tensorflow:实战Google深度学习框架第四章01损失函数
深度学习:两个重要特性:多层和非线性
线性模型:任意线性模型的组合都是线性模型,只通过线性变换任意层的全连接神经网络与单层神经网络没有区别。
激活函数:能够实现去线性化(神经元的输出通过一个非线性函数)。
多层神经网络:能够解决异或问题,深度学习有组合特征提取的功能。
使用激活函数和偏置项的前向传播算法
import tensorflow as tf
a = tf.nn.relu(tf.matmul(x,w1) + biases1)
y = tf.nn.relu(tf.matmul(a,w2) + biases2)
常用的激活函数:tf.nn.relu, tf.sigmoid, tf.tanh
二、损失函数(loss faction)
1、经典损失函数:分类问题:交叉熵,回归问题:均方误差
交叉熵:刻画两个概率分布之间的距离,交叉熵越小,概率分布越接近,给定两个概率分布p和q,通过q表示p的交叉熵(概率分布q来表达概率分布p的困难程度,p:正确答案,q:代表预测值):

神经网络的输出不一定是概率分布,Softmax回归就是将神经网络的输出变成概率分布常用的方法
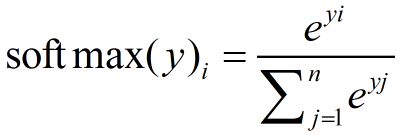
交叉熵的代码实现:
cross_entropy = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-10,1.0)))#y_代表正确结果,y代表预测结果
#第一个运算tf.clip_by_value函数可以将张量的数值限制在一个范围内,这样可以避免一些运算错误
#例如
import tensorflow as tf
sess = tf.Session()
v=tf.constant([[1.0,2.0,3.0],[4.0,5.0,6.0]])
print(tf.clip_by_value(v,2.5,4.5).eval(session=sess))
#输出[[ 2.5 2.5 3. ],[ 4. 4.5 4.5]],将小于2.5的数替换为2.5,将大于4.5的数替换为4.5
#第二个运算tf.log函数,这个函数完成对张量中所有元素依次取对数。
v = tf.constant([1.0,2.0,3.0])
print(tf.log(v).eval(session=sess))
#输出为[ 0. 0.69314718 1.09861231]
#第三个运算乘法,在交叉熵代码中将矩阵使用“*”操作相乘,这是元素之间直接相乘,矩阵乘法需要tf.matmul函数完成
v1 = tf.constant([[1.0,2.0],[3.0,4.0]])
v2 = tf.constant([[5.0,6.0],[7.0,8.0]])
print((v1 * v2).eval(session=sess))#元素相乘
#输出为[[ 5. 12.] [ 21. 32.]]
print(tf.matmul(v1,v2).eval(session=sess))#矩阵相乘
#输出[[ 19. 22.] [ 43. 50.]]
#前三步结果为:n*m的矩阵,其中n为一个batch的样例数量,m为分类的类别数量。根据交叉熵公式,要将每行m个结果相加得到所有样例的交叉熵,再对这n行取平均得到一个batch的平均交叉熵
#由于分类问题类别不变
sess.close()
配合softmax函数使用:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y,y_)
若只有一个正确答案,使用下面函数加速计算:
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(y,y_)
回归问题解决的是具体数值的预测,一般只有一个输出节点,最常用的损失函数是均方误差(MSE):
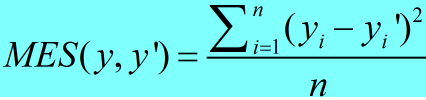
代码实现:
mse = tf.reduce_mean(tf.square(y_-y))
2、自定义损失函数
# 不同的损失函数会对训练模型产生重要影响
import tensorflow as tf
from numpy.random import RandomState # 1. 定义神经网络的相关参数和变量
batch_size = 8
x = tf.placeholder(tf.float32, shape=(None, 2), name="x-input")
y_ = tf.placeholder(tf.float32, shape=(None, 1), name='y-input')
w1= tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1))
y = tf.matmul(x, w1) # 2. 设置自定义的损失函数
# 定义损失函数使得预测少了的损失大,于是模型应该偏向多的方向预测。
loss_less = 10
loss_more = 1
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * loss_more, (y_ - y) * loss_less))
train_step = tf.train.AdamOptimizer(0.001).minimize(loss) # 3. 生成模拟数据集
rdm = RandomState(1)
X = rdm.rand(128,2)
Y = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X] # 4. 训练模型
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 5000
for i in range(STEPS):
start = (i*batch_size) % 128
end = (i*batch_size) % 128 + batch_size
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 1000 == 0:
print("After %d training step(s), w1 is: " % (i))
print(sess.run(w1), "\n")
print("[loss_less=10 loss_more=1] Final w1 is: \n", sess.run(w1))
'''
After 0 training step(s), w1 is:
[[-0.81031823]
[ 1.4855988 ]] After 1000 training step(s), w1 is:
[[ 0.01247113]
[ 2.13854504]] After 2000 training step(s), w1 is:
[[ 0.45567426]
[ 2.17060685]] After 3000 training step(s), w1 is:
[[ 0.69968736]
[ 1.84653103]] After 4000 training step(s), w1 is:
[[ 0.89886677]
[ 1.29736042]] [loss_less=10 loss_more=1] Final w1 is:
[[ 1.01934707]
[ 1.04280913]]
''' # 5. 重新定义损失函数,使得预测多了的损失大,于是模型应该偏向少的方向预测
loss_less = 1
loss_more = 10
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * loss_more, (y_ - y) * loss_less))
train_step = tf.train.AdamOptimizer(0.001).minimize(loss) with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 5000
for i in range(STEPS):
start = (i*batch_size) % 128
end = (i*batch_size) % 128 + batch_size
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 1000 == 0:
print("After %d training step(s), w1 is: " % (i))
print(sess.run(w1), "\n")
print("[loss_less=1 loss_more=10] Final w1 is: \n", sess.run(w1))
'''
After 0 training step(s), w1 is:
[[-0.81231821]
[ 1.48359871]] After 1000 training step(s), w1 is:
[[ 0.18643527]
[ 1.07393336]] After 2000 training step(s), w1 is:
[[ 0.95444274]
[ 0.98088616]] After 3000 training step(s), w1 is:
[[ 0.95574027]
[ 0.9806633 ]] After 4000 training step(s), w1 is:
[[ 0.95466018]
[ 0.98135227]] [loss_less=1 loss_more=10] Final w1 is:
[[ 0.95525807]
[ 0.9813394 ]]
''' # 6. 定义损失函数为MSE
loss = tf.losses.mean_squared_error(y, y_)
train_step = tf.train.AdamOptimizer(0.001).minimize(loss) with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 5000
for i in range(STEPS):
start = (i*batch_size) % 128
end = (i*batch_size) % 128 + batch_size
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 1000 == 0:
print("After %d training step(s), w1 is: " % (i))
print(sess.run(w1), "\n")
print("[losses.mean_squared_error]Final w1 is: \n", sess.run(w1))
'''
After 0 training step(s), w1 is:
[[-0.81031823]
[ 1.4855988 ]] After 1000 training step(s), w1 is:
[[-0.13337614]
[ 1.81309223]] After 2000 training step(s), w1 is:
[[ 0.32190299]
[ 1.52463484]] After 3000 training step(s), w1 is:
[[ 0.67850214]
[ 1.25297272]] After 4000 training step(s), w1 is:
[[ 0.89473999]
[ 1.08598232]] [losses.mean_squared_error]Final w1 is:
[[ 0.97437561]
[ 1.0243336 ]]
'''
tensorflow:实战Google深度学习框架第四章01损失函数的更多相关文章
- tensorflow:实战Google深度学习框架第四章02神经网络优化(学习率,避免过拟合,滑动平均模型)
1.学习率的设置既不能太小,又不能太大,解决方法:使用指数衰减法 例如: 假设我们要最小化函数 y=x2y=x2, 选择初始点 x0=5x0=5 1. 学习率为1的时候,x在5和-5之间震荡. im ...
- Tensorflow 实战Google深度学习框架 第五章 5.2.1Minister数字识别 源代码
import os import tab import tensorflow as tf print "tensorflow 5.2 " from tensorflow.examp ...
- [Tensorflow实战Google深度学习框架]笔记4
本系列为Tensorflow实战Google深度学习框架知识笔记,仅为博主看书过程中觉得较为重要的知识点,简单摘要下来,内容较为零散,请见谅. 2017-11-06 [第五章] MNIST数字识别问题 ...
- 1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
学习过程是Tensorflow 实战google深度学习框架一书的第六章的迁移学习环节. 具体见我提出的问题:https://www.tensorflowers.cn/t/5314 参考https:/ ...
- TensorFlow+实战Google深度学习框架学习笔记(5)----神经网络训练步骤
一.TensorFlow实战Google深度学习框架学习 1.步骤: 1.定义神经网络的结构和前向传播的输出结果. 2.定义损失函数以及选择反向传播优化的算法. 3.生成会话(session)并且在训 ...
- 学习《TensorFlow实战Google深度学习框架 (第2版) 》中文PDF和代码
TensorFlow是谷歌2015年开源的主流深度学习框架,目前已得到广泛应用.<TensorFlow:实战Google深度学习框架(第2版)>为TensorFlow入门参考书,帮助快速. ...
- TensorFlow实战Google深度学习框架-人工智能教程-自学人工智能的第二天-深度学习
自学人工智能的第一天 "TensorFlow 是谷歌 2015 年开源的主流深度学习框架,目前已得到广泛应用.本书为 TensorFlow 入门参考书,旨在帮助读者以快速.有效的方式上手 T ...
- TensorFlow实战Google深度学习框架1-4章学习笔记
目录 第1章 深度学习简介 第2章 TensorFlow环境搭建 第3章 TensorFlow入门 第4章 深层神经网络 第1章 深度学习简介 对于许多机器学习问题来说,特征提取不是一件简单的事情 ...
- TensorFlow实战Google深度学习框架10-12章学习笔记
目录 第10章 TensorFlow高层封装 第11章 TensorBoard可视化 第12章 TensorFlow计算加速 第10章 TensorFlow高层封装 目前比较流行的TensorFlow ...
随机推荐
- Docker容器的网络连接:
yw1989@ubuntu:~$ ifconfig docker0 Link encap:Ethernet HWaddr 02:42:97:61:42:9f inet addr:172.17.0.1 ...
- BestCoder Round #92 1001 Skip the Class —— 字典树 or map容器
题目链接:http://bestcoder.hdu.edu.cn/contests/contest_showproblem.php?cid=748&pid=1001 题解: 1.trie树 关 ...
- SystemV和BSD的区别
目前,Unix操作系统不管其内核如何,其操作风格上主要分为SystemV(目前一般采用其第4个版本SVR4)和BSD两种.其代表操作系统本别是Solaris和FreeBSD.当然,在SunOS4(So ...
- div遮罩弹框口
<html> <head> <meta http-equiv="Content-Type" content="text/html; char ...
- map的详细用法 (转
map的详细用法: map是STL的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称为该关键字的值)的数据处理能 力,由于这个特性,它完成有可能在我 ...
- log4j 配置文件详解
[1]从零开始 a). 新建Java Project>>新建package>>新建java类: b). import jar包(一个就够),这里我用的是log4j-1.2.14 ...
- Yii 表单验证规则---总结
Filter: 过滤,'filter'=>'trim',表示去空格 Required:必须的,表示不能为空 Match: 匹配正则,需要和pattern一起使用,定义正则表达式,'pattern ...
- VOIP语音编码带宽计算
VOIP Bandwidth consumption naturally depends on the codec used. VOIP消耗的带宽一般取决于所使用的语音编码. When calcul ...
- 2018值得选用的五个Linux服务器发行版
[IT168 编译]据最新统计,目前Linux发行版约有300种,几乎都可以作为服务器系统运行.在Linux早期,几乎所有发行版都是“万能”发行版,专门的Linux服务器发行版并不火热,到21世纪初, ...
- 洛谷P4145上帝造题的七分钟——区间修改
题目:https://www.luogu.org/problemnew/show/P4145 区间开平方,可以发现其实开几次就变成1,不需要开了,所以标记一下,每次只去开需要开的地方: 原来写的并查集 ...