【转载】 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
原文地址:
https://www.cnblogs.com/steven-yang/p/5686473.html
-----------------------------------------------------------------------------------------------------------------
前言
最近在看Peter Harrington写的“机器学习实战”,这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能。
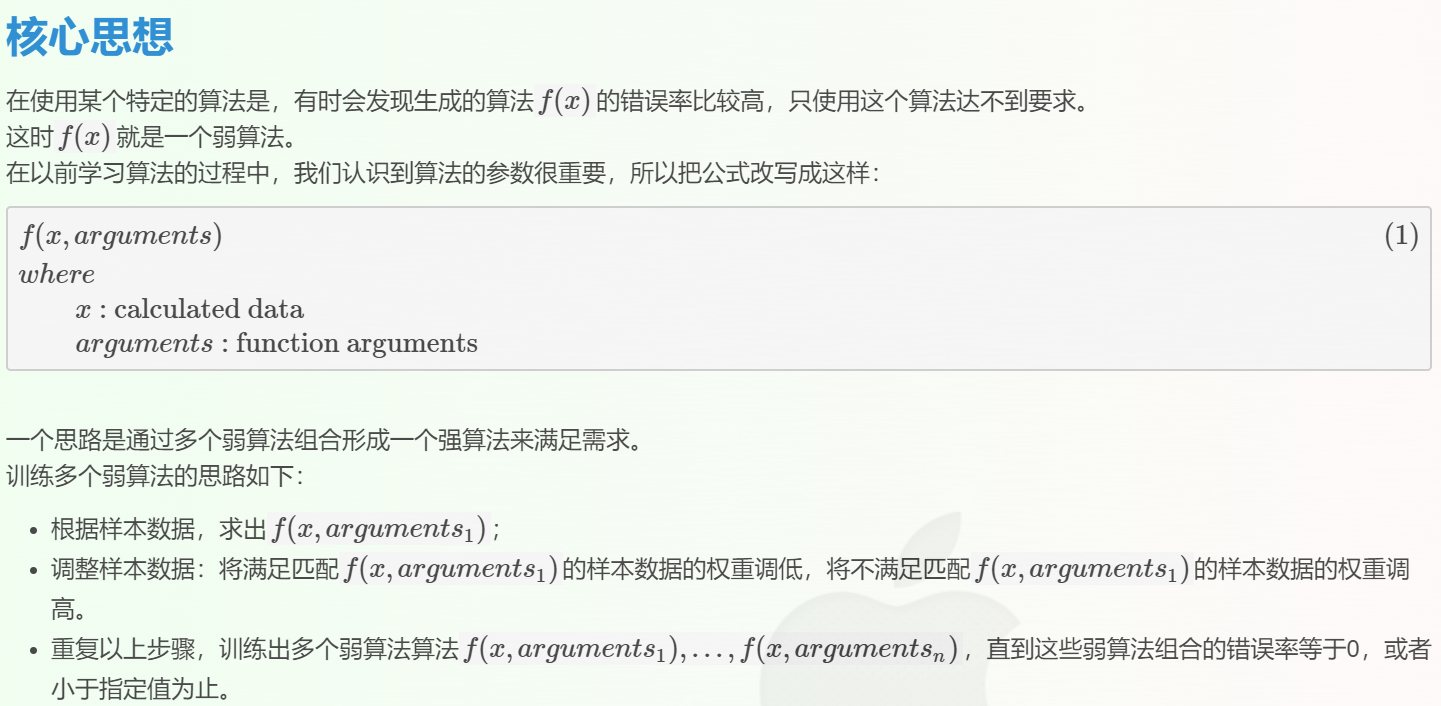
这个思路称之为Adaboost算法,是对其它算法组合的一种方式。
我们可以看出弱算法是同类的算法,也就是说,它们是基于相同的算法,只不过参数不同。这样元算法在训练算法的步骤中就好容易控制。
注:也有其它的的元算法,可以针对不同算法的。
基本概念
- 元算法(meta-algorithm),是对其它算法组合的一种方式。也称为集成方法(ensemble method)。
- 弱算法:准确度较低的算法。元算法通过组合多个弱算法来提高准确率。
- 强算法:可以认为是组合后的算法。
- boosting : 是一种元算法,将多个弱算法变成强算法的算法族。除了AdsBoost,还有LPBoost, TotalBoost, BrownBoost, xgboost, MadaBoost, LogitBoost, and others.
- Adaboost : Adaptive Boosting的简称。一个具体的boosting算法。本章就是介绍这个算法。
详解Adaboost
说明:书中弱算法是一个单层决策树算法,返回的是一个二类分类结果(-1, 1)。所以书中Adaboost也是一个二类分类算法。
Adaboost训练算法
- 输入
- 样本数据
- 弱算法的数量
- 输出
- 一个弱算法数组(弱算法参数,弱算法权重
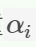 )
)
- 一个弱算法数组(弱算法参数,弱算法权重
- 逻辑
在一个迭代中(弱算法数量)
计算当前算法的参数
计算当前算法的错误率
计算当前算法的权重
计算下次样本数据的权重
计算当前的样本数据错误数,如果是0,退出。


解释:
假如有1000个sample,有100个sample被分错类,则:

可以看出错误的sample占的比例越小,下次的权重是二次方级数增大。
Adaboost分类算法
- 输入
- 分类数据
- 弱算法数组
- 输出
- 分类结果
- 逻辑
在一个迭代中(弱算法数量)
用当前弱算法计算分类结果$classified_i$
计算强分类结果(使用下面的公式)
返回分类结果
AdaBoost分类器中计算公式

参考
- Machine Learning in Action by Peter Harrington
- Boosting (machine learning)
-------------------------------------------------------------------------------------
【转载】 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能的更多相关文章
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
- 《机器学习实战第7章:利用AdaBoost元算法提高分类性能》
import numpy as np import matplotlib.pyplot as plt def loadSimpData(): dataMat = np.matrix([[1., 2.1 ...
- 利用AdaBoost元算法提高分类性能
当做重要决定时,大家可能都会吸取多个专家而不只是一个人的意见.机器学习处理问题时又何尝不是如此?这就是元算法背后的思路.元算法是对其他算法进行组合的一种方式. 自举汇聚法(bootstrap aggr ...
- 第七章:利用AdaBoost元算法提高分类性能
本章内容□ 组合相似的分类器来提髙分类性能□应用AdaBoost算法□ 处理非均衡分类问题
- 监督学习——AdaBoost元算法提高分类性能
基于数据的多重抽样的分类器 可以将不通的分类器组合起来,这种组合结果被称为集成方法(ensemble method)或者元算法(meta-algorithom) bagging : 基于数据随机抽样的 ...
- 机器学习实战 - 读书笔记(13) - 利用PCA来简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第13章 - 利用PCA来简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. ...
- 使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 第九篇:使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 机器学习实战 - 读书笔记(14) - 利用SVD简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第14章 - 利用SVD简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. 基 ...
随机推荐
- 大数据之路week07--day06 (Sqoop 的安装及配置)
Sqoop 的安装配置比较简单. 提供安装需要的安装包和连接mysql的驱动的百度云链接: 链接:https://pan.baidu.com/s/1pdFj0u2lZVFasgoSyhz-yQ 提取码 ...
- memcached的缺点
上篇博客说了为什么引入memcached,主要讲述了memcached的优点,接下来就是我们在使用中必须要注意的内容,memcached的缺点,只有正确认识它,才能运用自如,接下来先看一下memcac ...
- python开发笔记-python-numpy
一.Numpy概念 Numpy(Numerical Python的简称)是Python科学计算的基础包.它提供了以下功能: 除了为Python提供快速的数组处理能力,Numpy在数据分析方面还有另外 ...
- SVM: 相对于logistic regression而言SVM的 cost function与hypothesis
很多学习算法的性能都差不多,关键不是使用哪种学习算法,而是你能得到多少数据量和应用这些学习算法的技巧(如选择什么特征向量,如何选择正则化参数等) SVM在解决非线性问题上提供了强大的方法. logis ...
- 用jquery快速解决IE输入框不能输入的问题_jquery
代码如下: 在IE10以上版本,微软为了提高IE输入框的便利性,增加了文本内容全部删除和密码眼睛功能,但是有些时候打开新的页面里,输入框却被锁定无法编辑,需要刷新一下页面,或者如果输入框有内容需要点击 ...
- JAVA中使用Dom解析XML
在G盘下新建XML文档:person.xml,XML代码: <?xml version="1.0" encoding="utf-8"?> <s ...
- C# 对IOC的理解 依赖的转移
原文:https://blog.csdn.net/huwei2003/article/details/40022011 系统 可方便的替换 日志类 自己的理解: 依赖接口,日志的实例化 不直接写在依赖 ...
- 洛谷 P1006 传纸条 题解
P1006 传纸条 题目描述 小渊和小轩是好朋友也是同班同学,他们在一起总有谈不完的话题.一次素质拓展活动中,班上同学安排做成一个m行n列的矩阵,而小渊和小轩被安排在矩阵对角线的两端,因此,他们就无法 ...
- flutter踩坑小记:The number of method references in a .dex file cannot exceed 64K.
The number of method references in a .dex file cannot exceed 64K. 这句话的意思翻译出来是:.dex文件中的方法引用数不能超过64K. ...
- Three.js实现滚轮放大展现不同的模型
目录 Three.js实现滚轮放大展现不同的模型 修改OrbitControls.js的源码 OrbitControls在透视相机(PerspectiveCamera)的控制原理 具体实现 Three ...