大数据之路week07--day06 (Sqoop 在从HDFS中导出到关系型数据库时的一些问题)
问题一:
在上传过程中遇到这种问题:
ERROR tool.ExportTool: Encountered IOException running export job: java.io.IOException: No columns to generate for ClassWriter
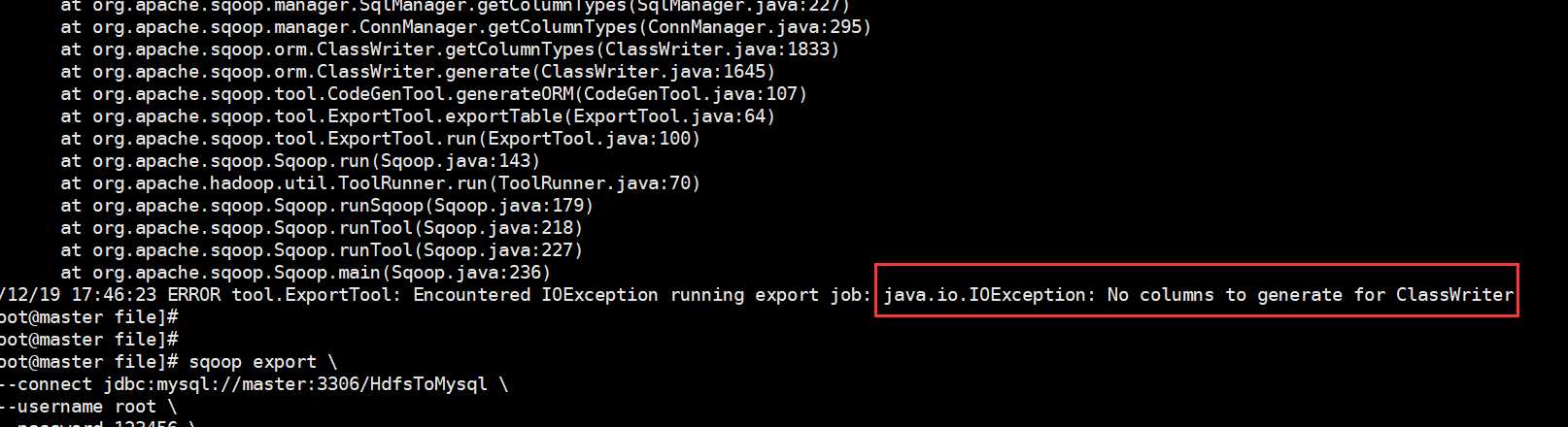
解决方式:
在网上搜索的时候很多博客说时驱动版本的过低导致的,其实在尝试这个方法的时候我们可以先进行这样:加一行命令,--driver com.mysql.jdbc.Driver \ 然后问题解决!!!
如果添加命令之后还没有解决就把jar包换成高点版本的。百度云链接:
链接:https://pan.baidu.com/s/1q-6O0ER-Vtc74ha_9DMbpQ
提取码:174n
问题二:
依旧是导出的时候,会报错,但是我们很神奇的发现,也有部分数据导入了。这也就是下一个问题。
Caused by: java.lang.NumberFormatException: For input string: "null"

解决方式:因为数据有存在null值得导致的
在命令中加入一行(方式一中的修改方式,方式二也就是转换一下格式):--input-null-string '\\N' \ 也有的博主说加两行,但是我加一行也可以,具体原因没有细查。
问腿三:
java.lang.RuntimeException: Can't parse input data: '1998/5/11'
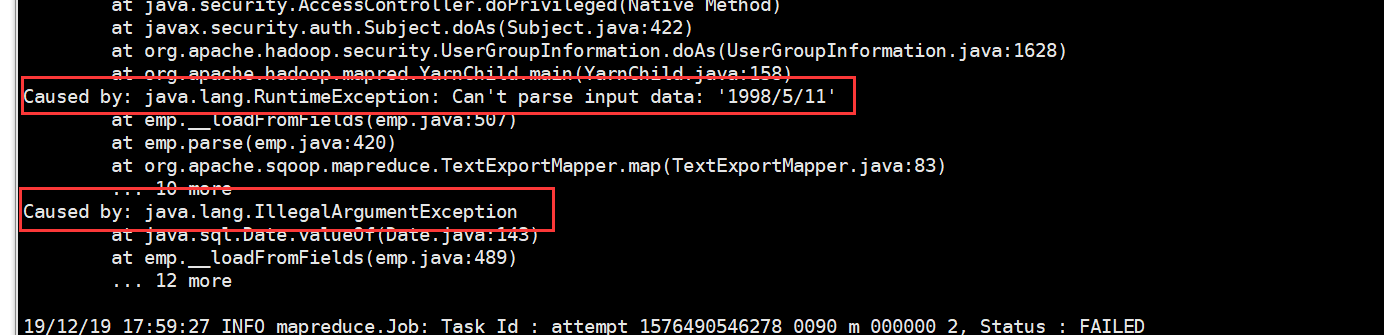
出现像这样的问题,大多是因为HDFS上的数据与关系型数据库创建表的字段类型不匹配导致的。仔细对比修改后,就不会有这个报错啦!!
当然,会发生的问题肯定不会是就这么点,主要靠平时的积累,修改,才能不断地成长。
注意: 千万不要犯像敲错字母,或者命令打错,空格少打这样的低级错误,这样会很耗时,唯一的解决办法,那就是,多加练习,勤敲。!!!
大数据之路week07--day06 (Sqoop 在从HDFS中导出到关系型数据库时的一些问题)的更多相关文章
- 大数据之路week07--day06 (Sqoop 的使用)
Sqoop的使用一(将数据库中的表数据上传到HDFS) 首先我们先准备数据 1.没有主键的数据(下面介绍有主键和没有主键的使用区别) -- MySQL dump 10.13 Distrib 5.1.7 ...
- 大数据之路week07--day06 (Sqoop 将关系数据库(oracle、mysql、postgresql等)数据与hadoop数据进行转换的工具)
为了方便后面的学习,在学习Hive的过程中先学习一个工具,那就是Sqoop,你会往后机会发现sqoop是我们在学习大数据框架的最简单的框架了. Sqoop是一个用来将Hadoop和关系型数据库中的数据 ...
- 大数据之路week07--day07 (Sqoop 从mysql增量导入到HDFS)
我们之前导入的都是全量导入,一次性全部导入,但是实际开发并不是这样,例如web端进行用户注册,mysql就增加了一条数据,但是HDFS中的数据并没有进行更新,但是又再全部导入一次又完全没有必要. 所以 ...
- 大数据之路week07--day06 (Sqoop 的安装及配置)
Sqoop 的安装配置比较简单. 提供安装需要的安装包和连接mysql的驱动的百度云链接: 链接:https://pan.baidu.com/s/1pdFj0u2lZVFasgoSyhz-yQ 提取码 ...
- 大数据框架开发基础之Sqoop(1) 入门
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle , ...
- 大数据之路week07--day05 (一个基于Hadoop的数据仓库建模工具之一 HIve)
什么是Hive? 我来一个短而精悍的总结(面试常问) 1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark). 2:hive可以使用类sql方言,对存储在hdfs上的数据进 ...
- 大数据之路week07--day04 (YARN,Hadoop的优化,combline,join思想,)
hadoop 的计算特点:将计算任务向数据靠拢,而不是将数据向计算靠拢. 特点:数据本地化,减少网络io. 首先需要知道,hadoop数据本地化是指的map任务,reduce任务并不具备数据本地化特征 ...
- 大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念 一.Hadoop出现的前提环境 随着数据量的增大带来了以下的问题 (1)如何存储大量的数据? (2)怎么处理这些数据? (3)怎样的高效的分析这些数据? (4)在数据增长的情况 ...
- 大数据之路week04--day06(I/O流阶段一 之异常)
从这节开始,进入对I/O流的系统学习,I/O流在往后大数据的学习道路上尤为重要!!!极为重要,必须要提起重视,它与集合,多线程,网络编程,可以说在往后学习或者是工作上,起到一个基石的作用,没了地基,房 ...
随机推荐
- consul集群搭建以及ACL配置
由于时间匆忙,要是有什么地方没有写对的,请大佬指正,谢谢.文章有点水,大佬勿喷这篇博客不回去深度的讲解consul中的一些知识,主要分享的我在使用的时候的一些操作和遇见的问题以及解决办法.当然有些东西 ...
- springcloud 连接docker中运行的RabbitMQ消息中间件。
参考:https://blog.51cto.com/zero01/2173288 主要是记录几个坑: 第一个坑:开始订单服务中配置文件是: #配置rabbitmq 2019.5.17 added by ...
- springcloud feign 调用
client端调用feigh, 要在启动类上添加@EnableFeignClients注解,并添加扫描: 不然会调用失败,找不到调用方法
- 【知识总结】动态 DP
勾起了我悲伤的回忆 -- NOIP2018 316pts -- 主要思想:将 DP 过程分解为方便单点修改和一个区间合并的操作(通常类似矩阵乘法),然后用数据结构(通常为线段树)维护. 例:给定一个长 ...
- 【转帖】国产PCIe SSD主控芯片获得中国芯大奖 3500MB/s读取
国产PCIe SSD主控芯片获得中国芯大奖 3500MB/s读取 https://www.cnbeta.com/articles/tech/906033.htm 国产主控 在日前的2019“中国芯”集 ...
- [转帖]【MySQL+keepalived】用keepalived实现MySQL主主模式的高可用
[MySQL+keepalived]用keepalived实现MySQL主主模式的高可用 https://www.jianshu.com/p/8694d07595bc 一.实验说明 MySQL主主模式 ...
- wmi的作用
WMI是Windows 2K/XP管理系统的核心,对于其他的Win32操作系统,WMI是一个有用的插件. WMI的作用是: ①通过它可以访问.配置.管理和监视几乎所有的Windows资源,比如用户可以 ...
- c++模板使用及常见问题
一.为什么使用模板?? 使用模板的目的是为了避免重复声明和定义一系列基本功能相同的函数或者类,其区别因传入参数的不同而产生不同类型的数据,其基本工作过程都是一致的! 二.调用模板函数产生不明确问题 ( ...
- 存储库之MongoDB
一.简介 MongoDB是一款强大.灵活.且易于扩展的通用型数据库(非关系型数据库) 1.易用性 MongoDB是一个面向文档(document-oriented)的数据库,而不是关系型数据库. 不采 ...
- MySQL数据库-表操作-SQL语句(一)
1. 数据库操作与存储引擎 1.1 数据库和数据库对象 数据库对象:存储,管理和使用数据的不同结构形式,如:表.视图.存储过程.函数.触发器.事件等. 数据库:存储数据库对象的容器. 数据库分两种 ...