ELK日志分析
1. 为什么用到ELK
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获取自己想要的信息。但是规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
收集--能够采集多种来源的日志数据
传输--能够稳定的把日志数据传输到中央系统
存储--如何存储日志数据
分析--可以支持UI分析
警告--能够提供错误报告,监控机制 ELK 提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
2. ELK简介
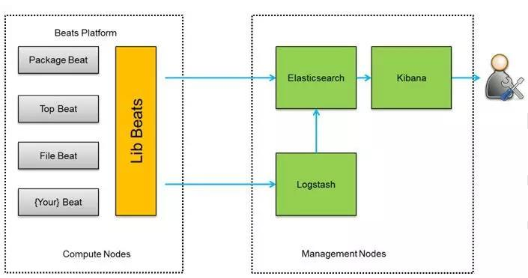
ELK 是三个开源软件的缩写,分别表示:Elasticsearch、Logstash、Kibana,它们都是都是开源软件。新增了一个FileBeat,他是一个轻量级的日志收集处理工具(Agent),FileBeat占用资源少,适合于在各个服务器上收集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch 是个开源分布式搜索引擎,提供收集、分析、存储数据三大功能。它的特点有:分布式、零配置、自动发现、索引自动分片、索引副本机制、restful 风格接口、多数据源、自动搜索负载等。
Logstash 主要是用来日志的收集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s 架构,客户(client)端安装在需要收集日志的主机上,server 端负责将收集到的各节点日志进行过滤、修改等操作再一起并发到 Elassticseaarch 上去。
Kibana 也是一个开源和免费的工具,Kibana 可以成为Logstash 和Elasticsearch 提供的日志分析友好的web界面,可以帮助汇总、分析和搜索重要数据日志。
FileBeat 隶属于 Beats。目前Beats 包含四种工具:
Packetbeat (搜集网络流量数据)
Topbeat(搜集系统、进程和文件系统级别的CPU 和内存使用情况等数据)
FileBeat(搜集文件数据)
Winlogbeat(搜集windows 事件日志数据)
3. 实验部署
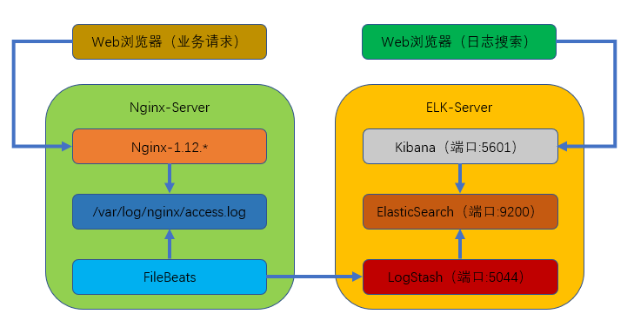
本次部署的是filebeats(客户端),logstash+elasticsearch+kibana(服务端)组成的架构。
业务请求到达nginx-server 机器上nginx,nginx 响应请求,并在access.log 文件中在增加访问记录;FileBeat 搜集数据的日志,通过Logstash 的5044 端口上传日志;Logstash 将日志信息通过本机的9200 端口传入到elasticsearch;搜集日志的用户通过浏览器访问 Kibana,服务器端口是5601;Kibana 通过9200 端口访问 Elasticsearch;
实验环境:
本次部署的是单点ELK 用了两台机器(Centos7)
ELK 服务端:192.168.80.130
Nginx 客户端:192.168.80.132
3.1 准备工作
配置网络yum源
[root@localhost /etc/yum.repos.d]# wget http://mirrors.aliyun.com/repo/Centos-7.repo
[root@localhost /etc/yum.repos.d]# wget http://mirrors.aliyun.com/repo/epel-7.repo
关闭SELinux
[root@localhost ~]# vim /etc/sysconfig/selinux SELINUX=disabled
开放防火墙端口
firewall-cmd --zone=public --add-port=/tcp
firewall-cmd --zone=public --add-port=/tcp --permanent
firewall-cmd --zone=public --add-port=/tcp
firewall-cmd --zone=public --add-port=/tcp --permanent
firewall-cmd --zone=public --add-port=/tcp
firewall-cmd --zone=public --add-port=/tcp --permanent
3.2 下载并安装软件包
[root@localhost ~]# mkdir /elk
[root@localhost ~]# cd /elk/
[root@localhost /elk]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.tar.gz
[root@localhost /elk]# wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.3.tar.gz
[root@localhost /elk]# wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.3-linux-x86_64.tar.gz
3.3 安装JDK
[root@localhost ~]# yum -y install java-1.8*
3.4 配置elasticsearch
1)新建 elasticsearch 用户并启动(使用elasticsearch 普通用户启动)
[root@localhost /usr/local]# useradd elasticsearch
[root@localhost /usr/local]# chown -R elasticsearch:elasticsearch /usr/local/elasticsearch-6.2./
[root@localhost /usr/local]# su - elasticsearch
[elasticsearch@localhost ~]$ cd /usr/local/elasticsearch-6.2./
[elasticsearch@localhost ~]$ ./bin/elasticsearch -d
2)查看进程是否正常启动(等待一会)
[elasticsearch@localhost ~]$ netstat -antp
3)若启动出错可查看日志
[elasticsearch@localhost ~]$ cat /usr/local/elasticsearch-6.2./logs/elasticsearch.log
4)测试是否可以正常访问
[root@localhost /usr/local]# curl localhost:
{
"name" : "ezNB3lt",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "CDnRSJwDRbOLwOMEX5U0MA",
"version" : {
"number" : "6.2.3",
"build_hash" : "c59ff00",
"build_date" : "2018-03-13T10:06:29.741383Z",
"build_snapshot" : false,
"lucene_version" : "7.2.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
3.5 配置Logstash
Logstash 收集nginx 日志使用 grok 过滤插件解析日志。grok 作为一个 Logstash 的过滤插件,支持根据模式解析文本日志行,拆成字段。
1)logstash 中 grok 的正则匹配
[root@localhost /usr/local/logstash-6.2.]# vim vendor/bundle/jruby/2.3./gems/logstash-patterns-core-4.1./patterns/grok-patterns
#在最后添加以下内容
#nginx
WZ ([^ ]*)
NGINXACCESS %{IP:remote_ip} \- \- \[%{HTTPDATE:timestamp}\] "%{WORD:method} %{WZ:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:status} %{NUMBER:bytes} %{QS:referer} %{QS:agent} %{QS:xforward}
2)创建 logstash 配置文件
[root@localhost /usr/local/logstash-6.2.]# vim /usr/local/logstash-6.2./default.conf
input {
beats {
port => ""
}
}
#数据过滤
filter {
grok {
match => { "message" => "%{NGINXACCESS}" }
}
geoip {
#nginx客户端ip
source => "192.168.80.132"
}
}
#输出配置为本机的9200端口,这是elasticsearch 服务的监听端口
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
}
}
3)进入到/usr/local/logstash-6.2.3 目录下,并执行下列命令
后台启动logstash:nohup bin/logstash -f default.conf &
查看启动日志:tail -f nohup.out
查看端口是否启动:netstat -antp |grep
3.6 配置 Kibana
1) 打开Kibana 配置文件 /usr/local/kibana-6.2.3-linux-x86_64/config/kibana.yml,找到下面这行并修改
vim /usr/local/kibana-6.2.-linux-x86_64/config/kibana.yml
#server.host: "localhost"
修改为
server.host: "192.168.80.130"
这样其他电脑就能用浏览器访问Kibana 的服务
2)进入Kibana 的目录:cd /usr/local/kibana-6.2.3-linux-x86_64/
执行启动命令:nohup bin/kibana &
查看启动日志:tail -f nohup.out
查看端口是否启动:netstat -napt|grep
3)测试:
在浏览器访问 192.168.80.130:5601
至此,ELK 部署完成
3.7 nginx 客户端配置
1)安装nginx
yum -y install nginx
2)下载filebeat并解压到/usr/local/
[root@localhost ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.3-linux-x86_64.tar.gz
[root@localhost ~]# tar -zxvf filebeat-6.2.-linux-x86_64.tar.gz -C /usr/local/
3)vim /usr/local/filebeat-6.2.3-linux-x86_64/filebeat.yml,找到如下内容,修改
enabled: false #修改为true
/var/log/*.log #修改为/var/log/nginx/*.log
#output.elasticsearch: #将此行注释掉
#hosts: ["localhost:9200"] #将此行注释掉
output.logstash: #此行取消注释
hosts: ["192.168.80.130:5044"] #此行取消注释并修改IP地址为ELK服务器地址
4)切换到/usr/local/filebeat-6.2.3-linux-x86_64 目录
cd /usr/local/filebeat-6.2.-linux-x86_64/
后台启动:nohup ./filebeat -e -c filebeat.yml &
查看日志:tail -f nohup.out
5)通过浏览器多访问几次nginx服务,这样可以多制造一些访问日志,访问地址:https://192.168.80.132
6)访问 Kibana:https://192.168.80.130:5601,点击左上角的Discover,就可以看到访问日志已经被ELk收集,然后按照以下步骤完成设置
a. 输入logstash-*,点击"Next step"
b. 选择time filter,再点击"Create index pattern"
c. 然后自行创建日志内容查询规则
ELK日志分析的更多相关文章
- ELK 日志分析体系
ELK 日志分析体系 ELK 是指 Elasticsearch.Logstash.Kibana三个开源软件的组合. logstash 负责日志的收集,处 ...
- ELK 日志分析实例
ELK 日志分析实例一.ELK-web日志分析二.ELK-MySQL 慢查询日志分析三.ELK-SSH登陆日志分析四.ELK-vsftpd 日志分析 一.ELK-web日志分析 通过logstash ...
- 浅谈ELK日志分析平台
作者:珂珂链接:https://zhuanlan.zhihu.com/p/22104361来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 小编的话 “技术干货”系列文章 ...
- ELK日志分析系统简单部署
1.传统日志分析系统: 日志主要包括系统日志.应用程序日志和安全日志.系统运维和开发人员可以通过日志了解服务器软硬件信息.检查配置过程中的错误及错误发生的原因.经常分析日志可以了解服务器的负荷,性能安 ...
- elk日志分析与发掘深入分析
elk日志分析与挖掘深入分析 1 为什么要做日志采集? 2 挖财自己的日志采集和分析体系应该怎么建? 2.1 日志的采集 2.2 日志的汇总与过滤 2.3 日志的存储 2.4 日志的分析与查询 3 需 ...
- Rsyslog+ELK日志分析系统
转自:https://www.cnblogs.com/itworks/p/7272740.html Rsyslog+ELK日志分析系统搭建总结1.0(测试环境) 因为工作需求,最近在搭建日志分析系统, ...
- 十分钟搭建和使用ELK日志分析系统
前言 为满足研发可视化查看测试环境日志的目的,准备采用EK+filebeat实现日志可视化(ElasticSearch+Kibana+Filebeat).题目为“十分钟搭建和使用ELK日志分析系统”听 ...
- ELK日志分析系统-Logstack
ELK日志分析系统 作者:Danbo 2016-*-* 本文是学习笔记,参考ELK Stack中文指南,链接:https://www.gitbook.com/book/chenryn/kibana-g ...
- elk 日志分析系统Logstash+ElasticSearch+Kibana4
elk 日志分析系统 Logstash+ElasticSearch+Kibana4 logstash 管理日志和事件的工具 ElasticSearch 搜索 Kibana4 功能强大的数据显示clie ...
- ELK日志分析 学习笔记
(贴一篇之前工作期间整理的elk学习笔记) ELK官网 https://www.elastic.co ELK日志分析系统 学习笔记 概念:ELK = elasticsearch + logstas ...
随机推荐
- Spring Boot 知识笔记(创建maven项目、HTTP接口)
一.使用Maven手工创建SpringBoot应用(IDEA) 1. 点击File——New——Project——Maven——Next,填写相关信息,创建项目. 2. 在pom.xml中添加相关 ...
- No module named 'requests_toolbelt'
pip install requests-toolbelt
- Error in readRDS(dest) : error reading from connection
Error in readRDS(dest) : error reading from connection 解决办法:可能是镜像设置错误,导致无法抓取文件 修改 RStudio 中的镜像地址 设置成 ...
- List 拆分集合与 读写XML配置文件
有时候会出现需要将一个集合分成所干个集合,依次再对每组集合进行处理,想了想,用 Linq 处理就很方便 ); ).Take(); //第一组 ).Take(); //第二组 ; i < time ...
- 一张MGR切换的图,不解释
- [HeadFrist-HTMLCSS学习笔记]第三章构建模块:Web页面建设
[HeadFrist-HTMLCSS学习笔记]第三章构建模块:Web页面建设 敲黑板!! <q>元素添加短引用,<blockquote>添加长引用 在段落里添加引用就使用< ...
- C的位运算符
1.前言 C的位运算符有&(按位与).|(按位或).^(按位异或).~(按位取反),位运算符把运算对象看作是由二进制位组成的位串信息,按位完成指定的运算,得到相应的结果. 2.位运算符 在上面 ...
- AKKA Inbox收件箱
起因 得到ActorRef就可以给actor发送消息,但无法接收多回复,也不知道actor是否停止 Inbox收件箱出现就是解决这两个问题 示例 package akka.demo.actor imp ...
- MD5加盐与安全
PHP开发者对md5()这个函数是熟悉不过了,很多开发者都使用md5('abc123')对用户密码进行加密处理,这样做没有错,但是安全性还是很低的,因为很多网站的用户数据都是用md5进行加密处理的,所 ...
- python实现根据前序与中序求后序
我就不板门弄斧了求后序 class Tree(): def __init__(self,x): self.value=x self.left=None self.right=None class So ...