elastic客户端TransportClient的使用
关于TransportClient,elastic计划在Elasticsearch 7.0中弃用TransportClient,并在8.0中完全删除它。后面,应该使用Java高级REST客户端,它执行HTTP请求而不是序列化的Java请求。Java客户端主要用途有:
(1)在现有集群上执行标准索引,获取,删除和搜索操作
(2)在正在运行的集群上执行管理任务
获取Elasticsearch客户端最常用方法是创建连接到群集的TransportClient。
maven依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>6.4.3</version>
</dependency>
客户端必须具有与群集中的节点相同的主要版本(例如2.x或5.x)。客户端可以连接到具有不同次要版本(例如2.3.x)的群集,但可能不支持新功能。理想情况下,客户端应具有与群集相同的版本。此博客目前正在使用的版本是6.4.3。
获取TransportClient
TransportClient使用传输模块远程连接到Elasticsearch集群。它不加入集群,而只是获取一个或多个初始传输地址,并在每个操作上以循环方式与它们通信。
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.cluster.node.DiscoveryNode;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient; import java.net.InetAddress;
import java.net.UnknownHostException; public class Elasticsearch {
public static void main(String[] args) throws UnknownHostException {
//on startup
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//继续添加其他地址
//on shutdown
client.close();
}
}
如果出现:

说明需要配置日志
maven依赖
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency> 然后再resources里面添加log4j2.properties,内容如下:
appender.console.type = Console
appender.console.name = console
appender.console.layout.type = PatternLayout rootLogger.level = info
rootLogger.appenderRef.console.ref = console
如果出现"Exception in thread "main" java.lang.NoSuchMethodError: org.apache.logging.log4j.Logger.debug(Ljava/lang/String;Ljava/lang/Object;)", 则说明版本冲突,或者引的包是错的。
请注意,如果使用集群名称不是默认的“elasticsearch”,则必须设置集群名称, 通过对Settings经行设置:
Settings settings = Settings.builder()
.put("cluster.name", "myClusterName").build();
TransportClient client = new PreBuiltTransportClient(settings);
//Add transport addresses and do something with the client...
如果开启嗅探功能,即自动检测集群内其他的节点和新加入的节点,不需要全部都是用addTransportAddress添加,设置如下:
Settings settings = Settings.builder()
.put("client.transport.sniff", true).build();
TransportClient client = new PreBuiltTransportClient(settings);
Document APIs
Single document APIs
(1)Index api
import com.fasterxml.jackson.core.JsonProcessingException;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.transport.client.PreBuiltTransportClient; import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Date;
import java.util.HashMap;
import java.util.Map; public class Elasticsearch {
public static void main(String[] args) throws UnknownHostException, JsonProcessingException {
//on startup
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//继续添加其他地址
Map<String, Object> json = new HashMap<String, Object>();
json.put("user", "kimchy");
json.put("postDate", new Date());
json.put("message", "trying out Elasticsearch");
// index--twitter type--_doc id--1
IndexResponse indexResponse = client.prepareIndex("twitter", "_doc", "1").setSource(json, XContentType.JSON).get();
// Index name
String _index = indexResponse.getIndex();
// Type name
String _type = indexResponse.getType();
// Document ID (generated or not)
String _id = indexResponse.getId();
// Version (if it's the first time you index this document, you will get: 1)
long _version = indexResponse.getVersion();
// status has stored current instance statement.
RestStatus status = indexResponse.status();
//on shutdown
client.close();
}
}
实现了数据的插入
(2)GET API
get API允许根据其id从索引中获取类型化的JSON文档。以下示例从名为twitter的索引中获取JSON文档,该类型名为_doc`,id值为1:
import com.fasterxml.jackson.core.JsonProcessingException;
import org.elasticsearch.action.get.GetRequestBuilder;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.transport.client.PreBuiltTransportClient; import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Date;
import java.util.HashMap;
import java.util.Map; public class Elasticsearch {
public static void main(String[] args) throws UnknownHostException, JsonProcessingException {
//on startup
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//继续添加其他地址 GetResponse documentFields = client.prepareGet("twitter", "_doc", "1").get();
System.out.println(documentFields.getIndex());
System.out.println(documentFields.getType());
System.out.println(documentFields.getId());
System.out.println(documentFields.getSourceAsString());
//on shutdown
client.close();
}
}
输出结果:

(3)DELETE API
import com.fasterxml.jackson.core.JsonProcessingException;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequestBuilder;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.transport.client.PreBuiltTransportClient; import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Date;
import java.util.HashMap;
import java.util.Map; public class Elasticsearch {
public static void main(String[] args) throws UnknownHostException, JsonProcessingException {
//on startup
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//继续添加其他地址 DeleteResponse response = client.prepareDelete("twitter", "_doc", "1").get();
System.out.println(response.toString());
//on shutdown
client.close();
}
}
结果如下:
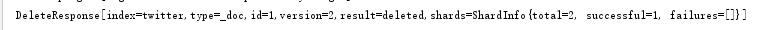
(4)Delete By Query API
import com.fasterxml.jackson.core.JsonProcessingException;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequestBuilder;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.reindex.BulkByScrollResponse;
import org.elasticsearch.index.reindex.DeleteByQueryAction;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.transport.client.PreBuiltTransportClient; import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Date;
import java.util.HashMap;
import java.util.Map; public class Elasticsearch {
public static void main(String[] args) throws UnknownHostException, JsonProcessingException {
//on startup
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//继续添加其他地址 BulkByScrollResponse response = DeleteByQueryAction.INSTANCE.newRequestBuilder(client)
.filter(QueryBuilders.matchQuery("user", "kimchy"))
.source("twitter")
.get();
long deleted = response.getDeleted(); //on shutdown
client.close();
}
}
以刚才那条index->twitter为例,此api先查询出满足条件的所有index,然后调用getDeleted函数删除相关的数据。
(5)Update API
可以使用prepareUpdate()方法
import com.fasterxml.jackson.core.JsonProcessingException;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequestBuilder;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.reindex.BulkByScrollResponse;
import org.elasticsearch.index.reindex.DeleteByQueryAction;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.transport.client.PreBuiltTransportClient; import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Date;
import java.util.HashMap;
import java.util.Map; import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder; public class Elasticsearch {
public static void main(String[] args) throws IOException {
//on startup
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//继续添加其他地址 client.prepareUpdate("twitter", "_doc", "1")
.setDoc(jsonBuilder()
.startObject()
.field("user", "chenmz")
.endObject())
.get();
//on shutdown
client.close();
}
}
用kibana查询后:
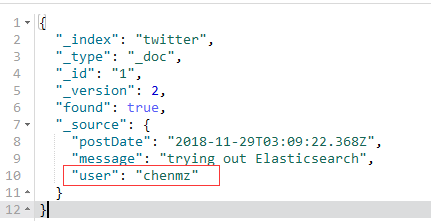
发现名字已经发生改变,更改成功。
Multi-document APIs
(1)Multi Get API
multi get API允许根据索引和id获取文档列表,往elastic中添加id为2的document,然后查询:
import com.fasterxml.jackson.core.JsonProcessingException;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequestBuilder;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.get.MultiGetItemResponse;
import org.elasticsearch.action.get.MultiGetResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.reindex.BulkByScrollResponse;
import org.elasticsearch.index.reindex.DeleteByQueryAction;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.transport.client.PreBuiltTransportClient; import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Date;
import java.util.HashMap;
import java.util.Map; import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder; public class Elasticsearch {
public static void main(String[] args) throws IOException {
//on startup
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//继续添加其他地址 MultiGetResponse multiGetItemResponses = client.prepareMultiGet()
.add("twitter", "_doc", "1", "2")
.get();
for (MultiGetItemResponse itemResponse : multiGetItemResponses) {
GetResponse response = itemResponse.getResponse();
if (response.isExists()) {
String json = response.getSourceAsString();
System.out.println(json);
}
} //on shutdown
client.close();
}
}
运行结果:

(2)Bulk API
批量API允许在单个请求中索引和删除多个文档。以下演示增加多个索引。
import com.fasterxml.jackson.core.JsonProcessingException;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequestBuilder;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.get.MultiGetItemResponse;
import org.elasticsearch.action.get.MultiGetResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.reindex.BulkByScrollResponse;
import org.elasticsearch.index.reindex.DeleteByQueryAction;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.transport.client.PreBuiltTransportClient; import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Date;
import java.util.HashMap;
import java.util.Map; import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder; public class Elasticsearch {
public static void main(String[] args) throws IOException {
//on startup
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//继续添加其他地址 BulkRequestBuilder bulkRequest = client.prepareBulk();
bulkRequest.add(client.prepareIndex("twitter", "_doc", "3")
.setSource(jsonBuilder()
.startObject()
.field("user", "zhangsan")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject()
)
); bulkRequest.add(client.prepareIndex("twitter", "_doc", "4")
.setSource(jsonBuilder()
.startObject()
.field("user", "lisi")
.field("postDate", new Date())
.field("message", "another post")
.endObject()
)
); BulkResponse bulkResponse = bulkRequest.get();
if (bulkResponse.hasFailures()) {
// process failures by iterating through each bulk response item
} //on shutdown
client.close();
}
}
然后查询,得到如下的结果:

说明批量添加索引成功。
(4)Reindex API
可以提供查询以过滤应该从源索引到目标索引重新索引哪些文档。就是在已有的索引当中选择一些放到另一个索引之中。
import com.fasterxml.jackson.core.JsonProcessingException;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequestBuilder;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.get.MultiGetItemResponse;
import org.elasticsearch.action.get.MultiGetResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.reindex.BulkByScrollResponse;
import org.elasticsearch.index.reindex.DeleteByQueryAction;
import org.elasticsearch.index.reindex.ReindexAction;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.transport.client.PreBuiltTransportClient; import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Date;
import java.util.HashMap;
import java.util.Map; import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder; public class Elasticsearch {
public static void main(String[] args) throws IOException {
//on startup
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//继续添加其他地址
BulkByScrollResponse response = ReindexAction.INSTANCE.newRequestBuilder(client).source("_all")
.destination("target_index")
.filter(QueryBuilders.matchQuery("user", "lisi")).get();
System.out.println(response.toString()); //on shutdown
client.close();
}
}
其中.source后面可以添加具体的索引.source("index1", "index2");等。
用Kibana查询结果如下:

生成一个target_index,下面多了一条user为lisi的document
ps:这边的主要面向Document APIs, 其实呢还有很多其他的api, elastic封装了很多的其他api也能达到同样的效果。
elastic客户端TransportClient的使用的更多相关文章
- Elastic Stack 笔记(八)Elasticsearch5.6 Java API
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 底层依赖于 Lucene 库,而 Lucene 库完全是 Java 编写的,前面的文章都是发送的 RESTf ...
- ES 03 - 初探Elasticsearch的主要配置文件(以6.6.0版本为例)
目录 1 elasticsearch.yml(ES服务配置) 1.1 Cluster集群配置 1.2 Node节点配置 1.3 Paths路径配置 1.4 Memory内存配置 1.5 Network ...
- Spring Data Elasticsearch 和 x-pack 用户名/密码验证连接
Elasticsearch Java API 客户端连接 一个是TransportClient,一个是NodeClient,还有一个XPackTransportClient TransportClie ...
- 搜索引擎框架之ElasticSearch基础详解(非原创)
文章大纲 一.搜索引擎框架基础介绍二.ElasticSearch的简介三.ElasticSearch安装(Windows版本)四.ElasticSearch操作客户端工具--Kibana五.ES的常用 ...
- Stack Overflow: The Architecture - 2016 Edition(Translation)
原文: https://nickcraver.com/blog/2016/02/17/stack-overflow-the-architecture-2016-edition/ 作者:Nick Cra ...
- Stack Overflow 2016最新架构探秘
这篇文章主要揭秘 Stack Overflow 截止到 2016 年的技术架构. 首先给出一个直观的数据,让大家有个初步的印象. 相比于 2013 年 11 月,Stack Overflow 在 20 ...
- 【转载】Stack Overflow: The Architecture - 2016 Edition
转载:http://www.infoq.com/cn/news/2016/03/Stack-Overflow-architecture-insi?utm_source=tuicool&utm_ ...
- 【ES】ElasticSearch初体验之使用Java进行最基本的增删改查~
好久没写博文了, 最近项目中使用到了ElaticSearch相关的一些内容, 刚好自己也来做个总结. 现在自己也只能算得上入门, 总结下自己在工作中使用Java操作ES的一些小经验吧. 本文总共分为三 ...
- zt (stack overflow 介绍)
这是「解密 Stack Overflow 架构」系列的第一篇,本系列会有非常多的内容.欢迎阅读并保持关注. 为了便于理解本文涉及到的东西到底都干些了什么,让我先从 Stack Overflow 每天平 ...
随机推荐
- 【iCore4 双核心板_ARM】例程十七:USB_MSC实验——读/写U盘(大容量存储器)
实验方法: 1.将跳线冒跳至USB_UART,通过Micro USB 线将iCore4 USB-UART接口与电脑相连. 2.打开PUTTY软件. 3.通过读U盘转接线将U盘(或者读卡器)与iCore ...
- [转]devm_gpiod_get_optional用法
https://blog.csdn.net/kris_fei/article/details/78932904
- springcloud-04-自定义ribbon的配置方式
在dubbo项目中, zookeeper即注册中心帮我们实现了调度和负载均衡的能力, 这种方式被称为服务器端的负载均衡, springcloud中, 使用ribben实现的客户端负载均衡 什么是rib ...
- 安卓开发笔记——个性化TextView(新浪微博)
这几天在仿写新浪微博客户端,在处理微博信息的时候需要处理关键字高亮和微博表情,查了一些资料,决定记录点东西 先来看下效果图: 像以上这种#话题#,@XXX昵称,HTTP:网页链接等元素,在微博里是被高 ...
- JQuery Easyui引入easyui-lang-zh_CN.js后出现乱码的问题解决方法
最近使用Easyui做项目,发现引入easyui-lang-zh_CN.js单元后页面会出现乱码,无论设置<meta>.还是Response都不能解决问题.用记事本打开easyui-lan ...
- [Laravel] 15 - REST API: sidebar with unit test
前言 实现一个博客的侧边栏的链接,然后顺便对其进行单元测试的过程. Archives 一.视图中展示SQL结果 一条 sql 语句[查询] select year(created_at) year, ...
- Flask框架(1)-程序基本结构
1. 安装Flask 1.1 安装虚拟环境 mkdir myproject cd myproject py -3 -m venv venv #Linux系统: python3 -m venv venv ...
- Android Selinux
https://blog.csdn.net/rikeyone/article/details/84337115 如何快速定位SElinux问题并修复? https://blog.csdn.net/ ...
- AutoFac记录
概念 Autofac是一个轻量级的依赖注入的框架,同类型的框架还有Spring.NET,Unity,Castle等: ContainerBuilder:将组件注册成服务的创建者. 组件:Lambda表 ...
- R和Tableau平行坐标图
R平行坐标图 library(lattice)data(iris)parallelplot( ~ iris[1:4], iris, groups = Species, horizontal.a ...