Redis全文搜索教程之创建索引并关联源数据
Redis 全文搜索是依赖于 Redis 官方提供的 RediSearch 来实现的。RediSearch 提供了一种简单快速的方法对 hash 或者 json 类型数据的任何字段建立二级索引,然后就可以对被索引的 hash 或者 json 类型数据字段进行搜索和聚合操作。
这里我们把被索引的 hash 或者 json 类型数据叫做源数据。
本文大纲如下,
使用体验
简单场景下,用 RediSearch 来平替 Elasticsearch 的使用场景已经足够。像是 Elasticsearch 中常用的查询语法 AND 、OR 、IN 、NOT IN 、> 、< 、= 、like 等,在 RediSearch 中都是支持的。
此外 RediSearch 还支持聚合统计、停用词、文本标记和转义、同义词、标签、排序、向量查询、中文分词等。
就我个人来说,个人项目使用 RediSearch 作为全文搜索引擎已经够用了,它有占用内存低、索引建立快、查询数据性能足够高等优点。
后续发展
就目前官方对 RediSearch 的支持更新来看,
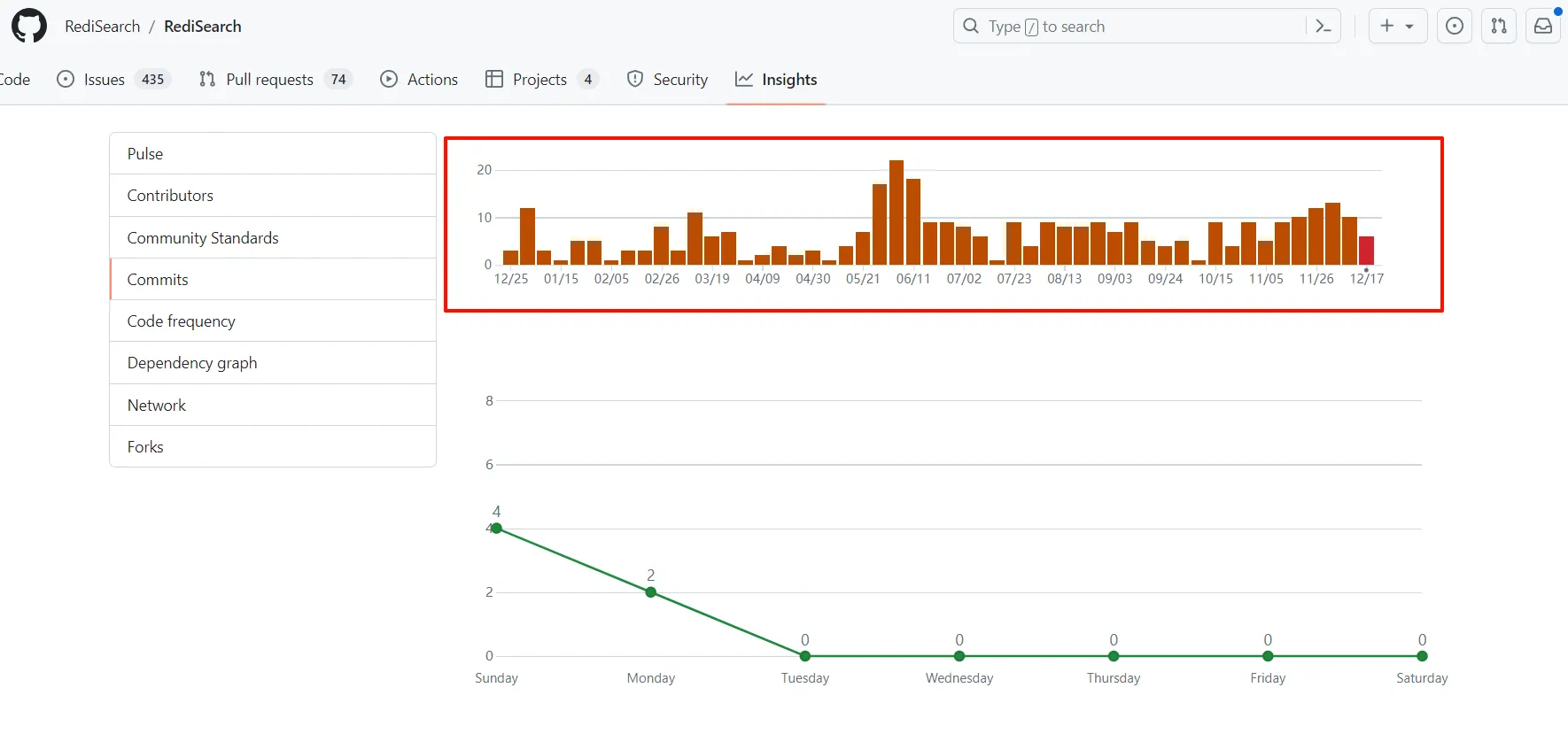
最近一次提交记录在 12 月 17 号。
可以看到 RediSearch 的更新频率还是比较高的,而且是官方支持做的模块,不用担心后续无人维护。
虽然 Redis 天生支持分布式集群,但是 RediSearch 对 Redis 集群的支持还不完善,引用官方说明,
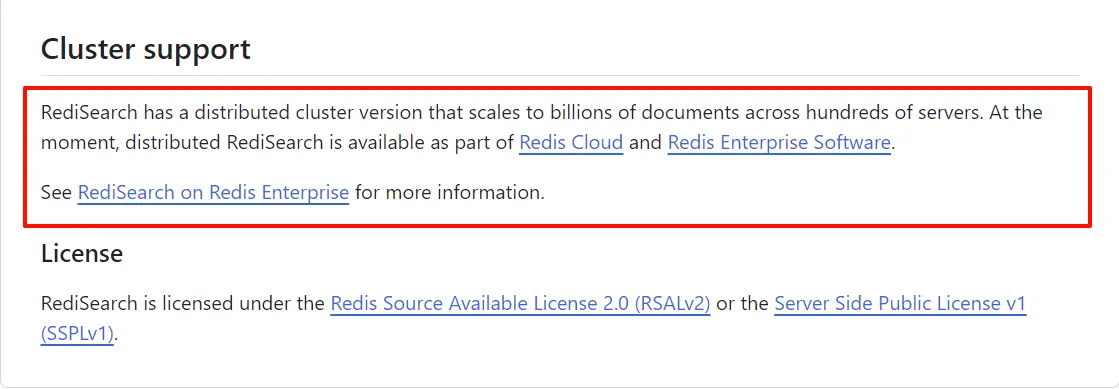
官方针对 RediSearch 的集群支持问题,提供了一个 RediSearch 集群版本,但是这个版本只能在 Redis 企业版或者 Redis Cloud 上能使用,开源版还没有,这一点需要告诉大家。
遇到 bug
首先在使用 RediSearch 的过程中,遇到了 bug 并发现 bug 来源于 RediSearch,不要慌,也不要抱怨难用, 毕竟是开源项目,
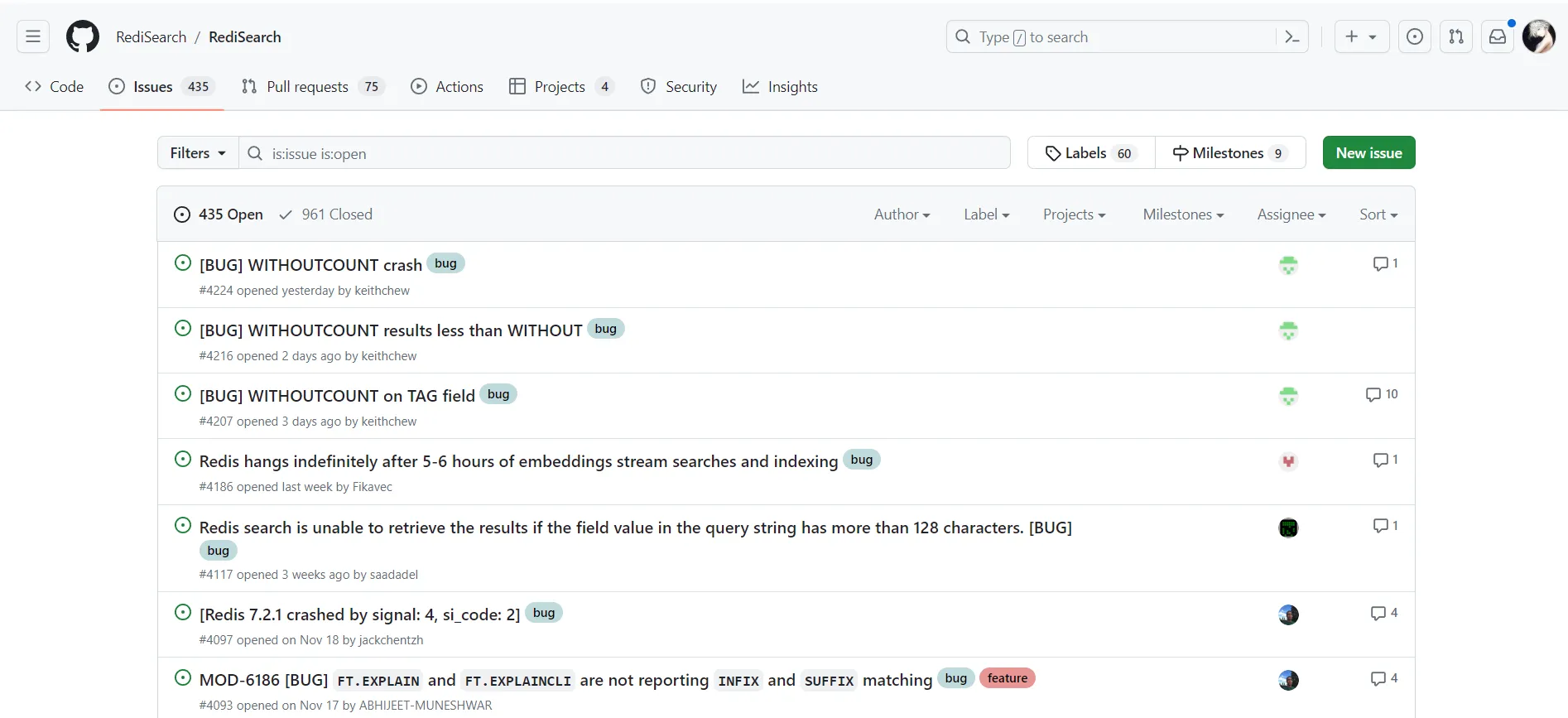
大家可以看到 issue 列表中有很多 bug 没有解决。
不过本着开源共进的精神,希望大家发现了 bug 后,第一时间在 RediSearch 官方 github 上提个 issue,方便官方发现并解决问题。
RediSearch Github 仓库地址:https://github.com/RediSearch/RediSearch
下面我给大家用 newbee-mall-pro 项目作为样本,给大家介绍下如何创建一个索引并关联源数据。
newbee-mall-pro 项目地址:https://github.com/wayn111/newbee-mall-pro
添加源数据
在 newbee-mall-pro 项目中,已经将商品数据以 hash 类型存入了 Redis 中,
其中,我们对于 key 名称的定义规则是按照 newbee_mall:goods: + 商品ID。
这里我们的 key 名称定义规则很重要,RediSearch 创建索引会基于 key 名称前缀来生成。
hash 类型的 value 包含属性如下,
goodsId: 商品 ID,唯一属性,由数据库商品表主键生成goodsName: 商品名称goodsIntro: 商品简介goodsCategoryId: 商品分类 ID,唯一属性,由数据库商品分类表主键生成goodsSellStatus: 商品上架状态,0 代表下架,1 代表上架sellingPrice: 商品售价originalPrice: 商品原价tag: 商品标签
在 newbee-mall-pro 中,添加源数据的方法已经写好了,代码逻辑在 JedisSearch.addGoodsListIndex() 方法里,
public boolean addGoodsListIndex(String keyPrefix, List<Goods> list) {
int chunk = 200;
List<List<Goods>> partition = ListUtil.partition(list, chunk);
AbstractPipeline pipelined = client.pipelined();
for (List<Goods> goodsList : partition) {
for (Goods goods : goodsList) {
RsGoodsDTO target = new RsGoodsDTO();
MyBeanUtil.copyProperties(goods, target);
Map<String, String> hash = MyBeanUtil.toMap(target);
// 支持中文
hash.put("_language", Constants.GOODS_IDX_LANGUAGE);
pipelined.hset(keyPrefix + goods.getGoodsId(), hash);
}
}
pipelined.sync();
return true;
}
上诉代码中,其实就是把 list 商品列表以 hash 类型的数据结构写进 Redis 中,并且为了加快写入速度,使用了 Redis 提供的管道操作。
需要注意的就是 hash 类型中新增了一个 _language 字段,用于指定 RediSearch 对于源数据关联的索引,要使用中文分词查询。
建立索引
RediSearch 通过提供一种简单且自动的方式在 Redis hash 类型数据结构上创建二级索引,并且内部极大地简化了这一过程。(最终会出现更多数据结构)
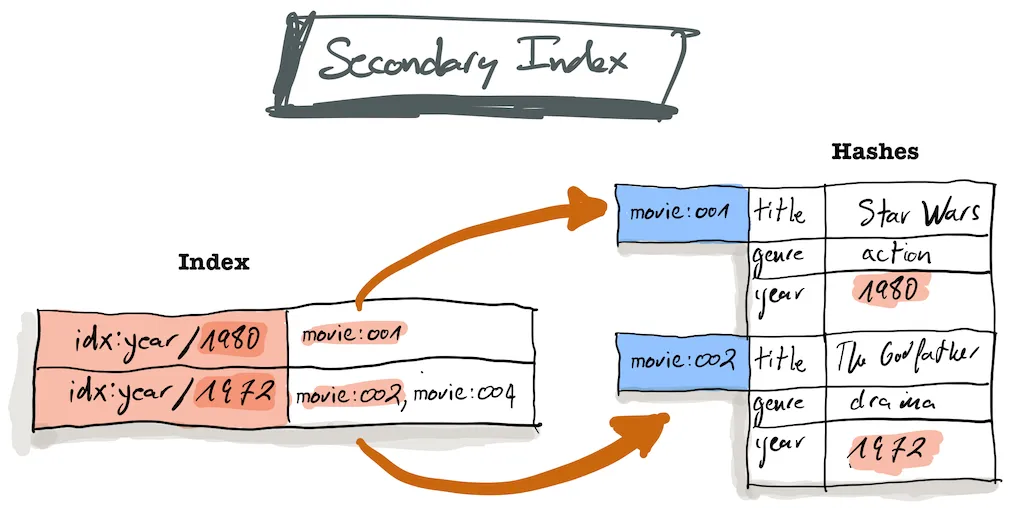
如果我们要使用 RediSearch 查询商品 hash 结构里的 goodsName 字段,那么必须要对该字段建立索引。
Jedis 新建索引
所以这里,我给大家介绍下在 newbee-mall-pro 项目中,是如何建立索引的,代码逻辑在 GoodsServiceImpl.syncRs() 方法中,
// 定义索引结构
public boolean syncRs() {
jedisSearch.dropIndex("idx:goods");
Schema schema = new Schema()
.addSortableTextField("goodsName", 1.0)
.addSortableTextField("goodsIntro", 0.5)
.addSortableNumericField("goodsId")
.addSortableNumericField("goodsCategoryId")
.addSortableNumericField("goodsSellStatus")
.addSortableNumericField("sellingPrice")
.addSortableNumericField("originalPrice")
.addSortableTagField("tag", "|");
jedisSearch.createIndex(Constants.GOODS_IDX_NAME, Constants.GOODS_IDX_PREFIX, schema);
}
上述代码中,我们对商品 hash 结构里的下方字段都建立了索引。
goodsName:文本类型,可排序,设置权重为 1.0goodsIntro:文本类型,可排序,设置权重为 0.5goodsId:数字类型,可排序goodsCategoryId:数字类型,可排序goodsSellStatus:数字类型,可排序sellingPrice:数字类型,可排序originalPrice:数字类型,可排序tag:标签类型,可排序,设置分隔符为字符串|
在 RediSerach 中可以添加的字段类型有 text、numberic、tag 等,可以设置是否排序。
并且还可以设置权重系数,表示该字段已加权。这对于在搜索操作期间为特定字段分配不同的重要性级别非常有用,通常就是在条件筛选完成后的打分排序阶段用于提升或者降低排名。
Redis 中的新建索引语法
当我们把上面的 Jedis 新建索引的代码转换为 Redis 中的语法后,如下
> FT.CREATE idx:goods ON hash PREFIX 1 "newbeemall:goods:" \
SCHEMA goodsName TEXT SORTABLE WEIGHT 1.0 \
SCHEMA goodsIntro TEXT SORTABLE WEIGHT 0.5 \
goodsId NUMERIC SORTABLE \
goodsCategoryId NUMERIC SORTABLE \
goodsSellStatus NUMERIC SORTABLE \
sellingPrice NUMERIC SORTABLE \
originalPrice NUMERIC SORTABLE \
tag TAG SORTABLE SEPARATOR "|"
现在我给大家详细介绍下这条命令:
FT.CREATE:RediSearch 中索引创建语法。idx:goods:指定索引名称,索引名称将在所有键名称中使用,因此请保持简短。ON hash:指定索引关联的结构类型。需要注意的是,在 RediSearch 2.0 中仅支持哈希结构,随着 RediSearch 更新,后续有望支持更多数据结构。PREFIX 1 "newbeemall:goods:":指定索引的关联源数据的 key 前缀,可以指定多个前缀。SCHEMA ...:字段定义,用于定义字段名称、类型、是否排序、权重等。可以定义多个字段。
如果你想了解更多关于 ft.search 的语法以及字段定义相关的只是,可以打开官方文档,
https://redis.io/docs/interact/search-and-query/basic-constructs/schema-definition
Redis 中查询索引定义
在 RediSearch 中要查询已经存在的索引详情也是很简单的,官方提供了 ft.info 索引名称 的语法,用来打印索引详情。
> FT.INFO idx:goods
最后聊两句
本文给大家用我的开源项目 newbee-mall-pro 作为样本,给大家细致的介绍了一番 RediSearch 在项目实战中关于索引创建与关联源数据的用法,希望大家喜欢。
关注公众号【waynblog】每周分享技术干货、开源项目、实战经验、国外优质文章翻译等,您的关注将是我的更新动力!
Redis全文搜索教程之创建索引并关联源数据的更多相关文章
- lucene全文搜索之四:创建索引搜索器、6种文档搜索器实现以及搜索结果分析(结合IKAnalyzer分词器的搜索器)基于lucene5.5.3
前言: 前面几章已经很详细的讲解了如何创建索引器对索引进行增删查(没有更新操作).如何管理索引目录以及如何使用分词器,上一章讲解了如何生成索引字段和创建索引文档,并把创建的索引文档保存到索引目录,到这 ...
- lucene全文搜索之三:生成索引字段,创建索引文档(给索引字段加权)基于lucene5.5.3
前言:上一章中我们已经实现了索引器的创建,但是我们没有索引文档,本章将会讲解如何生成字段.创建索引文档,给字段加权以及保存文档到索引器目录 luncene5.5.3集合jar包下载地址:http:// ...
- 项目之solr全文搜索工具之创建项目索引库
以创建项目baotao core为例 1. 在example目录下创建baotao-solr文件夹: 2. 将./solr下的solr.xml拷贝到baotao-solr目录下: 3. 在bao ...
- lucene全文搜索之一:lucene的主要功能和基本结构(基于lucene5.5.3)
前言:lucene并不是像solr或elastic那样提供现成的.直接部署可用的系统,而是一套jar包,提供了一些常见语言分词.构建索引和创建搜索器等等功能的API,我们常用到的也就是分词器.索引目录 ...
- lucene全文搜索之二:创建索引器(创建IKAnalyzer分词器和索引目录管理)基于lucene5.5.3
前言: lucene全文搜索之一中讲解了lucene开发搜索服务的基本结构,本章将会讲解如何创建索引器.管理索引目录和中文分词器的使用. 包括标准分词器,IKAnalyzer分词器以及两种索引目录的创 ...
- C# 全文搜索Lucene
全文出自:https://blog.csdn.net/huangwenhua5000/article/details/9341751 1 lucene简介1.1 什么是luceneLucene是一个全 ...
- Lucene.net 从创建索引到搜索的代码范例
关于Lucene.Net的介绍网上已经很多了在这里就不多介绍Lucene.Net主要分为建立索引,维护索引和搜索索引Field.Store的作用是通过全文检查就能返回对应的内容,而不必再通过id去DB ...
- Flask 教程 第十六章:全文搜索
本文翻译自The Flask Mega-Tutorial Part XVI: Full-Text Search 这是Flask Mega-Tutorial系列的第十六部分,我将在其中为Microblo ...
- 搜索引擎系列 ---lucene简介 创建索引和搜索初步
一.什么是Lucene? Lucene最初是由Doug Cutting开发的,2000年3月,发布第一个版本,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎 :Lucene得名于Doug妻子 ...
- OSChina 的全文搜索设计说明 —— 索引过程
http://www.oschina.net/question/12_71591 言: OSChina 的搜索做得并不好,很久之前一直想在细节方面进行改造,一直也没什么好的思路.但作为整体的结构或许对 ...
随机推荐
- 简单了解PyCharm
简单了解PyCharm PyCharm的简单使用 修改主题 1 2 切换解释器 1 如何创建pythin文件 1 2 3 4 注释语法 行注释 这里是注释 块注释 '''这里是注释''' 常量和变量的 ...
- Jenkins 忘记密码|密码重置
I. 当前环境 OS Version : AlmaLinux release 8.8 Jenkins Version : 2.414.1 II. 操作步骤 2.1 修改配置文件 1. SSH 登录服务 ...
- python入门基础(13)--类、对象
面向过程的编程语言,如C语言,所使用的数据和函数之间是没有任何直接联系的,它们之间是通过函数调用提供参数的形式将数据传入函数进行处理. 但可能因为错误的传递参数.错误地修改了数据而导致程序出错,甚至是 ...
- ArcGIS将遥感影像的0值设置为NoData
本文介绍在ArcMap软件中,将栅格图层中的0值或其他指定数值作为NoData值的方法. 在处理栅格图像时,有时会发现如下图所示的情况--我们对某一个区域的栅格数据进行分类着色后,其周边区域( ...
- MySQL实战实战系列 07 行锁功过:怎么减少行锁对性能的影响?
在上一篇文章中,我跟你介绍了 MySQL 的全局锁和表级锁,今天我们就来讲讲 MySQL 的行锁. MySQL 的行锁是在引擎层由各个引擎自己实现的.但并不是所有的引擎都支持行锁,比如 MyISAM ...
- linux常见命令(四)
用于查看日期和时间的相关命令 cal date hwclock cal:显示日历信息 命令语音:cal [选项] [[[日]月]年] 选项 选项含义 -j 显示出给定月中的每一天是一年总的第几天(从1 ...
- 第七单元《中国传统文化与管理》单元测试 mooc
第七单元<中国传统文化与管理>单元测试 返回 本次得分为:8.00/10.00, 本次测试的提交时间为:2020-08-30, 如果你认为本次测试成绩不理想,你可以选择 再做一次 . 1 ...
- jmeter的全局变量(将登陆token设置全局)
1.首先调用登陆接口,用json提取器,取出响应内的token值 2.在beanshell取样器中设置全局变量 //设置全局变量方法一:用函数__setProperty设置${__setProper ...
- Ubuntu上解决快捷键与idea快捷键冲突
Ubuntu上解决快捷键与idea快捷键冲突 一.ubuntu 本身系统导致,需要修改 ubuntu 快捷键 解决方案: 设置 按钮→系统设置→硬件选项区域中的"键盘"→切换到&q ...
- z函数|exkmp|拓展kmp 笔记+图解
题外话,我找个什么时间把kmp也加一下图解 z函数|exkmp 别担心 这个exkmp和kmp没毛点关系,请放心食用. 本文下标以1开始,为什么?因为1开始就不需要进行长度和下标的转换,长度即下标. ...