040 关于hive元数据的解析
一:原理
1.整体原理
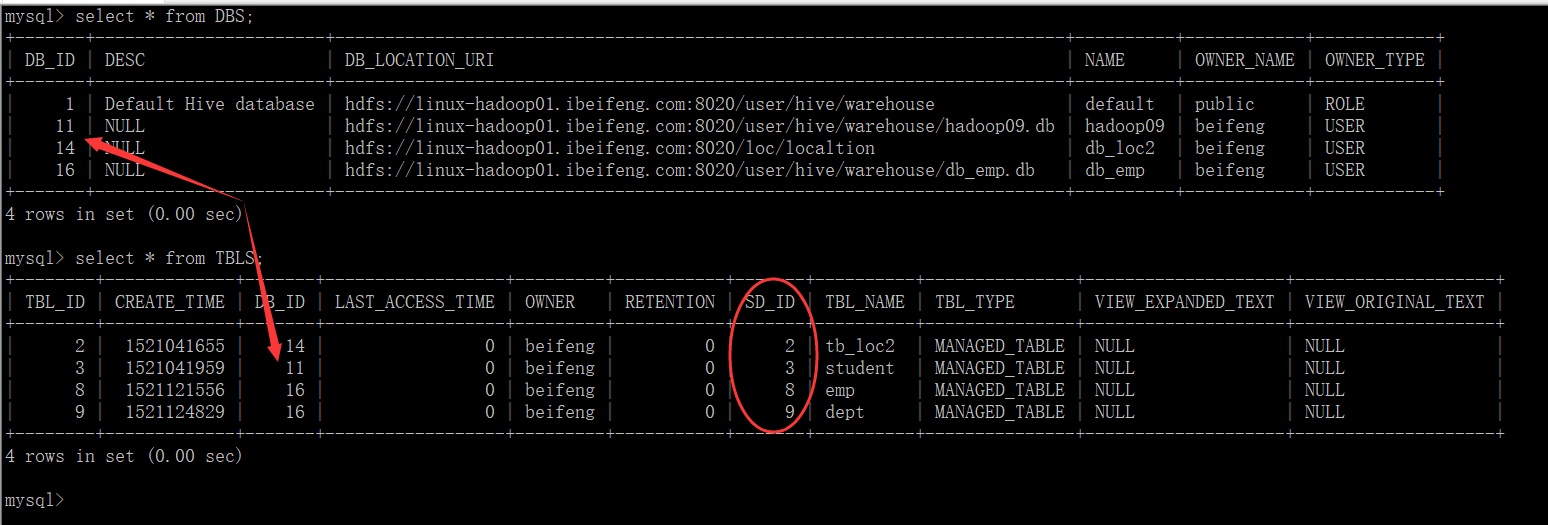
找到数据库
找到表
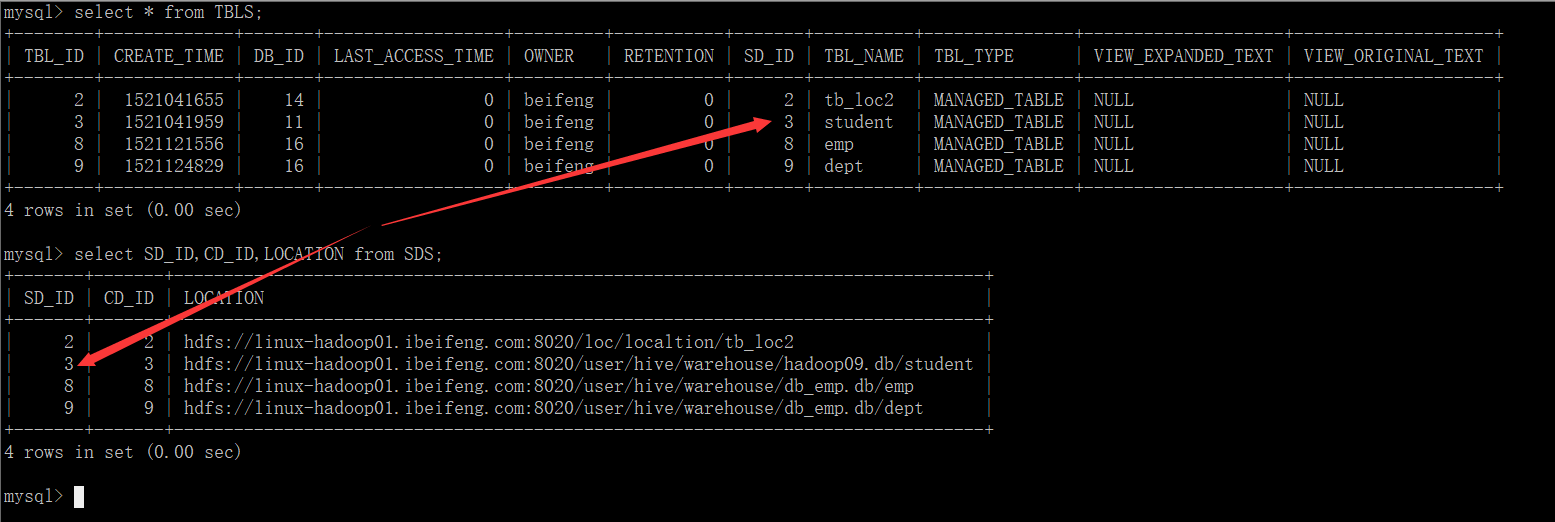
先找分区表,然后不找SDS表了,先去找PARTITIONS表,根据这张表的SD_ID找对应的HDFS路劲
再普通表,直接根据SDS表的中SD_ID找到对应的HDFS路径。
二:具体思路
1.登录metastore库
2.需要查询的表
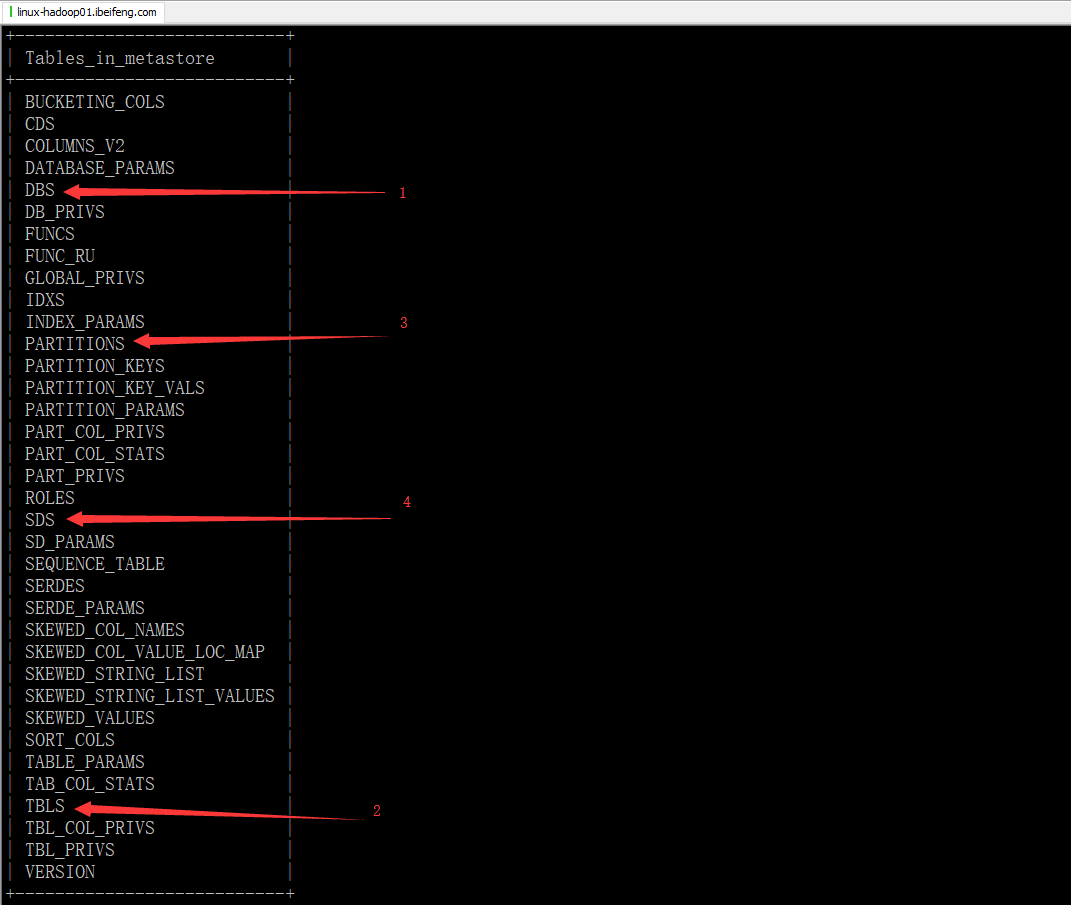
3.查询DBS;

4.查询TBLS
5.查询SDS;
这里没有分区表,就没先查分区表。
040 关于hive元数据的解析的更多相关文章
- hive 元数据解析
在使用Hive进行开发时,我们往往需要获得一个已存在hive表的建表语句(DDL),然而hive本身并没有提供这样一个工具. 要想还原建表DDL就必须从元数据入手,我们知道,hive的元数据并不存放在 ...
- 大数据学习(11)—— Hive元数据服务模式搭建
这一篇介绍Hive的安装及操作.版本是Hive3.1.2. 调整部署节点 在Hadoop篇里,我用了5台虚拟机来搭建集群,但是我的电脑只有8G内存,虚拟机启动之后卡到没法操作,把自己坑惨了. Hive ...
- 如何监听对 HIVE 元数据的操作
目录 简介 HIVE 基本操作 获取 HIVE 源码 编译 HIVE 源码 启动 HIVE 停止 HIVE 监听对 HIVE 元数据的操作 参考文档 简介 公司有个元数据管理平台,会定期同步 HIVE ...
- hive元数据研究
hive的元数据存放在关系型数据库中,元数据中存储了hive中所有表格的信息,包括表格的名字,表格的字段,字段的类型,注释.这些信息分散的存放在各个表中,给定一个hive中的表格名字,查询这个表中含有 ...
- spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据 目的:在spark on yarn模式下,执行spark-sql访问hive的元数据.并对比一下spark-sql 和hive ...
- Hive元数据启动失败,端口被占用
org.apache.thrift.transport.TTransportException: Could not create ServerSocket on address 0.0.0.0/0. ...
- 使用Hive的正则解析器RegexSerDe分析nginx日志
1.环境: hadoop-2.6.0 + apache-hive-1.2.0-bin 2.使用Hive分析nginx日志,站点的訪问日志部分内容为: cat /home/hadoop/hivetest ...
- Hive源码解析
date: 2020-07-08 15:12:00 updated: 2020-08-21 17:38:00 Hive源码解析 入口:hive-cli-1.1.0-cdh5.14.4.jar!/org ...
- Hive实现自增序列及常见的Hive元数据问题处理
Hive实现自增序列 在利用数据仓库进行数据处理时,通常有这样一个业务场景,为一个Hive表新增一列自增字段(比如事实表和维度表之间的"代理主键").虽然Hive不像RDBMS如m ...
随机推荐
- 第三次实验计算分段函数 第四次计算分段函数和循环NEW 第五次分支+循环加强版 实验报告
一.实验题目,设计思路,实现方法 第四次分支+循环 加强版 (2-2计算个人所得税,2-7 装睡,2-8计算天数) 设计思路:2-2 用if-else的语句,与计算分段函数的题类似的做法:2-7 运用 ...
- dp填表法,刷表法
填表法:利用上一状态推当前 刷表法:利用当前推关联,利用刷表法较为便捷,向上边界较容易处理,处理在本次循环中的影响
- luogu 1052 过河
神仙的博客,先copy了日后绝对删掉的,(因为我实在没耐心看懂啊..) 题解 step 1理解题意 在做这道题之前,一定要理解好题意,有一个需要特别注意注意的地方: 青蛙不是一定要跳到石头上[嗯... ...
- POJ 2513 Colored Sticks (欧拉回路+并查集+字典树)
题目链接 Description You are given a bunch of wooden sticks. Each endpoint of each stick is colored with ...
- 【Mysql sql inject】POST方法BASE64编码注入write-up
翻到群里的小伙伴发出一道POST型SQL注入题,简单抓包判断出题目需要base64编码后才执行sql语句,为学习下SQL注入出题与闯关的思路+工作不是很忙,所以花点时间玩了一下,哈哈哈哈哈哈哈哈哈 ...
- Linux Kernel 代码艺术——编译时断言【转】
转自:http://www.cnblogs.com/hazir/p/static_assert_macro.html 本系列文章主要写我在阅读Linux内核过程中,关注的比较难以理解但又设计巧妙的代码 ...
- linux统计某个特定文件名的大小总和【原创】
[hch@EAISRVBJ2 log]$find ./ -name "test_chs_00*"|xargs du -ck|grep total|awk 'BEGIN{sum=0} ...
- 【转】OpenCV—imread读取数据为空
之前遇到一个很郁闷的问题,因为从用OpenCV2.3.1改成OpenCV2.4.4,开始改用Mat和imread来代替Iplimage和cvLoadImage,出了点小问题:imread读入数据总是为 ...
- maven项目提示web.xml is missing或红色感叹号
1.web.xml is missing and <failOnMissingWebXml> is set to true 提示信息应该能看懂.也就是缺少了web.xml文件,<fa ...
- mysql数据库查询库中所有表所占空间大小
SELECT CONCAT(table_schema,'.',table_name) AS 'TABLE_NAME', CONCAT(, ),'M') AS 'ROW_SIZE', CONCAT( ) ...