubscribe(Subscription subscription) {
this.subscription = subscription;
this.subscription.request(2); // 首先请求两个元素
}
/*
之后,每获取到两个元素就发送一个 “获取下两个元素” 的反馈信息给 Publisher,
以此达到背压的效果
*/
@Override
public void onNext(Integer integer) {
System.out.println("onNext: " + integer);
amt++;
if (amt % 2 == 0) this.subscription.request(2);
}
@Override
public void onError(Throwable throwable) {
// nothing should to do....
}
@Override
public void onComplete() {
// nothing should to do....
}
});
处理策略
当Publisher 发布元素的速度大于 Subscriber 能够处理的速度时,将会导致 Publisher 的·数据积压,需要采取不同的处理策略来解决这个问题。
具体的处理策略定义于 reactor.core.publisher.FluxSink.OverflowStrategy 中,主要有以下几种策略:
BUFFER(默认)将多余的元素放入
buffer中,这种方式在速率相差很大的情况下将会产生异常LATEST订阅者仅仅获得最新的元素,和
DROP策略有点类似DROPPublisher丢弃产生的多余的元素ERROR直接传一个
IllegalStateException给SubscriberIGNORE完全忽略来自
Subscriber的背压请求(当订阅者队列已满时,这可能会导致IllegalStateException)
冷流和热流
一般由 Flux.jus(...) 方法创建的元素流是静态的、有长度限制的并且只能被 Subscriber 一次,处理起来也比较容易,这种元素流也被称为 “冷流”。实际使用过程中,这种情况不太可能会遇到,一般情况下,没有长度限制的元素流、能够被多个订阅者订阅的元素流才是常见的情况
冷流 —> 热流
通过调用 Flux 对象的 publish() 或 replay 方法可以将 “冷流” 转换为 “热流”
publish()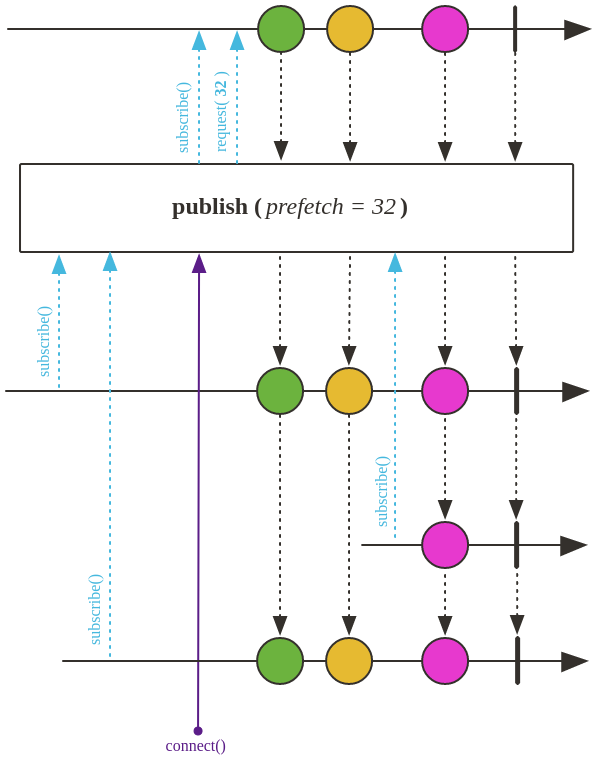
如图,调用
publish() 方法之后,每个subscriber都有自己的一个Flux元素流,从而使得多个subscriber能够订阅一个Flux具体示例如下:
ConnectableFlux<Object> publish = Flux.create(sink -> {
while (true) {
sink.next(System.currentTimeMillis()); // 不断地产生元素
}
})
.sample(Duration.ofMillis(500)) // 每隔 500ms publish 一个元素
.publish();
publish.subscribe(s -> System.out.println("Subscribe-1: " + s)); // subscrbe-1
publish.subscribe(s -> System.out.println("Subscribe-2: " + s)); // subscrbe-1
publish.connect(); // 在 connect 之前不会产生进一步的动作 // 也可以在调用 publish() 方法之后直接调用 autoConnect() 方法使得订阅的 subscriber 能够自动连接,或者也可以通过 refCount(int n) 方法使得在有 n 个订阅者订阅时自动连接来达到同样的效果
replay()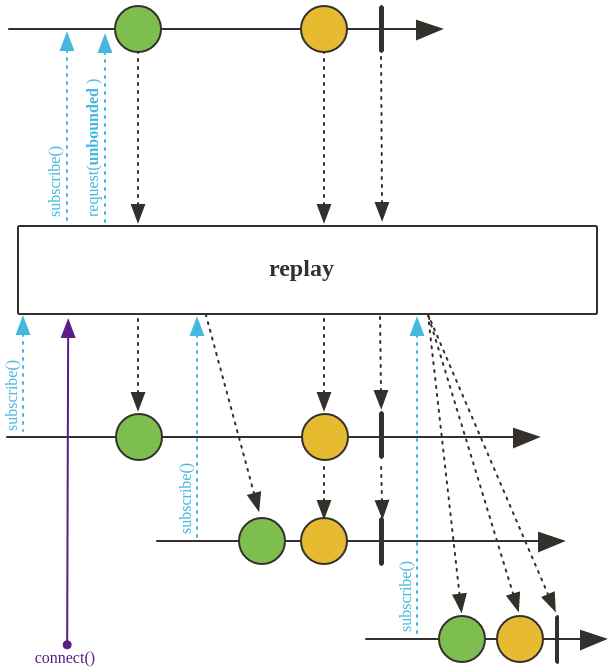
replay()同样可以将 “冷流” 转换为 “热流”,不同的地方在与replay()方法会使得新来的subscribe首先获取前面的元素,再正式完成元素流的订阅。
并发
一般情况下,创建的元素流是在当前的线程下启动的,由于 Reactor 是完全非阻塞的,因此如果某个流的操作阻塞的,那么在这种情况下可能就无法看到执行的信息(但实际上确实做了这个任务)。
如果想要将当前流的执行环境放入到另一个线程中,可以考虑使用 Reactor 提供的 Schedulers 来实现
具体示例如下:
Flux.just(1, 2, 3, 4)
.log()
.map(i -> i * 2)
.subscribeOn(Schedulers.parallel()) // 修改 Subscribe 所在的线程,这里由 Schedulers 控制
.doOnNext(s -> System.out.println("Current Thread: " + Thread.currentThread().getName())) // 每次获取到元素时打印当前的线程
.subscribe();
/*
由于 JVM 会在不存在非守护线程时退出,而 Reactor 又是完全非阻塞的,因此 Reactor 运行时的线程会被视为一个已完成任务的线程(实际上还没有),在 Main 方法中,直接这么编写将会导致 JVM 提前结束;为了解决这个问题,主要有两种思路:使得当前线程睡眠一会儿使得所有任务有机会执行;开启一个新的非守护线程去执行这个任务(在当前的 Schedule 调度的情况下,会创建一个新的单线程的线程池去执行,因此这么做也是非阻塞的)。
*/
Thread.sleep(1000);
得到的输出如下:

图中的 "parallel-1" 就是 Flux 所在的流执行的线程
如果使用创建新的线程的方式来执行,具体示例如下:
// 创建一个
Flux<Integer> flux = Flux.just(1, 2, 3, 4)
.log()
.map(i -> i * 2)
/*
注意,不要使用 Schedulers 来执行调度,这样会使得当前的“父线程”(当前 Flux 的执行线程)
为非阻塞的而直接结束
*/
// .subscribeOn(Schedulers.parallel())
.doOnNext(s -> System.out.println("Current Thread: " + Thread.currentThread().getName()));
/*
创建一个名为 "subscribe-Thread" 的线程去执行这个任务,由于 Flux 的元素是在这个新的线程中执行的,
因此在这个过程中这个线程始终都是存活的,这样就可以避免 JVM 提前退出的问题了
*/
new Thread(flux::subscribe, "subscribe-Thread").start();
执行结果如下:

实际使用
异步处理
现在,有了 Reactor 之后,实现任务的异步处理就变得十分简单了。在 Reactor 之前,如果使用传统的 Future 或者 CompletableFuture 来实现类似功能,尽管看上去是异步的,但是实际上 Future 的 get() 操作依旧是阻塞的
现在,来看一个具体的问题:现在需要从一些文件中读取一些数据,再将它们进行排序。
由于 IO 操作是一个阻塞操作,按照一般的同步的方式进行文件的读取,当遇到一个文件比较大时,将会导致整个系统整体的响应时间会比较大,使用异步的方式可以有效地降低系统的响应时间。
File[] readFiles = new File[]{
new File(basPath + "/data_1.txt"), // data_1 的数据量为 10000 条
new File(basPath + "/data_2.txt"), // data_2 的数据量为 100 条
new File(basPath + "/data_3.txt"), // data_3 的数据量为 30000 条
new File(basPath + "/data_4.txt"), // data_4 的数据量为 600 条
new File(basPath + "/data_5.txt"), // data_5 的数据量为 200 条
new File(basPath + "/data_6.txt"), // data_6 的数据量为 20000 条
};
AtomicLong start = new AtomicLong();
AtomicLong end = new AtomicLong();
Flux.just(readFiles)
.doOnSubscribe(any -> start.set(System.currentTimeMillis()))
.flatMap(
file -> Mono.just(new ReadFunction(file.getName()).apply(file))
.subscribeOn(Schedulers.newParallel("Thread-" + file.getName()))
.flatMap(element -> Mono.just(new SortFunction().apply(element)))
)
.doOnNext(element -> System.out.println(element.getName() + " has been finished......"))
.subscribe(new Subscriber<Element>() {
private Subscription subscription;
@Override
public void onSubscribe(Subscription subscription) {
this.subscription = subscription;
this.subscription.request(1L);
}
@Override
public void onNext(Element element) {
System.out.println("Get Element=" + element.getName());
this.subscription.request(1L);
}
@Override
public void onError(Throwable throwable) {}
@Override
public void onComplete() {
end.set(System.currentTimeMillis());
System.out.println("Take Time: " + (end.get() - start.get()) + " ms");
System.exit(0); // 由于使用别的线程来处理,有时这些线程会一直存在,导致 JVM 无法正常退出。。。。
}
});
运行结果如下:

可以看到,最终的结果是通过异步的方式来执行的(不是按照元素流的顺序),Reactor 是 Java 实现异步编程很有用的工具
任务调度
有四个程序:service-1、service-2、service-3、service-4 存在以下依赖关系:service-1 必须等待 service-2 程序执行完成之后才能执行,service-4 必须在 service-1 和 service-3 全部执行完成之后才能执行。
如果通过其它的 Future 类来完成这几个服务程序的处理,代码将会变得相当复杂,但是使用 Reactor 则可以简化这些代码。
首先,模拟四个服务程序:
public class Util {
public static void print(Flux<?> flux) {
flux.subscribe(System.out::println);
}
// service-1 执行 1000 ms
public static String service1() throws InterruptedException {
Thread.sleep(1000);
return "service-1";
}
// service-2 执行 1500 ms
public static String service2(String inputFrom1) throws InterruptedException {
Thread.sleep(1500);
return "service-2 " + inputFrom1;
}
// service-3 执行 1200 ms
public static String service3() throws InterruptedException {
Thread.sleep(1200);
return "service-3";
}
// service-4 执行 500 ms
public static String service4(String inputFrom2, String inputFrom3) throws InterruptedException {
Thread.sleep(500);
return "service-4: " + inputFrom2 + " : " + inputFrom3;
}
}
现在通过 Reactor 的方式来将这四个程序进行调度处理:
Mono<String> mono2 = Mono.fromCallable(Util::service1)
.flatMap(ret1 -> Mono.fromCallable(() -> Util.service2(ret1))
.subscribeOn(Schedulers.newSingle("service2"))
); // service-1 和 service-2 之间的依赖关系
Mono<String> mono3 = Mono.fromCallable(Util::service3)
.subscribeOn(Schedulers.newSingle("service3")); // service-3 是一个单独的执行任务
Mono<String> ret4 = Flux.zip(mono2, mono3).single() // zip 方法将两个 publisher 合并到一起
.flatMap(tuple -> Mono.fromCallable( () -> Util.service4(tuple.getT1(), tuple.getT2()))); // 合并 service-1 和 service-3,并执行 service-4 的任务
System.out.println("=======================================");
AtomicLong start = new AtomicLong(), end = new AtomicLong();
ret4.doOnSubscribe(any -> start.set(System.currentTimeMillis()))
.doFinally(any -> {
end.set(System.currentTimeMillis());
System.out.println("take time: " + (end.get() - start.get()) + " ms");
System.exit(0);
})
.subscribe(System.out::println);
输出结果如下:

由于线程睡眠、唤醒以及上下文切换之间存在一定的开销,因此最终的执行时间会大于必要的串行执行的总和 \(1000ms + 1500ms + 500ms = 3000ms\)
参考:
[1] https://tech.io/playgrounds/929/reactive-programming-with-reactor-3/Intro
[2] https://www.baeldung.com/reactor-core
Reactor 简介的更多相关文章
- reactor官方文档译文(1)Reactor简介
原文地址:http://projectreactor.io/docs/reference/ Reactor简介 Reactor是一个基础库,用在构建实时数据流应用.要求有容错和低延迟至毫秒.纳秒.皮秒 ...
- JVM上的响应式流 — Reactor简介
强烈建议先阅读下JVM平台上的响应式流(Reactive Streams)规范,如果没读过的话. 官方文档:https://projectreactor.io/. 响应式编程 作为响应式编程方向上的第 ...
- 响应式编程简介之:Reactor
目录 简介 Reactor简介 reactive programming的发展史 Iterable-Iterator 和Publisher-Subscriber的区别 为什么要使用异步reactive ...
- Spring Boot集成Reactor事件处理框架的简单示例
1. Reactor简介 Reactor 是 Spring 社区发布的基于事件驱动的异步框架,不仅解耦了程序之间的强调用关系,而且有效提升了系统的多线程并发处理能力. 2. Spring Boot集成 ...
- Spring Reactor 入门与实践
适合阅读的人群:本文适合对 Spring.Netty 等框架,以及 Java 8 的 Lambda.Stream 等特性有基本认识,希望了解 Spring 5 的反应式编程特性的技术人员阅读. 一.前 ...
- Netty简介
Netty简介 Netty是由JBOSS提供的一个Java开源框架.Netty提供异步的.事件驱动的网络应用程序框架和工具,用以快速开发高性能.高可靠性的网络服务器和客户端程序.和传统BIO不同,NI ...
- libevent简介 构成
libevent简介 libevent是一个事件驱动的网络库,支持跨平台,如Linux, *BSD, MacOS X, Solaris, Windows.支持I/O多路复用,epoll.poll./d ...
- Reactor构架模式
http://www.cnblogs.com/hzbook/archive/2012/07/19/2599698.html Reactor框架是ACE各个框架中最基础的一个框架,其他框架都或多或少地用 ...
- JAVA NIO 简介(转)
1. 基本 概念 IO 是主存和外部设备 ( 硬盘.终端和网络等 ) 拷贝数据的过程. IO 是操作系统的底层功能实现,底层通过 I/O 指令进行完成. 所有语言运行时系统提供执行 I/O 较高级 ...
- 公布一个基于 Reactor 模式的 C++ 网络库
公布一个基于 Reactor 模式的 C++ 网络库 陈硕 (giantchen_AT_gmail) Blog.csdn.net/Solstice 2010 Aug 30 本文主要介绍 muduo 网 ...
随机推荐
- C#开源、功能强大、免费的Windows系统优化工具 - Optimizer
前言 今天给大家推荐一款由C#开源.功能强大.免费的Windows系统优化工具 - Optimizer. 工具介绍 Optimizer是一款功能强大的Windows系统优化工具,可帮助用户提高计算机性 ...
- DHCP是什么
DHCP 1. DHCP是什么 协议,一种应用层的网络协议,他可以动态地分配网络中的IP地址和其他网络配置的参数以及网络设备,通俗一点讲,每台设备的IP地址,子网掩码,网关等网络参数信息都是由他来完成 ...
- Django框架项目——BBS项目介绍、表设计、表创建同步、注册、登录功能、登录功能、首页搭建、admin、头像、图片防盗、个人站点、侧边栏筛选、文章的详情页、点赞点踩、评论、后台管理、添加文章、头像
文章目录 1 BBS项目介绍.表设计 项目开发流程 表设计 2 表创建同步.注册.登录功能 数据库表创建及同步 注册功能 登陆功能 3 登录功能.首页搭建.admin.头像.图片防盗.个人站点.侧边栏 ...
- struct 结构体【GO 基础】
〇.前言 虽然 Go 语言中没有"类"的概念,也不支持"类"的继承等面向对象的概念,但是可以通过结构体的内嵌,再配合接口,来实现面向对象,甚至具有更高的扩展性和 ...
- MIT协议原文及中文翻译
MIT协议原文及翻译 参考链接 原文: Copyright ( C ) Permission is hereby granted, free of charge, to any person obta ...
- 数据结构与算法(LeetCode)第一节:认识复杂度,对数器,二分法与异或运算
一.认识复杂度 1.评估算法优劣的核心指标: 时间复杂度:当完成了表达式的建立,只要把最高阶项留下即可.低阶项都去掉,高阶项的系数也去掉,记为O(去掉系数的高阶项): 时间复杂度是衡量算法流程的复 ...
- 解决 Error L6915E 问题
出现以下错误: Error: L6915E: Library reports error: The semihosting __user_initial_stackheap cannot reliab ...
- 可怕!.Net 8正式发布了,.Net野心确实不小!
随着三天.NET Conf 2023的会议结束了,.Net 8正式发布了. .Net 8是官方号称有史以来性能最快的一个版本了. .Net 8 增加了数以千计的性能.稳定性和安全性改进,以及平台和工具 ...
- 查看API官方文档
盛年不重来,一日难再晨.及时宜自勉,岁月不待人. 学习一门语言, 了解其开发文档必不可少.开发文档就是我们在编程开发.维护.升级过程中的参考最全面.最权威的资料.我认为就是开发者为后人方便理解留下 ...
- Oracle ADG容灾端部署Rman备份的一些实践经验
随着数据库中数据量的不断增加.业务的复杂性提高.各种政策颁布的系统容灾等级要求,数据库备份的工作及备份文件的有效性及备份文件的管理变得愈发重要.在Oracle数据库中提供了强大的备份和恢复工具,其中R ...