Hive 企业调优
9.企业级调优
9.1 Fetch 抓取
- Fetch 抓取:Hive 中对某些情况的查询可以不必使用 MapReduce 计算;
hive.fetch.task.conversion:more
9.2 本地模式
- 大多数的 Hadoop Job 是需要 Hadoop 提供完整的可扩展性来处理大数据集的。不过,有时 Hive 的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive 可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
hive.exec.mode.local.auto:true
9.3 表的优化
9.3.1 小表Join大表
- 实际测试发现:新版的 hive 已经对小表JOIN大表和大表JOIN小表进行了优化,小表放在左边和右边已经没有明显区别;
9.3.2 大表Join大表
- 第一种方式:查询之前,过滤Null
select n.* from (select * from nullidtable where id is not null) n left join bigtable o on n.id = o.id;
- 第二种方式:给Null的赋值
- 需要避免数据倾斜,所以使用
rand(); select n.* from nullidtable n full join bigtable o on case when n.id is null then concat('hive', rand()) else n.id end = o.id;
- 需要避免数据倾斜,所以使用
9.3.3 MapJoin
- 如果不指定 MapJoin 或者不符合 MapJoin 的条件,那么 Hive 解析器会将 Join 操作转换成 Common Join,即:在Reduce阶段完成join,容易发生数据倾斜。可以用 MapJoin 把小表全部加载到内存,在 map 端进行 join,避免 reducer 处理。
- 开启
MapJoin参数设置:- 开启自动选择 MapJoin:
set hive.auto.convert.join=true;,默认为true; - 设置大表小表的阈值(默认25M 以下就是小表):
set hive.mapjoin.smalltable.filesize=25000000;
- 开启自动选择 MapJoin:
- MapJoin 工作机制:
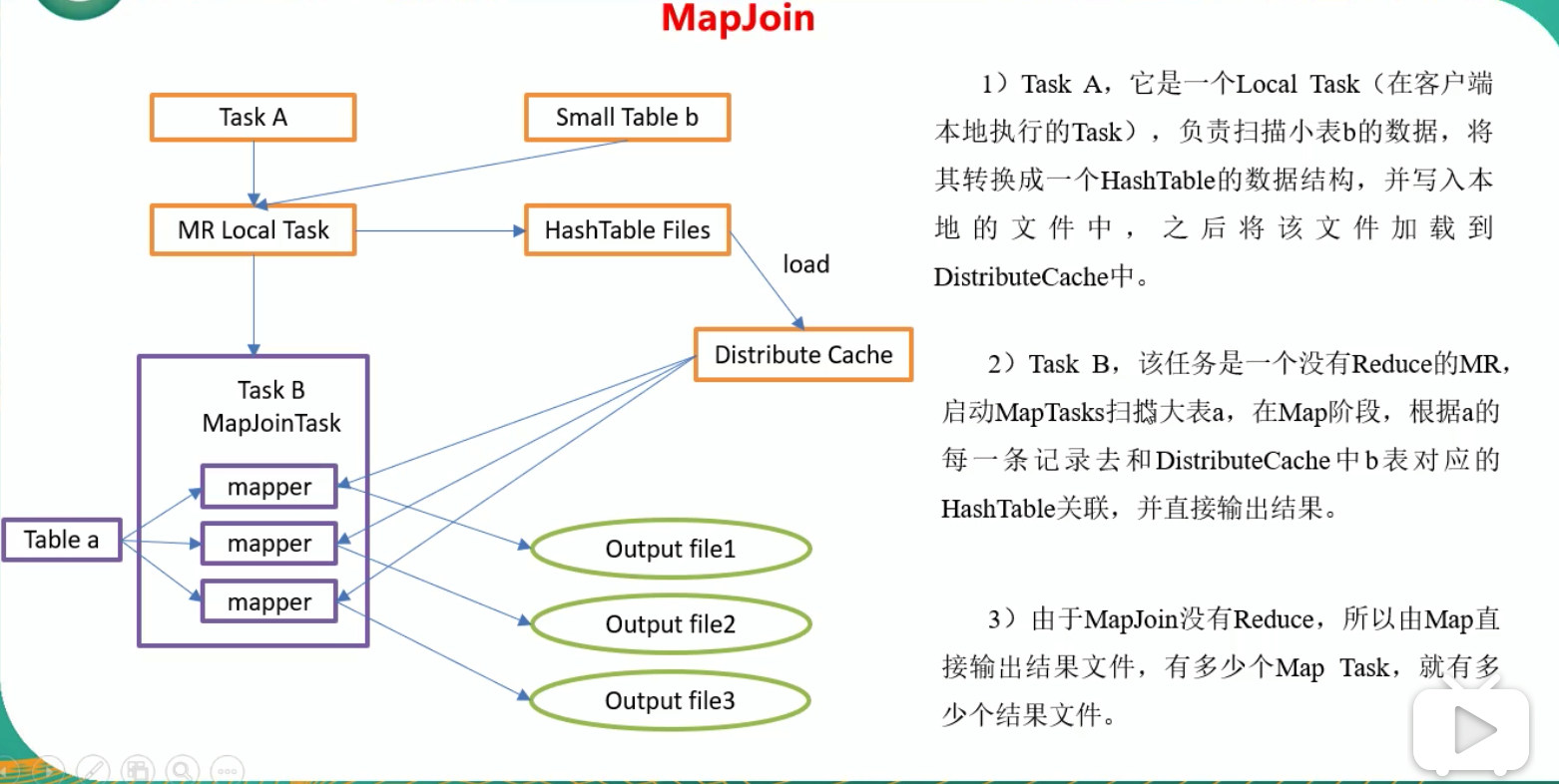
9.3.4 Group By
- 默认情况下,Map 阶段同一 Key 数据分发给一个 reduce,当一个 key 数据过大时,就可能发生数据倾斜;
- 并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以现在 Map 端进行部分聚合,最后在 Reduce 端得出最终结果。
- 开启 Map 端聚合参数设置:
- 是否在 Map 端进行聚合,默认为true:
hive.map.aggr=true; - 在 Map 端进行聚合操作的条目数目:
hive.groupby.mapaggr.checkinterval=100000; - 有数据倾斜的时候,进行负载均衡:
hive.groupby.skewindata=true;
- 是否在 Map 端进行聚合,默认为true:
9.3.5 Count(Distinct)去重统计
- 数据量大的情况下,由于 COUNT DISTINCT 操作需要用一个Reduce Task 来完成,这一个 Reduce 需要处理的数据量太大,就会导致整个 Job 很难完成,一般 COUNT DISTINCT 使用时,先 GROUP BY 再 COUNT 的方式替换;
9.3.6 动态分区调整
- 关系型数据库中,对分区表Insert数据的时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive 中也提供了类似的机制,即动态分区(Dynamic Partition);
- 开启动态分区参数设置:
- 开启动态分区功能,默认为true:
hive.exec.dynamic.partition=true; - 设置为非严格模式(默认为strict,即必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区):
hive.exec.dynamic.partition.mode=nonstrict; - 在所有执行 MR 的节点上,最大一共可以创建多少个动态分区:
hive.exec.max.dynamic.partitions=1000; - 在每个执行 MR 的节点上,最大可以创建多少个动态分区:
hive.exec.max.dynamic.partitions.pernode=100; - 整个 MR Job中,最大可以创建多少个HDFS文件:
hive.exec.max.created.files=100000; - 当有空分区生成时,是否抛出异常:
hive.error.on.empty.partition=false;
- 开启动态分区功能,默认为true:
Hive 企业调优的更多相关文章
- 数据迁移过程中hive sql调优
本文记录的是,在数据处理过程中,遇到了一个sql执行很慢,对一些大型的hive表还会出现OOM,一步一步通过参数的设置和sql优化,将其调优的过程. 先上sql ) t where t.num =1) ...
- Hive(十)Hive性能调优总结
一.Fetch抓取 1.理论分析 Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算.例如:SELECT * FROM employees;在这种情况下,Hive可以简单 ...
- Hive参数调优
调优 Hive提供三种可以改变环境变量的方法,分别是: (1)修改${HIVE_HOME}/conf/hive-site.xml配置文件: 所有的默认配置都在${HIVE_HOME}/conf/hiv ...
- hive tez调优(3)
根据.方案最右侧一栏是一个8G VM的分配方案,方案预留1-2G的内存给操作系统,分配4G给Yarn/MapReduce,当然也包括了HIVE,剩余的2-3G是在需要使用HBase时预留给HBase的 ...
- hive的调优
调优 1 Fetch抓取(Hive可以避免进行MapReduce) Hive中对某些情况的查询可以不必使用MapReduce计算.例如:SELECT * FROM employees;在这种情况下,H ...
- 06hive企业调优
一.Fetch抓取 Fetch抓取是指,Hive 中对某些情况的查询可以不必使用MapReduce计算. 在 hive-default.xml.template 文件中 hive.fetch.task ...
- 关于Hive的调优(本身,sql,mapreduce)
1.关于hive的优化 ->大表拆分小表 ->过滤字段 ->按字段分类存放 ->外部表与分区表 ->外部表:删除时只删除元数据信息,不删除数据文件 多人使用多个外部表操作 ...
- 060 关于Hive的调优(本身,sql,mapreduce)
1.关于hive的优化 ->大表拆分小表 ->过滤字段 ->按字段分类存放 ->外部表与分区表 ->外部表:删除时只删除元数据信息,不删除数据文件 多人使用多个外部表操作 ...
- Hive 性能调优
避免执行MR select * or select field1,field2 limit 10 where语句中只有分区字段或该表的本地字段 使用本地set hive.exec.mode.local ...
随机推荐
- 一个简单的setTimeout的问题
经常使用 setTimeout,并且自己认为也算比较熟悉这个函数的用法. 不过今天碰到了,突然发现自己没有意识到这个问题.于是作为一个记录点,进行巩固一下. var timer = window.se ...
- Pytest权威教程15-运行Nose用例
目录 运行Nose用例 使用方法 支持的nose风格 不支持的习语/已知问题 返回: Pytest权威教程 运行Nose用例 Pytest基本支持运行Nose框架格式的测试用例. 使用方法 后安装py ...
- html5中progress/meter元素
html5中progress/meter元素 一.总结 一句话总结: progress元素:用来建立一个进度条 meter元素的作用:用来建立一个度量条,用来表示度量衡的评定 <progress ...
- DELPHI开发LINUX插件架构的程序
DELPHI开发LINUX插件架构的程序 DELPHI可以开发LINUX配置型插件架构的程序,并且这一套插件架构,同样适用于MSWINDOWS和MAC. 配置插件: 根据配置,动态加载插件:
- 【转】Python编程: 多个PDF文件合并以及网页上自动下载PDF文件
1. 多个PDF文件合并1.1 需求描述有时候,我们下载了多个PDF文件, 但希望能把它们合并成一个PDF文件.例如:你下载的数个PDF文件资料或者电子发票,你可以使用python程序合并成一个PDF ...
- Spring事务原理分析--手写Spring事务
一.基本概念和原理 1.Spring事务 基于AOP环绕通知和异常通知的 2.Spring事务分为编程式事务.声明事务.编程事务包括注解方式和扫包方式(xml) Spring事务底层使用编程事务(自己 ...
- graph embedding 使用方法
无论是network embedding 还是graph embedding都是通过节点(node)和边的图,学出每个节点的embedding向量. 比较流行的算法有: Model Paper Not ...
- Robot Framework安装使用
关于robotframework环境搭建安装请参考 另外一篇博文:Robot Framework的环境搭建(就是一些库文件的安装) 项目基本流程: 1.创建项目New Project----选择dir ...
- TextView: android:ellipsize="marquee" 跑马灯效果无效的问题
今天练习的时候想实现一个文字的跑马灯效果,本来想自己手动实现的,不过突然想起来android里的TextView属性似乎自带了这个效果,叫: android:ellipsize ,平时都是把它的属性值 ...
- restful swagger api java go
rest框架使用swagger api,接口越来越多后性能会很差,如何优化? - 知乎https://www.zhihu.com/question/59349319 golang restful 框架 ...