浅谈Trie树
Trie树,也叫字典树。顾名思义,它就是一个字典
字典是干什么的?查找单词!(英文字典哦)
个人认为字典树这个名字起得特别好,因为它真的跟字典特别像,一会r你就知道了。
注:trie的中文翻译就是单词查找树
一、引入
先来看一个题:
给你n个单词构成一个字典,再给你一个单词,问此单词在字典中有没有出现。
简单,暴力!
时间复杂度:n*单词长度
再来看一个题:
给你n个单词构成一个字典,再给你m个单词,问这m个单词在字典中有没有出现。
再暴力!
时间复杂度:n*单词长度+m*n*单词长度
n≤1e4,m≤1e4,单词长度≤1e3
boom!
(╯‵□′)╯︵┻━┻
所以,为什么要学习使用Trie树?
因为它快!
二、概念
我们首先来看看Trie树是啥
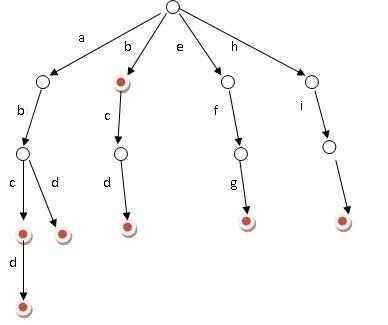
↑就是它
我们来解剖一下,好好研究研究(Trie树:瑟瑟发抖)
首先,我们发现树的每条边上都有一个字母
这就是Trie树的样子,每条边上都有一个字母,每个顶点代表从根到该节点的路径所对应的字符串(根结点除外)
其次,有些节点是红色的,有些则不是
这是什么意思呢?
结点不是代表单词嘛
所以如果结点标红,代表该单词在字典中实际出现过
如果看不太懂,不要紧,继续往下
三、插入单词(构建Trie树)
这里进入正题。第一步,构建trie树
就好比你想要查找单词,首先得有字典才行吧
step1:初始化
Trie树为空,只包含一个孤零零的根结点

step2:插入单词(注:这里假设所有单词仅由小写字母构成)
插入一个单词的步骤如下:
(1)对于Trie树,我们从根结点开始,设该节点为P;对于这个单词,我们从第一个字母开始,设此字符为s
(2)扫描P下方的所有边,看s有没有出现过
如果出现了,设s与P→Q这条边上的字符相同,则P=Q
如果没有出现,另建一条边,使该边上的字母为s,新节点为Q,然后P=Q
(3)s变为该单词的下一个字符,重复步骤2,直到扫描完整个单词为止
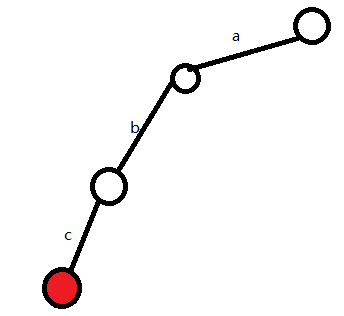
以概念中的那个图为例
首先我们要插入abc这个单词
(1)P为根结点,s为'a'
发现根结点下方无'a',所以新建一条边
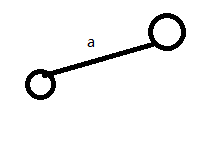
(2)P为a下方那个结点,s为'b'
发现P下方无'b',所以新建一条边
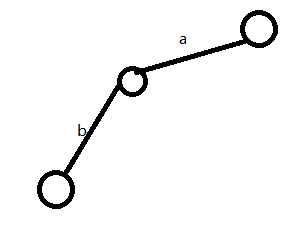
(3)P为b下方那个结点,s为'c'
发现P下方无'c',所以新建一条边
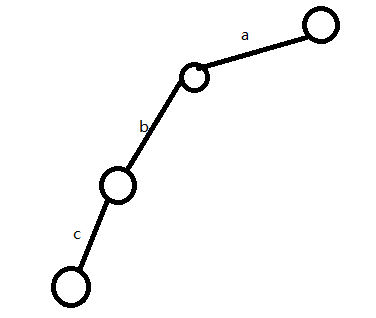
(4)发现abc这个单词插入完成,所以在当前的s做个标记,表示abc是一个出现过的单词
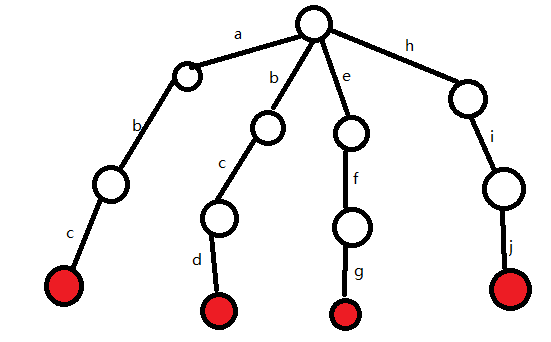
接着我们按照相同的步骤插入bcd、efg和hij
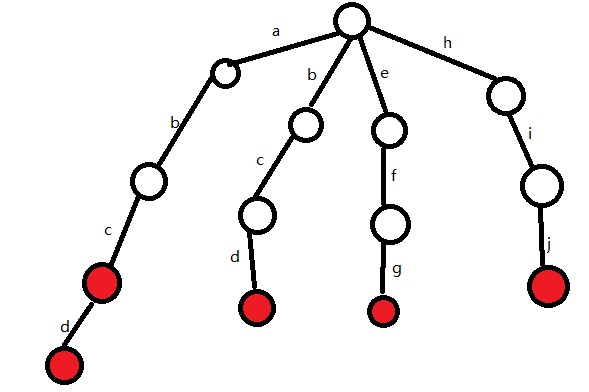
接下来插入abcd
(1)P为根结点,s为'a'
发现根结点下方有'a',所以P变为'a'下方的结点
(2)P为a下方那个结点,s为'b'
发现P下方有'b',所以P变为'b'下方的结点
(3)P为b下方那个结点,s为'c'
发现P下方有'c',所以P变为'c'下方的结点
(4)P为c下方那个红色的结点,s为'd'
发现P下方无'd',所以所以新建一条边
(5)单词abcd插入完毕,将当前的s做标记
下面按照相同的方法,继续插入单词abd和b
插入完成后Trie树如下:
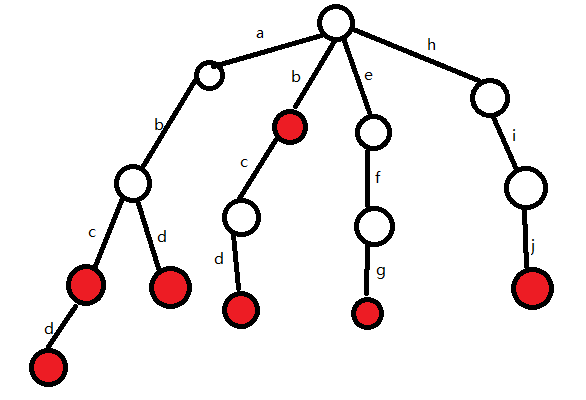
看看一样不:
(右下那条边应该是j)
我们可以发现,在Trie树中有相同前缀的单词共用相同的前缀,这样就可以大大的优化空间和时间
插入单词的时间复杂度为O(NE)(N为单词个数,E为单词长度)
参考代码:
void insert(char *s)//s为要插入的字符串
{
int len=strlen(s);
int u=;//1为根节点
for(int i=;i<len;i++)
{
int c=s[i]-'a';//'a'有时需换成'A'或'0'
if(!trie[u][c])//没有共同前缀,建立一个新的
ch[u][c]=++tot;//tot为总点数
u=ch[u][c];//继续向下插入单词
}
book[u]=true;//标记是一个出现过的单词(图中涂红色)
}
insert
四、查找单词
词典有了,接下来就可以查词了
在trie树中查单词就跟查字典一样。先查首字母,然后第二个,第三个……
查找过程跟插入的过程很像:
(1)对于Trie树,我们从根结点开始,设该节点为P;对于这个单词,我们从第一个字母开始,设此字符为s
(2)扫描P下方的所有边,看s有没有出现过
如果出现了,设s与P→Q这条边上的字符相同,则P=Q
如果没有出现,则该单词没有出现过,直接返回false
(3)s变为该单词的下一个字符,重复步骤2,直到扫描完整个单词为止
(4)扫描完成后,判断节点P有没有被标记(是不是某个出现过的单词的结尾)。如果标记了,那么该单词出现过,返回true;如果没有标记,那么该单词是词典中这个单词的前缀,返回false。
对于(4)讲解一下:
还是这棵Trie树:
我们查找ef这个单词:
(1)P为根结点,s为'e'
发现根结点下方有'e',所以P变为'e'下方的结点
(2)P为e下方那个结点,s为'f'
发现P下方有'f',所以P变为'f'下方的结点
(3)查找完成,发现P这里没有标记,所以ef是词典中单词efg的前缀,而不是直接出现在了词典里,返回false
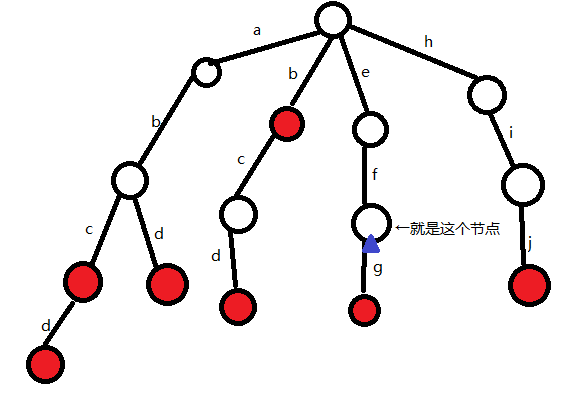
再举一个例子,我们查找abd这个单词:
(1)P为根结点,s为'a'
发现根结点下方有'a',所以P变为'a'下方的结点
(2)P为a下方那个结点,s为'b'
发现P下方有'b',所以P变为'b'下方的结点
(3)P为b下方那个结点,s为'd'
发现P下方有'd',所以P变为'd'下方的结点
(3)查找完成,发现P这里有标记,所以abd是词典中的单词,返回true
应该讲的挺明白的
查找的一个单词的时间复杂度O(E),比起暴力的O(NE)要快多了
参考代码:
bool find(char *s)//s为要查找的字符串
{
int len=strlen(s);
int u=;//1为根节点
for(int i=;i<len;i++)
{
int c=s[i]-'a';//'a'有时需换成'A'或'0'
if(!trie[u][c])//单词没有出现,直接返回false
return false;
u=ch[u][c];//继续向下查找单词
}
//如果扫描完了这个单词
return true;//是某个单词的前缀
}
查找单词是否是词典中某单词的前缀
bool find(char *s)//s为要查找的字符串
{
int len=strlen(s);
int u=;//1为根节点
for(int i=;i<len;i++)
{
int c=s[i]-'a';//'a'有时需换成'A'或'0'
if(!trie[u][c])//单词没有出现,直接返回false
return false;
u=ch[u][c];//继续向下查找单词
}
//如果扫描完了这个单词
return book[u];//如果出现过,返回true;如果没有出现过(是前缀),返回false
}
查找单词是否在词典中出现过
模板题:
https://www.cnblogs.com/llllllpppppp/p/9366344.html
本文部分图片来源于网络
部分内容参考《信息学奥赛一本通.提高篇》第二部分第三章 Trie字典树
若需转载,请注明https://www.cnblogs.com/llllllpppppp/p/9449846.html
~祝大家编程顺利~
浅谈Trie树的更多相关文章
- (转)浅谈trie树
浅谈Trie树(字典树) Trie树(字典树) 一.引入 字典是干啥的?查找字的. 字典树自然也是起查找作用的.查找的是啥?单词. 看以下几个题: 1.给出n个单词和m个询问,每次询问 ...
- 浅谈 trie树 及其实现
定义:又称字典树,单词查找树或者前缀树,是一种用于快速检索的多叉树结构, 如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树. 核心思想:是空间换时间.利用字符串的公共前缀来降低查询时间的开 ...
- 浅谈Trie树(字典树)
Trie树(字典树) 一.引入 字典是干啥的?查找字的. 字典树自然也是起查找作用的.查找的是啥?单词. 看以下几个题: 1.给出n个单词和m个询问,每次询问一个单词,回答这个单词是否在单 ...
- [转] 浅谈Trie树(字典树)
原文地址:https://www.cnblogs.com/TheRoadToTheGold/p/6290732.html Trie树(字典树) 一.引入 字典是干啥的?查找字的. 字典树自然也是起查找 ...
- 浅谈 trie树 及事实上现
定义:又称字典树,单词查找树或者前缀树,是一种用于高速检索的多叉树结构. 如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树. 核心思想:是空间换时间.利用字符串的公共前缀来减少查询时间的开 ...
- 浅谈B+树索引的分裂优化(转)
http://www.tamabc.com/article/85038.html 从MySQL Bug#67718浅谈B+树索引的分裂优化 原文链接:http://hedengcheng.com/ ...
- 浅谈oracle树状结构层级查询之start with ....connect by prior、level及order by
浅谈oracle树状结构层级查询 oracle树状结构查询即层次递归查询,是sql语句经常用到的,在实际开发中组织结构实现及其层次化实现功能也是经常遇到的,虽然我是一个java程序开发者,我一直觉得只 ...
- 浅谈oracle树状结构层级查询测试数据
浅谈oracle树状结构层级查询 oracle树状结构查询即层次递归查询,是sql语句经常用到的,在实际开发中组织结构实现及其层次化实现功能也是经常遇到的,虽然我是一个java程序开发者,我一直觉得只 ...
- 浅谈Trie
所谓\(Trie\)就是字典树. 何为字典树?想象一下我们平时用拼音查字法在字典树查汉字的时候,一位一位确定这个汉字的拼音从而翻到我们想要看的那一面. 所以\(Trie\)树跟字典一样,是一种逐位检索 ...
随机推荐
- hdoj:2024
#include <iostream> #include <string> #include <vector> using namespace std; int m ...
- (转)基于形状匹配的Halcon算子create_shape_model
HDevelop开发环境中提供的匹配的方法主要有三种,即Component-Based.Gray-Value-Based.Shape-Based,分别是基于组件(或成分.元素)的匹配,基于灰度值的匹配 ...
- Linux(C/C++)下的文件操作open、fopen与freopen
open是linux下的底层系统调用函数, fopen与freopen c/c++下的标准I/O库函数,带输入/输出缓冲. linxu下的fopen是open的封装函数,fopen最终还是要调用底层的 ...
- talk 1
话转偏锋 让别人可以接话, 同时可以设计转换到的话题, 把"谈话带到正确的轨道", 就像下象棋一样, 要看三步 A: 很喜欢看篮球比赛, 对B说 我每次都堵湖人队会赢 B: 篮球最 ...
- CentOS 7.4编译安装Nginx1.10.3+MySQL5.7.16
准备篇 一.防火墙配置 CentOS 7.x默认使用的是firewall作为防火墙,这里改为iptables防火墙. 1.关闭firewall: systemctl stop firewalld.se ...
- ubuntu安装anaconda后,终端输入conda,出现未找到命令
解决办法: 终端输入:vim ~/.bashrc 键盘大写“G”,在最末端输入:export PATH=~/anaconda2/bin:$PATH 使其生效:source ~/.bashrc 打印 ...
- Spark学习笔记——读写Hbase
1.首先在Hbase中建立一张表,名字为student 参考 Hbase学习笔记——基本CRUD操作 一个cell的值,取决于Row,Column family,Column Qualifier和Ti ...
- 面包屑 CSS
首先祝大家,在新年里,好的.善良的都都马上有. 关于css实现面包屑已经是一个典型例子了.不过今天还是与大家分享一下实现的原理.原理:每一段元素固定宽度并向左浮动,头尾突出部分相对父元素用相对定位固定 ...
- Flv的结构分析
Flv是网络上流行的非常广的一种媒体格式,很多大型媒体网站都在使用这种格式承载音视频信息,比如优酷等网站. Flv文件格式相对而言还是比较简单的,主要是由两部分组成 FLV header FLV bo ...
- k8s(1)-使用kubeadm安装Kubernetes
安装前准备 1. 一台或多台主机,这里准备三台机器 角色 IP Hostname 配置(最低) 操作系统版本 主节点 192.168.0.10 master 2核2G CentOS7.6.1810 工 ...