CMU Database Systems - Storage and BufferPool
Database Storage
存储分为volatile和non-volatile,越快的越贵越小
那么所以要解决的第一个问题就是,如果尽量在有限的成本下,让读写更快些
意思就是,尽量读写volatile存储,但是volatile比较很有限,所以需要合理的在两种存储上去swap
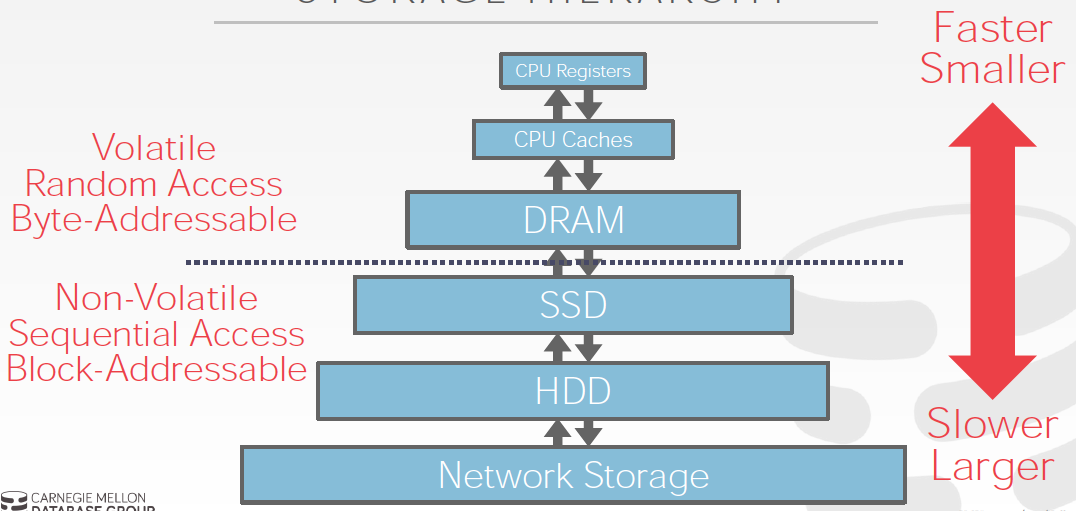
但是技术是在飞速的进步的,所以现在有Non-volatile memory
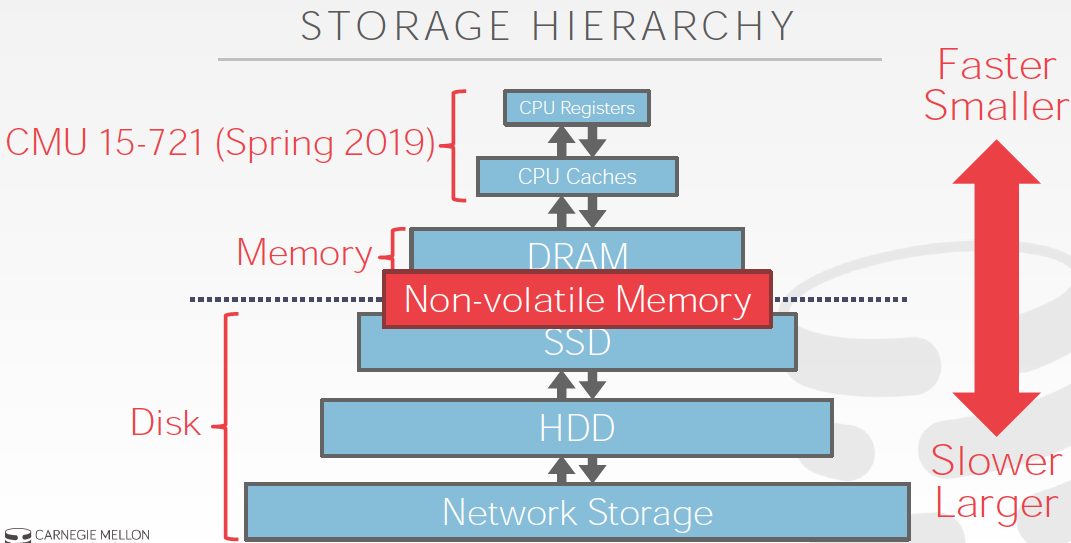
所以最近流行内存数据库,因为当前的memory和磁盘间的IO瓶颈已经消除,所以当前的瓶颈是CPU cache和Memory之前的问题
这个问题会在下一门课里面说
所以继续前面的问题,怎么解决disk和memory之间的IO瓶颈
一个直觉的想法就是,交给操作系统去做,使用虚拟内存,Virtual Memory
mmap可以产生内存文件,把磁盘文件的内容map到内存的地址空间,这样有个问题就是如果有多个并发写,需要同步机制,系统也提供右图这些同步指令
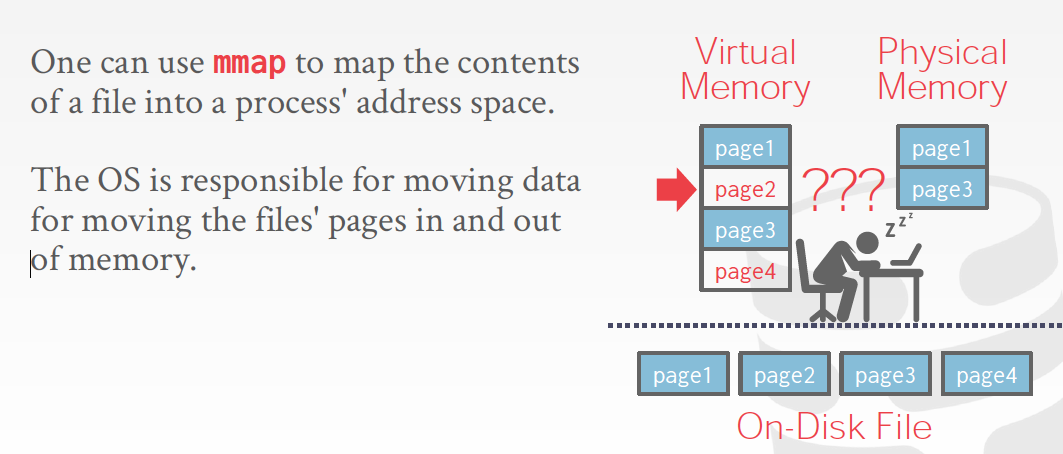

但是数据库管理系统往往希望做的更精细,因为操作系统是个通用方案,一定达不到性能最优

下面我们来看第二个问题,DBMS如何将数据库的数据放到磁盘文件上?
这里有个选择,DBMS是否要用系统的文件系统,还是拿一块raw storage自己管理,现在一般的选择是还是使用文件系统,毕竟方便
既然用文件系统,那么DBMS就需要把数据库数据存成一个或多个文件
这里有个概念,Page,文件是由一堆page组成的

page其实就是固定大小的数据块,那为什么要有这层抽象?
这个和我们使用的存储有关,当前用的磁盘,除了慢,还有个特点是对顺序读写比较友好,因为随机读需要磁头不断的机械移动的,这个想想也很慢
所以文件系统和磁盘间的IO,需要尽量批量读,读写数据的最小单位称为数据块,一般是4K,为什么是4K,应该是因为比较经济
而数据库的page是基于文件系统的,所以设计成4k的倍数会比较合理
数据库会自己维护一个page id到实际存储地址(文件+offset)的映射

那么如何在磁盘文件上管理page?
有三种方式,最常见的是Heap FIle

HeapFile就是用来放page的文件,当然我们可以通过文件名+offset,访问某个page
同时我们需要可以遍历所有的page,知道哪些page有free space可以用来存放tuples

所以这里heap file也有两种实现方式,


继续看看Page的构造是怎么样的?
可以看到在page中的header,存储了一些元数据,如果需要self-contained,就需要包含scheam,编码信息等

那么data,是如何组织的了?
其实有两种方式存储数据库的数据,
Tuple-oriented和Log-structured
Tuple-oriented主要的存储方式是,slotted pages
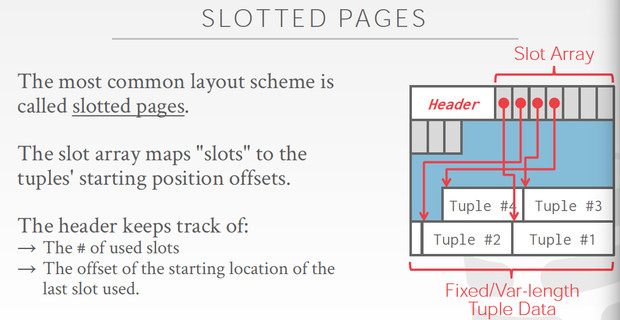
这个方法关键就是加入了slot array来索引各个tuple,这样就可以兼容变长的tuples,不然怎么知道每个tuple从哪里开始,删除tuple也更简单
如果是Log-structured,写数据会比较简单
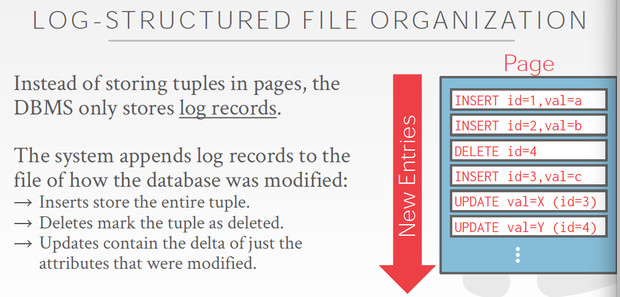
但读数据就比较麻烦了,需要replay出数据,因为你只记录了log吗
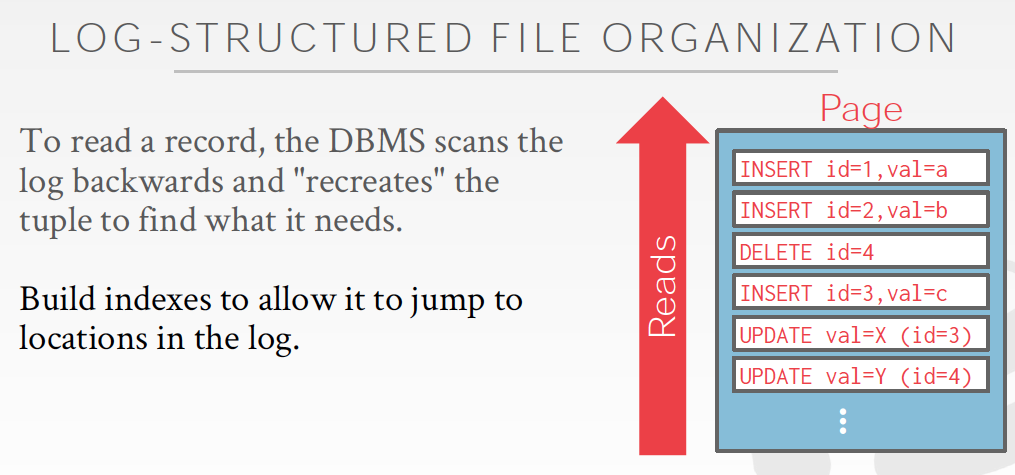
提供读性能的方式有两种,尽量减少replay的数据,就是打snapshot或建index
比较常用的就是定期的做compaction,比如HBase, Cassandra,LevelDB,RocksDB
Compaction分为两种,按层逐级compact,或是universal

最后,tuple本身的存储结构是怎么样的?

同样Tuple也有一个header,里面包含元数据,比如这个tuple可见性,BitMap表示哪些是NULL
注意这里一般是不会包含schema,因为在每个tuple都包含没有必要,一个table的schema是固定的,单独存就好
Denormalized Tuple Data
这是一种针对查询的优化,
Denormalized,都知道关系模型有范式,冗余数据一定是会打破范式的,所以是de-
两个表join,把需要的字段冗余到一张表中,称为pre join,读的时候会比较快,单纯从当前page就可以完成,但是写就麻烦了,因为打破范式了吗


总结一下上面的说的,如下图
这里page管理用的是direction的方式,所以读取page2,
首先要把direction page加载到buffer里面,这样读到page2的地址然后再去读出page2,然后Execute engine需求去解析page
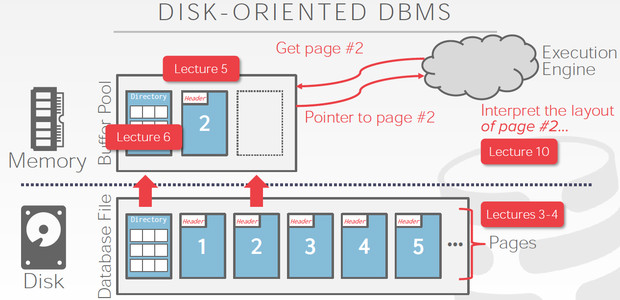
Page中就是tuple的集合,tuple是a sequence of bytes,但如果我们要使用这些数据,首先要把这些bytes转化为相应类型的数据
主要的类型如下,

需要特别关注的,
浮点数和定点数
定点数就是小数点是固定的,所以我们用int分别存储小数点前后的数字就可以实现,定点数是可以做到精确计算的,但是局限也很明显,只能表示固定精度

浮点数就比较复杂了,因为小数是连续的,无限的,而计算机实现是离散的,有限的
所以要在计算机里面表示浮点小数,就需要用trick的方法去近似,定义出的标准就是IEEE-754,浮点运算是近似的,非精确的

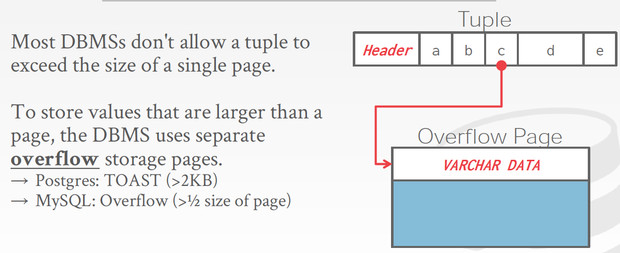
VARCHAR,BLOB
由于tuple大小不能超过page,比如对于varchar,如果大于page,需要把多的存放到overflow page里面
而对于blob这样的类型,干脆就需要存放到外部文件中,这里注意对于存放到外部文件的数据,是不保证transaction等语义的
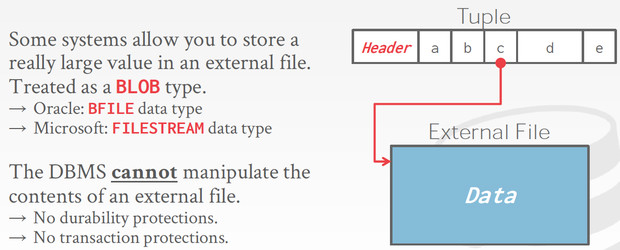
那么现在有个关键的问题,数据库的元数据是存储在什么地方的?
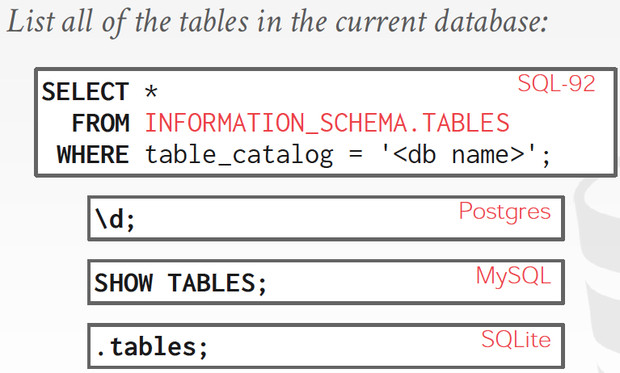
Catalogs,Catalogs的信息可以从Information_schema表中读取到


不同的库,对于元数据读取有不同的shortcuts,

最后再看下,行列存的区别,
行存,row storage,称为n-ary storage model
对于左图的OLTP的需求,行存很适合,插入和更新比较简单,整行的查询
但对于右图,OLAP的需求,行存会比较慢,BI需求往往需要扫描大量的行,但只是用其中的部分字段


列存,column store,decmposition storage model
相对于行存,列存是把一列的数据集中存储在一个page中,
这样上面的例子,就只需要读包含这两个列的page,其他page就不用读了


列存关键的问题是如何恢复成行?
这里给的方法也很简单,如果列中的每个value都是等长的,那直接根据length除就知道是第几行的
或者,就是在每个列里面记录下tupleid

BufferPool
bufferPool是一种cache机制,读磁盘慢,所以把读到的page缓存在bufferPool的frame里面
并且用Page Table来记录,到底哪些page在bufferpool中;page table中还会记录meta,比如dirty flag,这个page被改过,不能直接drop掉,需要写回磁盘;Pin,这个page正在被读,不能被swap out
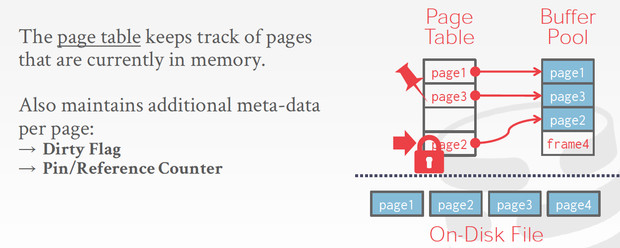
上面的锁的形状,表示latch,
我要读page2,table中miss,那么先用latch锁定一个slot,然后等page2被load到bufferPool的frame的时候,link上,这个过程中别人不能来修改或读取这个slot
下图,表示在数据库领域,lock和latch的区别,
lock是应用层面的,对逻辑内容的互斥,比如行,表,库,事务
latch是应用不可见的,内部数据结构的互斥

同时,如果一个数据库只有一个bufferPool,因为所有和磁盘间的数据交换都要通过他,很容易争抢,解决的方式,
我们可以用多个bufferPool,按不同的用途,维度区分开

BufferPool在cache的时候有些优化
Pre-Fetching
预取,这个就是dbms自己做cache的好处,你让os做cache,它没法去知道你下面可能要读什么
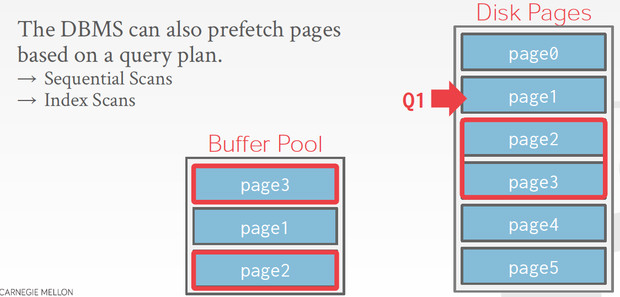

Scan Sharing
简单的说,就是Query之间可以共享已经cache的page

Buffer Pool ByPass
防止scan操作会污染buffer pool,所以单独开块内存去cache query级别的缓存

OS Page Cache
OS在文件系统操作的时候,本身会有page cache
既然dbms在buffer pool已经自己管理了page cache,那么os的这封cache显的有些多余,所以一般数据库都会用direct IO,把OS的page cache给关掉
不关掉有个好处,比如db进程重启了,但这个时候os的page cache还在,可以避免冷启动

Buffer Replacement Policy
LRU,这个每个page都有个最后访问的时间戳,淘汰最老的,但这个需要按时间排序;
Clock,对LRU的近似,更简单

LRU和Clock对于sequential scan都支持不好,scan很容易就会把之前的buffer给冲掉
所以可以用LRU-K,记录下history,算访问interval,这样scan这种只访问一次的,就很容易被淘汰掉
更特化的策略,比如priority hints,dbms知道哪些page比较重要,经常访问,打上标签
Dirty Page
page被修改过,就不能直接drop掉,主要flush回disk;
如果每次等eviction的时候再去flush脏页,会让eviction的过程非常的慢,所以一般会有个后台进程定期批量的去刷脏页
最后dbms除了有buffer pool来cache tuples和indexes,还有其他的一些memory pool,

CMU Database Systems - Storage and BufferPool的更多相关文章
- CMU Database Systems - Database Recovery
数据库数据丢失的典型场景如下, 数据commit后,还没有来得及flush到disk,这时候crash就会丢失数据 当然这只是fail的一种情况,DataBase Recovery要讨论的是,在各种f ...
- CMU Database Systems - Timestamp Ordering Concurrency Control
2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的 Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时 ...
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- CMU Database Systems - Query Processing
Query Model Query处理有三种方式, 首先是Iterator model,这是最基本的model,又称为volcano,pipeline模式 他是top-down的模式,通过next函数 ...
- CMU Database Systems - Two-phase Locking
首先锁是用来做互斥的,解决并发执行时的数据不一致问题 如图会导致,不可重复读 如果这里用lock就可以解决,数据库里面有个LockManager来作为master,负责锁的记录和授权 数据库里面的基本 ...
- CMU Database Systems - Distributed OLTP & OLAP
OLTP scale-up和scale-out scale-up会有上限,无法不断up,而且相对而言,up升级会比较麻烦,所以大数据,云计算需要scale-out scale-out,就是分布式数据库 ...
- CMU Database Systems - MVCC
MVCC是一种用空间来换取更高的并发度的技术 对同一个对象不去update,而且记录下每一次的不同版本的值 存在不会消失,新值并不能抹杀原先的存在 所以update操作并不是对世界的真实反映,这是一种 ...
- CMU Database Systems - Embedded Database Logic
正常应用和数据库交互的过程是这样的, 其实我们也可以把部分应用逻辑放到DB端去执行,来提升效率 User-defined Function Stored Procedures Triggers Cha ...
- CMU Database Systems - Parallel Execution
并发执行,主要为了增大吞吐,降低延迟,提高数据库的可用性 先区分一组概念,parallel和distributed的区别 总的来说,parallel是指在物理上很近的节点,比如本机的多个线程或进程,不 ...
随机推荐
- c# Match类
- Redis持久化从rdb切换到aof
要求:不重启redis的情况下,将RDB数据切换到AOF数据中 准备,配置文件已支持RDB持久化 port 6379 daemonize yes pidfile /data/6379/redis.pi ...
- UVA816 Abbott's Revenge (三元组BFS)
题目描述: 输入输出: 输入样例: SAMPLE 3 1 N 3 3 1 1 WL NR * 1 2 WLF NR ER * 1 3 NL ER * 2 1 SL WR NF * 2 2 SL WF ...
- 0025SpringMVC的几种响应方式
本文主要涉及到一下几种响应方式: 1.返回字符串2.返回void3.返回ModelAndView4.转发关键字forward和重定向关键字redirect返回字符串5.ajax调用返回json 具体实 ...
- margin值为负值
引用地址:http://www.cnblogs.com/2050/archive/2012/08/13/2636467.html#2457812 http://www.cnblogs.com/jsco ...
- Apollo简介及工作原理
一.Apollo简介 1.Apollo是携程框架部门研发的分布式配置中心 2.集中化管理应用的不同环境和不同集群的配置 3.配置修改后能够实时推送到应用端 4.具备规范的权限.流程治理等特性 二.Ap ...
- VOJ 1049送给圣诞夜的礼物——矩阵快速幂模板
题意 顺次给出 $m$个置换,反复使用这 $m$ 个置换对一个长为 $n$ 初始序列进行操作,问 $k$ 次置换后的序列.$m<=10, k<2^31$. 题目链接 分析 对序列的置换可表 ...
- 简述 OSI 七层协议?
OSI七层协议是一个用于计算机或通信系统间互联的标准体系. 物理层功能:主要是基于电器特性发送高低电压(电信号),高电压对应数字1,低电压对应数字0. 数据链路层的功能:定义了电信号的分组方式按照以太 ...
- 012——软件安装之_matlab2019安装
(一)参考文献:https://www.isharepc.com/14196.html (二)下载地址: 链接:https://pan.baidu.com/s/1gq06TuBWGr1Qc4owpRX ...
- NIO原理详解
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/CharJay_Lin/article/d ...