Mongodb 基础 复制集原理和搭建
数据复制原理
开启复制集后,主节点会在local库下生成一个集合叫 oplog.rs,这是一个有限的集合,即大小固定。这个集合记入了整个mongod实例一段时间内数据库的所有变更操作(如:增/删/改),当空间用完时新的记入会覆盖最老的记录。而复制集的从节点就是通过读取主节点上面的oplog来实现数据同步的。oplog.rs的滚动覆盖写入有两种方式:一种是达到设定大小就开始覆盖写入;二是设定文档数量,达到文档数量就开始覆盖写入(不推荐使用)。
下图为复制集的工作方式:
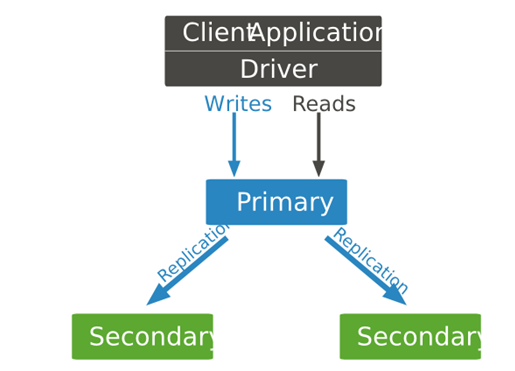
主节点和应用程序之间的交互是通过Mongodb驱动进行的,MongoDB复制集有自动故障转移功能,我们可以通过rs.isMaster()函数来识别谁是主节点。默认应用程序的读写都是在主节点上,默认情况下,读写都只能在主节点上进行。但是主压力过大时就可以把读操作分离到从节点从而提高性能。下面是MongoDB的驱动支持5种复制集读选项:
primary:默认模式,所有的读操作都在复制集的主节点进行的。
primaryPreferred:在大多数情况时,读操作在主节点上进行,但是如果主节点不可用了,读操作就会转移到从节点上执行。
secondary:所有的读操作都在复制集的从节点上执行。
secondaryPreferred:在大多数情况下,读操作都是在从节点上进行的,但是当从节点不可用了,读操作会转移到主节点上进行。
nearest:读操作会在复制集中网络延时最小的节点上进行,与节点类型无关。
但是除了primary 模式以外的复制集读选项都有可能返回非最新的数据,因为复制过程是异步的,从节点上应用操作可能会比主节点有所延后。如果我们不使用primary模式,请确保业务允许数据存在可能的不一致。
复制集写操作
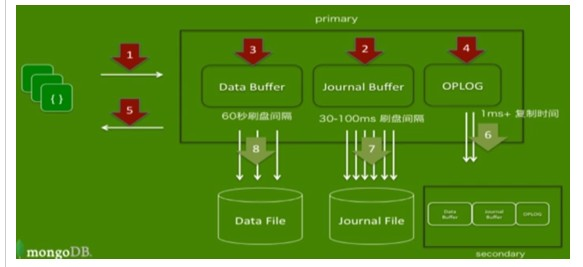
如果启用复制集的话,就在内存中会多一个oplog区域,是节点之间进行同步数据的手段,它会把操作日志放到oplog中,然后oplog会复制到从节点上,从节点接收并执行oplog上的操作记入,从而达到同步的效果:
步骤:
1.客户端的数据进来
2.数据操作写入日志缓冲
3.数据写入到数据缓冲
4.把日志缓冲中的操作放到oplog中
5.返回操作结果到客户端
6. 后台线程进行OPLOG复制到从节点,这个频率是非常高的,比日志刷盘频率还要高,从节点会一直监听主节点,OPLOG一有变化就会进行复制操作
7. 后台线程进行日志缓冲中的数据刷盘,非常频繁(默认100)毫秒,也可自行设置(30-60);
需要重点强调的是oplog只记录改变数据库状态的操作。比如,查询就不存储在oplog中。这是因为oplog只是作为从节点与主节点保持数据同步的机制。存储在oplog中的操作也不是完全和主节点的操作一模一样的,这些操作在存储之前先要做等幂变换,也就是说,这些操作可以在从服务器端多次执行,只要顺序是对的,就不会有问题。例如,使用“$inc”执行的增加更新操作,会被转换为“$set”操作。
如下图表示流程:
oplog大小
当你第一次启动复制集中的节点时,MongoDB会用默认大小建立Oplog。这个默认大小取决于你的机器的操作系统。大多数情况下,默认的oplog大小是足够的。在 mongod 建立oplog之前,我们可以通过设置 oplogSizeMB 选项来设定其大小。但是,如果已经初始化过复制集,已经建立了Oplog了,我们需要通过修改Oplog大小中的方式来修改其大小。
OpLog的默认大小:
- 在64位Linux、Windows操作系统上为当前分区可用空间的5%,但最大不会超过50G。
- 在64位的OS X系统中,MongoDB默认分片183M大小给Oplog。
- 在32位的系统中,MongoDB分片48MB的空间给Oplog。
复制时间窗口:
既然Oplog是一个封顶集合,那么Oplog的大小就会有一个复制时间窗口的问题。举个例子,如果Oplog是大小是可用空间的5%,且可以存储24小时内的操作,那么从节点就可以在停止复制24小时后仍能追赶上主节点,而不需要重新获取全部数据。如果说从节点在24小时后开始追赶数据,那么不好意思主节点的oplog已经滚动覆盖了,把从节点没有执行的那条语句给覆盖了。这个时候为了保证数据一致性就会终止复制。然而,大多数复制集中的操作没有那么频繁,oplog可以存放远不止上述的时间的操作记录。但是,再生产环境中尽可能把oplog设置大一些也不碍事。使用rs.printReplicationInfo()可以查看oplog大小以及预计窗口覆盖时间。
Oplog大小应随着实际使用压力而增加
如果我能够对我复制集的工作情况有一个很好地预估,如果可能会出现以下的情况,那么我们就可能需要创建一个比默认大小更大的oplog。相反的,如果我们的应用主要是读,而写操作很少,那么一个小一点的oplog就足够了。
下列情况我们可能需要更大的oplog。
同时更新大量的文档
Oplog为了保证 幂等性 会将多项更新(multi-updates)转换为一条条单条的操作记录。这就会在数据没有那么多变动的情况下大量的占用oplog空间。
删除了与插入时相同大小的数据
如果我们删除了与我们插入时同样多的数据,数据库将不会在硬盘使用情况上有显著提升,但是oplog的增长情况会显著提升。
大量In-Place更新
如果我们会有大量的in-place更新,数据库会记录下大量的操作记录,但此时硬盘中数据量不会有所变化。
Oplog幂等性
Oplog有一个非常重要的特性——幂等性(idempotent)。即对一个数据集合,使用oplog中记录的操作重放时,无论被重放多少次,其结果会是一样的。举例来说,如果oplog中记录的是一个插入操作,并不会因为你重放了两次,数据库中就得到两条相同的记录。
复制集数据同步过程
先通过initial sync同步全量数据,再通过replication不断重放Primary上的oplog同步增量数据。初始同步会将完整的数据集复制到各个节点上,Secondary启动后,如果满足以下条件之一,会先进行initial sync。
1. Secondary上oplog为空,比如新加入的空节点。
2. local.replset.minvalid集合里_initialSyncFlag标记被设置。当initial sync开始时,同步线程会设置该标记,当initial sync结束时清除该标记,故如果initial sync过程中途失败,节点重启后发现该标记被设置,就知道应该重新进行initial sync。
3. BackgroundSync::_initialSyncRequestedFlag被设置。当向节点发送resync命令时,该标记会被设置,此时会强制重新initial sync。
initial sync同步流程
1. minValid集合设置_initialSyncFlag(db.replset.minvalid.find())。
2. 获取同步源当前最新的oplog时间戳t0。
3. 从同步源克隆所有的集合数据。
4. 获取同步源最新的oplog时间戳t1。
5. 同步t0~t1所有的oplog。
6. 获取同步源最新的oplog时间戳t2。
7. 同步t1~t2所有的oplog。
8. 从同步源读取index信息,并建立索引(除了_id ,这个之前已经建立完成)。
9. 获取同步源最新的oplog时间戳t3。
10. 同步t2~t3所有的oplog。
11. minValid集合清除_initialSyncFlag,initial sync结束。
当完成了所有操作后,该节点将会变为正常的状态secondary。
Mongodb复制集的搭建
主节点(Primary)
在复制集中,主节点是唯一能够接收写请求的节点。MongoDB在主节点进行写操作,并将这些操作记录到主节点的oplog中。而从节点将会从oplog复制到其本机,并将这些操作应用到自己的数据集上。(复制集最多只能拥有一个主节点)
从节点(Secondaries)
从节点通过应用主节点传来的数据变动操作来保持其数据集与主节点一致。从节点也可以通过增加额外参数配置来对应特殊需求。例如,从节点可以是non-voting或是priority 0.
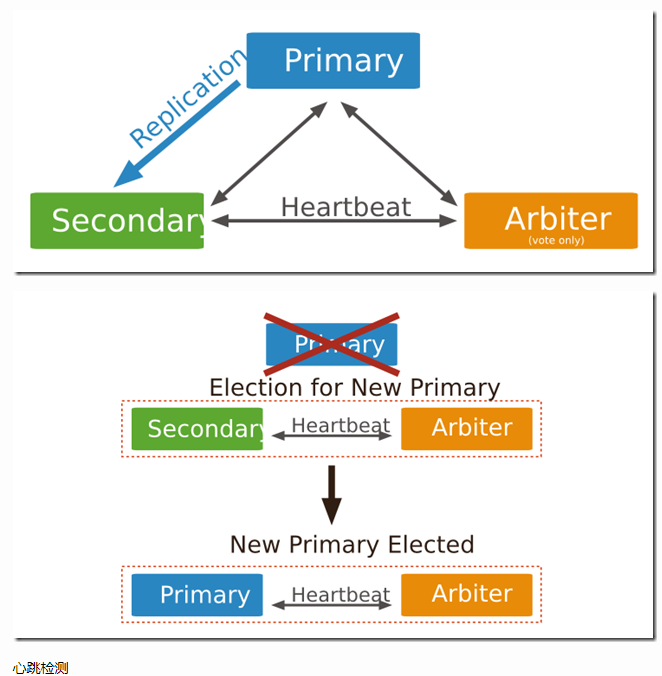
仲裁节点(ARBITER)
仲裁节点即投票节点,其本身并不包含数据集,且也无法晋升为主节点。但是,旦当前的主节点不可用时,投票节点就会参与到新的主节点选举的投票中。仲裁节点使用最小的资源并且不要求硬件设备。投票节点的存在使得复制集可以以偶数个节点存在,而无需为复制集再新增节点 不要将投票节点运行在复制集的主节点或从节点机器上。 投票节点与其他 复制集节点的交流仅有:选举过程中的投票,心跳检测和配置数据。这些交互都是不加密的。
注意:
仲裁节点(Arbiter)是复制集中的一个mongodb实例,它并不保存数据。仲裁节点使用最小的资源并且不要求硬件设备,不能将Arbiter部署在同一个数据集节点中,可以部署在其他应用服务器或者监视服务器中,也可部署在单独的虚拟机中。为了确保复制集中有奇数的投票成员(包括primary),需要添加仲裁节点做为投票,否则primary不能运行时不会自动切换primary。如下图所示;
配置文件准备
先为每一个节点创建数据目录和日志目录
[root@hdp4 ~]# mkdir mongodb1
[root@hdp4 ~]# mkdir mongodb2
[root@hdp4 ~]# mkdir mongodb3
[root@hdp4 ~]# mkdir mongodblog
创建配置文件:
每个节点都创建一个配置文件:
vim /usr/local/mongodb/mongodb1.conf
bind_ip=192.168.203.114
port=
dbpath=/root/mongodb1/ // 上面所创的数据目录
logpath=/root/mongodb/mongodb1.log // 再日志目录上创建日志文件
logappend=true
fork=true
maxConns=
replSet=haha // 复制集名称所有节点需要一样
vim /usr/local/mongodb/mongodb2.conf
bind_ip=192.168.203.114
port=
dbpath=/root/mongodb2/
logpath=/root/mongodb/mongodb2.log
logappend=true
fork=true
maxConns=
replSet=haha // 复制集名称所有节点需要一样
vim /usr/local/mongodb/mongodb3.conf
bind_ip=192.168.203.114
port=
dbpath=/root/mongodb3/
logpath=/root/mongodb/mongodb3.log
logappend=true
fork=true
maxConns=
replSet=haha // 复制集名称所有节点需要一样
启动mongod
用配置文件启动所有节点:
mongod -f /usr/local/mongodb/mongodb1.conf
mongod -f /usr/local/mongodb/mongodb2.conf
mongod -f /usr/local/mongodb/mongodb3.conf
初始化主节点:先用客户端进行连接
mongo --host 192.168.203.114 --port
>use admin;
初始化配置:
>config = {
_id: 'haha',
members: [
{_id: , host: '192.168.203.114:28017'},
{_id: , host: '192.168.203.114:28018'},
{_id: , host: '192.168.203.114:28019'}
]
}
>rs.initiate(config)
添加从节点
haha:PRIMARY>rs.add('192.168.203.114:27018');
添加仲裁节点
haha:PRIMARY> rs.addArb('192.168.203.114:27019');
查看状态
haha:PRIMARY> rs.status();
{
"set" : "haha",
"date" : ISODate("2019-03-13T12:34:14.813Z"),
"myState" : ,
"term" : NumberLong(),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -,
"heartbeatIntervalMillis" : NumberLong(),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
},
"appliedOpTime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
},
"durableOpTime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
}
},
"members" : [
{
"_id" : ,
"name" : "192.168.203.114:27017",
"health" : ,
"state" : ,
"stateStr" : "PRIMARY",
"uptime" : ,
"optime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
},
"optimeDate" : ISODate("2019-03-13T12:34:06Z"),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -,
"infoMessage" : "",
"electionTime" : Timestamp(, ),
"electionDate" : ISODate("2019-03-13T11:35:45Z"),
"configVersion" : ,
"self" : true,
"lastHeartbeatMessage" : ""
},
{
"_id" : ,
"name" : "192.168.203.114:27018",
"health" : ,
"state" : ,
"stateStr" : "SECONDARY",
"uptime" : ,
"optime" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
},
"optimeDurable" : {
"ts" : Timestamp(, ),
"t" : NumberLong()
},
"optimeDate" : ISODate("2019-03-13T12:34:06Z"),
"optimeDurableDate" : ISODate("2019-03-13T12:34:06Z"),
"lastHeartbeat" : ISODate("2019-03-13T12:34:14.366Z"),
"lastHeartbeatRecv" : ISODate("2019-03-13T12:34:13.931Z"),
"pingMs" : NumberLong(),
"lastHeartbeatMessage" : "",
"syncingTo" : "192.168.203.114:27017",
"syncSourceHost" : "192.168.203.114:27017",
"syncSourceId" : ,
"infoMessage" : "",
"configVersion" :
},
{
"_id" : ,
"name" : "192.168.203.114:27019",
"health" : ,
"state" : ,
"stateStr" : "ARBITER",
"uptime" : ,
"lastHeartbeat" : ISODate("2019-03-13T12:34:14.366Z"),
"lastHeartbeatRecv" : ISODate("2019-03-13T12:34:12.498Z"),
"pingMs" : NumberLong(),
"lastHeartbeatMessage" : "",
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -,
"infoMessage" : "",
"configVersion" :
},
],
"ok" :
}
以上就是Mongodb的复制集安装搭建。
注意:本片文章的前半部分原理是来源于:https://www.cnblogs.com/ExMan/p/9665060.html 笔者在这个基础上加上了搭建部分
Mongodb 基础 复制集原理和搭建的更多相关文章
- MongoDB复制集原理
版权声明:本文由孔德雨原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/136 来源:腾云阁 https://www.qclo ...
- MongoDB复制集原理、环境配置及基本测试详解
一.MongoDB复制集概述 MongoDB复制集实现了冗余备份和故障转移两大功能,这样能保证数据库的高可用性.在生产环境,复制集至少包括三个节点,其中一个必须为主节点,一个从节点,一个仲裁节点.其中 ...
- MongoDB之 复制集搭建
MongoDB复制集搭建步骤,本次搭建使用3台机器,一个是主节点,一个是从节点,一个是仲裁者. 主节点负责与前台客户端进行数据读写交互,从节点只负责容灾,构建高可用,冗余备份.仲裁者的作用是当主节点宕 ...
- mongodb之 复制集维护小结
原文地址:https://www.cnblogs.com/zhaowenzhong/p/5667312.html 一.新增副本集成员 1.登录primary 2.use admin >rs.ad ...
- mongodb配置复制集replset
Mongodb的replication主要有两种:主从和副本集(replica set).主从的原理和mysql类似,主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己 ...
- MongoDB 部署复制集(副本集)
部署MongoDB复制集(副本集) 环境 操作系统:Ubuntu 18.04 MongoDB: 4.0.3 服务器 首先部署3台服务器,1台主节点 + 2台从节点 3台服务器的内容ip分别是: 1 ...
- 利用Mongodb的复制集搭建高可用分片,Replica Sets + Sharding的搭建过程
参考资料 reference: http://mongodb.blog.51cto.com/1071559/740131 http://docs.mongodb.org/manual/tutori ...
- mongoDB的复制集5----复制集安全(认证,用户,权限)
一.什么是认证 如何开启认证 1).auth=true(在配置文件里增加) 2).keyFile(建议添加到配置文件里) #如果设置了auth=true,但第一次没有创建用户就启动实例怎 ...
- MongoDB学习4:MongoDB复制集机制和原理,搭建复制集
1.复制集的作用 1.1 MongoDB复制集的主要意义在于实现服务高可用 1.2 它的实现依赖于两个方面的功能: · 数据写入时将数据迅速复制到另一个独立节点上 · 在接收写入的 ...
随机推荐
- ASP.NET MVC文章系列
Summary of article list for ASP.NET MVC [Basic] Pro ASP.NET MVC chapter 2 http://www.cnblogs.com/yan ...
- JVM源码分析之栈溢出完全解读
概述 之所以想写这篇文章,其实是因为最近有不少系统出现了栈溢出导致进程crash的问题,并且很隐蔽,根本原因还得借助coredump才能分析出来,于是想从JVM实现的角度来全面分析下栈溢出的这类问题, ...
- 具有键“XXX”的 ViewData 项属于类型“System.Int32”,但它必须属于类型“IEnumerable<SelectListItem>
原因是Edit视图中有@Html.DropDownListFor(m => m.BirthdayAD... 但是没有从Controller中没有设置值
- 电子产品使用感受之--Windows 10 小米笔记本Air HDMI转VGA无信号问题
最近一直通过HDMI转VGA线缆链接我的戴尔P2314H显示器,前天睡觉前,看到电脑上英伟达显卡推了驱动更新,顺手更新了一下,就去睡觉了,转天晚上再用,HDMI接口就没有信号了,上网查了一些信息,获知 ...
- java整形数据和浮点型数据
在定义数据的时候,如果有不是整形的数据(单精度,双精度之类的),那么运算的时候要在其所在式子里的数据后面加上.0,否则会出现(1/2=0.1.0/2=0.5)的现象,比如如下代码 public cla ...
- [No0000166]CPU的组成结构及其原理
中央处理器(Central Processing Unit, CPU) CPU的基本架构和工作原理其实百科上讲得已经相当清楚了,不过我觉得有些事情呢还是给个例子出来比较方便学习.本文会先从内存地址,计 ...
- 函数调用堆栈及活动记录 堆栈溢出 stack overflow
小结: 1.当被调函数返回主调函数时,被调函数的 活动记录-activation record / 堆栈帧-stack frame 被 弹出-popping 程序执行栈-program executi ...
- xcrun: error: unable to find utility "PackageApplication", not a developer tool or in PATH
Xcode升级到8.3后 用命令进行打包 提示下面这个错误 xcrun: error: unable to find utility "PackageApplication", n ...
- cocos2dx 常用的构建工具
理编辑工具Physics Editing ToolsMekanimo 网址:http://www.mekanimo.net/PhysicsBench 网址:http://www.cocos2d-iph ...
- 《linux 文件目录》- touch/rm/mv/cat/head/tail/cp/mkdir/chmod/chown/find/locate/which/whereis
一:基本 / 根目录下目录结构定义 /bin 常见的用户指令 ls/echo ...... 等 /boot 内核和启动文件 /dev 设备文件 /etc 系统和服务配置文件 /home 用户家目录 / ...