R语言——实验5-聚类分析
- 针对课件中的例子自己实现k-means算法
- 调用R语言自带kmeans()对给定数据集表示的文档进行聚类。
- 给定数据集:
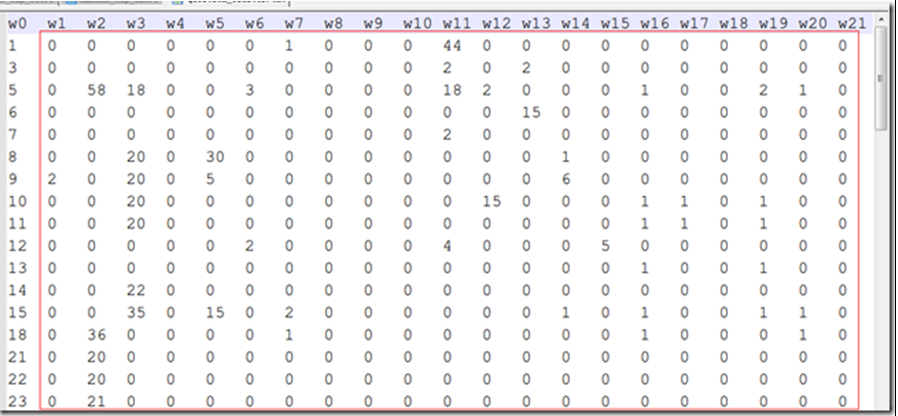
a) 数据代表的是文本信息。
b) 第一行代表词语,由于保密原因,词语已经被转意。第一列代表了文本的编号。
c) 红框中的数字为对应词的词频。
共113个样本,用K-Means算法将样本分为8类。
1、针对课件中的例子自己实现k-means算法
rm(list=ls())
#导入数据 id<-c(1:8)
x<-c(1,2,1,2,4,5,4,5)
y<-c(1,1,2,2,3,3,4,4)
inputdata<-data.frame(id,x,y) #计算距离函数
cal_distance<-function(x1,y1,x2,y2){
dis=(x1-x2)*(x1-x2)+(y1-y2)*(y1-y2)
dis=sqrt(dis)
return(dis)
} #假定随机选择的两个对象,如序号1和序号3当作初始点
center1=matrix(c(inputdata[1,2],inputdata[1,3]))
center2=matrix(c(inputdata[3,2],inputdata[3,3])) #一开始两个簇都是空的
cu1<-c()
cu2<-c() for(time in 1:5)
{
#遍历每一个点
for(i in 1:length(inputdata$id))
{
distance1=cal_distance(inputdata$x[i],inputdata$y[i],center1[1],center1[2])
distance2=cal_distance(inputdata$x[i],inputdata$y[i],center2[1],center2[2])
if(distance1<=distance2)
{
cu1<-c(cu1,i)
}
else
{
cu2<-c(cu2,i)
}
} #更新簇1的质心
sx=0
sy=0
for(i in 1:length(cu1))
{
sx=sx+inputdata$x[cu1[i]]
sy=sy+inputdata$y[cu1[i]]
}
center1[1]=sx*1.0/length(cu1)
center1[2]=sy*1.0/length(cu1) #更新簇2的质心
sx=0
sy=0
for(i in 1:length(cu2))
{
sx=sx+inputdata$x[cu2[i]]
sy=sy+inputdata$y[cu2[i]]
}
if(center2[1]==sx*1.0/length(cu2)&¢er2[2]==sy*1.0/length(cu2))
{
break
}
center2[1]=sx*1.0/length(cu2)
center2[2]=sy*1.0/length(cu2)
cu1<-c()
cu2<-c()
} cat("簇1质心: ",center1[1]," ",center1[2])
print("簇1包含的元素有: ")
for(i in 1:length(cu1))
{
print(cu1[i])
}
print("")
cat("簇2质心: ",center2[1]," ",center2[2])
print("")
print("簇1包含的元素有: ")
for(i in 1:length(cu2))
{
print(cu2[i])
}

2、 调用R语言自带kmeans()对给定数据集表示的文档进行聚类。
rm(list=ls())
setwd("C:/Users/Administrator/Desktop/R语言与数据挖掘作业/实验5-聚类分析")
data = read.table("data_cluster.txt")
kc <- kmeans(data, 8) #分类模型训练
print(kc)
#fitted(kc) #查看具体分类情况
#table(data$Species, data$cluster)#查看分类概括
R语言——实验5-聚类分析的更多相关文章
- R语言——实验4-人工神经网络
带包实现: rm(list=ls()) setwd("C:/Users/Administrator/Desktop/R语言与数据挖掘作业/实验4-人工神经网络") Data=rea ...
- R语言- 实验报告 - 利用R语言脚本与Java相互调用
一. 实训内容 利用R语言对Java项目程序进行调用,本实验包括利用R语言对java的.java文件进行编译和执行输出. 在Java中调用R语言程序.本实验通过eclipse编写Java程序的方式,调 ...
- R语言简单实现聚类分析计算与分析(基于系统聚类法)
聚类分析计算与分析(基于系统聚类法) 下面以一个具体的例子来实现实证分析.2008年我国其中31个省.市和自治区的农村居民家庭平均每人全年消费性支出. 根据原始数据对我国省份进行归类统计. 原始数据如 ...
- R语言 实验三 数据探索和预处理
计算缺失值个数 计算缺失率 简单统计量:计算最值 箱形图分析 分布分析:画出频率直方图 统计量分析:对于连续属性值,求出均值以及标准差 缺失值处理:删除法 去除 ...
- 社交网络分析的 R 基础:(一)初探 R 语言
写在前面 3 年的硕士生涯一转眼就过去了,和社交网络也打了很长时间交道.最近突然想给自己挖个坑,想给这 3 年写个总结,画上一个句号.回想当时学习 R 语言时也是非常戏剧性的,开始科研生活时到处发邮件 ...
- 用R语言对NIPS会议文档进行聚类分析
一.用R语言建立文档矩阵 (这里我选用的是R x64 3.2.2) (这里我取的是04年NIPS共计207篇文档做分析,其中文档内容已将开头的作者名和最后的参考文献进行过滤处理) ##1.Data I ...
- 实验的方差分析(R语言)
实验设计与数据处理(大数据分析B中也用到F分布,故总结一下,加深印象)第3课小结--实验的方差分析(one-way analysis of variance) 概述 实验结果\(S\)受多个因素\(A ...
- 独立成分分析(ICA)的模拟实验(R语言)
本笔记是ESL14.7节图14.42的模拟过程.第一部分将以ProDenICA法为例试图介绍ICA的整个计算过程:第二部分将比较ProDenICA.FastICA以及KernelICA这种方法,试图重 ...
- 数据分析与R语言
数据结构 创建向量和矩阵 函数c(), length(), mode(), rbind(), cbind() 求平均值,和,连乘,最值,方差,标准差 函数mean(), sum(), min(), m ...
随机推荐
- 《DSP using MATLAB》Problem 6.9
9月9日,我们怀念毛主席! 代码: %% +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ...
- debian 安装使用NTP
编程之路刚刚开始,错误难免,希望大家能够指出. 领导要求,要4台机器时钟同步,上网查了查,主要看了看ptp和ntp,感觉ntp就够用,索性就直接上手ntp了. 以下内容纯属最基础的内容,只适合第一次接 ...
- static关键字的使用(有个深刻领悟)
没有实例化对象的时候进行可以调用static 属性 static方法 (用类名去调用) 非static定义的方法可以调用static的属性或方法. static定义的方法不能调用非static的方法 ...
- hive GenericUDF1
和UDF相比,通用GDF(GenericUDF)支持复杂类型(比如List,struct等)的输入和输出. 下面来看一个小示例. Hive中whereme表中包含若干人的行程如下: A 2 ...
- day 52 js学习 DOM 和BOM
前戏 到目前为止,我们已经学过了JavaScript的一些简单的语法.但是这些简单的语法,并没有和浏览器有任何交互. 也就是我们还不能制作一些我们经常看到的网页的一些交互,我们需要继续学习BOM和DO ...
- Modularizing your graphQL schemas
转自: https://tomasalabes.me/blog/nodejs/graphql/2018/07/11/modularizing-graphql.html Modularizing you ...
- Pycharm主题设置以及导入方式
主题下载链接: http://www.themesmap.com/ pycharm -- 导入主题(theme) and 修改背景颜色(护眼色) 前情提要 众所周知,随着python语言的不断流行 ...
- C# 远程调用实现案例
C#远程调用实现案例 2007年11月19日 13:45:00 阅读数:6012 C#实现远程调用主要用到“System.Runtime.Remoting”这个东西.下面从三个方面给于源码实例. ·服 ...
- checkbox复选框,如何让其勾选时触发一个事件,取消勾选时不触发
<input type="checkbox" onclick="checkboxOnclick(this)" /> <script> f ...
- spring-整合Struts2
1. Spring 如何在 WEB 应用中使用 ? 1). 需要额外加入的 jar 包: spring-web-4.0.0.RELEASE.jarspring-webmvc-4.0.0.RELEASE ...