Scrapy爬取自己的博客内容
python中常用的写爬虫的库有urllib2、requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现。这里有一篇我之前写过的用urllib2+BeautifulSoup做的一个抓取百度音乐热门歌曲的例子,有兴趣可以看一下。
本文介绍用Scrapy抓取我在博客园的博客列表,只抓取博客名称、发布日期、阅读量和评论量这四个简单的字段,以求用较简单的示例说明Scrapy的最基本的用法。
环境配置说明
操作系统:Ubuntu 14.04.2 LTS
Python:Python 2.7.6
Scrapy:Scrapy 1.0.3
注意:Scrapy1.0的版本和之前的版本有些区别,有些类的命名空间改变了。
创建项目
执行如下命令创建一个Scrapy项目
scrapy startproject scrapy_cnblogs
创建之后查看项目的目录结构如下:
scrapy_cnblogs
├── botcnblogs
│ ├── __init__.py
│ ├── items.py #用于定义抓取内容的实体
│ ├── pipelines.py #处理抓取的item的管道
│ ├── settings.py #爬虫需要的配置参数在这里
│ └── spiders
│ └── __init__.py
└── scrapy.cfg #项目的配置文件,可以不去理会,默认即可
其中scrapy.cfg所在的目录为项目的根目录,此文件是项目的配置文件,项目建立后,此文件的内容可以不用理会。其内容如下:
[settings]
default = botcnblogs.settings [deploy]
#url = http://localhost:6800/
project = botcnblogs
在items.py文件里定义在抓取网页内容中抽象出来的数据结构的定义,由于这里需要博客名称、发布日期、阅读量和评论量这四个字段,定义的Item结构如下:
from scrapy import Item,Field #引入Item、Field class BotcnblogsItem(Item):
# define the fields for your item here like:
title = Field() #标题
publishDate = Field() #发布日期
readCount = Field() #阅读量
commentCount = Field() #评论数
在pipelines.py里对爬虫抓取到的信息(这里的信息是已经组织好的上面定义的Item对象)进行处理,官方介绍的典型的应用场景为:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库中
它的定义也很简单,只需要实现process_item方法即可,此方法有两个参数,一个是item,即要处理的Item对象,另一个参数是spider,即爬虫。
另外还有open_spider和close_spider两个方法,分别是在爬虫启动和结束时的回调方法。
本例中处理很简单,只是将接收的Item对象写到一个json文件中,在__init__方法中以“w+”的方式打开或创建一个item.json的文件,然后把对象反序列化为字符串,写入到item.json文件中。代码如下:
# -*- coding: utf-8 -*- import json class BotcnblogsPipeline(object):
def __init__(self):
self.file = open("item.json", "w+") def process_item(self, item, spider):
record = json.dumps(dict(item), ensure_ascii=False)+"\n" #此处如果有中文的话,要加上ensure_ascii=False参数,否则可能出现乱码
self.file.write(record)
return item def open_spider(self, spider):
pass def close_spider(self, spider):
self.file.close()
setting.py是爬虫的配置文件,配置爬虫的一些配置信息,这里用到的就是设置pipelines的ITEM_PIPELINES参数,此参数配置项目中启用的pipeline及其执行顺序,以字典的形式存在,{“pipeline”:执行顺序整数}
此例中的配置如下:
SPIDER_MODULES = ['botcnblogs.spiders']
NEWSPIDER_MODULE = 'botcnblogs.spiders' ITEM_PIPELINES = {
'botcnblogs.pipelines.BotcnblogsPipeline': 1,
}
准备工作都做好了,爬虫呢,爬虫在哪里实现呢,我们看到项目中有个spiders目录,里面只有一个init.py文件,没错,爬虫文件需要自己创建,就在这个目录下,这里创建一个botspider.py的文件,对网页进行解析的工作就要在这里实现了,此例中定义的爬虫类继承自CrawlSpider类。
定义一个Spider需要如下几个变量和方法实现:
name:定义spider名字,这个名字应该是唯一的,在执行这个爬虫程序的时候,需要用到这个名字。
allowed_domains:允许爬取的域名列表,例如现在要爬取博客园,这里要写成cnblogs.com
start_urls:爬虫最开始爬的入口地址列表。
rules:如果要爬取的页面不是单独一个或者几个页面,而是具有一定的规则可循的,例如爬取的博客有连续多页,就可以在这里设置,如果定义了rules,则需要自己定义爬虫规则(以正则表达式的方式),而且需要自定义回调函数。
代码说话:
#-*- coding:utf-8 -*-
__author__ = 'linuxfengzheng' from scrapy.spiders import Spider, Rule
from scrapy.selector import Selector
from botcnblogs.items import BotcnblogsItem
from scrapy.linkextractors import LinkExtractor
import re
from scrapy.spiders import CrawlSpider class botspider(CrawlSpider):
name = "cnblogsSpider" #设置爬虫名称 allowed_domains = ["cnblogs.com"] #设置允许的域名
start_urls = [
"http://www.cnblogs.com/fengzheng/default.html?page=3", #设置开始爬取页面
] rules = (
Rule(LinkExtractor(allow=('fengzheng/default.html\?page\=([\d]+)', ),),callback='parse_item',follow=True),
) #制定规则 def parse_item(self, response):
sel = response.selector
posts = sel.xpath('//div[@id="mainContent"]/div/div[@class="day"]')
items = []
for p in posts:
#content = p.extract()
#self.file.write(content.encode("utf-8"))
item = BotcnblogsItem()
publishDate = p.xpath('div[@class="dayTitle"]/a/text()').extract_first() item["publishDate"] = (publishDate is not None and [publishDate.encode("utf-8")] or [""])[0]
#self.file.write(title.encode("utf-8"))
title = p.xpath('div[@class="postTitle"]/a/text()').extract_first()
item["title"] = (title is not None and [title.encode("utf-8")] or [""])[0] #re_first("posted @ 2015-11-03 10:32 风的姿态 阅读(\d+") readcount = p.xpath('div[@class="postDesc"]/text()').re_first(u"阅读\(\d+\)") regReadCount = re.search(r"\d+", readcount)
if regReadCount is not None:
readcount = regReadCount.group()
item["readCount"] = (readcount is not None and [readcount.encode("utf-8")] or [0])[0] commentcount = p.xpath('div[@class="postDesc"]/text()').re_first(u"评论\(\d+\)")
regCommentCount = re.search(r"\d+", commentcount)
if regCommentCount is not None:
commentcount = regCommentCount.group()
item["commentCount"] = (commentcount is not None and [commentcount.encode("utf-8")] or [0])[0]
items.append(item) return items
#self.file.close()
因为1.0版和之前的版本在包上有所改变,这里列出此例中所涉及的不同版本的区别
| 类 | 所在包 | |
| 1.0版本 | 之前版本 | |
Spider |
scrapy.spiders |
scrapy.spider |
CrawlSpider |
scrapy.spiders |
scrapy.contrib.spiders |
LinkExtractor |
scrapy.linkextractors |
scrapy.contrib.linkextractors |
Rule |
scrapy.spiders | scrapy.contrib.spiders |
爬虫思路:
首先进入到我的博客页面http://www.cnblogs.com/fengzheng/,这是我的博客首页,以列表形式显示已经发布的博文,这是第一页,点击页面下面的下一页按钮,进入第二页,页面地址为http://www.cnblogs.com/fengzheng/default.html?page=2,由此看出网站以page作为参数来表示页数,这样看来爬虫的规则就很简单了, fengzheng/default.html\?page\=([\d]+),这个就是爬虫的规则,爬取default.html页面,page参数为数字的页面,这样无论有多少页都可以遍历到。当然,如果页面数量很少可以在start_urls列表中,将要爬取的页面都列出来,但是这样当博文数量增多就会出现问题,如下:
start_urls = [
"http://www.cnblogs.com/fengzheng/default.html?page=1",
"http://www.cnblogs.com/fengzheng/default.html?page=2",
"http://www.cnblogs.com/fengzheng/default.html?page=3",
]
当爬取的网页具有规则定义的情况下,要继承CrawlSpider爬虫类,使用Spider就不行了,在规则定义(rules)时,如果要对爬取的网页进行处理,而不是简单的需要Url,这时,需要定义一个回调函数,在爬取到符合条件的网页时调用,并且设置follow=Ture,定义如下:
rules = (
Rule(LinkExtractor(allow=('fengzheng/default.html\?page\=([\d]+)', ),),callback='parse_item',follow=True),
)
回调函数名称为parse_item,在parse_item方法中,就是真正要分析网页html,获取需要的内容的时候了。观察页面,查看需要的信息在什么位置,如图:
之后,分析网页源码,分析出xpath
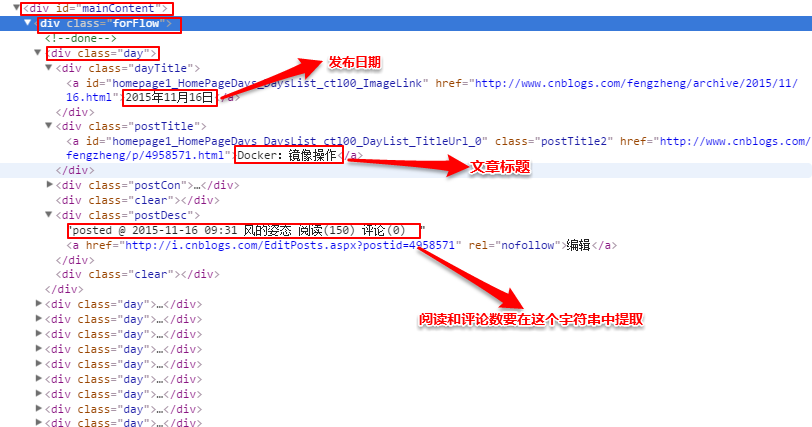
用如下代码找到所有的class为day的div,每一个就是一个博文区域:
posts = sel.xpath('//div[@id="mainContent"]/div/div[@class="day"]')
之后遍历这个集合,获取所需内容,其中注意一下几点:
- 因为有中文内容,要对获取的内容进行encode("utf-8")编码
- 由于评论数和阅读量混在一起,要对那个字符串再进行正则表达式提取
至此,简单的爬虫已经完成,接下来要运行这个爬虫,cd进入到爬虫项目所在的目录,执行以下命令:
scrapy crawl cnblogsSpider
会输出爬取过程信息

之后会看到,根目录中多了一个item.json文件,cat此文件内容,可以看到信息已经被提取出来:

Scrapy爬取自己的博客内容的更多相关文章
- scrapy 爬取自己的博客
定义项目 # -*- coding: utf-8 -*- # items.py import scrapy class LianxiCnblogsItem(scrapy.Item): # define ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- python+selenium+requests爬取我的博客粉丝的名称
爬取目标 1.本次代码是在python2上运行通过的,python3的最需改2行代码,用到其它python模块 selenium 2.53.6 +firefox 44 BeautifulSoup re ...
- python3+selenium3+requests爬取我的博客粉丝的名称
爬取目标 1.本次代码是在python3上运行通过的 selenium3 +firefox59.0.1(最新) BeautifulSoup requests 2.爬取目标网站,我的博客:https:/ ...
- step2: 爬取廖雪峰博客
#https://zhuanlan.zhihu.com/p/26342933 #https://zhuanlan.zhihu.com/p/26833760 scrapy startproject li ...
- 一文搞定scrapy爬取众多知名技术博客文章保存到本地数据库,包含:cnblog、csdn、51cto、itpub、jobbole、oschina等
本文旨在通过爬取一系列博客网站技术文章的实践,介绍一下scrapy这个python语言中强大的整站爬虫框架的使用.各位童鞋可不要用来干坏事哦,这些技术博客平台也是为了让我们大家更方便的交流.学习.提高 ...
- scrapy爬取极客学院全部课程
# -*- coding: utf-8 -*- # scrapy爬取极客学院全部课程 import scrapy from pyquery import PyQuery as pq from jike ...
- python scrapy爬取知乎问题和收藏夹下所有答案的内容和图片
上文介绍了爬取知乎问题信息的整个过程,这里介绍下爬取问题下所有答案的内容和图片,大致过程相同,部分核心代码不同. 爬取一个问题的所有内容流程大致如下: 一个问题url 请求url,获取问题下的答案个数 ...
随机推荐
- WebStorm 2016.2 破解方法
http://www.jetbrains.com/ 以前的 http://idea.lanyus.com/ 不能激活了 有帖子说的 http://15.idea.lanyus.com/ http:// ...
- x
笔记 { 计算机 { 底层 { 程序运行 } 信息学 { 网络 { 网络信息安全 } 算法 { 算法 拟合 编译解释词法分析 } 编程语言 { C语言 嵌入式C++ } 黑客 } } 安卓 { 软件 ...
- 进击的Python【第十章】:Python的socket高级应用(多进程,协程与异步)
Python的socket高级应用(多进程,协程与异步)
- Linux SHELL 命令入门题目答案(一)
1.如何使用shell 打印 “Hello World!” (1)如果你希望打印 !,那就不要将其放入双引号中,或者你可以通过转义字符转义(2)echo 'hello world!' 使用单引号ech ...
- MYSQL 按照字母排序查询
select id vKey, name vValue from ib_brand order by convert(name USING gbk) COLLATE gbk_chinese_ci a ...
- IDE-Sublime【3】-配置Node.js开发环境
一.下载Nodejs插件,下载地址为https://github.com/tanepiper/SublimeText-Nodejs,解压到当前文件夹,改名为Nodejs 二.打开Sublime Tex ...
- 疑难问题解决备忘录(2)——ubuntu12.04分配swap
分配swapdd if=/dev/zero of=Swap.disk bs=1M count=6k (count=1k创建1G的Swap,如果要创建6G则count=6k:这步比较慢) 创建swap文 ...
- 安装了VS2012 还有Update4 我的Silverlight5安装完后 我的Silverlight4项目打不开
安装了VS2012 还有Update4 我的Silverlight5安装完后 我的Silverlight4项目打不开 求助 不知道是哪里出问题了 我的Silverlihgt4项目一直报错 无法打开 ...
- checkbox和文本上下对齐
只需要分别给checkbox和文本加上这个样式就可以了: vertical-align:middle;
- XVI Open Cup named after E.V. Pankratiev. GP of Ukraine
A. Associated Vertices 首先求出SCC然后缩点,第一次求出每个点能到的点集,第二次收集这些点集即可,用bitset加速,时间复杂度$O(\frac{nm}{64})$. #inc ...