Deep Reinforcement Learning with Iterative Shift for Visual Tracking
Deep Reinforcement Learning with Iterative Shift for Visual Tracking
2019-07-30 14:55:31
Code: not find yet.
Paper List of Tracking with Deep Reinforcement Learning: https://github.com/wangxiao5791509/Tracking-with-Deep-Reinforcement-Learning
1. Background and Motivation:
本文的贡献在于:
1). 提出一种 Actor-Critic Network 来预测物体运动的参数,并根据跟踪状态选择动作,不同的动作,会根据对结果的影响不同,设置不同的奖励;
2). 将 tracking 看做是迭代的平移问题,而不是 CNN Classification 问题,所以定位更加高效和准确;
3). 在 OTB 和 TC128 数据集上取得了较好的效果;
2. Approach:
本文所提出的方法包含三个模块:1). the actor network; 2). the prediction network; 3). the critic network.
2.1 Iterative Shift for Visual Tracking
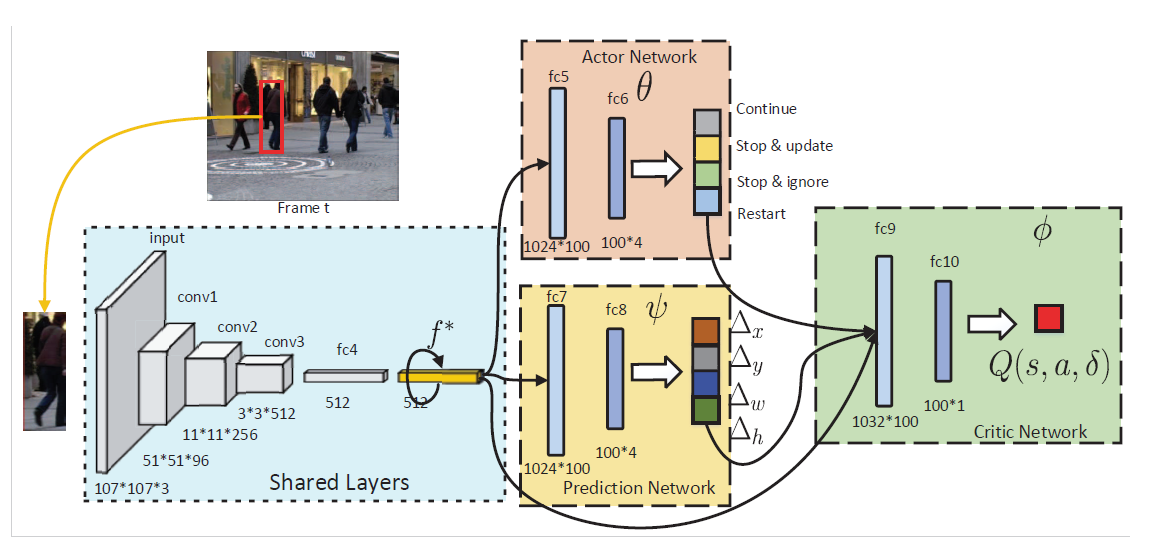
本文将 tracking 看做是迭代的平移问题。 给定当前帧和之前的跟踪结果,prediction network 会迭代的平移候选框,以定位住目标物体,与此同时,action network 会在跟踪状态上进行预测,判断是否进行模型的更新,预测网络,甚至是重启跟踪过程。
正式的来说,给定上一帧的跟踪结果 $l_{t-1} = {x_{t-1}, y_{t-1}, w_{t-1}, h_{t-1}}$ 以及 feature $f_{t-1}^*$,我们先根据该位置,得到当前帧的大致位置,抠出该 feature $f_t$,然后用预测网络进行预测:

其中,预测网络的输出为:

此外,跟踪状态也可能会影响最终的结果,即:需要适时的更新预测网络。为了联合的基于 target's motion status 以及 tracker's status 进行决策,我们利用 actor network 根据多项式分布来产生动作:

其中,$a_k \in A = \{ continuous, stop & update, stop & ignore, restart \}$。
对于动作 continuous 来说,即:不用更新模型,继续平移,而进行的 shift 是根据 prediction network 进行的。
对于动作 step & update 来说,即:停止平移,更新模型,即:

对于动作 stop & ignore 来说,停止平移,不更新模型,表示目标物体已经找到,然而,跟踪器无法确定是否需要进行更新。
对于动作 restart 来说,重新进行跟踪过程,即:restart the iteration by re-sampling a random set of candidate patches $L_t$ around $l_{t-1}^*$ in $I_t$ and select the patch which has the highest Q-values.
DRL-IS with Actor-Critic:
我们探索 AC算法,来进行联合的训练三个网络。首先作者根据跟踪的性能,进行了奖励的设定:
对于 continue 动作, 根据

对于 stop & update and stop & ignore 动作,奖励的设定是根据 final prediction 和 ground truth 之间的 IoU 进行评判的:

对于 restart 动作,当 final prediction 和 groundtruth 之间的 IoU 低于 0.4 时,给予 pos 的奖励:

然后,我们计算每一个动作的 Q-value。
对于 action continue 的 Q-value 来说:

对于其他的三个动作来说,是按照如下的式子进行计算:

最终,两个函数的优化是按照如下的式子进行的:

其中,s' 是下一个状态,a' 是选择的最优动作,Action-value 以及 Value function 是按照如下的方式进行计算的:


总体的算法过程如下所示:

==
Deep Reinforcement Learning with Iterative Shift for Visual Tracking的更多相关文章
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
- getting started with building a ROS simulation platform for Deep Reinforcement Learning
Apparently, this ongoing work is to make a preparation for futural research on Deep Reinforcement Le ...
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
- Paper Reading 1 - Playing Atari with Deep Reinforcement Learning
来源:NIPS 2013 作者:DeepMind 理解基础: 增强学习基本知识 深度学习 特别是卷积神经网络的基本知识 创新点:第一个将深度学习模型与增强学习结合在一起从而成功地直接从高维的输入学习控 ...
- repost: Deep Reinforcement Learning
From: http://wanghaitao8118.blog.163.com/blog/static/13986977220153811210319/ accessed 2016-03-10 深度 ...
随机推荐
- js switch case 判断的是绝对相对===,值和类型都要相等
js switch case 判断的是绝对相对===,值和类型都要相等
- 元素定位方法之Uiautomator方法
这个方法只能用于安卓系统,方法通过类UiSelector()来构造对象的 官网地址:https://developer.android.google.cn/topic/libraries/testin ...
- Java开发环境之Maven
查看更多Java开发环境配置,请点击<Java开发环境配置大全> 肆章:Maven安装教程 1)下载Maven安装包 https://maven.apache.org/download.c ...
- 浅谈HTTP中Get与Post的区别【转】
转自http://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html#commentform 感谢LZ分享 Http定义了与服务器交互的不同方法 ...
- 02-CSS常用样式
本篇主要介绍css的常用样式,以及网页布局相关知识.绝对定位和相对定位,盒子模型.css权重.以及css选择器: 绪论:CSS基本介绍 为了让网页元素的样式更加丰富,也为了让网页的内容和样式能拆分开, ...
- Linux用户组和权限管理
Linux用户组和权限管理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Linux的安全模型 1>.安全3A 这并不是Linux特有的概念,在很多领域都有3A的概念 ...
- PAT甲级1002水题飘过
#include<iostream> #include<string.h> using namespace std; ]; int main(){ int n1, n2; wh ...
- Kotlin属性委托系统总结与提供委托详解
属性委托总结回顾: 在前三次已经将Kotlin委托相关的知识点进行了完整的学习了,具体博文如下: https://www.cnblogs.com/webor2006/p/11369019.html h ...
- failed to recover intents
failed to recover intents 无法恢复意图
- .NET Core项目修改project.json来引用其他目录下的源码等文件的办法 & 解决多框架时 project.json 与 app.config冲突的问题
作者: zyl910 一.缘由 项目规模大了后,经常会出现源码文件分布在不同目录的情况,但.NET Core项目默认只有项目目录下的源码文件,且不支持“Add As Link”方式引入文件.这时需要手 ...