spark的一些基本概念和模型
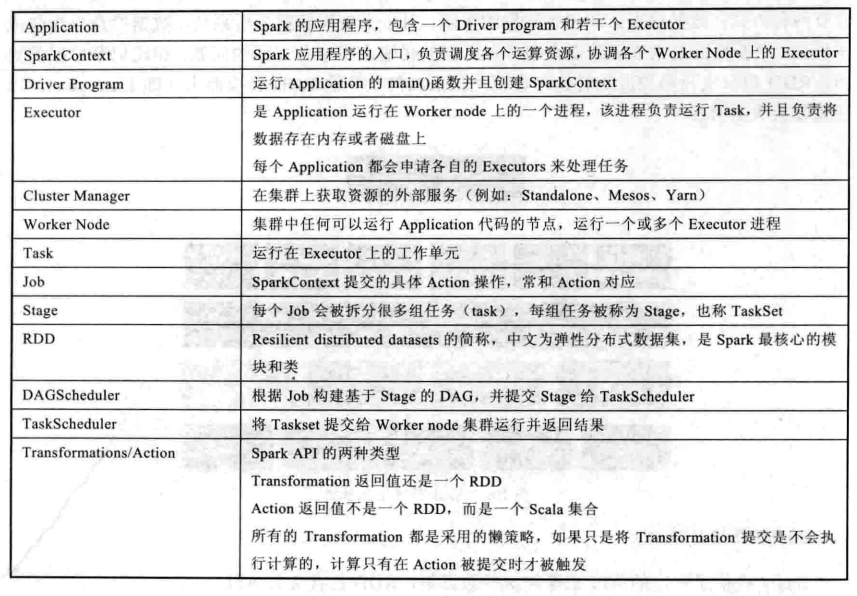
Application
application和Hadoop MapReduce类似,都是指用户编写的spark应用程序,其中包含了一个driver功能的代码和分布在集群中多个节点运行的executor代码。
Driver
使用driver这一概念的分布式框架很多,比如hive。spark中的driver即运行上述application的main()函数并创建sparkcontext,创建sparkcontext的目的是为了准备spark应用程序的运行环境。在spark中,由sparkcontext负责与clustermanager通信,进行资源的申请,任务的分配和监控等。当executor部分执行完毕以后,driver负责将sparkcontext关闭。通常用sparkcontext代表driver。
Executor
某个application运行worker节点上的一个进程,该进程负责执行task,并且负责将数据存储在内存或者磁盘上。每个application都有各自独立的一批executor。在spark on yarn模式下,其进程名字为CoarseGrainedExecutor Backend,类似于Hadoop MapReduce中的YarnChild,一个CoarseGrainedExecutor Backend进程有且仅有一个executor对象,它负责将task包装成taskRunner,并从线程池中抽取一个空闲线程运行task。这样,每个CoarseGrainedExecutor Backend能并行运行task的数量就取决于分配给它的CPU个数了。
ClusterManager
指的是在集群上获取资源的外部服务,目前有三种类型。
Standalone
Spark原生的资源管理,由master负责资源的分配,可以在亚马逊的EC2上运行。
Apache Mesos
与Hadoop MapReduce兼容性良好的一种资源调度框架。
Hadoop Yarn
主要指的是yarn中的resourcemanager。
Worker
集群中任何可以运行application代码的节点,类似于yarn中的nodemanager节点。在standalone模式中指的就是通过slave文件配置的worker节点,在spark on yarn中指的是nodemanager节点。
Task
被送到某个executor上的工作单元,和Hadoop MapReduce中的maptask和reducetask概念一样,是运行Application的基本单位,多个task组成一个stage,而task的调度和管理由TaskScheduler负责。
Job
包含多个task组成的并行计算,往往由spark Action触发产生。一个Application中可能会产生多个job
Stage
每个job会拆分成多组task,作为一个TaskSet,其名称为Stage,Stage的划分和调度由DAGSchedule负责。Stage有非最终的Stage(即shuffle Map Stage)和最终的Stage即(Result Stage)两种,Stage的边界就是发生shuffle的地方。
RDD
Spark的基本计算单元,通过一系列的算子进行操作(主要有transformation和Action两种操作)。同时,RDD是Spark最核心的东西,它表示已被分区、被序列化、不可变的、有容错机制的,并且能够被并行操作的数据集合。其存储基本可以是磁盘也可以是内存,通过spark.storageLevel属性配置。
共享变量
在spark Application运行时,可能需要共享一些变量,提供给Task或Driver使用。Spark提供了两种共享变量,一种是可以缓存到各个节点的广播变量,另外一种是只支持加法操作,可以实现求和的累加变量。
宽依赖
或称为shuffleDependency,与Hadoop MapReduce中的shuffle的数据依赖相同,宽依赖需要计算好所有父RDD对应的数据分区,然后在节点之间进行shuffle。
窄依赖
或称为narrowDependency,指某个具体的RDD,其分区partition a最多被子RDD中的的一个分区partition b依赖,此种情况只有map任务,是不需要shuffle过程的。窄依赖分为1:1和N:1两种。
DAGScheduler
根据job构建基于stage的DAG,并提交stage给TaksScheduler,其划分stage的依据是RDD之间的依赖关系。
TaskScheduler
将task任务提交给worker运行,每个executor运行什么task就是再次分配的。
常见术语表
spark的一些基本概念和模型的更多相关文章
- 大话Spark(1)-Spark概述与核心概念
说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先 ...
- 【转】浅谈UML的概念和模型之UML九种图
原文地址:浅谈UML的概念和模型之UML九种图 目录: UML的视图 UML的九种图 UML中类间的关系 上文我们介绍了,UML的视图,在每一种视图中都包含一个或多种图.本文我们重点讲解UML每种图的 ...
- 【转】从PowerDesigner概念设计模型(CDM)中的3种实体关系说起
PowerDesigner概念模型的relationship .inheritance. association 从PowerDesigner概念设计模型(CDM)中的3种实体关系说起
- Spark快速获得CrossValidator的最佳模型参数
Spark提供了便利的Pipeline模型,可以轻松的创建自己的学习模型. 但是大部分模型都是需要提供参数的,如果不提供就是默认参数,那么怎么选择参数就是一个比较常见的问题.Spark提供在org.a ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
- Spark 概念学习系列之Spark基本概念和模型(十八)
打好基础,别小瞧它! spark的运行模式多种多样,在单机上既可以本地模式运行,也可以伪分布模式运行.而当以分布式的方式在集群中运行时.底层的资源调度可以使用Mesos或者Yarn,也可使用spark ...
- Spark流式编程介绍 - 编程模型
来源Spark官方文档 http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#programm ...
- 浅谈UML的概念和模型之UML九种图
1.用例图(use case diagrams) [概念]描述用户需求,从用户的角度描述系统的功能 [描述方式]椭圆表示某个用例:人形符号表示角色 [目的]帮组开发团队以一种可视化的方式理解系统的功能 ...
- [UML]转:浅谈UML的概念和模型之UML九种图
转自:http://blog.csdn.net/jiuqiyuliang/article/details/8552956 目录: UML的视图 UML的九种图 UML中类间的关系 上文我们介绍了,UM ...
随机推荐
- python之json库的使用
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写. 1.json库的使用 使用 JSON 函数需要导入 json 库:import jso ...
- Unity VS2017 调试外部DLL
之前写的C++ DLL VS2012 都可以附加进程的方式调试Unity中的调用 这次用了一个C# DLL VS2017 在Unity 2018上无法附加进程的方式调试 经过一番折腾, 主要是两个问题 ...
- CSS标签选择器&类选择器
基本选择器包括标签选择器.类选择器和ID选择器三类,其他选择器都是在这三类选择器的基础上组合形成 ##标签选择器 示例: <style type="text/css"> ...
- 【layui】layer.photos 相册层动态生成Img 中出现的问题的解决方案
layui版本:2.5.5 参照文档:https://www.jianshu.com/p/c594811fa882 他的3.8的解决方案有一些调整因为发现他的解决方式有些繁琐而最新的2.5.5版本中有 ...
- 如何在backoffice里创建Hybris image container以及分配给product
登录backoffice,在media container视图点击新建按钮: Catalog选择Product Catalog: 在Properties界面,可以选择media实例放入该contain ...
- 【CMDB】获取服务器数据
一.通过agent的方式 原理:服务器定制执行py文件通过subprocess模块采集数据发送给数据收集的机器 数据收集的机器:192.168.11.62 服务器:192.168.11.169 数据收 ...
- vim小结
1.工作模式 命令模式 编辑模式 一般模式 2.配置文件 :set nu / :set nonu 显示与取消行号 :syntax on / :syntax off 是否依据语法显示相关的颜色帮 ...
- Windows性能计数器监控实践
Windows性能计数器(Performance Counter)是Windows提供的一种系统功能,它能实时采集.分析系统内的应用程序.服务.驱动程序等的性能数据,以此来分析系统的瓶颈.监控组件的表 ...
- python链式对比
参考 https://www.cnblogs.com/shanghongyun/p/10519579.html 为什么Python中“2==2>1”结果为True在Python中,你可能会发现这 ...
- 团队作业第六次—团队Github实战训练(追光的人)
所属课程 软件工程1916 作业要求 团队作业第六次-团队Github实战训练 团队名称 追光的人 作业目标 搭建一个相对公平公正的抽奖系统,根据QQ聊天记录,完成从统计参与抽奖人员颁布抽奖结果的基本 ...