008 Spark中standalone模式的HA(了解,知道怎么配置即可)
standalone也存在单节点问题,这里主要是配置两个master。
1.官网

2.具体的配置

3.配置方式一(不是太理想)
这种知识基于未来可以重启,但是不能在宕机的时候提供服务。
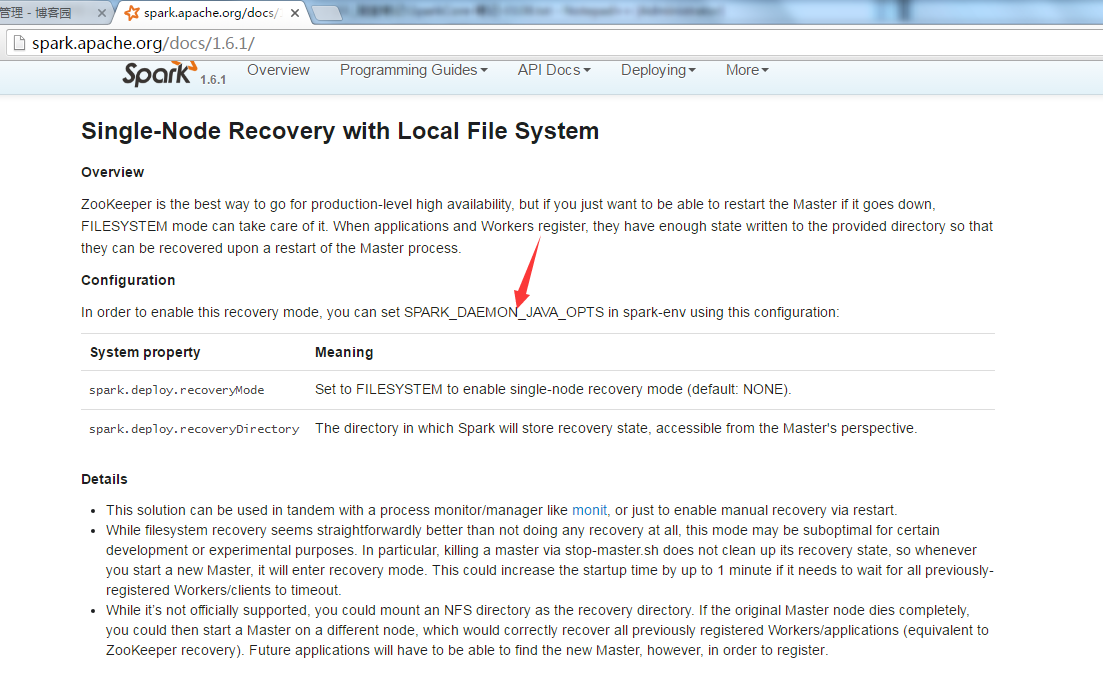
方式一:Single-Node Recovery with Local File System
类似于Hadoop1中的SecondaryNameNode
当出现单点故障的时候,需要手动启动master,然后master会读刚刚断掉之前的日志,类似于secondarynamenode方式。
做法:
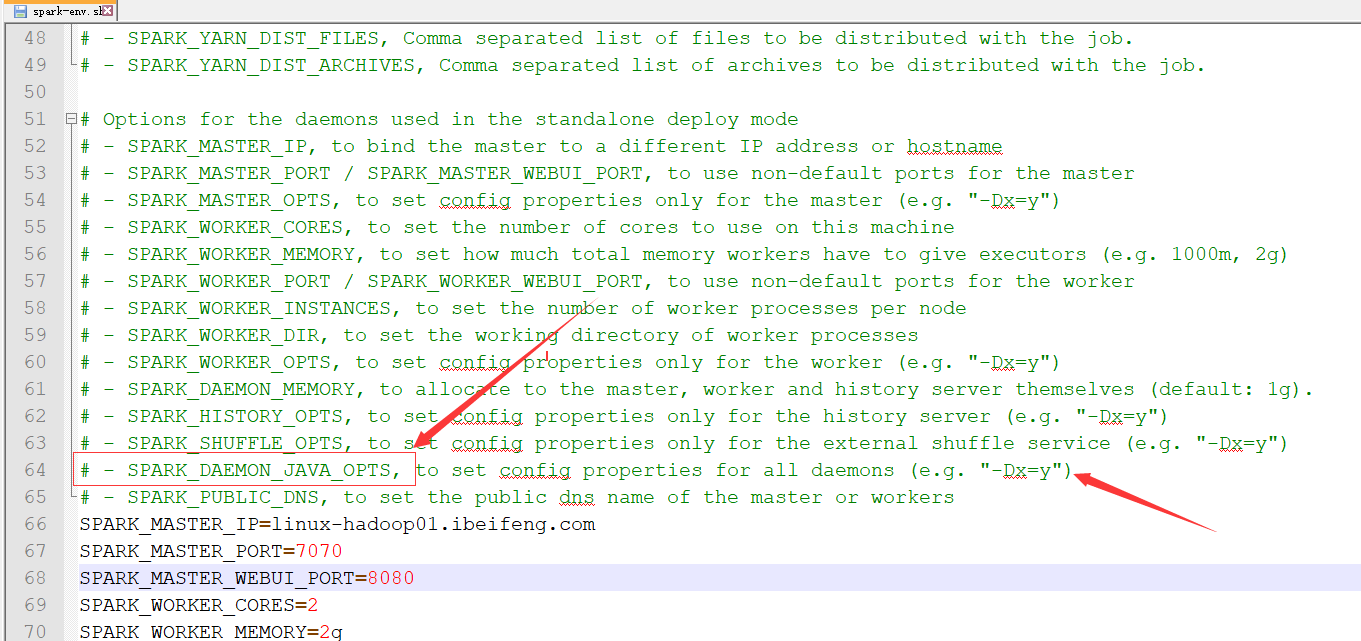
1. 修改conf/sparn-env.sh配置文件,打开conf/sparn-env.sh
2. 给参数SPARK_DAEMON_JAVA_OPTS添加配置参数
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/tmp/xxxx"
一个参数是恢复模式,一个参数是恢复路劲
4.配置方式二(比较给力)
方式二:Standby Masters with ZooKeeper
类似于Hadoop2中的NameNode的HA机制,因此会自动转移
做法:
1. 修改conf/sparn-env.sh配置文件
2. 给参数SPARK_DAEMON_JAVA_OPTS添加配置参数
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop-senior01:2181,hadoop-senior02:2181,hadoop-senior03:2181 -Dspark.deploy.zookeeper.dir=/spark"

008 Spark中standalone模式的HA(了解,知道怎么配置即可)的更多相关文章
- Spark部署三种方式介绍:YARN模式、Standalone模式、HA模式
参考自:Spark部署三种方式介绍:YARN模式.Standalone模式.HA模式http://www.aboutyun.com/forum.php?mod=viewthread&tid=7 ...
- 【Spark篇】--Spark中Standalone的两种提交模式
一.前述 Spark中Standalone有两种提交模式,一个是Standalone-client模式,一个是Standalone-master模式. 二.具体 1.Standalon ...
- Spark的StandAlone模式原理和安装、Spark-on-YARN的理解
Spark是一个内存迭代式运算框架,通过RDD来描述数据从哪里来,数据用那个算子计算,计算完的数据保存到哪里,RDD之间的依赖关系.他只是一个运算框架,和storm一样只做运算,不做存储. Spark ...
- 【Spark】Spark的Standalone模式安装部署
Spark执行模式 Spark 有非常多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则执行在集群中,眼下能非常好的执行在 Yarn和 Mesos 中.当然 Spark 还有自带的 St ...
- spark运行模式之二:Spark的Standalone模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- 【Spark篇】---Spark中yarn模式两种提交任务方式
一.前述 Spark可以和Yarn整合,将Application提交到Yarn上运行,和StandAlone提交模式一样,Yarn也有两种提交任务的方式. 二.具体 1.yarn-clien ...
- Spark之standalone模式
standalone hdfs:namenode是主节点进程,datanode是从节点进程 yarn:resourcemanager是主节点进程,nodemanager是从节点进程 hdfs和yarn ...
- Spark在StandAlone模式下提交任务,spark.rpc.message.maxSize太小而出错
1.错误信息org.apache.spark.SparkException: Job aborted due to stage failure:Serialized task 32:5 was 172 ...
- Spark:Master High Availability(HA)高可用配置的2种实现
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障的问题.如何解决这个单点故障的问题,Spar ...
随机推荐
- [C++]指针与引用(定义辨析)
1.定义: 1.1 &-----取地址运算符 功能:返变量的内存地址 Eg:int *p,m; 定义p为指向int类型变量的指针,同时定义变量m ...
- CF1009F Dominant Indices
传送门 还是放个链接让泥萌去学一下把 orzYYB 题目中要求的\(f_{x,j}\),转移是\(f_{x,j}=\sum_{y=son_x} f_{y,j-1}\),所以这个东西可以用长链剖分优化, ...
- luogu P4074 [WC2013]糖果公园
传送门 这种题显然要用树上莫队 何为树上莫队?就是在树上跑莫队算法就是先把树分块,然后把询问离线,按照左端点所在块为第一关键字,右端点所在块为第二关键字,时间戳(如果有修改操作)为第三关键字排序,然后 ...
- Error: Cannot find module PhantomJS
node install.js Considering PhantomJS found at /usr/local/bin/phantomjs Looks like an `npm install - ...
- Android学习笔记——Content Provider(一)
Content Provider是Android系统四大组件之一: 官方的定义是:A Content Provider manages access to a central repository o ...
- Shiro缓存(十三)
使用缓存,可以解决每次访问请求都查数据库的问题.第一次授权后存入缓存. 缓存流程 shiro中提供了对认证信息和授权信息的缓存.shiro默认是关闭认证信息缓存的,对于授权信息的缓存shiro默认开启 ...
- Python3学习笔记11-循环语句
条件判断使用if,需要加上冒号,当条件判断为True时,执行if下的代码块,为false就什么也不做 只要var1不是0,非空字符串,非空list等,就判断为True.否则为False var1 = ...
- CentOS 6.5自动化运维之基于DHCP和TFTP服务的PXE自动化安装centos操作系统详解
前言 如果要给很多台客户端主机安装操作系统,要是每一台都拿张安装光盘一台一台主机的去装系统那就太浪费时间和精力了.在生产环境中也不实际,要实现为多台主机自动安装操作系统,那我们怎么实现自动化安装 ...
- centos6下的lvm逻辑卷的管理
LVM:Logical Volume Manager 将多块设备组合成一个来使用 dm:device mapper 设备映射 设备文件 /dev/卷组名/逻辑卷名 /dev/mapp ...
- Android数据存储:SQLite
Android数据存储之SQLite SQLite:Android提供的一个标准的数据库,支持SQL语句.用来处理数据量较大的数据.△ SQLite特征:1.轻量性2.独立性3.隔离性4.跨平台性5. ...