Flume+Kafka整合
脚本生产数据---->flume采集数据----->kafka消费数据------->storm集群处理数据
日志文件使用log4j生成,滚动生成!
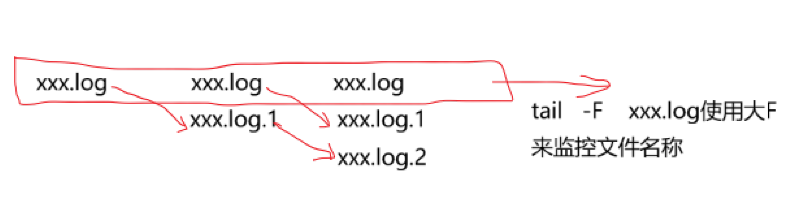
当前正在写入的文件在满足一定的数量阈值之后,需要重命名!!!
flume+Kafka整合步骤及相关配置:(先安装好zookeeper集群和Kafka集群)
配置flume:
1、下载flume
2、解压flume安装包
cd /export/servers/
tar -zxvf apache-flume-1.6.0-bin.tar.gz
ln -s apache-flume-1.6.0-bin flume
3、创建flume配置文件
cd /export/servers/flume/conf/
mkdir myconf
vi exec.conf
输入一下内容:
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.sources.r1.type=exec
a1.sources.r1.command=tail -F /export/data/flume_sources/click_log/1.log
a1.sources.r1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=10000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic=test
a1.sinks.k1.brokerList=kafka01:9092
a1.sinks.k1.requiredAcks=1
a1.sinks.k1.batchSize=20
a1.sinks.k1.channel=c1
4、准备目标数据的目录
mkdir -p /export/data/flume_sources/click_log
5、通过脚本创建目标文件并生产数据
for((i=0;i<=50000;i++));
do echo "message-" + $i >> /export/data/flume_sources/click_log/1.log;
done
注:脚本名称为click_log_out.sh,需要使用root用户赋权,chmod +x click_log_out.sh
6、开始打通所有流程
一:启动Kafka集群
kafka-server-start.sh /export/servers/kafka/config/server.properties
二:创建一个topic并开启consumer
kafka-console-consumer.sh --topic=test --zookeeper zk01:2181
三:执行数据生产的脚本
sh click_log_out.sh
四:启动flume客户端
./bin/flume_ng agent -n a1 -c conf -f conf/myconf/exec.conf -Dflume.root.logger=INFO,console
五:在第三步启动的kafka consumer窗口查看效果
Flume+Kafka整合的更多相关文章
- hadoop 之 kafka 安装与 flume -> kafka 整合
62-kafka 安装 : flume 整合 kafka 一.kafka 安装 1.下载 http://kafka.apache.org/downloads.html 2. 解压 tar -zxvf ...
- 大数据系列之Flume+kafka 整合
相关文章: 大数据系列之Kafka安装 大数据系列之Flume--几种不同的Sources 大数据系列之Flume+HDFS 关于Flume 的 一些核心概念: 组件名称 功能介绍 Agent ...
- Flume+Kafka+Storm+Redis 大数据在线实时分析
1.实时处理框架 即从上面的架构中我们可以看出,其由下面的几部分构成: Flume集群 Kafka集群 Storm集群 从构建实时处理系统的角度出发,我们需要做的是,如何让数据在各个不同的集群系统之间 ...
- flume与kafka整合
flume与kafka整合 前提: flume安装和测试通过,可参考:http://www.cnblogs.com/rwxwsblog/p/5800300.html kafka安装和测试通过,可参考: ...
- Flume+Kafka+Storm+Hbase+HDSF+Poi整合
Flume+Kafka+Storm+Hbase+HDSF+Poi整合 需求: 针对一个网站,我们需要根据用户的行为记录日志信息,分析对我们有用的数据. 举例:这个网站www.hongten.com(当 ...
- Flume+Kafka+Storm整合
Flume+Kafka+Storm整合 1. 需求: 有一个客户端Client可以产生日志信息,我们需要通过Flume获取日志信息,再把该日志信息放入到Kafka的一个Topic:flume-to-k ...
- ambari下的flume和kafka整合
1.配置flume #扫描指定文件配置 agent.sources = s1 agent.channels = c1 agent.sinks = k1 agent.sources.s1.type=ex ...
- Flume和Kafka整合安装
版本号: RedHat6.5 JDK1.8 flume-1.6.0 kafka_2.11-0.8.2.1 1.flume安装 RedHat6.5安装单机flume1.6:http://b ...
- flume和kafka整合(转)
原文链接:Kafka flume 整合 前提 前提是要先把flume和kafka独立的部分先搭建好. 下载插件包 下载flume-kafka-plus:https://github.com/beyon ...
随机推荐
- springboot(七)邮件服务
简单使用 发送邮件应该是网站的必备功能之一,什么注册验证,忘记密码或者是给用户发送营销信息.最早期的时候我们会使用JavaMail相关api来写发送邮件的相关代码,后来spring退出了JavaMai ...
- 攻击WEP加密无线网络
1.介绍 针对客户端环境和无客户端环境下破解WEP的几类方法. 有客户端环境: 一般当前无线网络中存在活动的无线客户端环境,即有用户通过无线连接到无线AP上并正在进行上网等操作时. 无客户端环境: 1 ...
- 「About Blockchain(一)」达沃斯年会上的区块链
「About Blockchain(一)」 --达沃斯年会上的区块链 写在前面:1月23日到26日,在瑞士达沃斯召开了第48届世界经济论坛.这个新闻本没有引起我格外的关注,直到前两天张老师分享给我一篇 ...
- 【CXF】com.sun.xml.internal.ws.fault.ServerSOAPFaultException: Client received SOAP Faul
在客户端生成代码之后测试出现错误: com.sun.xml.internal.ws.fault.ServerSOAPFaultException: Client received SOAP Faul ...
- python3爬虫二
1.获取列表页文章url集合: scrapy shell http://blog.jobbole.com/all-posts/ response.css('div.post-meta a.archiv ...
- ProcessHacker可编译版本
说明 做一个批量进程内搜索字符串的工具. 试了processhacker-2.39-src.zip. https://sourceforge.net/projects/processhacker/fi ...
- Django 查询集简述
通过模型中的管理器构造一个查询集(QuerySet),来从数据库中获取对象.查询集表示从数据库中取出来的对象的集合.它可以含有零个.一个或者多个过滤器.过滤器基于所给的参数限制查询的结果. 从SQL ...
- MISC混杂设备 struct miscdevice /misc_register()/misc_deregister()【转】
本文转自:http://blog.csdn.net/angle_birds/article/details/8330407 在Linux系统中,存在一类字符设备,他们共享一个主设备号(10),但此设备 ...
- CROSSUI桌面工具 分布加载模块(Distributed UI Module) 与 主模块Module 之间数据传输!
CROSSUI 基于 NW,如何在模Module 之间(主index.js and module1.js)传输数据? http://www.crossui.com/Forum/post577.htm ...
- java中集合的组成及特点
1:集合 Collection(单列集合) List(有序,可重复) ArrayList 底层数据结构是数组,查询快,增删慢 线程不安全,效率高 Vector 底层数据结构是数组,查询快,增删慢 线程 ...