java容器三:HashMap源码解析
前言:Map接口
map是一个存储键值对的集合,实现了Map接口的主要类有以下几种

TreeMap:用红黑树实现
HashMap:数组和链表实现
HashTable:与HashMap类似,但是线程安全
LinkedHashMap:与HashMap类似,但是内部有一个双向链表来维持插入顺序或其他某种要求的顺序
下面来介绍HashMap的具体信息
存储结构
链表
static class Node<K,V> implements Map.Entry<K,V>{
final int hash;
final K key;
V value;
Node<K,V>next;
}
Node<K,V>是用来存储一个键值对的,从next上我们可以看出这是一个链表结构,每一条链表上存储的是hash值相同的结点也就是键值对
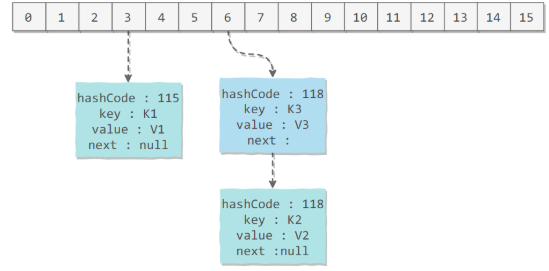
哈希桶
transient Node<K,V>[] table;
哈希桶是一个数组结构,数组的每一个元素保存一条链表
所以HashMap内部是采用“拉链法”来实现,示意图如下
确定桶下标
确定桶下标也就是确定键值对保存在数组中的下标,是根据key的哈希值来确定的,是用key的哈希值取模桶的长度得到。
虽然key的hashCode是int型取值有40多亿,但是由于桶长度远远小于hashCode能够取到的值,就会常常发生取模后得到的下标值相同的情景,
这称为“哈希碰撞”。为了解决这个问题,java设置了扰动函数来尽量减少哈希碰撞,就是代码中的hash()函数
/**找到存放该key的桶的下标时,是通过hashCode与桶的长度取余得到的。
*由于取余是通过与操作完成的,会忽略hash值的高位。
* 扰动函数就是为了解决hash碰撞的。它会综合hash值高位和低位的特征,并存放在低位,因此在与运算时,
* 相当于高低位一起参与了运算,以减少hash碰撞的概率。(在JDK8之前,扰动函数会扰动四次,JDK8简化了这个操作)
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
扩容方法
介绍
设 HashMap 的 table 长度为 M,需要存储的键值对数量为 N,如果哈希函数满足均匀性的要求,那么每条链表的长度大约为 N/M,因此平均查找次数的复杂度为 O(N/M)。
为了让查找的成本降低,应该尽可能使得 N/M 尽可能小,因此需要保证 M 尽可能大,也就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。
和扩容相关的参数主要有:capacity、size、threshold 和 load_factor。
| 变量 | 含义 |
| capicity | 哈希桶的容量,默认为16,注意capicity一定是2的N次方(因为hashmap中很多运算都是用位运算代替的,2的N次方才会使位运算满足代码逻辑) |
| size | 键值对的数量 |
| threshold | 阀值。当键值对的数量size>threshold的时候就会发生扩容 |
| load_factor | 装载因子。threshold = capicity*load_factor |
扩容方法源码解析
final Node<K,V>[] resize() {
//初始哈希桶
Node<K,V>[] oldTab = table;
//初始哈希桶容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//初始阀值
int oldThr = threshold;
//设置新的哈希桶容量和阀值都为0
int newCap, newThr = 0;
//当前容量>0
if (oldCap > 0) {
//如果旧哈希桶容量超过最大值,将阀值设为int的最大值1<<31-1,不扩容直接返回旧哈希桶
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}//否则新的容量为旧的容量的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//阀值也为旧阀值的2倍
newThr = oldThr << 1; // double threshold
}//当前哈希桶是空的,但是有阀值的,代表的是初始设置了容量和阀值的情况
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { //当前哈希表是空的且没有阀值,代表的是无参构造器的情况,则需要进行初始化
// zero initial threshold signifies using defaults
//容量设置为默认容量16
newCap = DEFAULT_INITIAL_CAPACITY;
//阀值设置为默认容量*默认加载因子
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//更新阀值
threshold = newThr;
//根据新的容量创造新的哈希桶
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//更新哈希桶引用
table = newTab;
//旧哈希桶不为空,将旧表中的数据复制到新哈希桶里
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
//将旧哈希桶里的元素设为null,方便GC
oldTab[j] = null;
//若原来链表上只有一个节点(不会发生哈希碰撞)
if (e.next == null)
/* 则只需要将其放到新的哈希桶里
* 桶的下标值是哈希值&(桶的长度-1),由于桶的长度是2的N次方,因此这实际上是个模运算
* 但是用位运算效率更高
*/
newTab[e.hash & (newCap - 1)] = e;
//如果链表的长度超过了阀值则要转为红黑树存储,暂且不讨论
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//链表长度不超过阀值,将旧链表中的节点复制到新链表中
else { // preserve order
/*因为容量是翻倍扩大的,因此原链表上的节点可能放在存放在原来的位置上也就是low位
* 也可能存放在扩容后的下标上high上
* high = low+原哈希桶容量
*/
//低位链表头指针和尾指针
Node<K,V> loHead = null, loTail = null;
//高位链表头指针和尾指针
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
/*利用位运算判断是放在低位链表还是高位链表
* 利用哈希值 与 旧的容量,可以得到哈希值去模后,是大于等于oldCap还是小于oldCap,
* 等于0代表小于oldCap,应该存放在低位,否则存放在高位
*/
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//将低位链表放在原index处
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//将高位链表放在新index处
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
put方法
jdk1.8采取的是“尾插法”,在此之前采用的是“头插法”
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
* jdk1.8以前是头插法,jdk1.8是尾插法
* jdk1.8以前也没有转为成红黑树的设置,1.8中当链表长度大于threshold(默认为8)之后会转为红黑树
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//若哈希桶为空,则直接初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果当前index=hash&(n-1)处的节点是空的,代表没有发生哈希碰撞
//则直接生成一个新的node挂载上去
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {//发生了哈希碰撞
Node<K,V> e; K k;
//如果哈希值相同,key值也相同则覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//红黑树暂且不谈
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//不是覆盖操作,则插入一个普通节点
//遍历链表
for (int binCount = 0; ; ++binCount) {
//找到尾节点
if ((e = p.next) == null) {
//插入节点
p.next = newNode(hash, key, value, null);
//如果追加节点后数量大于8则变成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//如果e不是null,说明有需要覆盖的节点
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
//覆盖原来Value并返回OldValue
e.value = value;
//空实现函数,用作LinkedHashMap重写复用
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断size是否需要扩容
if (++size > threshold)
resize();
//空实现函数,用作LinkedHashMap重写复用
afterNodeInsertion(evict);
return null;
}
get方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//循环链表,找到key扰动后的哈希值和key值都相等的Node返回
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
HashMap与HashTable比较
1、HashMap允许一个key为null,HashTable不予许
2、HashTable是线程安全的,因为给方法都加了synchronzied关键字
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
3、HashMap计算桶下标的时候运用了扰乱函数,HashTable直接用key的hashCode值
4、HashMap迭代器是fail-fast迭代器
5、HashMap不能保证随着时间推移元素的次序不变
6、HashMap扩容时扩大一倍,HashTable扩容时扩大一倍+1
7、HashMap中用了许多的位运算来代替HashTable中相同作用的普通乘除运算,效率更高
1)取模桶长度求下标时,用hashCode与(桶长度-1)代替取模运算
2)扩容操作判断放在低位链表还是高位链表时
/*利用位运算判断是放在低位链表还是高位链表
* 利用哈希值 与 旧的容量,可以得到哈希值去模后,是大于等于oldCap还是小于oldCap,
* 等于0代表小于oldCap,应该存放在低位,否则存放在高位
*/
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
注意
1、jdk1.8中链表的长度大于8时就会转化成红黑树存储
2、在jdk1.8以前put方法是采取头插法的,jdk1.8中改成了尾插法
3、HashMap是线程不安全的
java容器三:HashMap源码解析的更多相关文章
- 给jdk写注释系列之jdk1.6容器(4)-HashMap源码解析
前面了解了jdk容器中的两种List,回忆一下怎么从list中取值(也就是做查询),是通过index索引位置对不对,由于存入list的元素时安装插入顺序存储的,所以index索引也就是插入的次序. M ...
- java集合之HashMap源码解析
Map是java中的一种数据结构,围绕着Map接口,有一系列的实现类如Hashtable.HashMap.LinkedHashMap和TreeMap.而其中HashMap和Hashtable我们平常使 ...
- 给jdk写注释系列之jdk1.6容器(7)-TreeMap源码解析
TreeMap是基于红黑树结构实现的一种Map,要分析TreeMap的实现首先就要对红黑树有所了解. 要了解什么是红黑树,就要了解它的存在主要是为了解决什么问题,对比其他数据结构比如数组,链 ...
- 给jdk写注释系列之jdk1.6容器(6)-HashSet源码解析&Map迭代器
今天的主角是HashSet,Set是什么东东,当然也是一种java容器了. 现在再看到Hash心底里有没有会心一笑呢,这里不再赘述hash的概念原理等一大堆东西了(不懂得需要先回去看下Has ...
- 给jdk写注释系列之jdk1.6容器(5)-LinkedHashMap源码解析
前面分析了HashMap的实现,我们知道其底层数据存储是一个hash表(数组+单向链表).接下来我们看一下另一个LinkedHashMap,它是HashMap的一个子类,他在HashMap的基础上维持 ...
- Java中的容器(集合)之HashMap源码解析
1.HashMap源码解析(JDK8) 基础原理: 对比上一篇<Java中的容器(集合)之ArrayList源码解析>而言,本篇只解析HashMap常用的核心方法的源码. HashMap是 ...
- 【转】Java HashMap 源码解析(好文章)
.fluid-width-video-wrapper { width: 100%; position: relative; padding: 0; } .fluid-width-video-wra ...
- HashMap源码解析 非原创
Stack过时的类,使用Deque重新实现. HashCode和equals的关系 HashCode为hash码,用于散列数组中的存储时HashMap进行散列映射. equals方法适用于比较两个对象 ...
- 【转】Java集合:HashMap源码剖析
Java集合:HashMap源码剖析 一.HashMap概述二.HashMap的数据结构三.HashMap源码分析 1.关键属性 2.构造方法 3.存储数据 4.调 ...
- Java集合---Array类源码解析
Java集合---Array类源码解析 ---转自:牛奶.不加糖 一.Arrays.sort()数组排序 Java Arrays中提供了对所有类型的排序.其中主要分为Prim ...
随机推荐
- react 模板备份
/** * Created by hldev on 17-6-14. * 上市公司详情展示界面 */ import React, {Component} from "react"; ...
- golang高级用法总结
sync.WaitGroup add() done() wait() 相当于计数器,done会减一,wait会等待所有线程都执行完才执行下面代码 sync.pool 用来封装连接池
- idea2018.1.1版激活码到2020.7
N757JE0KCT-eyJsaWNlbnNlSWQiOiJONzU3SkUwS0NUIiwibGljZW5zZWVOYW1lIjoid3UgYW5qdW4iLCJhc3NpZ25lZU5hbWUiO ...
- 总结IDEA和VS常用实用的快捷键
整理了我一般撸码时使用下面两个IDE最常用到的快捷键: IntelliJ IDEA: 快捷搜索:Ctrl+F (Match Case:区分大小写,Words:全字匹配,Regex:正则匹配) 批量替换 ...
- Linux06 文件的打包和压缩(gzip/gunzip、tar、bzip2)
一.gzip/gunzip 这是用于压缩和解压单个文件的工具,且使用方法比较简单 gzip 文件名 gunzip 文件名 二.tar(用的比较多) 不仅可以用于打包文件,还可以将整个目录中的全部文 ...
- mysql中数据表记录的增删查改(2)
select `数据表.字段1`, group_concat(`数据表.字段2`) from `数据表` group by `数据表.字段1` order by `数据表.字段1` desc; sel ...
- Mybatis @ResultMap复用@Result
@ResultMap复用@Result: 可以简写成:@ResultMap("userMap")
- ASP.NET WebAPI 连接数据库
ASP.NET Web API 是一种框架,用于轻松构建可以访问多种客户端(包括浏览器和移动设备)的 HTTP 服务. ASP.NET Web API 是一种用于在 .NET Framework 上构 ...
- Ubuntu18.04防火墙相关
Ubuntu 18.04 LTS 系统中已经默认附带了 UFW 工具,如果您的系统中没有安装,可以在「终端」中执行如下命令进行安装: sudo apt install ufw 检查UFW状态 sudo ...
- 使用jQuery开发accordion手风琴插件
一.插件效果 手风琴插件常用的功能均已实现,包括:手风琴菜单项的折叠展开效果.选中指定菜单项.判断菜单项是否选中等. 效果如下: 二.插件内部HTML元素结构 <!-- accordioon组件 ...