04 elasticsearch学习笔记-Rest风格说明
Rest风格说明
Rest风格说明

| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有的数据 |
关于文档的基本操作
添加数据PUT
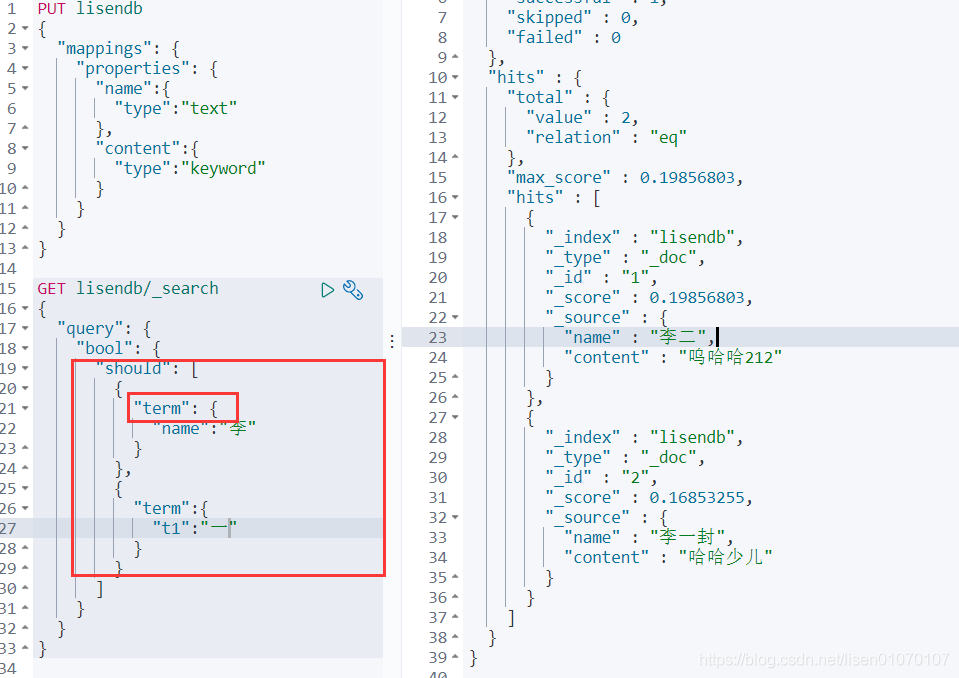
PUT /haima/user/1
{
"name":"狂神说123",
"age":13,
"desc":"我是描述",
"tags":["技术宅","温暖","直男"]
}
返回数据
#! Deprecation: [types removal] Specifying types in document get requests is deprecated, use the /{index}/_doc/{id} endpoint instead.
{
"_index" : "haima",
"_type" : "user",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 7,
"found" : true,
"_source" : {
"name" : "狂神说123",
"age" : 13,
"desc" : "我是描述",
"tags" : [
"技术宅",
"温暖",
"直男"
]
}
}
查询
最简单的搜索是GET
GET /haima/user/1
返回数据
#! Deprecation: [types removal] Specifying types in document get requests is deprecated, use the /{index}/_doc/{id} endpoint instead.
{
"_index" : "haima",
"_type" : "user",
"_id" : "1",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 7,
"found" : true,
"_source" : {
"name" : "狂神说123",
"age" : 13,
"desc" : "我是描述",
"tags" : [
"技术宅",
"温暖",
"直男"
]
}
}
多添加几条数据
PUT /haima/user/2
{
"name":"张三说",
"age":22,
"desc":"我是描述22",
"tags":["技术宅","温暖","直男"]
}
PUT /haima/user/3
{
"name":"李四说",
"age":33,
"desc":"我是描述33",
"tags":["技术宅","温暖","直男"]
}
PUT /haima/user/4
{
"name":"王五说",
"age":44,
"desc":"我是描述44",
"tags":["技术宅","温暖","直男"]
}
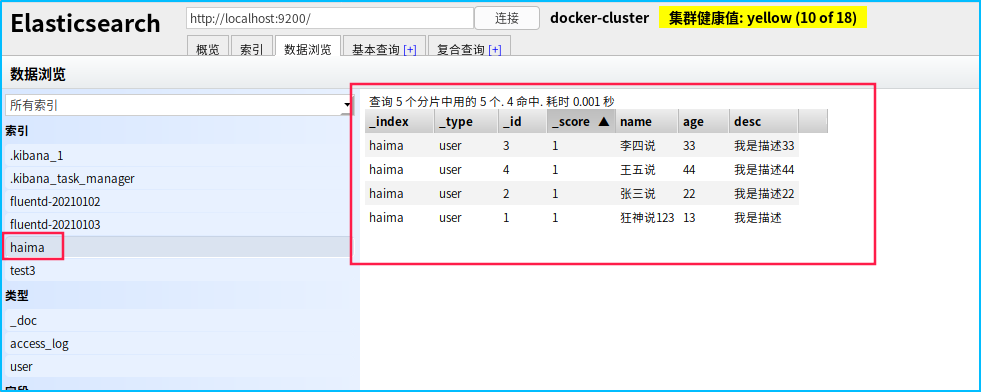
- 搜索功能search
GET /haima/user/_search?q=name:李四

这边name是text 所以做了分词的查询 如果是keyword就不会分词搜索了
- 复杂操作搜索select(排序,分页,高亮,模糊查询,精准查询)
//测试只能一个字段查询
GET lisen/user/_search
{
"query": {
"match": {
"name": "李森"
}
}
}
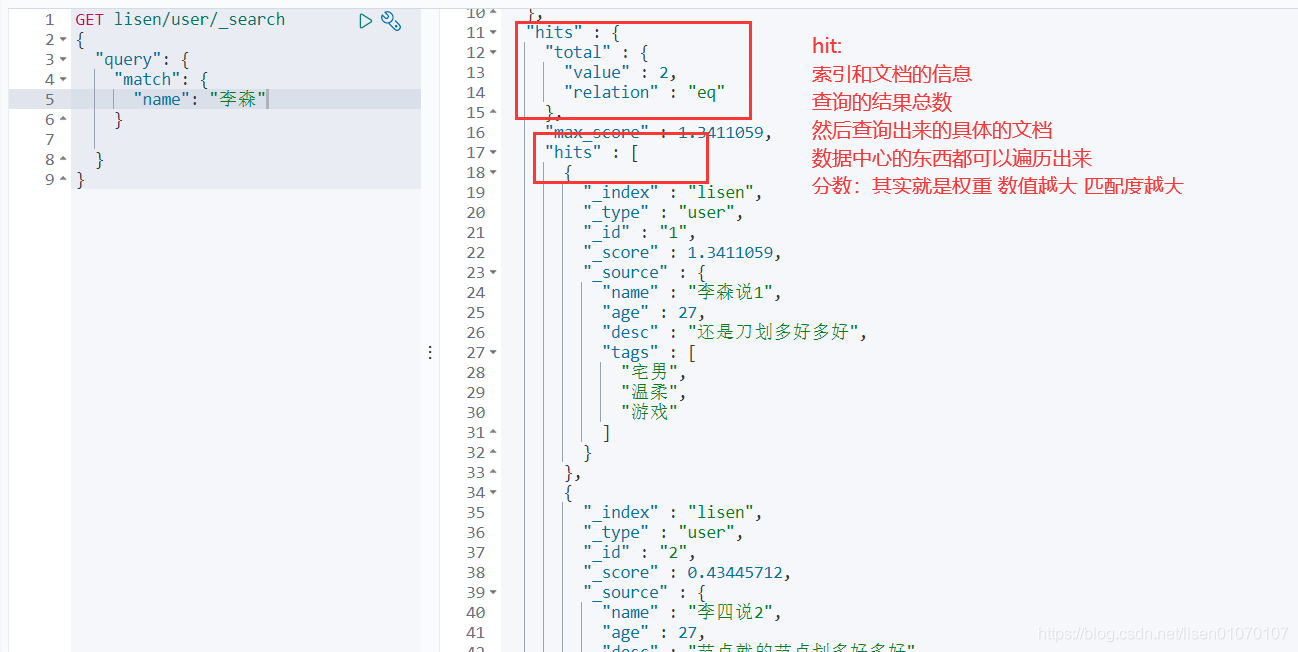
结果过滤,就是只展示列表中某些字段
GET /haima/user/_search
{
"query": {
"match": {
"name": "李四"
}
},
"_source":["name","age"]
}
字符串包涵 或者查询
es里存的数据为字符串
c_other_tags:"70,80,90"
c_other_tags包涵"70," || c_other_tags包涵"70," || c_other_tags包涵"*,70" || c_other_tags="70"
{
"query": {
"bool": {
"should": [
{
"wildcard": {
"c_other_tags": "70,*"
}
},
{
"wildcard": {
"c_other_tags": "*,70,*"
}
},
{
"wildcard": {
"c_other_tags": "*,70"
}
},
{
"match": {
"c_other_tags.keyword": "70"
}
}
]
}
},
"from": 0,
"size": 10
}
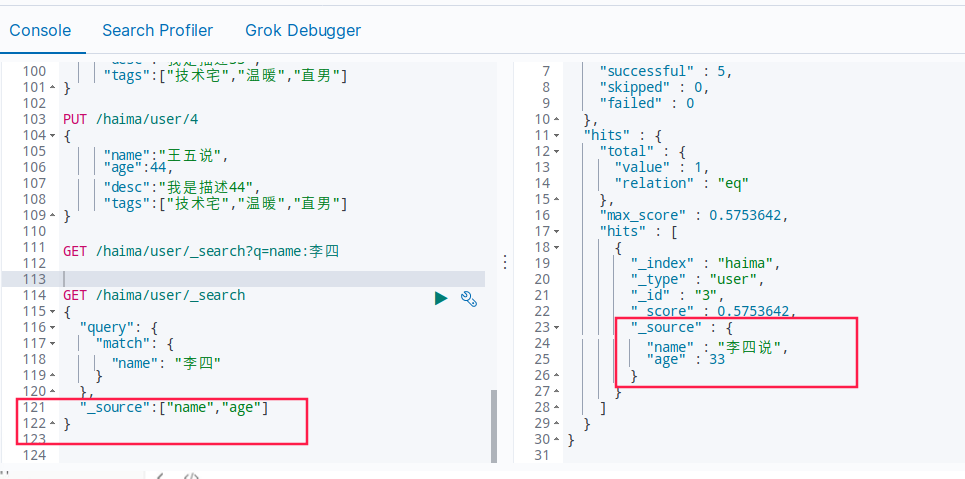
包含(只返回指定字段)

不包含(不返回指定字段,排除字段)
GET /haima/user/_search
{
"query": {
"match": {
"name": "李四"
}
},
"_source":{"excludes":["name","age"]}
}
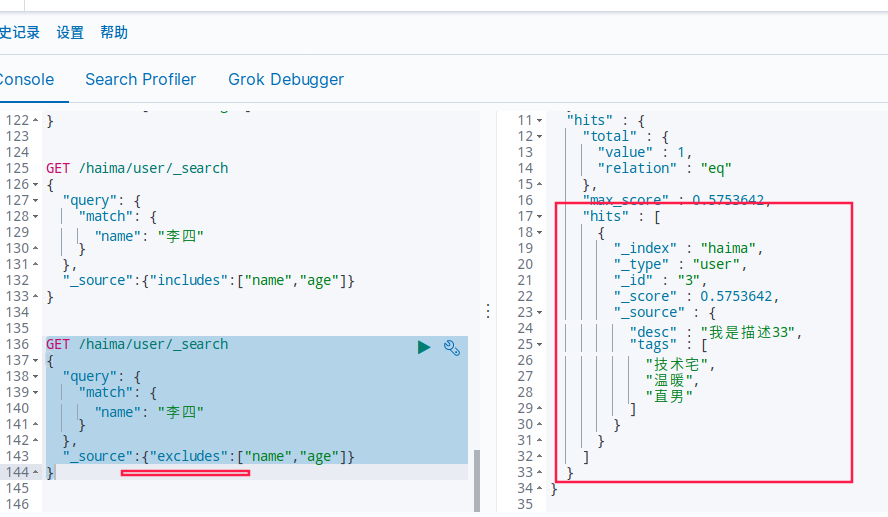
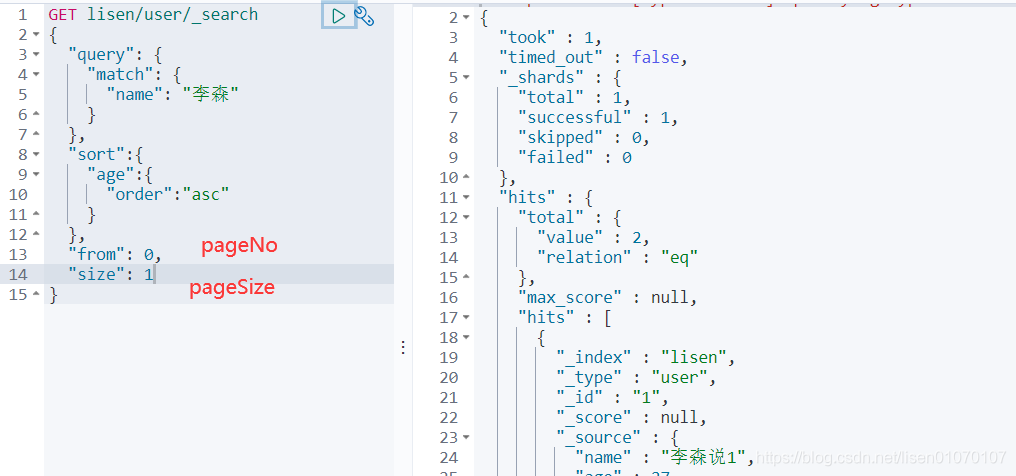
排序 asc(正序) / desc(倒序)

分页
GET /haima/user/_search
{
"query": {
"match": {
"name": "说"
}
},
"sort":{
"age":{
"order":"asc"
}
},
"from":0,
"size":2
}
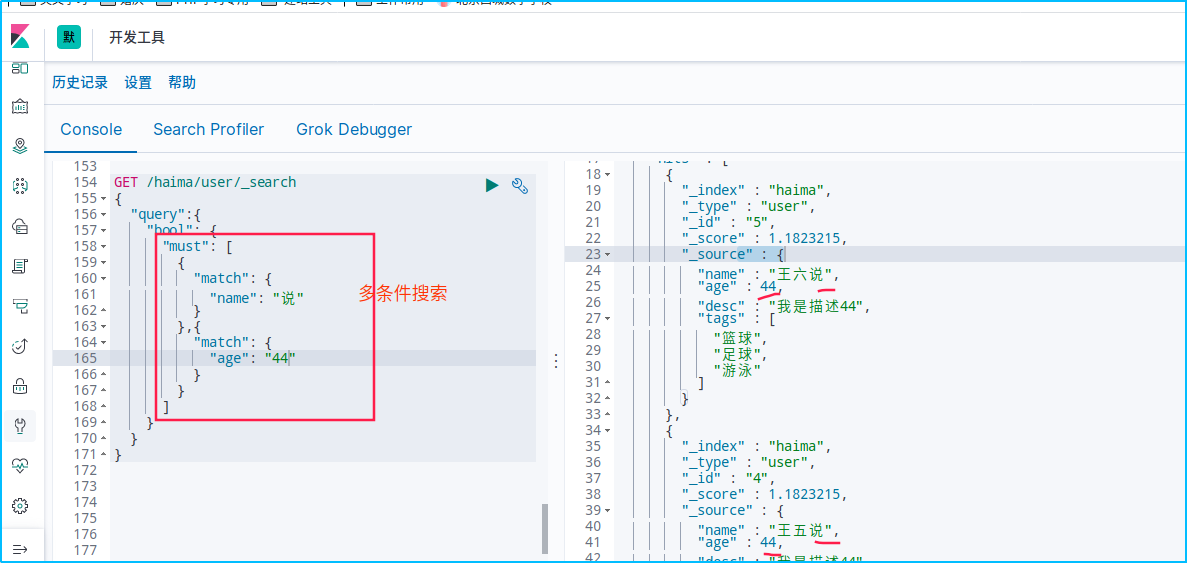
多条件查询
布尔值查询
must(and),所有的条件都要符合
GET /haima/user/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"name": "说"
}
},{
"match": {
"age": "22"
}
}
]
}
}
}
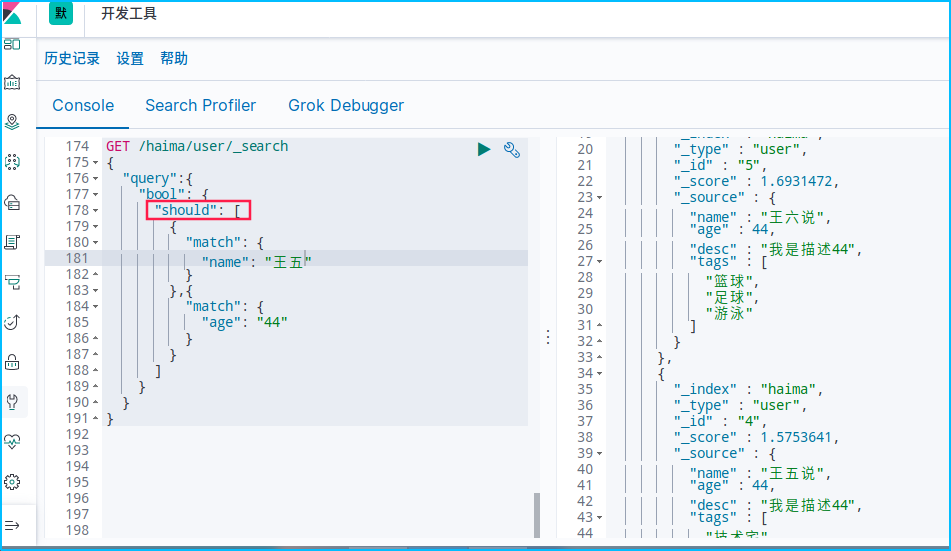
should(or)或者的关系,有一个条件成立即可
GET /haima/user/_search
{
"query":{
"bool": {
"should": [
{
"match": {
"name": "王五"
}
},{
"match": {
"age": "44"
}
}
]
}
}
}
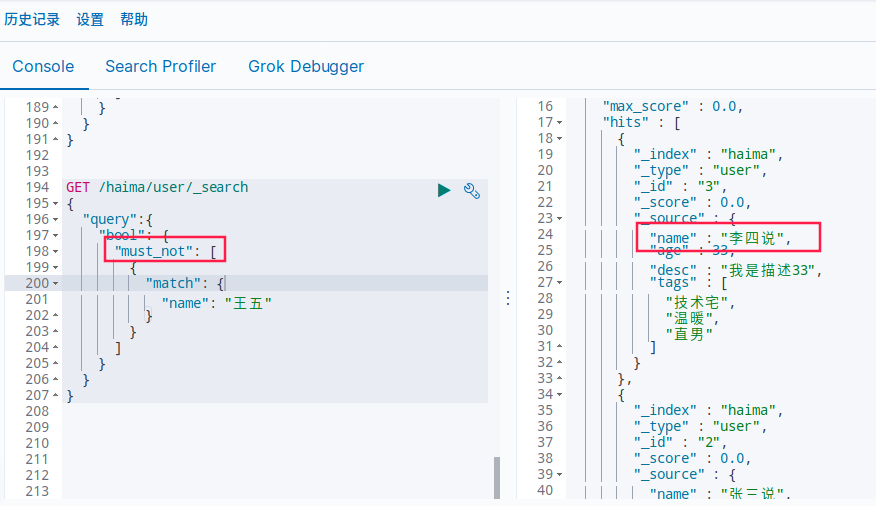
must_not(not)不等于
GET /haima/user/_search
{
"query":{
"bool": {
"must_not": [
{
"match": {
"name": "王五"
}
}
]
}
}
}
条件区间
在查询的结果上,过滤年龄区间符合条件的
GET /haima/user/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"name": "王五"
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 50
}
}
}
}
}
}

- 大于 gt
- 大于等于 gte
- 小于 lt
- 小于等于 lte
匹配多个条件(数组)
GET /haima/user/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"tags": "技术 女"
}
}
]
}
}
}

match没用倒排索引 这边改正一下
精确查找
更多term和match的区别参考下面文档:
https://www.jianshu.com/p/d5583dff4157
term查询是直接通过倒排索引指定的词条进程精确查找的
关于分词
- term,直接查询精确的
- match,会使用分词器解析!(先分析文档,然后通过分析的文档进行查询)
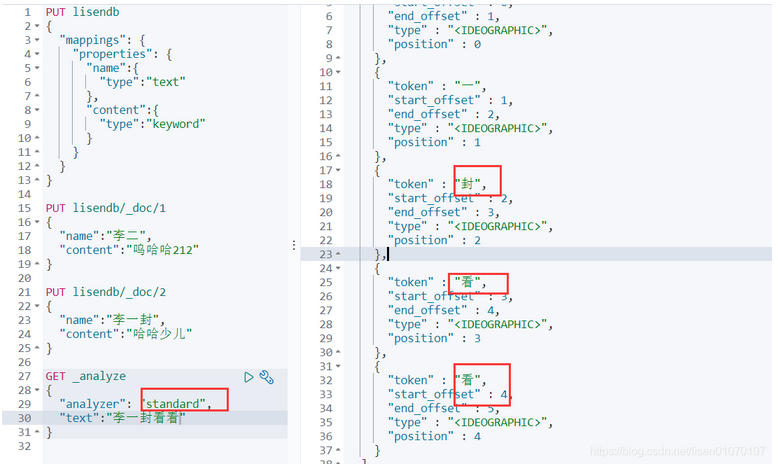
GET _analyze
{
"analyzer":"standard",
"text":"李一封看看"
}
GET _analyze
{
"analyzer":"standard",
"text":"张三说"
}
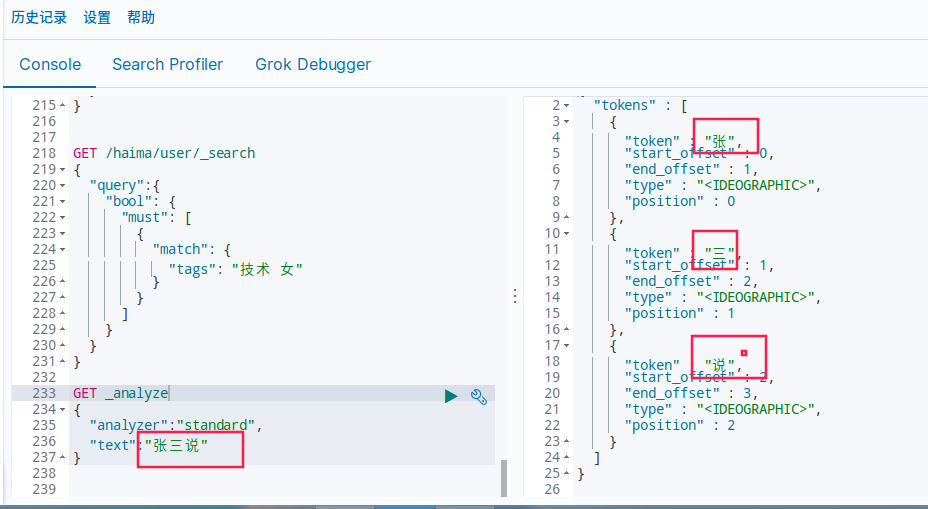
默认的是被分词了
GET _analyze
{
"analyzer":"keyword",
"text":"狂神说"
}
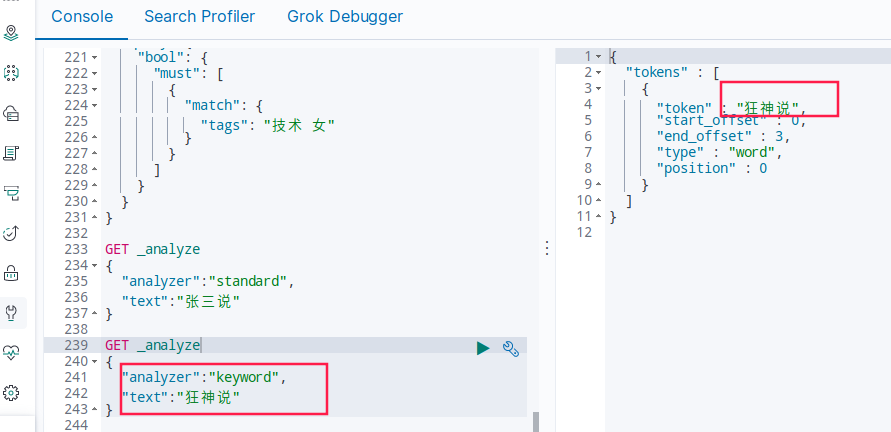

keyword没有被分词
精确查询多个值
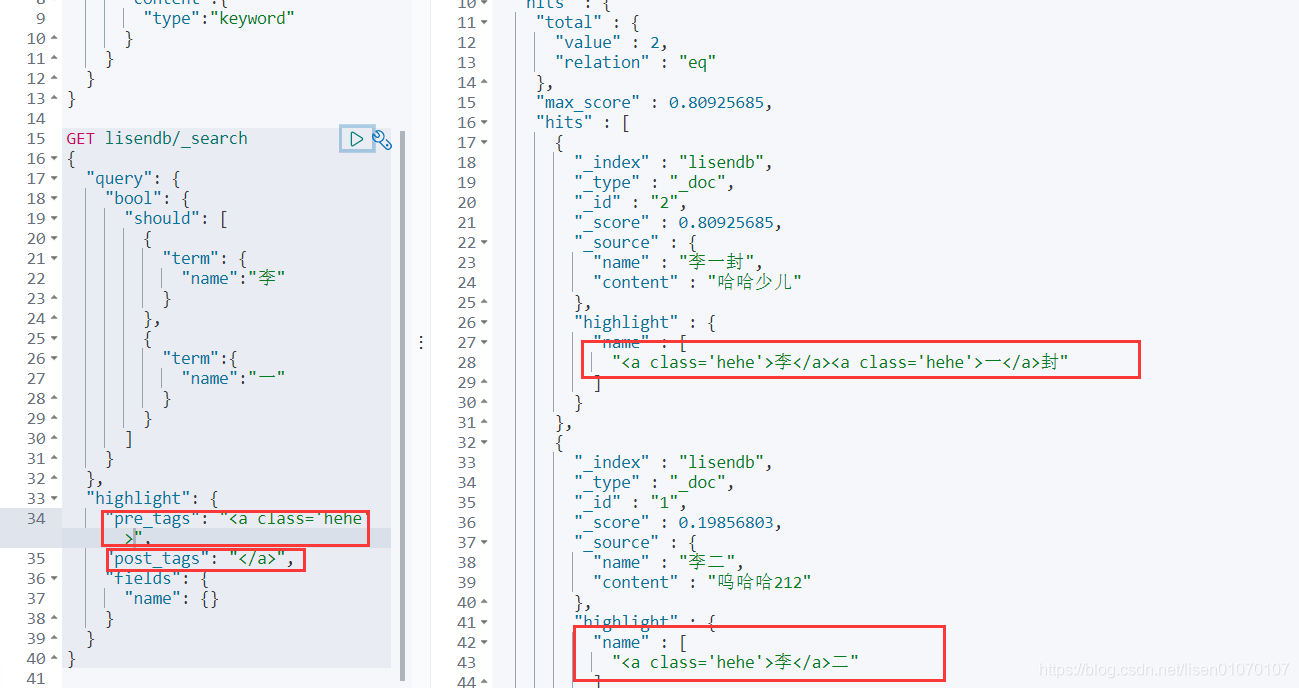
高亮
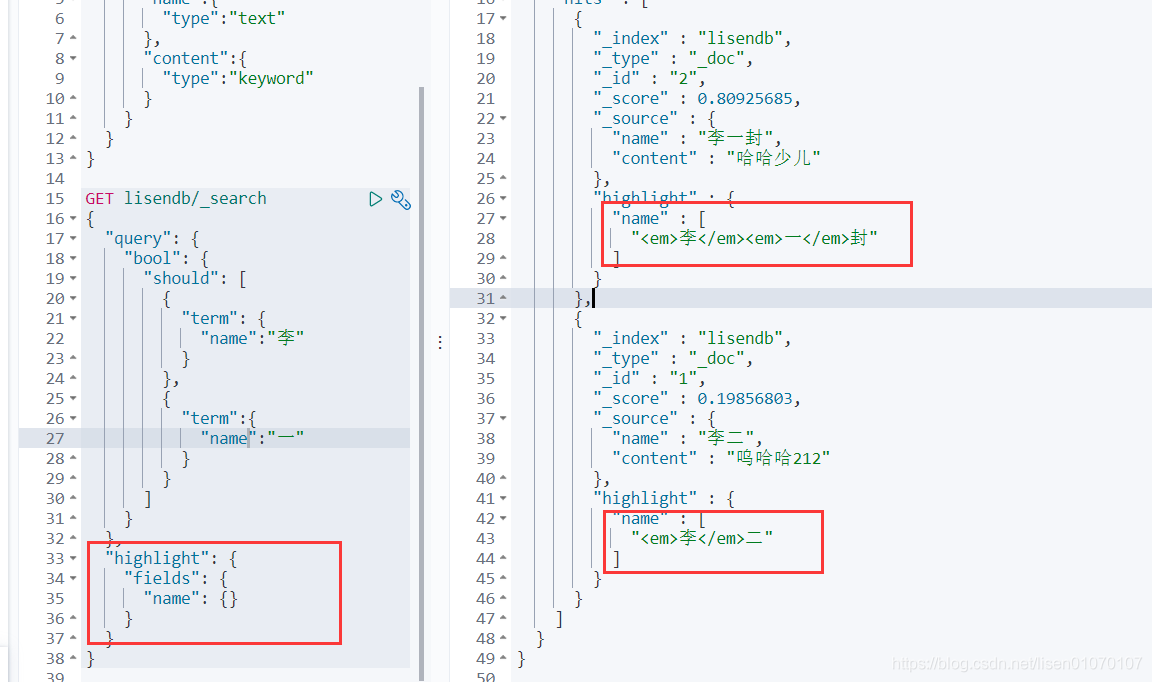
还能自定义高亮的样式
修改文档
- 修改我们可以还是用原来的PUT的命令,根据id来修改
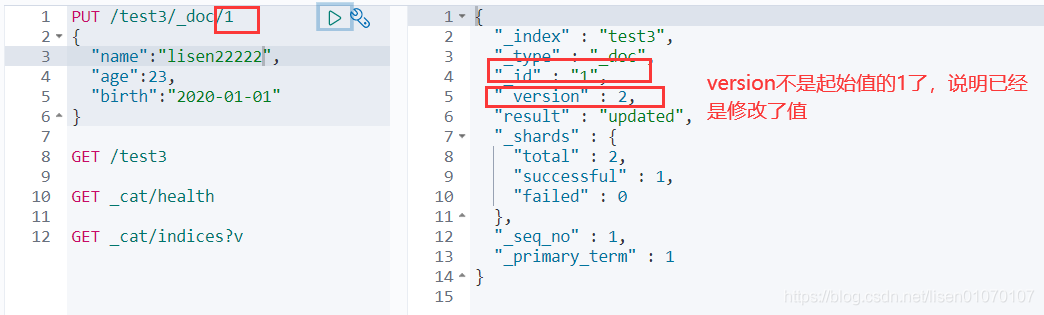
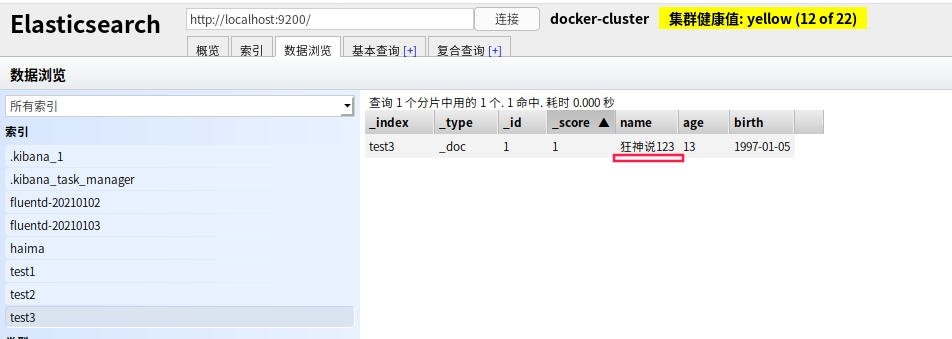
但是如果没有填写的字段 会重置为空了 ,相当于java接口传对象修改,如果只是传id的某些字段,那其他没传的值都为空了。
- 还有一种update方法 这种不设置某些值 数据不会丢失
POST /test3/_doc/1/_update
{
"doc":{
"name":"212121"
}
}
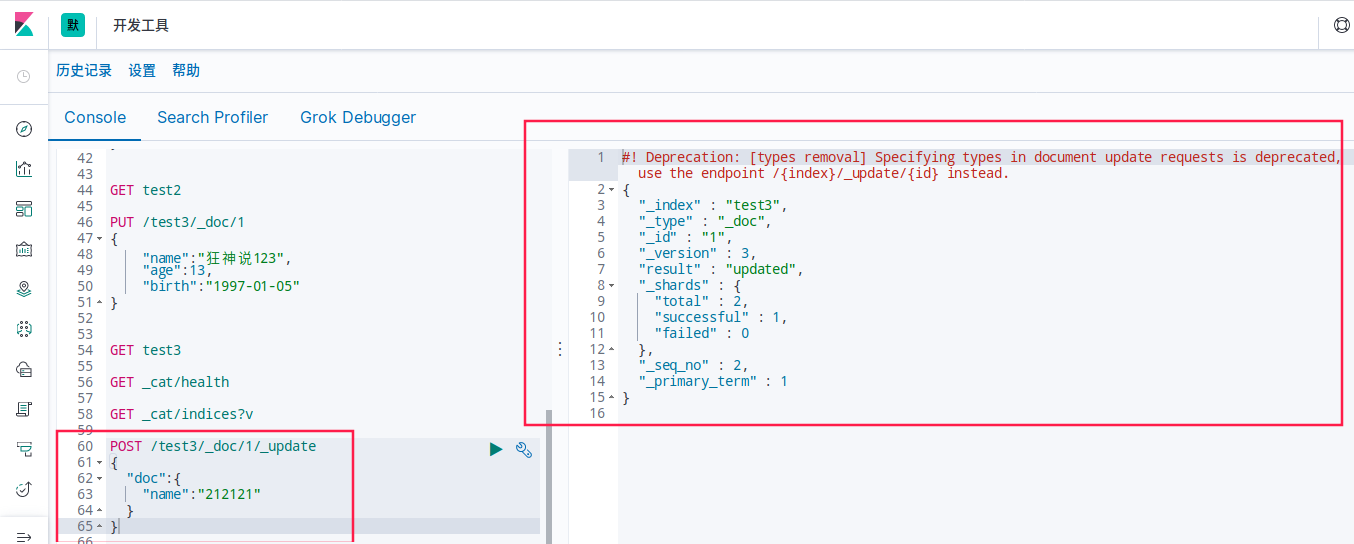
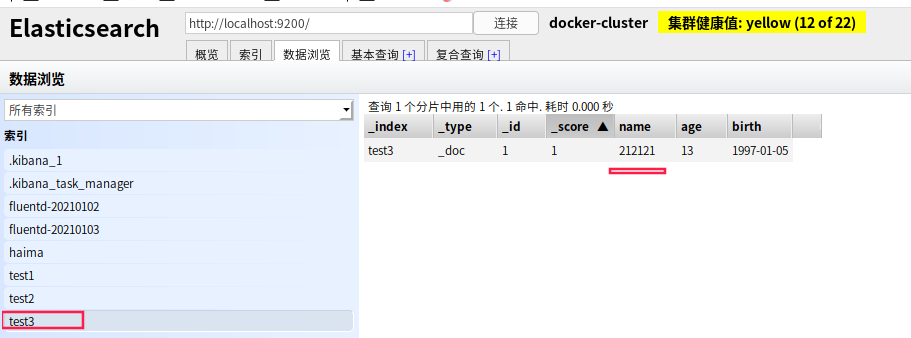
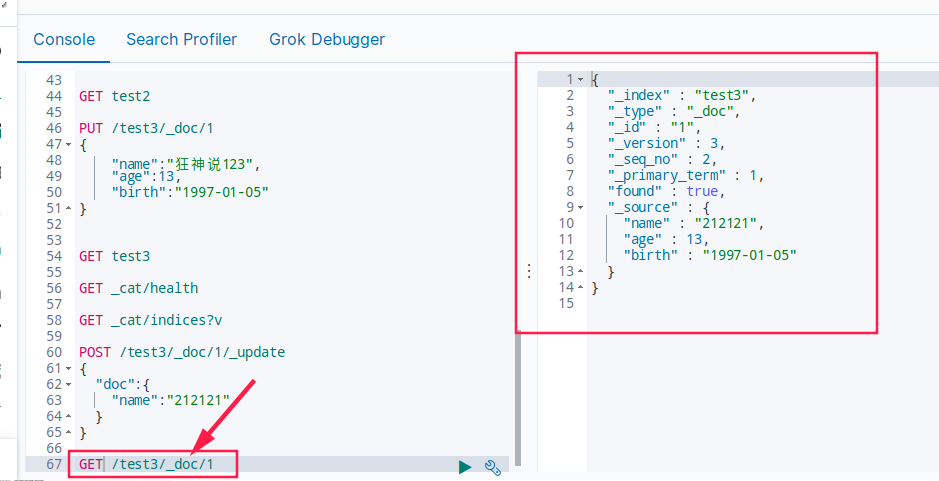
GET /test3/_doc/1
- 访求三
#修改文档 es7中推荐这种,因为默认只有_doc类型,所以可以省略
POST /test3/_update/1
{
"doc":{
"name":"张三"
}
}
返回结果:
{
"_index" : "test3",
"_type" : "_doc",
"_id" : "1",
"_version" : 8,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 8,
"_primary_term" : 2
}
带doc修改 查询也是带doc的(document)
//下面两种都是会将不修改的值清空的
POST /test3/_doc/1
{
"name":"212121"
}
POST /test3/_doc/1
{
"doc":{
"name":"212121"
}
}
删除索引或者文档
关于删除索引或者文档的操作
DELETE /test1删除索引
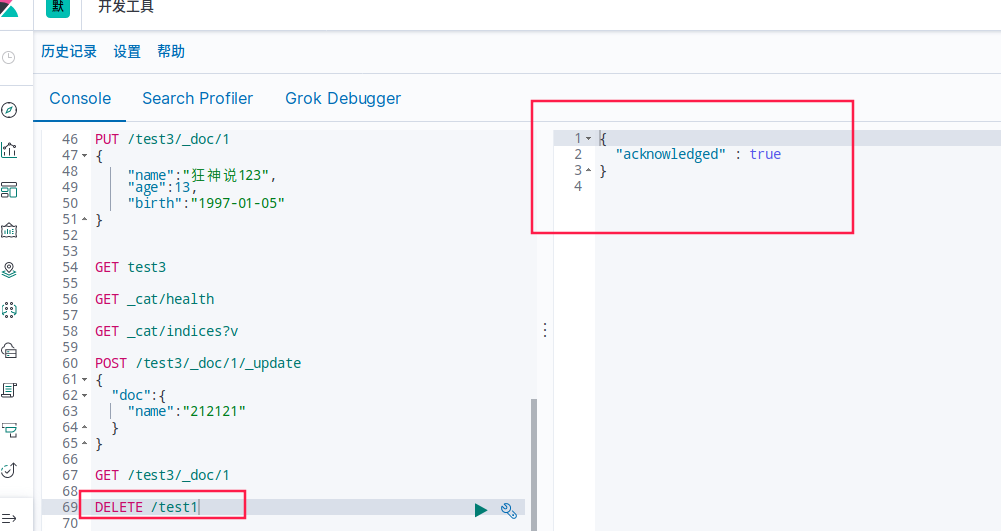
DELETE /test1/_doc/1删除test1索引里主键为1的文档
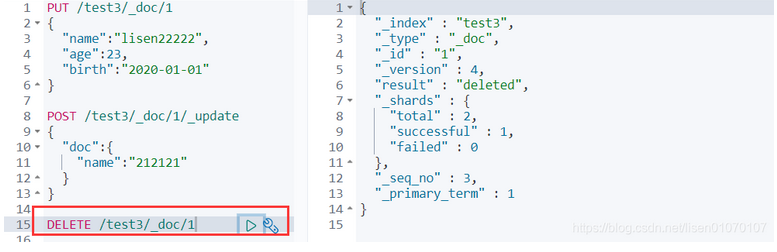
通过DELETE命令实现删除,根据你的请求来判断是删除索引还是删除文档记录
使用RESTFUL的风格是我们ES推荐大家使用的!
- 按搜索条件删除某一索引下所有数据
POST http://127.0.0.1:9200/index_name/type_name/_delete_by_query
{
"query": {"match_all": {}}
}
curl:
curl -u用户名:密码 -XPOST '127.0.0.1:9200/index_name/type_name/_delete_by_query?refresh&slices=5&pretty' -H 'Content-Type: application/json'
-d'{
"query": {
"match_all": {}
}
}'
返回数据:
{
"took": 21832,
"timed_out": false,
"total": 27008,
"deleted": 27008,
"batches": 28,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1.0,
"throttled_until_millis": 0,
"failures": []
}
参考笔记:
https://blog.csdn.net/lisen01070107/article/details/108288037
https://blog.csdn.net/mgdj25/article/details/105740191
https://www.jianshu.com/p/eca8ddb812eb
04 elasticsearch学习笔记-Rest风格说明的更多相关文章
- ElasticSearch学习笔记(超详细)
文章目录 初识ElasticSearch 什么是ElasticSearch ElasticSearch特点 ElasticSearch用途 ElasticSearch底层实现 ElasticSearc ...
- Elasticsearch学习笔记一
Elasticsearch Elasticsearch(以下简称ES)是一款Java语言开发的基于Lucene的高效全文搜索引擎.它提供了一个分布式多用户能力的基于RESTful web接口的全文搜索 ...
- elasticsearch学习笔记——相关插件和使用场景
logstash-input-jdbc学习 ES(elasticsearch缩写)的一大优点就是开源,插件众多.所以扩展起来非常的方便,这也造成了它的生态系统越来越强大.这种开源分享的思想真是与天朝格 ...
- 【原】无脑操作:ElasticSearch学习笔记(01)
开篇来自于经典的“保安的哲学三问”(你是谁,在哪儿,要干嘛) 问题一.ElasticSearch是什么?有什么用处? 答:截至2018年12月28日,从ElasticSearch官网(https:// ...
- Elasticsearch学习笔记 一
本文版权归博客园和作者吴双本人共同所有 转载和爬虫请注明原文地址 www.cnblogs.com/tdws. 本文参考和学习资料 <ES权威指南> 一.基本概念 存储数据到ES中的行为叫做 ...
- ElasticSearch学习笔记-01 简介、安装、配置与核心概念
一.简介 ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进 ...
- Elasticsearch学习笔记
Why Elasticsearch? 由于需要提升项目的搜索质量,最近研究了一下Elasticsearch,一款非常优秀的分布式搜索程序.最开始的一些笔记放到github,这里只是归纳总结一下. 首先 ...
- 2018/2/13 ElasticSearch学习笔记三 自动映射以及创建自动映射模版,ElasticSearch聚合查询
终于把这些命令全敲了一遍,话说ELK技术栈L和K我今天花了一下午全部搞定,学完后还都是花式玩那种...E却学了四天(当然主要是因为之前上班一直没时间学,还有安装服务时出现的各种error真是让我扎心了 ...
- 2018/2/11 ELK技术栈之ElasticSearch学习笔记二
终于有时间记录一下最近学习的知识了,其实除了写下的这些还有很多很多,但懒得一一写下了: ElasticSearch添加修改删除原理:ElasticSearch的倒排索引和文档一旦生成就不允许修改(其实 ...
- elasticsearch学习笔记——安装,初步使用
前言 久仰elasticsearch大名,近年来,fackbook,baidu等大型网站的搜索功能均开始采用elasticsearch,足见其在处理大数据和高并发搜索中的卓越性能.不少其他网站也开始将 ...
随机推荐
- FR常用正则表达式
禁止输入中文字符 ^[^\u4e00-\u9fa5]{0,}$
- 动态库 DLL 封装二:dll封装方法
例:我新建的工程是,带lib的MFC规则的DLL 主要有三个文件需要写东西 ( .h / .cpp / .def ) 示例: // a.h ...... #ifdef __cplusplus e ...
- openGauss每日一练(全文检索)
openGauss 每日一练(全文检索) 本文出处:https://www.modb.pro/db/224179 学习目标 学习 openGauss 全文检索 openGauss 提供了两种数据类型用 ...
- 安装pnpm 和报错解决,亲测可行
安装pnpm 和报错解决,亲测可行 pnpm 是一款磁盘空间高效的软件包管理器. 当使用 npm 或 Yarn 时,如果你有 1000个项目,并且所有项目都有一个相同的依赖包,那么, 你在硬盘上就需要 ...
- 如何用vsftpd实现用户不同权限:只能下载,可上传,管理权限等 [仅供参考未亲测]
如何用vsftpd实现用户不同权限:只能下载,可上传,管理权限等 2007-01-29 10:20:09 分类: LINUX 前提条件: 必须安装包:vsftpd-2.0.1-5 ...
- TypeScript 的理解?与 JavaScript 的区别?
一.是什么 TypeScript 是 JavaScript 的类型的超集,支持ES6语法,支持面向对象编程的概念,如类.接口.继承.泛型等 ❝ 超集,不得不说另外一个概念,子集,怎么理解这两个呢,举个 ...
- 使用Quorum Journal Manager(QJM)的HDFS NameNode高可用配置
前面的一篇文章写到了hadoop hdfs 3.2集群的部署,其中是部署的单个namenode的hdfs集群,一旦其中namenode出现故障会导致整个hdfs存储不可用,如果是要求比较高的集群,有必 ...
- vue 商品sku,笛卡尔算法,商品添加。动态生成table,table添加值后 再生成的table 不改变table之前输入的值
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Llama3-8B到底能不能打?实测对比
前几天Meta开源发布了新的Llama大语言模型:Llama-3系列,本次一共发布了两个版本:Llama-3-8B和Llama-3-70B,根据Meta发布的测评报告,Llama-3-8B的性能吊打之 ...
- 第 10 章 使用pyecharts 进行数据展示
第 10 章 使用pyecharts 进行数据展示 10.1 安装 pyecharts pyecharts 是一个用于生成 Echarts 图表的类库, Echarts 是百度开源的一个数据可视化JS ...