java集合与包装类
一.集合概述
1 为什么需要使用集合?
引入案例:存储每天产生的新闻。
是要解决数组的局限性(定长),由于数组定长,可能会导致内存浪费或者内存不够。
需要一种技术:能够根据数据量而动态伸缩内存空间一种技术。
与数组不同,没有长度限制
与数组不同,集合提供更多方便操作的方法
与数组不同,集合可以装不同类型的对象
2 什么是集合?
集合也叫容器,是用来装其它类型的对象元素的数据结构,有点类似数组
jdk提供一套容器框架,用来操作多个或者一组元素的容器
没有长度(元素个数)限制
集合提供一套各 种各样的api供我们选择,达到不同的操作目的
集合中的方法封装了一些算法,以便我们快速查找或者增删,或者排序。。。。
集合本身也是一个对象
二.如何研究集合?集合的API体系
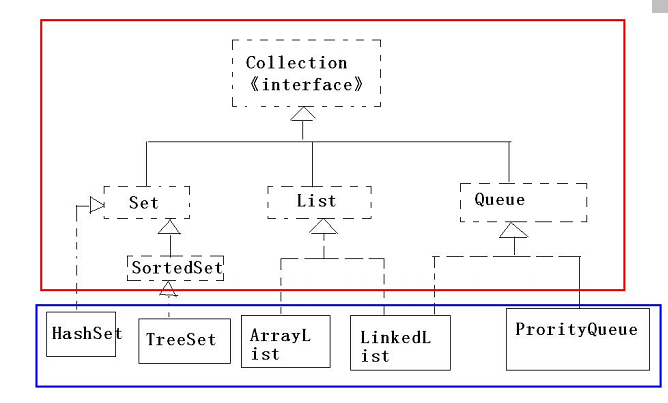
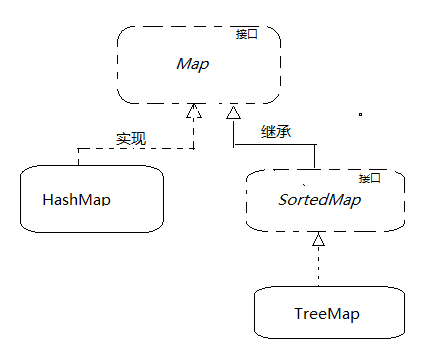
除了上面的集合图之外,还需学习以下接口和工具类:
(1)比较排序接口
Comparable
Comparator
(2)遍历迭代接口
Iterable
Iterator
(3)工具类
Collections
Arrays
面试题:Collection和Collections区别
11个接口7个实现类2个工具类
Collection VS Map
Collection - 元素是一个一个对象
Map - 元素是一对对的,由key对象与value对象组成
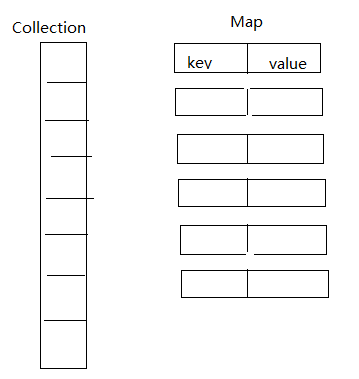
三.Collection
1 概述
Collection分支的根接口
所有这个分支下面的实现都具有该接口中的方法
在某些场合,使用Collection具有更普遍的适应性
Collection coll = new ?();
public void fn(Collection coll){
//.....
}
fn(?);
2 方法介绍
add() - 添加一个元素
addAll() - 添加一组元素
clear() - 清空整个集合
contains() -判断 是否包含某个元素
containsAll() - 判断 是否包含一组元素
equals() - 比较一个集合与另一个集合是否相同,挨个比较集合中所有元素
hashCode() - 返回此集合的哈希码
isEmpty() - 是不是size为0,元素的个数是不是为0
iterator() - 获得此集合的迭代器,用来遍历集合
remove() - 删除指定的元素
removeAll() - 删除一组指定的元素
retainAll() - 当前集合与指定集合(参数)求交集
size() - 返回元素个数
toArray() - 将集合转为数组
四.List
1 概述
有序的可重复的 collection(也称为序列)。内部维护一个索引(下标)。
此接口的用户可以对列表中每个元素的插入位置进行精确地控制。
用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素
有序,就是插入顺序(位置)
2 示意图
3 List的操作
除了具有Collection的所有方法外,还提供通过下标来操作的方法
add(int index, E element) - 将某个元素添加到指定的下标处
addAll(int index, Collection<? extends E> c) - 将一组元素添加到指定的下标处
get(int index) - 通过下标来获得某个具体的元素
indexOf(Object o) -获得指定元素的下标,从集合的头开始找
lastIndexOf(Object o) - 获得指定元素的下标,集合的尾部开始找
listIterator() - 返回List的特有的迭代器(ListIterator),ListIterator功能比较强大
remove(int index) -通过下标来删除元素
set(int index, E element) - 替换指定下标位置的元素
subList(int fromIndex, int toIndex) - 通过下标截取子集
五.ArrayList和LinkedList
1 概述
List 接口存储一组不唯一(里面元素可重复),有序(插入顺序)的对象
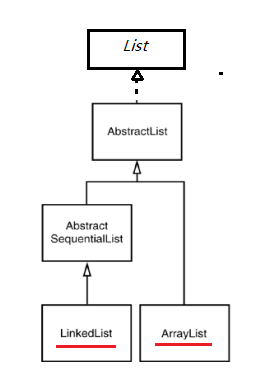
ArrayList(顺序表)类实现了长度可变的数组,在内存中分配连续的空间。遍历元素和随机访问元素的效率比较高

LinkedList类采用链表存储方式。插入、删除元素时效率比较高

这2个类是List的实现类,但并不是直接实现
2 ArrayList 和LinkedList的相关操作
(1)public ArrayList(int initialCapacity)//创建集合时,给定初始容量,以避免多余的数组重建。
int newCapacity = oldCapacity + (oldCapacity >> 1);
(2)public void ensureCapacity(int minCapacity)//给集合重新设置容量,以避免多余的数组重建。
(3)public void trimToSize() //ArrayList的尺寸是按照2的幂指数来增长的.比如你有17个元素,其实ArrayList是分了32空间,
//其中有15个是空的? trimToSize就是把这15个给砍掉了...
(4)在List中有很多操作都要判断指定的元素是否在集合中,例如contains(Object o), remove(Object o),indexOf(Object o),
这些方法内部都使用eqauls()来比较是否相同
3 ArrayList 和 LinkedList的区别
(1)ArrayList-查找快,增删慢
底层用数组实现,数组本身有下标,通过下标查找特别快,但是增删的因为要移动元素,所以很慢
(2)LinkedList - 查找慢,增删快
底层用双向链表实现,本身没有下标,需要额外的维护下标索引,导致查找非常慢。但是因为使用链表,增删只改变一下引用,不需要移动元素就可以做到增删,所以特别快
六.ArrayList与Vector区别:
相同点:
回顾:StringBuffer(线程安全) 与 StringBuilder(线程不安全)
1.两者都实现了List接口(List接口继承了Collection接口)。
2.两者都是有序集合,即存储在这两个集合中的元素的位置都是有顺序的,相当于一种动态的数组。
3.存放的数据都允许重复。
不同点:
1.同步性:
Vector是线程安全的,也就是说是它的方法之间是线程同步的,适用于多线程访问集合,访问效率低。
ArrayList是线程序不安全的,它的方法之间是线程不同步的,适用于单线程访问集合,不考虑线程安全,访问效率高。
2.数据增长:
Vector默认增长原来的一倍,可以手工设置增长空间的大小。
ArrayList默认增加原来的0.5倍,不可以手工设置增长空间的大小。
newCapacity = oldCapacity + oldCapacity >>1;//相当于 oldCapacity + oldCapacity /2
七.Queue与Stack
1 概述
叫队列,这种数据结构有一种特点,先进先出(FIFO)
与Stack(栈)相对,栈是先进后出(FILO)
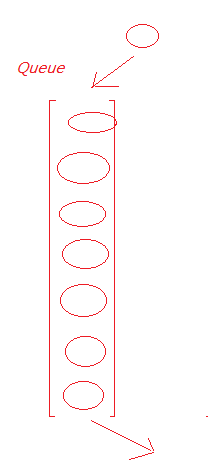
2 API方法
抛出异常 返回特殊值
插入 add(e) offer(e)
移除 remove() poll()
检查 element() peek()
八.LinkedList的队列的特点
public class TestQueue{
public static void main(String[] args){
//Queue q = new ArrayBlockingQueue(2);//有容量限制的队列
Queue q = new LinkedList();
/*
q.add("haha");
q.add("hehe");
q.add("xixi");
*/
q.offer("haha");
q.offer("hehe");
q.offer("xixi");
/*
System.out.println("==========1============>"+q);
Object o1 = q.remove();
System.out.println(o1+"==========2============>"+q);
Object o2 = q.remove();
System.out.println(o2+"==========3============>"+q);
Object o3 = q.remove();
System.out.println(o3+"==========4============>"+q);
Object o4 = q.remove();
*/
/*
System.out.println("==========1============>"+q);
Object o1 = q.poll();
System.out.println(o1+"==========2============>"+q);
Object o2 = q.poll();
System.out.println(o2+"==========3============>"+q);
Object o3 = q.poll();
System.out.println(o3+"==========4============>"+q);
Object o4 = q.poll();
*/
/*
System.out.println("==========1============>"+q);
Object o1 = q.element();
System.out.println(o1+"==========2============>"+q);
q.clear();//清空队列
Object o2 = q.element();
System.out.println(o2+"==========2============>"+q);
*/
System.out.println("==========1============>"+q);
Object o1 = q.peek();
System.out.println(o1+"==========2============>"+q);
q.clear();//清空队列
Object o2 = q.peek();
System.out.println(o2+"==========2============>"+q);
}
}
九.Set
1 Set概述
它是Collection子接口
特点是:无序的,不可重复
与List不同,Set没有下标
2 Set的API
全部方法都继承自Collection,没有自己扩展的方法
十.HashSet
(1)HashSet概述
是Set体系中比较常用的一个实现类
HashSet底层用的就是HashMap
HashMap是采用Hash算法的一种数据结构
Hash算法用快速寻找堆中的对象
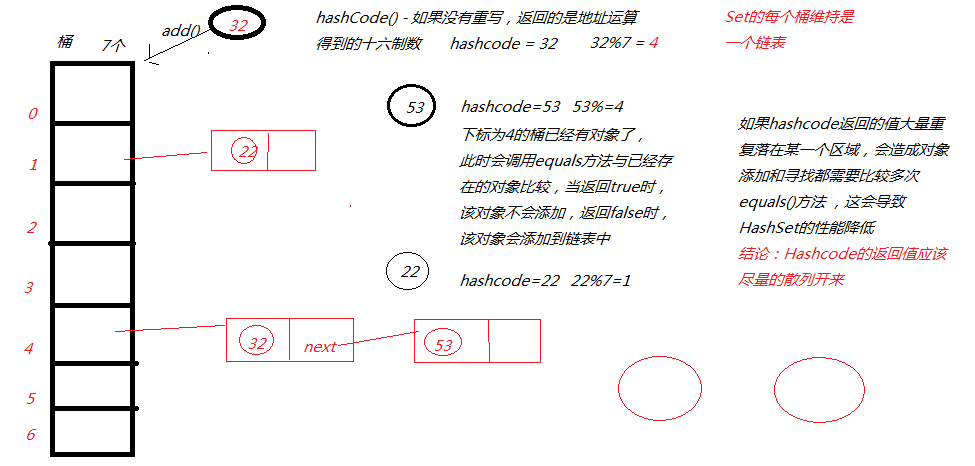
(2)HashSet数据结构
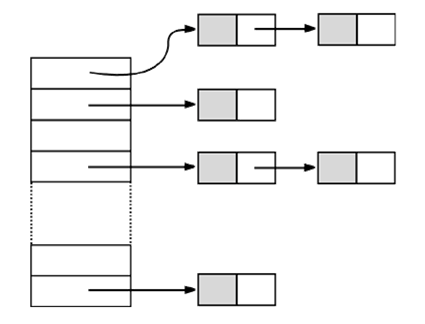
构造方法
1)初始容量 - 也叫桶
2)加载因子 - 扩充容量用的
当桶数用完时,需要扩展当前容量*加载因子
3)HashSet的add方法的流程
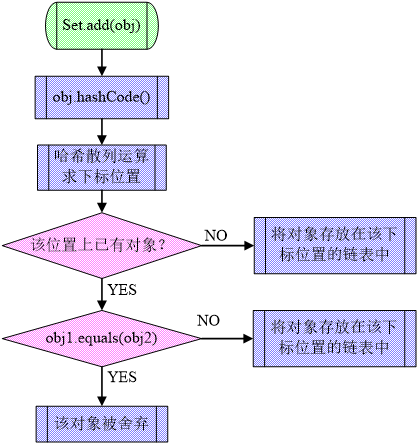
(4)equals()和hashCode的约定
hashCode()是Object中的方法 ,该方法是根据对象的地址值通过某种算法算出来的值
如果对象不同,则hashCode()返回的值一定不同
但是,作为开发者,我们经常需要主观上认为2个不同的对象为同一个,比如说姓名和年龄相同就认为是同一个,此前我们是用equals()定制这个主观的认同规则
api中equals方法的约定;注意:当equals方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码
api中hashCode的约定:equals中比较了哪些字段(属性),就用那些属性来生成hashCode就可以了
十一.Iterator
1 概述
迭代器,用于遍历集合,只要是实现了Collection接口,都一定具有iterator()方法,或者foreach方式遍历集合。该方法就是返回Iterator接口一个实例
2 Iterator操作
十二.LinkedHashSet
1 概述
Set接口下的一特例,它能够维持插入的顺序
此实现可以让客户免遭未指定的、由 HashSet 提供的通常杂乱无章的排序工作,而又不致引起与 TreeSet 关联的成本增加
2 LinkedHashSet操作
它的底层就是使用LinkedHashMap.
3 使用场合
如果我们的需求是元素不能重复,然后顺序是固定(插入顺序),此时就可以用LinkedHashSet
十三.排序树:TreeSet
1 概述
TreeSet底层就是使用TreeMap,它会按照自然顺序或比较器提供的顺序进行排序。
以二叉树的方式进行自然排序一个Set
Example:7, 5,2,4,12,13,8,15, 10,1
排序后:1 2 4 5 7 8 10 12 13 15
二叉树遍历方式:前序,中序,后序(递归算法)
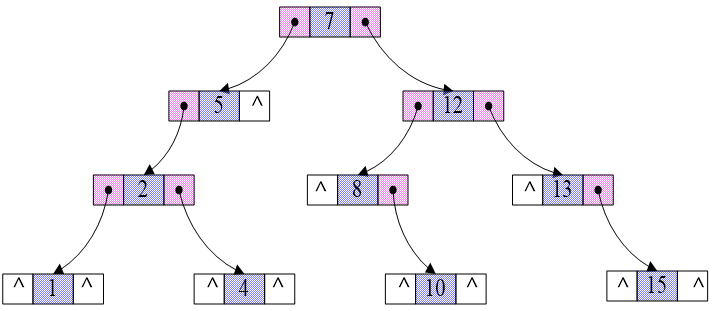
如果要使用TreeSet,则添加到里面的元素必须实现Comparable接口
或者提供定制的Comparator接口的实现,提供这了Comparator接口的实现后可以不用再实现Comparable接口!!!
十四.Comparable
1 概述
叫做可比较接口
实现该接口,表示这个类的对象是可以排序的,这种排序被称为类的自然排序,接口中的 compareTo 方法被称为它的自然比较方法
实际就是我们的类可以实现这个接口来定制自己的排序比较规则,例如Person是按age来排序
2 API方法
//开发者可以实现该方法来定制比较规则
//如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数
int compareTo(T o)
/**
重写定制自己的比较规则
先按年龄倒叙,如果年龄相等则按分数升序。
*/
public int compareTo(Object o) {
Student student = (Student) o;
if (this.age!=student.getAge()) {
return -(this.age-student.getAge());//按年龄倒叙
}else {
return this.score - student.getScore();//升序
}
}
十五.Comparator
1 概述
比较器接口,可以让开发者更加精确和灵活的控制排序
Collections.sort(Comparator)
Arrays.sort(Comparator)
TreeSet(Comparator) 2 API方法
/**
比较器1 ,按年龄倒叙
*/
class MyComparator implements Comparator<Student>{
public int compare(Student o1, Student o2) {
return -(o1.getAge()-o2.getAge());
}
}
/**
比较器2 ,按年龄倒叙,如果年龄相等,则按分数升序
*/
class MyComparator2 implements Comparator<Student>{
public int compare(Student o1, Student o2) {
if (o1.getAge()!=o2.getAge()) {
return -(o1.getAge()-o2.getAge());
}else {
return o1.getScore()-o2.getScore();
}
}
}
十六.Map
1 概述
映射,key - value
一个键(key) 决定一个值(value)
key不能重复,value可以重复
key没有顺序
2 Api方法
clear() - 清空Map
containsKey(Object key) - 是否包含指定的key
containsValue(Object value) - 是否包含指定的valie
entrySet() - 返回映射项(Map.Entry)组成的Set
equals(Object o) - 比较2个Map
get(Object key) - 通过key来获得value
hashCode() - 返回hash码
isEmpty() - 判断是否为空,其实就是判断 size==0
keySet() - 返回由key组成 的Set
put(K key, V value) - 将key和value添加到Map中
putAll(Map<? extends K,? extends V> m) - 将另一个Map中的所有key-value添加到本Map中
remove(Object key) -通过key来删除一对Entry
values() - 返回由所有的value组成的Collection
size() - 返回Map中的Entry的个数
十七.HashMap
1 概述
HashMap实现了Map接口
key也是跟HashSet一样,采用了哈希算法
HashSet底层用的就是HashMap
2 API操作
十八.HashMap和Hashtable区别:
1.同步性:
Hashtable是线程安全的,也就是说是它的方法之间是线程同步的,适用于多线程访问集合,访问效率低。
HashMap是线程序不安全的,它的方法之间是线程不同步的,适用于单线程访问集合,不考虑线程安全,访问效率高。
2.值
只有HashMap可以让你将null值作为一个表的条目的key或value
Hashtable是不允许的,运行时抛NullPointerException
3.Hashtable是Dictionary的子类,HashMap是Map接口的一个实现类;
十九.LinkedHashMap
可以对照着LinkedHashSet来学习,它的底层就是使用LinkedHashMap.
可以维持key-value插入的顺序
二十.TreeMap
参照TreeSet来学习,TreeSet底层就是使用TreeMap,它会按照自然顺序或比较器提供的顺序进行排序。
默认按照key的自然顺序排序
如果想更精确更活的排序,可以采用Comparator接口
二十一.Iterable:可迭代的
可迭代的接口
与Iterator有关系 ,实现了Iterable接口的类,必定会返回一个Iterator
所有的Collection都实现了Iterable
Iterable 创建 Iterator
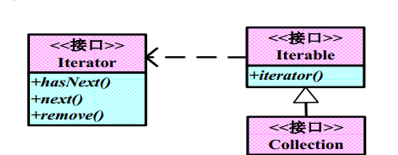
实现Iterable接口的类,都可以用ForEach来遍历
for(Object v : 实现了Iterable接口的类){
}
二十二.Collections
1 概述
Collections 是操作Collection的工具类,里面的方法都是static的,包括二分查找法,排序,反转,填充,打乱,生成不可变的集合。。。。
2 重点学习
binarySeach()-快速在List集合中查找指定的对象,前提是查找之前要对List先进行正排序,返回-1表示找不到指定的元素
sort() - 按自然排序
sort(Comparator) - 按比较器定制的规则来排序,可以用自定义比较器来实现排序,比如是倒叙排序。
reverse() - 将List集合的元素反转
fill() - 填充
shuffle() -打乱,打纸牌。
3.面试题:
Collection 和 Collections的区别。
Collections是个java.util下的类,它包含有各种有关集合操作的静态方法。
Collection是个java.util下的接口,它是各种集合结构的父接口。
public class TestCollections {
public static void main(String[] args) {
List list = new ArrayList();
list.add(2);
list.add(1);
list.add(5);
Collections.sort(list,new MyComparator());//按照比较器排序
System.out.println(list);
}
}
class MyComparator implements Comparator{
@Override
public int compare(Object o1, Object o2) {
int i1 = (Integer)o1;
int i2 = (Integer)o2;
return -(i1-i2);
}
}
二十三.Arrays
1 概述
用来操作数组的工具为在,包括填充,排序等等
2 API方法
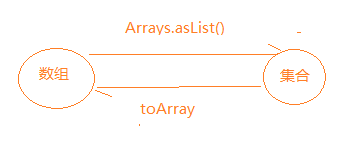
asList(T[] a) - 将一个数组转的转换成List,与Collection的toArray()方法
binarySearch() - 二分查找
copyOf() - 复制指定数组的指定个数的元素,形成一个新的数组
copyOfRange() - 复制指定数组的指定范围的元素,形成一个新的数组
equals()- 比较2个数组是否"相同"
fill() - 用指定的元素来填充数组
sort() - 排序,如果不传比较器(Comparator),则按自然排序(Comparable),如果传了Comparator,就按比较器规则排序
toString() - 将数组转成字符的格式
二十四.枚举接口:Enumeration
public static void main(String[] args) {
Vector v = new Vector();
v.add("java");
v.add("oracle");
v.add("linux");
v.add("html");
//Iterator
Enumeration<String> e = v.elements();
while(e.hasMoreElements()){
String s = e.nextElement();
System.out.println(s);
}
String s = null;
for(Enumeration<String> e2 = v.elements();e2.hasMoreElements();){
s = e2.nextElement();
System.out.println(s);
}
}
二十五.包装类
(1)概述
在java里,我们有八个基本数据类型,它们可以做各种运算,例如加减乘除。。。
但是这些基本数据类型没有更多的方法给开发者使用,所以Java对每个基本数据类型都提供一个包装类与之对应
byte - Byte
short - Short
int - Integer
long - Long
float - Float
double - Double
char - Character
boolean - Boolean
这也体现了java是一种完全面向对象的语言。
面试题:java提供了八大基本数据型的包装类,为什么还保留原来的基本数据类型?
1) 包装类型没有提供相应的(+,—,*,/等)运算方法
2) 包装类的对象比基本类型占用更多的内存
3)基本数据类型操作起来更加简单方便。
(2)封箱解箱
自动封箱解箱,是Jdk1.5开始提供的新特性
自动封箱:将基本类型自动包装成包装类,这个过程是由编译器自动完成
//想调用基本数据类型的更多功能,必须转换为相应的包装类型
Integer i = 6;//编译器:Integer i = new Integer(6);//自动封箱
System.out.println(i);
自动解箱:将包装类型自动转换成基本类型,这个过程是由编译器自动完成
//想更方便的操作,就解箱为基本数据类型,+-*/
Integer i2 = new Integer(7);
int i3 = i2;//编译器:int i3 = i2.intValue();//自动解箱
System.out.println(i3);
list.add(7);//自动封箱,相当于list.add(new Integer(7));
int i = list.get(0); //自动解箱,相当于int i = list.get(0).intValue(); 小心预防抛nullPoiterException
以下要小心,这样会抛nullPoiterException
Integer i = null;
int b = i;//相当于int b = null.intValude(); 所以抛nullPoiterException

(3)使用
/*
String s = "123";
int i1 = Integer.parseInt(s);
Integer i2 = Integer.valueOf(s);
*/ Scanner scan = new Scanner(System.in);
while(true){
String iStr = scan.nextLine();
int i = Integer.parseInt(iStr);
System.out.println("----->"+i);
String line = scan.nextLine();
System.out.println("String类型的:"+line);
}
(4)常量池
Integer这个包装类内部维护了一个常量池,类似String了维护常量池。
这个常量池能够缓存-128 ~ 127 这个范围的包装类对象,可以通过IntegerCatch查看常量池源码。
当我们创建一个新的在-128~127之间的值时,实际上是直接到常量池里去取。
Integer i3 = 112; //new Integer(112),会被放入常量池
Integer i4 = 112; //直接从常量池中取出已有对象
System.out.println(i3==i4);//true 同一个对象
Integer i3 = 130; //不会放入常量池,常量池只装-128 ~ 127的对象
Integer i4 = 130;
System.out.println(i3==i4);//false 注意:超过127不会被存到常量池中,会重新new一个对象。
而下面这2个代码不会去常量池去取
Integer i5 = new Integer(112);
Integer i6= new Integer(112);
System.out.println(i5==i6);
作用:
是为了方便快捷地创建某些对象而出现的,当需要一个对象时,就可以从池中取一个出来(如果池中没有则创建一个),则在需要重复重复创建相等变量时节省了很多时间。
要比较2个Integer对象是否相等,要用equals()方法
java集合与包装类的更多相关文章
- java集合框架1
1.综述 所有集合类都位于java.util包下.集合中只能保存对象(保存对象的引用变量).(数组既可以保存基本类型的数据也可以保存对象). 当我们把一个对象放入集合中后,系统会把所有集合元素都当成O ...
- 浅入深出之Java集合框架(上)
Java中的集合框架(上) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,如果已经有java基础的小伙伴可以直接跳到<浅入深出之Java集合框架 ...
- Java集合框架(一)
原文 http://www.jianshu.com/p/e31fb2600e4f 集合类存放于java.util包中,集合类存放的都是对象的引用,而非对象本身,出于表达上的便利,我们称集合中的对象就 ...
- JAVA (集合和数据结构)
Collection和Collections的区别: 1.java.util.Collection 是一个集合接口.它提供了对集合对象进行基本操作的通用接口方法.Collection接口在Java 类 ...
- 【Java集合系列】---ArrayList
开篇前言--ArrayList中的基本方法 前面的博文中,小编主要简单介绍java集合的总体架构,在接下来的博文中,小编将详细介绍里面的各个类,通过demo.对比,来对java集合类进行更加深入的理解 ...
- Java集合框架详解(全)
一.Java集合框架概述 集合可以看作是一种容器,用来存储对象信息.所有集合类都位于java.util包下,但支持多线程的集合类位于java.util.concurrent包下. 数组与集合的区别如下 ...
- Java集合必会14问(精选面试题整理)
前言:把这段时间复习的关于集合类的东西整理出来,特别是HashMap相关的一些东西,之前都没有很注意1.7 ->> 1.8的变化问题,但后来发现这其实变化挺大的,而且很多整理的面试资料都没 ...
- java集合框架综述
一.集合框架图 简化图: 说明:对于以上的框架图有如下几点说明 1.所有集合类都位于java.util包下.Java的集合类主要由两个接口派生而出:Collection和Map,Collection和 ...
- 超详细的java集合讲解
1 集合 1.1 为什么会出现集合框架 [1] 之前的数组作为容器时,不能自动拓容 [2] 数值在进行添加和删除操作时,需要开发者自己实现添加和删除. 1.2 Collection接口 1.2.1 C ...
随机推荐
- javascript性能优化之使用对象、数组直接量代替典型的对象创建和赋值
1.典型的对象创建和赋值操作代码示例 var myObject = new Object(); myObject.name = "Nicholas"; myObject.count ...
- JAVA线程sleep与wait区别
sleep就是正在执行的线程主动让出cpu,cpu去执行其他线程,在sleep指定的时间过后,cpu才会回到这个线程上继续往下执行,如果当前线程进入了同步锁,sleep方法并不会释放锁,即使当前线程使 ...
- Maven下用MyBatis Generator生成文件
使用Maven命令用MyBatis Generator生成MyBatis的文件步骤如下: 1.在mop文件内添加plugin <build> <finalName>KenShr ...
- promise、async和await之执行顺序
async function async1(){ console.log('async1 start') await async2() console.log('async1 end') } asyn ...
- SQL注入之Sqli-labs系列第二十八关(过滤空格、注释符、union select)和第二十八A关
开始挑战第二十八关(Trick with SELECT & UNION) 第二十八A关(Trick with SELECT & UNION) 0x1看看源代码 (1)与27关一样,只是 ...
- Django + nginx + uswgi 的部署总结
一.引言 自己小组内写了一个网站,需要部署到远程服务器,搜索了好多资料,但是大部分资料都比较繁琐,并且没有一个教程能够直接从头到尾适合,在部署过程中,我是按照很多教程然后综合试验着逐渐部署成功,其中有 ...
- redis集群cluster模式搭建
实验服务器 :192.168.44.139 192.168.44.138 192.168.44.144 在 192.168.44.139上操作: 将redis的包上传的新建的目录newtouc ...
- BF字符串匹配算法
Brute Force算法是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符: 若不相等,则比较S的第二个 ...
- 20165228 学习基础和C语言基础调查
========== 做中学读后感 我依然认为兴趣与自觉性是推动一个人进步的两大因素,他们之间的区别是"兴趣"带来的影响更多是主动性的学习,而"自觉"则是略显被 ...
- jquery使用ajax提交form表单
$.ajax({ type: jqform.attr('method'), // 提交方式 get/post url: jqform.attr('action'), // 需要提交的 url data ...