Swahili-text:华中大推出非洲语言场景文本检测和识别数据集 | ICDAR 2024
论文提出了一个专门针对斯瓦希里语自然场景文本检测和识别的数据集,这在当前研究中是一个未充分开发的语言领域。数据集包括
976张带标注的场景图像,可用于文本检测,以及8284张裁剪后的图像用于识别。来源:晓飞的算法工程笔记 公众号
论文: The First Swahili Language Scene Text Detection and Recognition Dataset

Introduction
如今,沟通很大程度上依赖于文本内容。文本是一种极为优秀的沟通方式,其影响力也能持续非常长的时间。场景文本广泛存在且包含着相当丰富的语义和信息,有助于理解现实世界。各种服务如报纸、医院、金融服务、保险和法律机构日益将大多数文档数字化以便实际应用。应用场景如汽车辅助、工业自动化、机器人导航、实时场景翻译、欺诈检测、图像检索、产品搜索等,这些都依赖于场景文本识别,并且这些应用每天都在不断进化和发展。现在,理解和解释图像中包含的文本内容变得至关重要。此外,文本无处不在,出现在许多关键的自然场景中:道路标志、广告、海报、街道、餐馆、商店等。
近年来,研究人员在挑战性场景中检测和识别文本的模型方面取得了显著进展,这些场景包括模糊图像、非传统背景、变化的光照条件、曲线文字或在恶劣环境中捕获的图像等。然而,大多数研究集中在英语和汉语等广泛使用的语言上,对资源有限地区如印度乡村和非洲的其他语言的关注和资源较少。因此,许多世界语言缺乏适当的数据集和量身定制的模型,这使得在这些语言中有效解决场景图像中文本检测和识别的挑战变得困难。
斯瓦希里语,又称基斯瓦希里语,是非洲大陆上使用最广泛的语言之一。超过1亿人口在包括坦桑尼亚、乌干达、刚果民主共和国、布隆迪和肯尼亚在内的多个非洲国家使用斯瓦希里语。该语言是坦桑尼亚和肯尼亚的官方语言,并广泛用于公共管理、教育和媒体领域。斯瓦希里语从阿拉伯语(约占40%)、波斯语、葡萄牙语、英语和德语等外语中借用了许多词汇。尽管如此,斯瓦希里语仍被归类为资源匮乏的语言之一,自然语言处理任务受到了注释数据稀缺的限制。
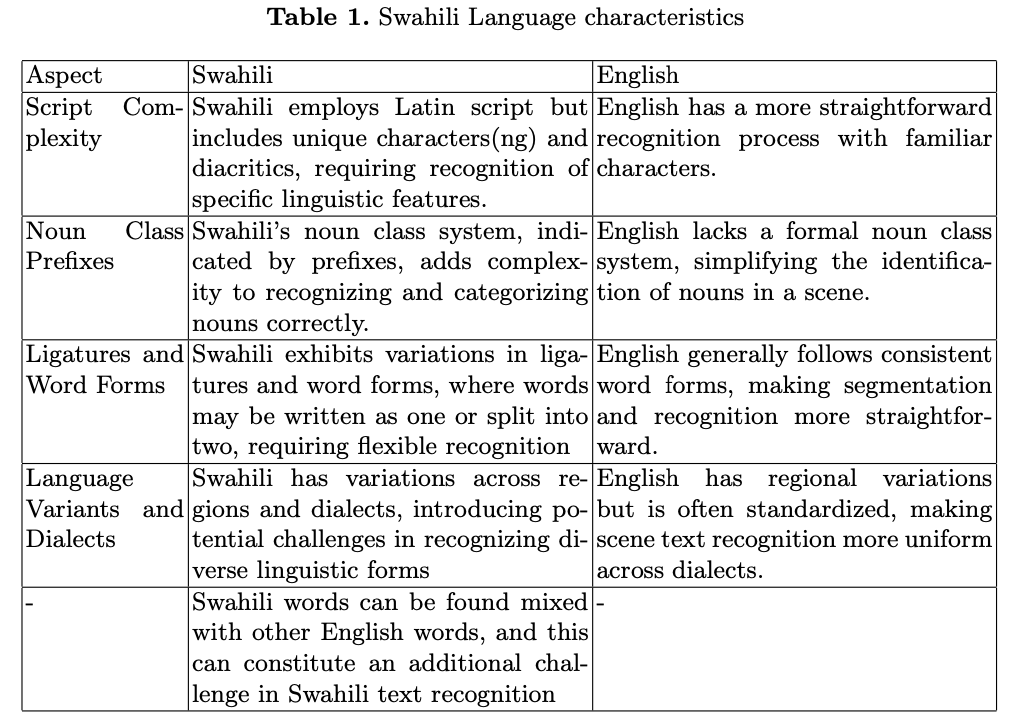
虽然斯瓦希里语使用拉丁字母表,但大多数涉及拉丁字母表的大型数据集主要集中在拥有不同语言特征的语言,比如英语。缺乏关注导致了斯瓦希里语,这种被数百万人使用的语言,没有专门的资源来优化和微调文本检测和识别模型以适应其独特的特征。表1列出了该语言与英语相比的一些特征。
本文的主要目标是为斯瓦希里语开发一个全面的场景文本数据集:Swahili-text。这个图像集合旨在满足专门数据集的需求,为评估现有模型提供基准,并帮助研究社区开发斯瓦希里语场景文本检测和识别的新的最先进方法。Swahili-text包含976张图片,大部分来自坦桑尼亚的城市,其他来自社交媒体。这些图片包括商店标签、广告横幅、海报和街道名称。每张图片在单词级别上都进行了手动注释。据作者所知,Swahili-Text是第一个专为斯瓦希里语场景文本检测和识别开发的全面数据集。
Related work
Swahili Language Datasets for Natural Language Processing
斯瓦希里语仍然被归类为资源匮乏的语言。由于注释数据稀缺,自然语言处理任务受到了限制。然而,随着深度学习和语言模型的发展,许多数据集开始对语言建模任务提供越来越多的支持。其中,Helsinki数据集是最常用的数据集之一,专门用于斯瓦希里语的语言研究。该数据集提供了未注释和已注释版本的斯瓦希里语文本集合。该数据集旨在支持语言分析、语料库语言学以及与斯瓦希里语自然语言处理任务相关的各种研究工作。
Gelas等人开发了一个用于语言建模任务的注释数据集。该数据集包含来自不同斯瓦希里语在线媒体平台的句子,涵盖了体育、一般新闻、家庭、政治和宗教等多个领域的句子。总共有512,000个独特单词。Shikali等人将该数据集与斯瓦希里语音节字母表结合,并改编了Mikolov等人提出的英语词类比数据集。Barack W等人开发了Kencorpus斯瓦希里语问答数据集(KenSwQuAD),旨在应对低资源语言,特别是斯瓦希里语中问答数据集的稀缺性,增强机器对自然语言的理解能力,应用于斯瓦希里语言者的互联网搜索和对话系统等任务。Alexander R等人则关注低资源语言(如斯瓦希里语)中语音数据集的缺乏,特别是口语数字识别领域。该研究开发了一个斯瓦希里语口语数字数据集,并研究了跨语言和多语言预训练方法对口头数字识别的影响。
这些数据集旨在促进斯瓦希里语言建模和自然语言处理任务的研究,然而在场景文本检测和识别任务中,目前还不存在一个全面的用于斯瓦希里语注释场景文本图像的数据集。
Latin Script Scene Text Datasets
场景文本识别领域受到标准数据集的影响,这些数据集使研究人员能够节省大量时间和精力来收集和注释数据。与拉丁字母场景文本识别相关的流行数据集有以下:
ICDAR数据集在文档分析和识别领域非常流行。ICDAR 2013数据集包含462张高分辨率的自然场景图像,如户外场景、标志和海报。该数据集引入了多方向文本、不同光照条件以及混合字体和文字大小的挑战,以促进强大的文本识别算法的发展。ICDAR 2015偶发场景文本数据集包含通过Google Glass捕捉的1,670张图像。该数据集包括具有非传统文本形状、曲线文本和不同语言文本的偶发场景文本。Total-text数据集针对多方向和曲线文本问题提出。它包含具有不同方向文本的图像,主要是曲线文本。MSRA-TD500数据集结合了英文和中文词汇,也非常受欢迎。它包含来自实际场景的500张任意方向的图像,并以句子级别进行了注释。除了拉丁字母脚本的数据集外,还提出了多语言场景文本识别的几个多语言数据集。
然而,大多数这些数据集并不包括斯瓦希里语。据知,目前尚未创建用于斯瓦希里语场景文本检测和识别的公共数据集。虽然一些用于英语的数据集可以用来,因为它们使用相同的字母表,但它们并不像一个专门针对斯瓦希里语的数据集那样有效。
Scene Text Detection and Recognition Methods
深度学习技术的爆炸性发展显著影响了场景文本检测和识别领域,为场景文本检测和识别打开了全新的可能性,能够从文本图像中提取更强大和具有区分性的特征。
文本检测和文本识别可以看作是两个独立的任务。在文本检测阶段,其目标是识别并标记输入图像中存在文本的区域。存在三种主要的方法:基于回归、基于部分和基于分割的方法。基于回归的方法直接回归边界框。通过将文本检测转化为回归问题,模型学习估计文本实例的空间分布,这使其非常适合需要精确定位文本区域的场景。基于部分的方法识别并将文本部分与单词边界框关联起来。基于分割的方法结合像素级预测和后处理技术,利用语义分割和基于MSER的算法等技术检测文本实例。
文本识别涉及将检测到的文本区域转换为字符实例,主要有两种方法:connectionist temporal classification(CTC)模型和注意力机制模型。CTC模型使用递归神经网络计算基于单帧预测的标签序列的条件概率,该过程包括三个重要步骤:使用卷积网络从文本区域提取特征、使用递归神经网络在每帧预测标签分布以及后处理步骤将每帧的预测转换为最终的标签序列。
注意力机制在计算机视觉领域,包括场景文本识别中,取得了显著的成果。注意力机制专注于输入的相关部分,从而在复杂或变化的环境中实现更精确的字符识别。这种方法利用编码结构从文本区域提取特征向量,并利用解码结构生成字符实例。肖等人解决了注意力机制产生无关信息的问题,并提出了一种评估注意力结果与查询之间相关性的方法。通过将Attention on Attention(AoA)机制整合到文本识别框架中,可以消除无关的注意力,从而提高文本识别的准确性。
尽管在场景文本检测和识别方面取得了显著进展,但标注训练数据的不足仍然是一个障碍。深度学习算法在泛化到现实世界场景时受到大规模数据集稀缺的限制,尤其是对于低资源语言或尚未研究的语言,包括带有标注的场景文本图像的数据集。
Swahili Text Dataset
Dataset Description
斯瓦希里语场景文本检测和识别数据集包含976张自然场景图像,数据来源多样。这些数据由专注于计算机视觉和自然语言处理的研究人员以及斯瓦希里语母语者收集。图像来源广泛,包括互联网资源和在坦桑尼亚城市使用手机相机直接拍摄的图像。这确保了从斯瓦希里语使用地区获得了具有代表性的场景集合。
为确保收集到的图像准确性和相关性,实施了严格的质量控制措施,并特别注意消除光照不均和模糊的图像。该数据集经历了预处理步骤,以移除具有不良质量属性的图像,并对具有不完整数据的实例进行了修正或排除,以维护数据的完整性。数据集中的每个图像都以JPEG格式存储。
斯瓦希里语文本数据集包含描绘自然场景的图像,其中包含斯瓦希里语文本元素,如街道标志、街道名称、广告、商店名称、横幅和其他常见于斯瓦希里语使用地区的标识物。为了便于场景文本检测和识别任务,数据集已进行标注,标注过程由领域专家进行,以确保对文本区域的准确注释。

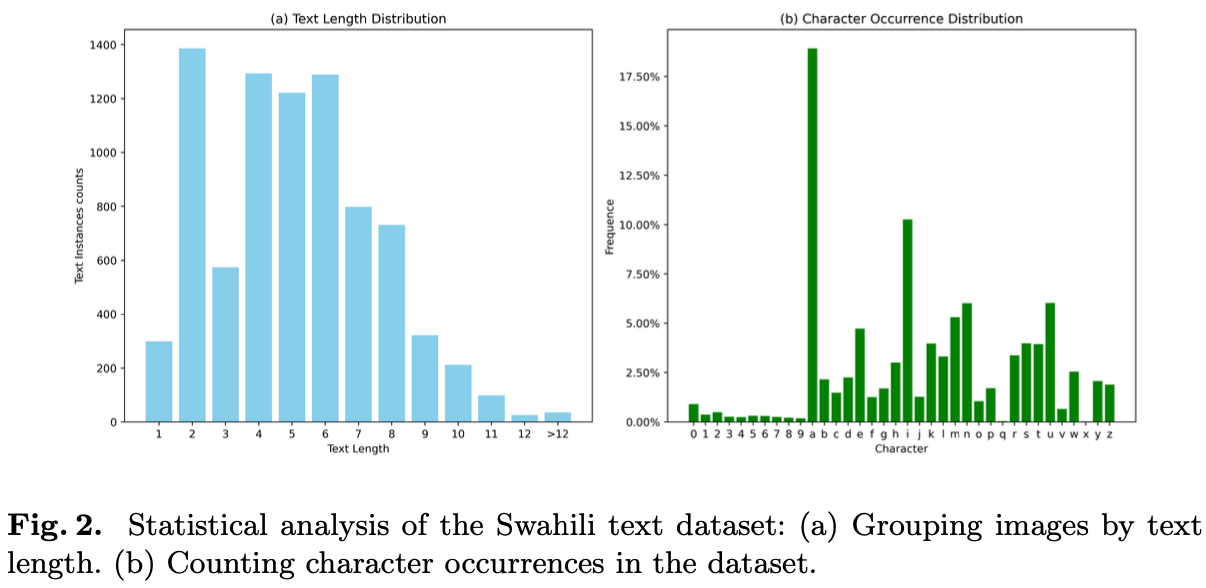
图1展示了数据集中包含的部分图像。用于识别任务,数据集中的图像已裁剪为8284张图像。图2展示了斯瓦希里语文本裁剪图像的统计数据,包括按文本长度分组的图像数量和字符出现的分布情况。
Annotation
为确保文本检测和识别的准确性,并评估系统的性能,准确的文本实例注释至关重要。因此,斯瓦希里语文本数据集采用了细致的手动注释方法。每个图像中的每个文本区域都用单个边界框进行注释,以确保在处理斯瓦希里语文本的各种形状和位置时能够准确地标注。

每个图像的文本实例注释被收集到一个单独的文件中。该文件包含单词的边界框坐标和相应的文本转录。边界框是一个具有n个点的多边形,每个点都有水平位置x1和垂直位置y1的坐标。不可读的文本实例仅用边界框标记,以便于检测但不参与文本的识别。图3展示了一个带有注释的示例图像。
Experiments
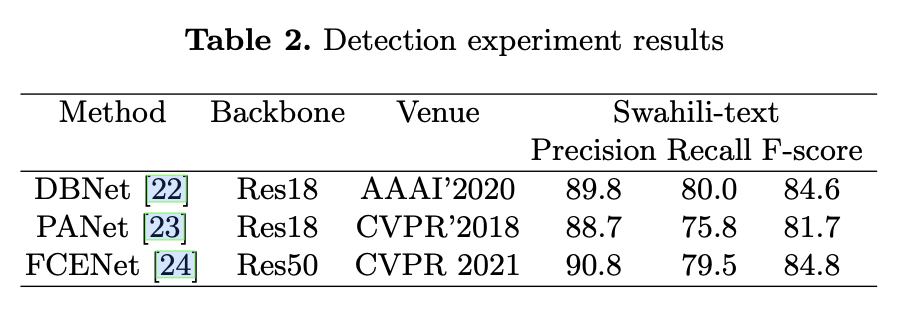
Text Detection Experiment

Text Recognition Experiment

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

Swahili-text:华中大推出非洲语言场景文本检测和识别数据集 | ICDAR 2024的更多相关文章
- OpenCV_contrib里的Text(自然场景图像中的文本检测与识别)
平台:win10 x64 +VS 2015专业版 +opencv-3.x.+CMake 待解决!!!Issue说明:最近做一些字符识别的事情,想试一下opencv_contrib里的Text(自然场景 ...
- Scene Text Detection(场景文本检测)论文思路总结
任意角度的场景文本检测论文思路总结共同点:重新添加分支的创新更突出场景文本检测基于分割的检测方法 spcnet(mask_rcnn+tcm+rescore) psenet(渐进扩展) mask tex ...
- EAST 自然场景文本检测
自然场景文本检测是图像处理的核心模块,也是一直想要接触的一个方面. 刚好看到国内的旷视今年在CVPR2017的一篇文章:EAST: An Efficient and Accurate S ...
- 【OCR技术系列之五】自然场景文本检测技术综述(CTPN, SegLink, EAST)
文字识别分为两个具体步骤:文字的检测和文字的识别,两者缺一不可,尤其是文字检测,是识别的前提条件,若文字都找不到,那何谈文字识别.今天我们首先来谈一下当今流行的文字检测技术有哪些. 文本检测不是一件简 ...
- Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network(利用像素聚合网络进行高效准确的任意形状文本检测)
PSENet V2昨日刚出,今天翻译学习一下. 场景文本检测是场景文本阅读系统的重要一步,随着卷积神经网络的快速发展,场景文字检测也取得了巨大的进步.尽管如此,仍存在两个主要挑战,它们阻碍文字检测部署 ...
- 使用Keras基于AdvancedEAST的场景图像文本检测
Blog:https://blog.csdn.net/linchuhai/article/details/84677249 GitHub:https://github.com/huoyijie/Adv ...
- CVPR2020论文解读:OCR场景文本识别
CVPR2020论文解读:OCR场景文本识别 ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network∗ 论文 ...
- Golang优秀开源项目汇总, 10大流行Go语言开源项目, golang 开源项目全集(golang/go/wiki/Projects), GitHub上优秀的Go开源项目
Golang优秀开源项目汇总(持续更新...)我把这个汇总放在github上了, 后面更新也会在github上更新. https://github.com/hackstoic/golang-open- ...
- HTML:Hyper Text Markup Language 超文本标记语言
1.HTML是什么? *Hyper Text Markup Language 超文本标记语言 *Hyper Text:超链接.把不同空间的资源,整合在一起,形成逻辑上的网状结构. *Markup La ...
- 【.Net】 大文件可使用的文本分组统计工具(附带源码,原创)
本工具可实现的效果: 1.读取大文件(大于1GB) 2.根据分隔符分割后的列分组 3.速度快. 4.处理过程中,可以随时停止处理,操作不卡死. 5.有对当前内存的实时监测,避免过多占用内存,影响系统运 ...
随机推荐
- FM20S用户手册-Linux开发环境搭建
- NXP i.MX 8M Mini开发板规格书(四核ARM Cortex-A53 + 单核ARM Cortex-M4,主频1.6GHz)
1 评估板简介 创龙科技TLIMX8-EVM是一款基于NXP i.MX 8M Mini的四核ARM Cortex-A53 + 单核ARM Cortex-M4异构多核处理器设计的高性能评估板,由核心板和 ...
- python 转换PDF 到 EPS
from win32com.client.dynamic import ERRORS_BAD_CONTEXT as ebc from win32com.client import DispatchEx ...
- python subprocess读取终端输出内容
参考链接:https://www.cnblogs.com/songzhenhua/p/9312718.html https://www.cnblogs.com/darkchii/p/9013673.h ...
- windows内置账户
参考文献: http://www.cnblogs.com/xianspace/archive/2009/04/05/1429835.html 转载自: https://www.cnblogs.com/ ...
- 1.1 第一个hello程序
还记得在每一个编程平台上的第一个程序都是hello world,现在就以这个程序为载体,先浅聊一下计算机系统吧. 1.预处理阶段,预处理器cpp根据字符#开头的命令修改原始的程序,并把头文件里的内容直 ...
- 操作系统|SPOOLing(假脱机)技术
什么是假脱机技术,它可以解决什么问题? 什么是脱机技术 要回答什么是假脱机技术,首先我们需要知道什么是脱机技术.<计算机操作系统(第四版)>写道: 为了解决人机矛盾及CPU和I/O设备之间 ...
- [oeasy]python0037_终端_terminal_电传打字机_tty_shell_控制台_console_发展历史
换行回车 回忆上次内容 换行 和 回车 是两回事 换行 对应字节0x0A Line-Feed 水平 不动 垂直 向上喂纸 所以是 feed 回车 对应字节0x0D Carriage-Return 垂直 ...
- oeasy教您玩转vim - 44 - # 综合练习
综合练习 回忆上节课内容 上次我们学到了各种的替换模式 r,替换当前光标的字符 R,进入替换模式 ~,改变大小写 这次来个综合练习吧! 我们这次要完成这样一个任务 我们有的时候需要写日志 Syst ...
- 第八节 JMeter基础-高级登录【数据库数据驱动】
声明:本文所记录的仅本次操作学习到的知识点,其中商城IP错误,请自行更改. 背景:获取数据库用户表中的数据进行登录接口测试.思路: 引用jar包[测试计划]. 设置数据库的连接信息,取变量名db1-- ...