4.1 手写Java PriorityQueue 核心源码 - 原理篇
本章先讲解优先级队列和二叉堆的结构。下一篇代码实现
从一个需求开始
假设有这样一个需求:在一个子线程中,不停的从一个队列中取出一个任务,执行这个任务,直到这个任务处理完毕,再取出下一个任务,再执行。
其实和 Android 的 Handler 机制中的 Looper 不停的从 MessageQueue 中取出一个消息然后处理是一样的。
不过这个需求还有一点。需要我们的任务是有优先之分的,优先高的先执行,优先级低的后执行。比如现在队列中已经有了10个任务了,现在有一个紧急的任务需要处理,怎么办?
解决办法有多种:
- 用数组实现,把任务放到数组里面,每次任务入队后,根据任务的优先级排序,把优先级最大的排到最前面,取任务的时候从队头取
- 用链表实现,每次入队的时候把每个元素的优先级比较一下,把优先级最大的放链表尾部,取的尾部,取任务的时候每次都从尾部取就行了。
总结:上面两种方法都可以实现,不过都有一定的缺点
- 第一种方法,用数组实现,入队的时候,需要遍历整个数组,才能找到合适的位置
入队的时间复杂度是O(n),出队的时间复杂度是O(1)
- 第二种方法,用链表实现,和数组一样,也是需要遍历整个链表,才能找到合适的位置,入队的时间复杂度是O(n),出队的时间复杂度是O(1)
虽然出队效率很高,但是入队效率太低。有没有一种方法入队出队效率都很高呢?
当然有,就是Java 给我们提供了一个 PriorityQueue 也就是优先级队列
我们来看一下PriorityQueue的用法
PriorityQueue的用法
我们有一个任务类,在里面执行一些操作。如下:
/*** 我们的任务类*/public class Task {//任务的名称public String name;//优先级,是一个整数,我们规定,数越大优先级越高public int priority;public Task(String name,int priority){this.name = name;this.priority = priority;}//假如这是任务需要做的事public void doSomthing(){System.out.println("do somthing");}@Overridepublic String toString() {return "taskName=" + name + " taskPriority=" + priority;}}
测试代码如下:
public static void main(String[] args){//比较两个任务,从大到小排序Comparator<Task> comparator = new Comparator<Task>() {@Overridepublic int compare(Task o1, Task o2) {if(o1.priority > o2.priority){return -1;}else if(o1.priority == o2.priority){return 0;}else {return 1;}}};//新建一个任务Queue<Task> priorityQueue = new PriorityQueue<Task>(10,comparator);//新建了4个不同优先级的任务入队,数越大优先级越大,也最先执行priorityQueue.add(new Task("task1",23));priorityQueue.add(new Task("task2",34));priorityQueue.add(new Task("task3",15));priorityQueue.add(new Task("task4",79));//分别取出任务,然后打印System.out.println(priorityQueue.poll()); // 首先应该是 task4, 先取出来,因为优先级最大System.out.println(priorityQueue.poll()); // 然后才是 task2 被取出来System.out.println(priorityQueue.poll()); // 然后才是 task1 被取出来System.out.println(priorityQueue.poll()); // 最后才是 task3 被取出来,因为优先级最小}
输出如下:
taskName=task4 taskPriority=79taskName=task2 taskPriority=34taskName=task1 taskPriority=23taskName=task3 taskPriority=15
由此可知,虽然入队的顺序是不一样的,但是出队的顺序,是优先大的先出队
如果现在有一个紧急的任务需要优先处理,那么就可以设置这个任务的优先级比79大,
就可以排到最前面,等到下一次从队列中取任务的时候,这个紧急的任务就被取出来了。
这就是优先级队列的作用。
PriorityQueue队列的原理
直接上结论:
- PriorityQueue是一个最大堆(或者用最小堆也是一样)
- 堆一种完全二叉树
- PriorityQueue是用一个数组存放二叉树中的元素的。
1 什么是完全二叉树?
完全二叉树:若设二叉树的深度为h,除第 h 层外,其它各层 (1 ~ h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
定义太抽象,我们上图来描述什么是二叉树。
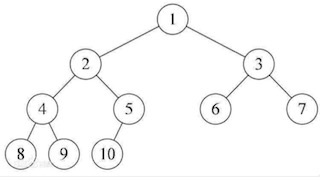
上由图可知:二叉树节点节点都在最左边。这就是完全二叉树,形态要记牢哦。
2 什么是堆结构?
堆结构有最大堆和最小堆,这里我们以最大堆为例。(最大堆懂了,那么最小堆自然就懂了)。
最大堆定义: 最大堆是一个完全二叉树,并且根节点的数都比左右两个节点的数大。
说白了就是最大的节点作用根。
由定义可知,最大堆有 2 个性质
- 最大堆是一个完全二叉树
- 最大堆,根节点比左右两个子节点大
如下图,是一个最大堆:
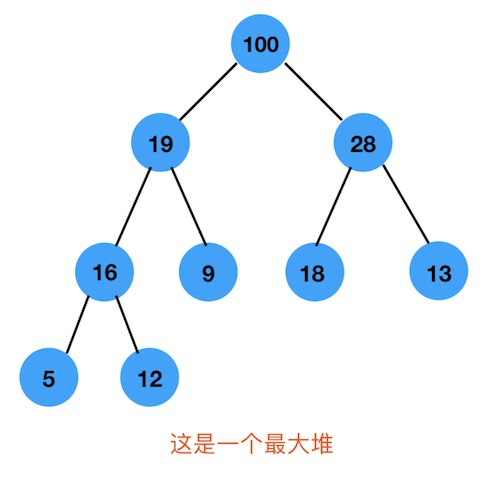
上图是一个最大堆,首先是一棵完全二叉树,并且每个根节点都大于它的左右子节点
这就是最大堆结构,当然最小堆和最大堆是反着的,根节点比左右子节点要小。
最大堆的形态要记牢哦。
最大堆和优先级队列
由上图最大堆可知:
- 假如取元素的时候,只取整棵树的根节点,也就是 100 那个节点。也就是优先级最高的节点。
- 100 节点取走以后,我们只需要把剩下的节点中,找个最大的,放在根节点位置,
- 插入一个节点的时候,我们保证插入的节点放在适合的位置,满足二叉堆的性质即可。
那么这样的数据结构不就是优先级队列吗。
现在的问题就是
- 如何用数组来存放二叉堆结构?(上面说了,二叉堆是用数组来存放数据的)
- 如何向二叉堆中插入一个节点,并放到合适的位置上?
- 取出根节点后,怎么找到剩下的最大的节点并放到合适的位置上?
下面我们来一一解决上面三个问题
1 如何用数组来存放二叉堆结构?
我们以下图一个简单的二叉堆为例
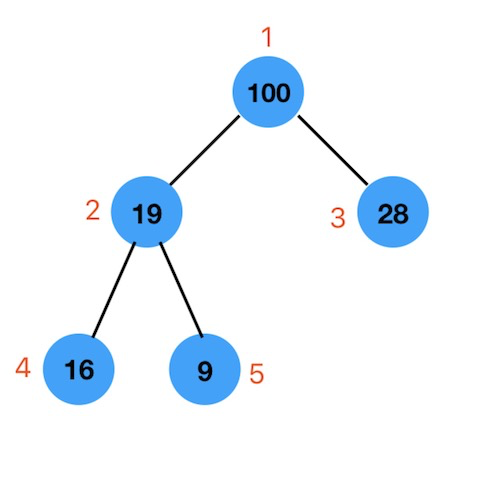
我们从左往右,按层序遍历,分别存放到数组的相应索引对应的位置上。
数组的第0个索引位置我们不用,从索引为1的位置开始存放。
最终这个最大堆存放到数组中,如下图
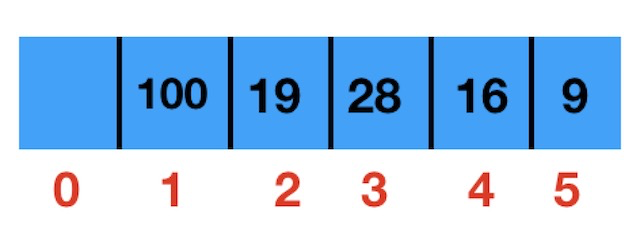
索引为0的位置不用。从1开始,为了方便后面计算。
对照图这两副图可以知道,二叉堆中的元素分层存放到数组中(从索引1开始存放)
有下面几个性质:
1 对于一个索引为n的节点,它的左孩子的索引是 2*n ,它的右孩子索引是 2*n+1
比如 索引为2的节点是19
- 那么它的左孩子是
2 * 2是数组中的索引为4的位置 ,也就是16 - 它的右孩子是
2*2 + 1是数组中的索引为5的位置,也就是9
同样也可以由节点的索引,知道此节点的父节点的索引。
比如 索引为2的节点是19
那么它的父节点是 2 / 2 ,也就是索引为1的位置
比如 索引为3的节点是28
那么它的父节点是 3 / 2 ,也是 1 ,是和图中能对得上吧。
由此可知:用数组存放二叉堆(从索引为1开始),有以下两个性质:
对于索引为 n 的节点
- 找孩子节点:左孩子的索引是
2*n,右孩子的索引是2*n + 1 - 找父节点: 父节点的索引是
n/2
注:只有完全二叉树按层序存放到数组中才有这样的性质。必须是完全二叉树,必须是完全二叉树,必须是完全二叉树。重要的事情说三遍
2 如何向二叉堆中插入一个节点,并放到合适的位置上?
要向二叉堆中插入一个节点,插入节点后
只需要满足是完全二叉树并且任意一个根节点都比它的左右两个孩子的大就行了。
感觉说的是废话
如下图,我们要向二叉堆中插入一个节点为 30 的元素。
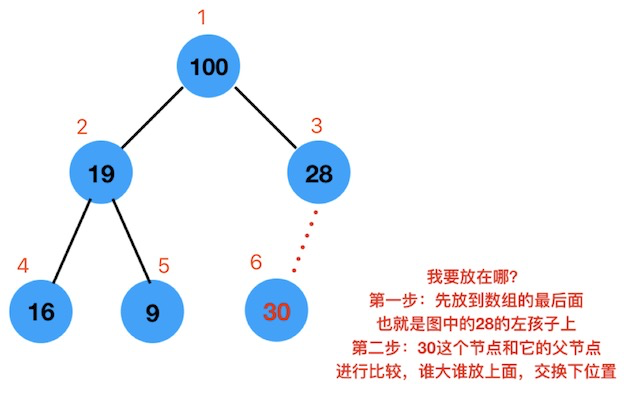
- 第一步:新来的节点放到数组的最后的位置
也就是索引为 6 的位置(数组大小不够了就扩容,后面讲) - 第二步:不停的与自己的父节点比大小,比父节点大,就交换位置
然后重复以上步骤
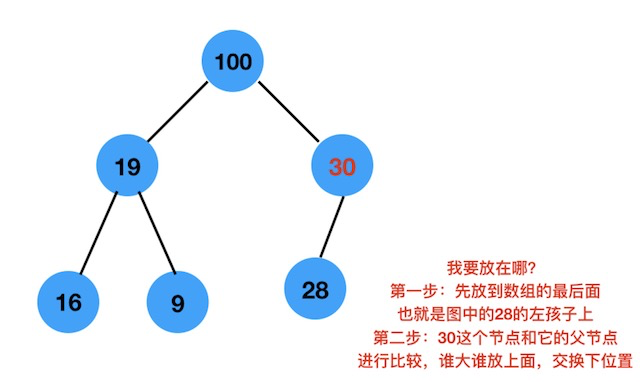
经过上面两步,就可以将一个节点插入到合适的位置上了。如下图
知道了如何向二叉堆中插入一个节点,,那么如何取出根节点后,怎么找到剩下的最大的节点并放到合适的位置上?也就是删除根节点后,剩下的怎么办呢?
3 如何删除根节点?
删除根节点很容易,关键是删除后剩下的节点怎么摆放?如下图
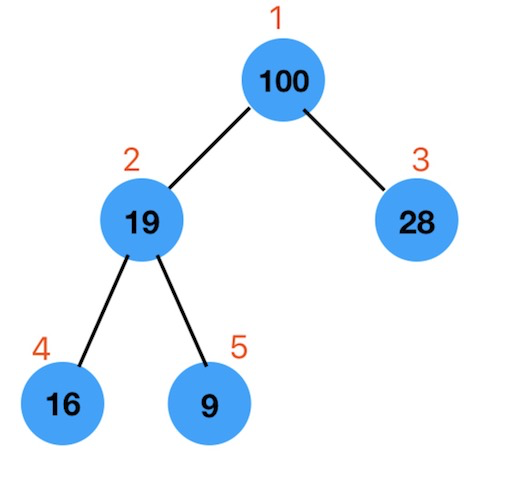
把根节点100删除后
- 第一步:把最后一个节点9放到100的位置上,也就是索引为 1 的位置上。
- 第二步:从根节点开始,不停的与它的左右两上节点比大小,找到左右两个节点为中的比较大的节点,然后交换位置,以此类推,直到这个节点比它的左右两个节点都大为止
如下图,第一步:
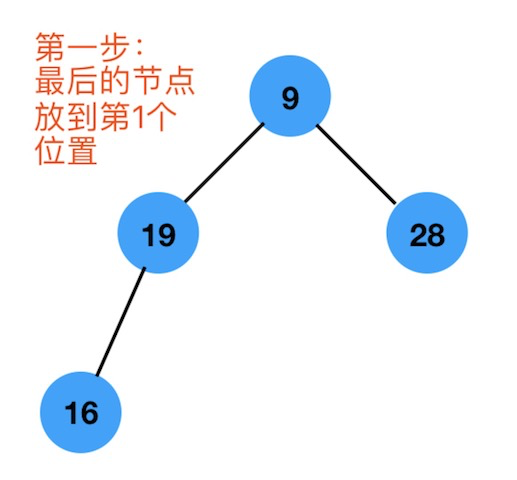
第二步:找出根节点9的最大的孩子节点 ,也就是 28,然后交换位置 :如下图
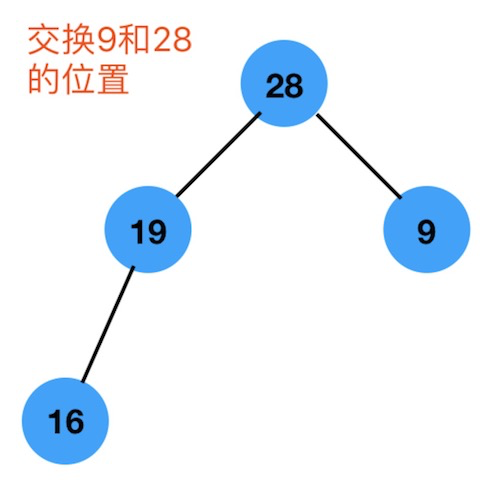
直到没有孩子可以比较了或者说有孩子,但是比孩子的节点要大,便不再比较
由上面可以知道,插入和删除都有了,下一章节就是代码实现了
4.1 手写Java PriorityQueue 核心源码 - 原理篇的更多相关文章
- 4.2 手写Java PriorityQueue 核心源码 - 实现篇
上一节介绍了PriorityQueue的原理,先来简单的回顾一下 PriorityQueue 的原理 以最大堆为例来介绍 PriorityQueue是用一棵完全二叉树实现的. 不但是棵完全二叉树,而且 ...
- 6 手写Java LinkedHashMap 核心源码
概述 LinkedHashMap是Java中常用的数据结构之一,安卓中的LruCache缓存,底层使用的就是LinkedHashMap,LRU(Least Recently Used)算法,即最近最少 ...
- 3 手写Java HashMap核心源码
手写Java HashMap核心源码 上一章手写LinkedList核心源码,本章我们来手写Java HashMap的核心源码. 我们来先了解一下HashMap的原理.HashMap 字面意思 has ...
- 1 手写Java ArrayList核心源码
手写ArrayList核心源码 ArrayList是Java中常用的数据结构,不光有ArrayList,还有LinkedList,HashMap,LinkedHashMap,HashSet,Queue ...
- 2 手写Java LinkedList核心源码
上一章我们手写了ArrayList的核心源码,ArrayList底层是用了一个数组来保存数据,数组保存数据的优点就是查找效率高,但是删除效率特别低,最坏的情况下需要移动所有的元素.在查找需求比较重要的 ...
- 5 手写Java Stack 核心源码
Stack是Java中常用的数据结构之一,Stack具有"后进先出(LIFO)"的性质. 只能在一端进行插入或者删除,即压栈与出栈 栈的实现比较简单,性质也简单.可以用一个数组来实 ...
- Java HashMap 核心源码解读
本篇对HashMap实现的源码进行简单的分析. 所使用的HashMap源码的版本信息如下: /* * @(#)HashMap.java 1.73 07/03/13 * * Copyright 2006 ...
- 手撕spring核心源码,彻底搞懂spring流程
引子 十几年前,刚工作不久的程序员还能过着很轻松的日子.记得那时候公司里有些开发和测试的女孩子,经常有问题解决不了的,不管什么领域的问题找到我,我都能帮她们解决.但是那时候我没有主动学习技术的意识,只 ...
- 手写JAVA虚拟机(二)——实现java命令行
查看手写JAVA虚拟机系列可以进我的博客园主页查看. 我们知道,我们编译.java并运行.class文件时,需要一些java命令,如最简单的helloworld程序. 这里的程序最好不要加包名,因为加 ...
随机推荐
- 《Android Studio有用指南》7.1 AndroidStudio代码检查工具概述
本文节选自<Android Studio有用指南> 作者: 毕小朋 博客: http://blog.csdn.net/wirelessqa 眼下本书已上传到百度阅读, 在百度中搜索[Anr ...
- 【caffe-windows】 caffe-master 之 卷积核可视化(利用matlab)
此篇是利用matlab对caffemodel的卷积核进行可视化.只介绍了卷积核的可视化,不涉及特征图的可视化. 是参考此博客: http://blog.csdn.net/zb1165048017/ar ...
- Js 模拟鼠标点击事件
var obj = document.getElementById('go'); if(document.all){ obj.click(); }else{ var e = document.crea ...
- Avro schemas are defined with JSON . This facilitates implementation in languages that already have JSON libraries.
https://avro.apache.org/docs/current/ Introduction Apache Avro™ is a data serialization system. Avro ...
- ideal 控制台乱码 解决
run config 中 tomcat VM options中填入一下命令 -Dfile.encoding=UTF-8
- Javascript的参数详解
函数可以有参数也可以没有参数,如果定义了参数,在调用函数的时候没有传值,默认设置为undefined 在调用函数时如果传递参数超过了定义时参数,jS会忽略掉多余参数 jS中不能直接写默认值,可以通过a ...
- RSA加密:利用模数和指数生成公钥加密
引子 目前做一款金融产品,由于涉及到资金安全,采用动态公钥的方式,即客户端每次登录服务端返回一个不同的XML串,由公钥的模数和指数构成,我需要用这个串生成公钥加密相关信息.服务端返回的XML串形如: ...
- vue中引入百度统计
vue作为单页面的,引入百度统计,需要注意不少. 一.基本的流量统计 在index.html 入口文件中引入百度统计生成的一连串代码: var _hmt = _hmt || []; (function ...
- Codeforces Round #401 (Div. 2) C Alyona and Spreadsheet —— 打表
题目链接:http://codeforces.com/contest/777/problem/C C. Alyona and Spreadsheet time limit per test 1 sec ...
- !function(){}()和function(){}()区别
控制台打印结果如下所示,接下来看一下具体运行,参考https://swordair.com/function-and-exclamation-mark/: 让一个函数声明语句变成了一个表达式