Locality-sensitive hashing Pr[m(Si) = m(Sj )] = E[JSˆ (Si, Sj )] = JS(Si, Sj )
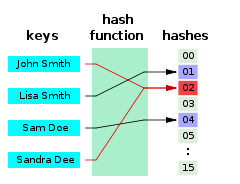
A hash function that maps names to integers from 0 to 15. There is a collision between keys "John Smith" and "Sandra Dee".、、
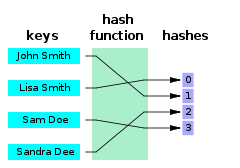
A minimal perfect hash function for the four names shown
https://en.wikipedia.org/wiki/Hash_function
【hash the input items so that similar items are mapped to the same buckets with high probability 相似的入同桶】
Locality-sensitive hashing (LSH) is a method of performing probabilistic dimension reduction of high-dimensional data. The basic idea is to hash the input items so that similar items are mapped to the same buckets with high probability (the number of buckets being much smaller than the universe of possible input items). This is different from the conventional hash functions, such as those used in cryptography, as in this case the goal is to minimize the probability of "collision" of every item.[18]
One example of LSH is MinHash algorithm used for finding similar documents (such as web-pages):
Let h be a hash function that maps the members of A and B to distinct integers, and for any set S define hmin(S) to be the member x of S with the minimum value of h(x). Then hmin(A) = hmin(B) exactly when the minimum hash value of the union A ∪ B lies in the intersection A ∩ B. Therefore,
- Pr[hmin(A) = hmin(B)] = J(A,B). where J is Jaccard index.
In other words, if r is a random variable that is one when hmin(A) = hmin(B) and zero otherwise, then r is an unbiased estimator of J(A,B), although it has too high a variance to be useful on its own. The idea of the MinHash scheme is to reduce the variance by averaging together several variables constructed in the same way.
【MinHash 减小方差--变异】
zh.wikipedia.org/wiki/散列函數
【性能不佳的散列函数表意味着查找操作会退化为费时的线性搜索】
Hash Tables
Hash functions are used in hash tables,[1] to quickly locate a data record (e.g., a dictionary definition) given its search key (the headword). Specifically, the hash function is used to map the search key to a list; the index gives the place in the hash table where the corresponding record should be stored. Hash tables, also, are used to implement associative arrays and dynamic sets.[2]
Typically, the domain of a hash function (the set of possible keys) is larger than its range (the number of different table indices), and so it will map several different keys to the same index. So then, each slot of a hash table is associated with (implicitly or explicitly) a set of records, rather than a single record. For this reason, each slot of a hash table is often called a bucket, and hash values are also called bucket listing[citation needed] or a bucket index.
Thus, the hash function only hints at the record's location. Still, in a half-full table, a good hash function will typically narrow the search down to only one or two entries.
People who write complete hash table implementations choose a specific hash function—such as a Jenkins hash or Zobrist hashing—and independently choose a hash-table collision resolution scheme—such as coalesced hashing, cuckoo hashing, or hopscotch hashing.
散列表是散列函数的一个主要应用,使用散列表能够快速的按照关键字查找数据记录。(注意:关键字不是像在加密中所使用的那样是秘密的,但它们都是用来“解锁”或者访问数据的。)例如,在英语字典中的关键字是英文单词,和它们相关的记录包含这些单词的定义。在这种情况下,散列函数必须把按照字母顺序排列的字符串映射到为散列表的内部数组所创建的索引上。
散列表散列函数的几乎不可能/不切实际的理想是把每个关键字映射到唯一的索引上(参考完美散列),因为这样能够保证直接访问表中的每一个数据。
一个好的散列函数(包括大多数加密散列函数)具有均匀的真正随机输出,因而平均只需要一两次探测(依赖于装填因子)就能找到目标。同样重要的是,随机散列函数不太会出现非常高的冲突率。但是,少量的可以估计的冲突在实际状况下是不可避免的(参考生日悖论或鸽洞原理)。
在很多情况下,heuristic散列函数所产生的冲突比随机散列函数少的多。Heuristic函数利用了相似关键字的相似性。例如,可以设计一个heuristic函数使得像FILE0000.CHK, FILE0001.CHK, FILE0002.CHK,等等这样的文件名映射到表的连续指针上,也就是说这样的序列不会发生冲突。相比之下,对于一组好的关键字性能出色的随机散列函数,对于一组坏的关键字经常性能很差,这种坏的关键字会自然产生而不仅仅在攻击中才出现。性能不佳的散列函数表意味着查找操作会退化为费时的线性搜索。
【通过平均用同一方式构造的许多随机变量,从而减少方差】
【The idea of the MinHash scheme is to reduce this variance by averaging together several variables constructed in the same way.】
The Jaccard similarity coefficient is a commonly used indicator of the similarity between two sets. For sets A and B it is defined to be the ratio of the number of elements of their intersection and the number of elements of their union:

This value is 0 when the two sets are disjoint, 1 when they are equal, and strictly between 0 and 1 otherwise. Two sets are more similar (i.e. have relatively more members in common) when their Jaccard index is closer to 1. The goal of MinHash is to estimate J(A,B) quickly, without explicitly computing the intersection and union.
Let h be a hash function that maps the members of A and B to distinct integers, and for any set S define hmin(S) to be the minimal member of S with respect to h—that is, the member x of S with the minimum value of h(x). Now, applying hmin to both A and B, and assuming no hash collisions, we will get the same value exactly when the element of the union A ∪ B with minimum hash value lies in the intersection A ∩ B. The probability of this being true is the ratio above, and therefore:
- Pr[ hmin(A) = hmin(B) ] = J(A,B),
That is, the probability that hmin(A) = hmin(B) is true is equal to the similarity J(A,B), assuming randomly chosen sets A and B. In other words, if r is the random variable that is one when hmin(A) = hmin(B) and zero otherwise, then r is an unbiased estimator of J(A,B). r has too high a variance to be a useful estimator for the Jaccard similarity on its own, because {\displaystyle r}
【 measurable functions on a measurable space 


http://infolab.stanford.edu/~ullman/mmds/book.pdf
【局部敏感哈希 思路 多次随机hash运算 相似的 进同一桶】
One general approach to LSH is to “hash” items several times, in such a way that similar items are more likely to be hashed to the same bucket than dissimilar items are. We then consider any pair that hashed to the same bucket for any of the hashings to be a candidate pair. We check only the candidate pairs for similarity. The hope is that most of the dissimilar pairs will never hash to the same bucket, and therefore will never be checked. Those dissimilar pairs that do hash to the same bucket are false positives; we hope these will be only a small fraction of all pairs. We also hope that most of the truly similar pairs will hash to the same bucket under at least one of the hash functions. Those that do not are false negatives; we hope these will be only a small fraction of the truly similar pairs.



Locality-sensitive hashing Pr[m(Si) = m(Sj )] = E[JSˆ (Si, Sj )] = JS(Si, Sj )的更多相关文章
- [Algorithm] 局部敏感哈希算法(Locality Sensitive Hashing)
局部敏感哈希(Locality Sensitive Hashing,LSH)算法是我在前一段时间找工作时接触到的一种衡量文本相似度的算法.局部敏感哈希是近似最近邻搜索算法中最流行的一种,它有坚实的理论 ...
- 局部敏感哈希算法(Locality Sensitive Hashing)
from:https://www.cnblogs.com/maybe2030/p/4953039.html 阅读目录 1. 基本思想 2. 局部敏感哈希LSH 3. 文档相似度计算 局部敏感哈希(Lo ...
- LSH(Locality Sensitive Hashing)原理与实现
原文地址:https://blog.csdn.net/guoziqing506/article/details/53019049 LSH(Locality Sensitive Hashing)翻译成中 ...
- Locality Sensitive Hashing,LSH
1. 基本思想 局部敏感(Locality Senstitive):即空间中距离较近的点映射后发生冲突的概率高,空间中距离较远的点映射后发生冲突的概率低. 局部敏感哈希的基本思想类似于一种空间域转换思 ...
- 局部敏感哈希-Locality Sensitive Hashing
局部敏感哈希 转载请注明http://blog.csdn.net/stdcoutzyx/article/details/44456679 在检索技术中,索引一直须要研究的核心技术.当下,索引技术主要分 ...
- 转:locality sensitive hashing
Motivation The task of finding nearest neighbours is very common. You can think of applications like ...
- 局部敏感哈希Locality Sensitive Hashing(LSH)之随机投影法
1. 概述 LSH是由文献[1]提出的一种用于高效求解最近邻搜索问题的Hash算法.LSH算法的基本思想是利用一个hash函数把集合中的元素映射成hash值,使得相似度越高的元素hash值相等的概率也 ...
- 局部敏感哈希-Locality Sensitivity Hashing
一. 近邻搜索 从这里开始我将会对LSH进行一番长篇大论.因为这只是一篇博文,并不是论文.我觉得一篇好的博文是尽可能让人看懂,它对语言的要求并没有像论文那么严格,因此它可以有更强的表现力. 局部敏感哈 ...
- 从NLP任务中文本向量的降维问题,引出LSH(Locality Sensitive Hash 局部敏感哈希)算法及其思想的讨论
1. 引言 - 近似近邻搜索被提出所在的时代背景和挑战 0x1:从NN(Neighbor Search)说起 ANN的前身技术是NN(Neighbor Search),简单地说,最近邻检索就是根据数据 ...
- Locality Sensitive Hash 局部敏感哈希
Locality Sensitive Hash是一种常见的用于处理高维向量的索引办法.与其它基于Tree的数据结构,诸如KD-Tree.SR-Tree相比,它较好地克服了Curse of Dimens ...
随机推荐
- ansible 2.7.1 快速开始
refer to 官方手册 https://docs.ansible.com/ansible/latest/modules/modules_by_category.html refer to 中文手册 ...
- C++面向对象程序设计_Part1
目录 C++历史 C++的组成 C++ 与 C 的数据和函数区别 基于对象与面向对象的区别 C++类的两个经典分类 头文件防卫式声明 头文件的布局 类的声明 类模板简介 内联(inline)函数 访问 ...
- BeanFactory和ApplicationContext的异同
相同: Spring提供了两种不同的IOC 容器,一个是BeanFactory,另外一个是ApplicationContext,它们都是Java interface,ApplicationContex ...
- SDOI 2015 约束个数和
Description: 共\(T \le 5 \times 10^4\)组询问, 每组询问给定\(n\)和\(m\), 请你求出 \[ \sum_{i = 1}^n \sum_{j = 1}^m \ ...
- zabbix学习系列之触发器
触发器的简介 监控项仅负责收集数据,而通常收集数据的目的还包括在某指标对应的数据超出合理范围时给相关人员发送告警信息,"触发器"正式 用于为监控项所收集的数据定义阈值 每一个触发器 ...
- 解决Linux下AES解密失败
前段时间,用了个AES加密解密的方法,详见上篇博客AES加密解密. 加解密方法在window上測试的时候没有出现不论什么问题.将加密过程放在安卓上.解密公布到Linuxserver的时候,安卓将加密的 ...
- 谈 API 的撰写 - 总览
背景 之前团队主要的工作就是做一套 REST API.我接手这个工作时发现那些API写的比较业余,没有考虑几个基础的HTTP/1.1 RFC(2616,7232,5988等等)的实现,于是我花了些时间 ...
- 重读金典------高质量C编程指南(林锐)-------第七章 内存管理
2015/12/10补充: 当我们需要给一个数组返回所赋的值的时候,我们需要传入指针的指针.当我们只需要一个值的时候,传入指针即可,或者引用也可以. 结构大致如下: char* p = (char*) ...
- 楼梯跳跃代码web
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- Skia构建系统与编译脚本分析
分析下Skia的构建系统,详细编译过程參看Windows下从源代码编译Skia.这里以ninja为例来分析.运行以下三条命令就能够完毕编译: SET "GYP_GENERATORS=ninj ...