caffe中的fine-tuning
caffe finetune两种修改网络结构prototxt方法
第一种方法:将原来的prototxt中所有的fc8改为fc8-re。(若希望修改层的学习速度比其他层更快一点,可以将lr_mult改为原来的10倍或者其他倍数)
第二种方法:只修改name,如下例子所示:
layer {
name: "fc8-re" #原来为"fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
inner_product_param {
num_output: 5 #原来为"1000"
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
caffe是一个深度学习框架,在建立好神经网络模型之后,使用大量的数据进行迭代调参数获取到一个拟合的深度学习模型caffemodel,使用这个模型可以实现我们需要的任务。
所谓fine tune就是用别人训练好(通常是ImageNet上1000类分类训练)的模型参数的基础上,加上我们自己的数据和具体的分类识别任务来进行特定的微调,以训练新的模型。fine tune相当于使用别人的模型的前几层,来提取浅层特征,然后在最后再落入我们自己的分类中。
fine tune的好处在于不用完全重新训练模型,从而提高效率,因为一般新训练模型准确率都会从很低的值开始慢慢上升,但是fine tune能够让我们在比较少的迭代次数之后得到一个比较好的效果。在数据量不是很大的情况下,fine tune会是一个比较好的选择。但是如果你希望定义自己的网络结构的话,就需要从头开始了。
另外,finetuning需要的计算资源相对较少,使用的trikes相对较少,难度较低,比较适合caffe新手。在finetuning过程中熟悉caffe的各种接口和操作。
finetuning的过程和训练的过程步骤大体相同,因此在finetuning的过程中可以对caffe训练过程有一个详细的了解,通过一步步的训练和finetuning,在寻找最优参数过程中加深对caffe框架的理解,为自己后续自己从头开始训练一个caffe深度网络模型打好基础。
话不多说,具体的fine-tuning流程如下:
一、准备好自己的训练数据和测试数据;
二、计算数据集的均值文件,因为数据集中特定领域的图像均值文件会跟imagenet上比较general的数据的均值不太一样;
前面两步和平时我们训练时制作自己的数据一样;
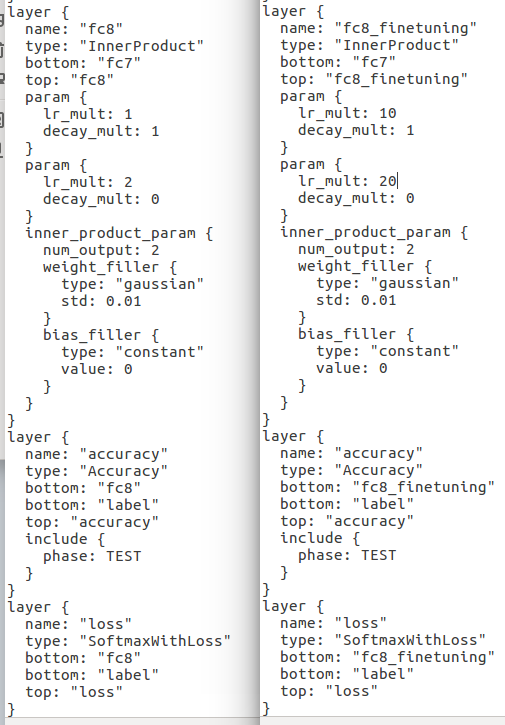
三、复制一份该model文件对应的prototxt文件进行修改,因为finetuning的过程是让原有训练好的模型适应自己的数据,因此一般情况下,网络的模型并没有大的变化。修改网络最后一层的网络名字(这样预训练模型赋值的时候就会因为名字的不同而重新训练,达到适应新任务的目的)和输出类别num_output,并且需要加快最后一层的参数学习速率(因为是最后一层要重新学习,所以将最后一层的weight和bias的lr_mult加快10倍),此外,和fc8相关的名字都要改掉;
四、调整solver文件的网络参数,通常学习数率和步长,迭代次数都要适当减少,这正式微调的本质所在;基本上就是将test_iter\base_lr\stepsize\max_iter进行相应地减小;
五、启动训练,并且需要加载pretrained模型的参数。在caffe根目录下运行: ./build/tools/caffe train -solver models/finetune_flickr_style/solver.prototxt -weights models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel -gpu 0
选取train函数,后面接具体的参数,分别为配置命令,配置文件路径,fine-tuning命令,fine-tuning依赖的基准模型文件目录,选用的训练方式:gpu或者cpu,使用cpu时可以默认不写。fine-tuning的过程与训练过程类似,只是在调用caffe接口时的命令不同,因此在fine-tuning之前,仍然需要按照训练流程准备数据:下载数据->生成trainset和testset->生成db->设置好路径->fine-tuning。这过程主要调用的是我们修改好的solver来自我们修改好的solver.prototxt文件,weights来自我们下载好的caffemodel。
caffe中的fine-tuning的更多相关文章
- (原)caffe中fine tuning及使用snapshot时的sh命令
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/5946041.html 参考网址: http://caffe.berkeleyvision.org/tu ...
- L23模型微调fine tuning
resnet185352 链接:https://pan.baidu.com/s/1EZs9XVUjUf1MzaKYbJlcSA 提取码:axd1 9.2 微调 在前面的一些章节中,我们介绍了如何在只有 ...
- caffe中权值初始化方法
首先说明:在caffe/include/caffe中的 filer.hpp文件中有它的源文件,如果想看,可以看看哦,反正我是不想看,代码细节吧,现在不想知道太多,有个宏观的idea就可以啦,如果想看代 ...
- 在caffe中使用hdf5的数据
caffe默认使用的数据格式为lmdb文件格式,它提供了把图片转为lmdb文件格式的小程序,但是呢,我的数据为一维的数据,我也要分类啊,那我怎么办?肯定有办法可以转为lmdb文件格式的,我也看了一些源 ...
- caffe中各层的作用:
关于caffe中的solver: cafffe中的sover的方法都有: Stochastic Gradient Descent (type: "SGD"), AdaDelta ( ...
- caffe中python接口的使用
下面是基于我自己的接口,我是用来分类一维数据的,可能不具通用性: (前提,你已经编译了caffe的python的接口) 添加 caffe塻块的搜索路径,当我们import caffe时,可以找到. 对 ...
- (原)torch和caffe中的BatchNorm层
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6015990.html BatchNorm具体网上搜索. caffe中batchNorm层是通过Batc ...
- (原)caffe中通过图像生成lmdb格式的数据
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/5909121.html 参考网址: http://www.cnblogs.com/wangxiaocvp ...
- CAFFE中训练与使用阶段网络设计的不同
神经网络中,我们通过最小化神经网络来训练网络,所以在训练时最后一层是损失函数层(LOSS), 在测试时我们通过准确率来评价该网络的优劣,因此最后一层是准确率层(ACCURACY). 但是当我们真正要使 ...
随机推荐
- Annoy 近邻算法
Annoy 随机选择两个点,以这两个节点为初始中心节点,执行聚类数为2的kmeans过程,最终产生收敛后两个聚类中心点 二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息 但是 ...
- springMVC源码分析--视图AbstractView和InternalResourceView(二)
上一篇博客springMVC源码分析--视图View(一)中我们介绍了简单介绍了View的结构实现及运行流程,接下来我们介绍一下View的实现类做的处理操作. AbstractView实现了rende ...
- 浅谈Phoenix在HBase中的应用
一.前言 业务使用HBase已经有一段时间了,期间也反馈了很多问题,其中反馈最多的是HBase是否支持SQL查询和二级索引,由于HBase在这两块上目前暂不支持,导致业务在使用时无法更好的利用现有的经 ...
- day15--JavaScript
上节作业回顾 <style></style>代表的是CSS样式 <script></script>代表的是JavaScript样式 1. ...
- Codeforces Round #429 (Div. 2) - D Leha and another game about graph
Leha and another game about graph 题目大意:给你一个图,每个节点都有一个v( -1 , 0 ,1)值,要求你选一些边,使v值为1 的点度数为奇数,v值为0的度数为偶数 ...
- Codeforces 535D - Tavas and Malekas
535D - Tavas and Malekas 题目大意:给你一个模板串,给你一个 s 串的长度,告诉你 s 串中有 m 个模板串并告诉你,他们的其实位置, 问你这样的 s 串总数的多少,答案对1e ...
- BZOJ4977 八月月赛 Problem G 跳伞求生 set 贪心
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ4977 - 八月月赛 Problem G 题意 小明组建了一支由n名玩家组成的战队,编号依次为1到n ...
- 【Java】 剑指offer(29) 顺时针打印矩阵
本文参考自<剑指offer>一书,代码采用Java语言. 更多:<剑指Offer>Java实现合集 题目 输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字. 思 ...
- Mybatis动态公用sql
<select id="collPageCount" parameterType="java.util.Map" resultType="lon ...
- java 如何用pattern 和 Matcher 来使用正则表达式
java的regex库 java里预留了一个regex库,方便于我们在java里操作正则表达式,或者用它来匹配字符串. 其中比较常用的就是 Pattern 和 Matcher ,pattern是一个编 ...