图论篇2——最小生成树算法(kurskal算法&prim算法)
基本概念
树(Tree)
如果一个无向连通图中不存在回路,则这种图称为树。
生成树 (Spanning Tree)
无向连通图G的一个子图如果是一颗包含G的所有顶点的树,则该子图称为G的生成树。
生成树是连通图的极小连通子图。这里所谓极小是指:若在树中任意增加一条边,则将出现一条回路;若去掉一条边,将会使之变成非连通图。
最小生成树
一个带权值的连通图。用$n-1$条边把$n$个顶点连接起来,且连接起来的权值最小。
应用场景
设想有9个村庄,这些村庄构成如下图所示的地理位置,每个村庄的直线距离都不一样。若要在每个村庄间架设网络线缆,若要保证成本最小,则需要选择一条能够联通9个村庄,且长度最小的路线。
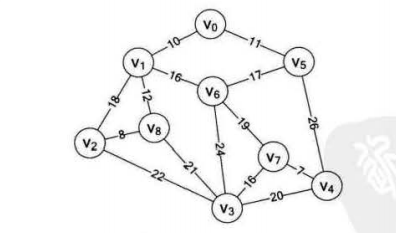
Kruskal算法
知识点:数据结构——并查集
基本思想
始终选择当前可用、不会(和已经选取的边)构成回路的最小权植边。
具体步骤:
1. 将所有边按权值进行降序排序
2. 依次选择权值最小的边
3. 若该边的两个顶点落在不同的连通分量上,选择这条边,并把这两个顶点标记为同一连通分量;若这条边的两个顶点落到同一连通分量上,舍弃这条边。反复执行2,3,直到所有的都在同一连通分量上。【这一步需要用到上面的并查集】
模板题:https://www.luogu.org/problem/P3366
#include <iostream>
#include <algorithm>
using namespace std;
int pre[];
int n, m; //n个定点,m条边 struct ENode {
int from, to, dis;
bool operator<(ENode p) {
return dis < p.dis;
}
}M[]; int Find(int x) {
return x == pre[x] ? pre[x] : pre[x] = Find(pre[x]);
} int kurskal() {
sort(M, M + m);
int N = n, res = ;
for (int i = ; i < m && N > ; i++) {
int fx = Find(M[i].from), fy = Find(M[i].to);
if (fx != fy) {
pre[fx] = fy;
N--;//找到了一条边,当N减到1的时候表明已经找到N-1条边了,就完成了
res += M[i].dis;
}
}
if (N == )//循环做完,N不等于1 表明没有找到合适的N-1条边来构成最小生成树
return res;
return -;
} int main() {
cin >> n >> m;
for (int i = ; i <= n; i++) {
pre[i] = i;
}
for (int i = ; i < m; i++) {
scanf("%d%d%d", &M[i].from, &M[i].to, &M[i].dis);;
}
int ans = kurskal();
if (ans != -)
cout << ans << endl;
else
cout << "orz" << endl;
return ;
}
Prim算法
Prim算法思想:
首先将图的点分为两部分,一种是访问过的$u$(第一条边任选),一种是没有访问过的$v$
1: 每次找$u$到$v$的权值最小的边。
2: 然后将这条边中的$v$中的顶点添加到$u$中,直到$v$中边的个数$=$顶点数$-1$
图解步骤:
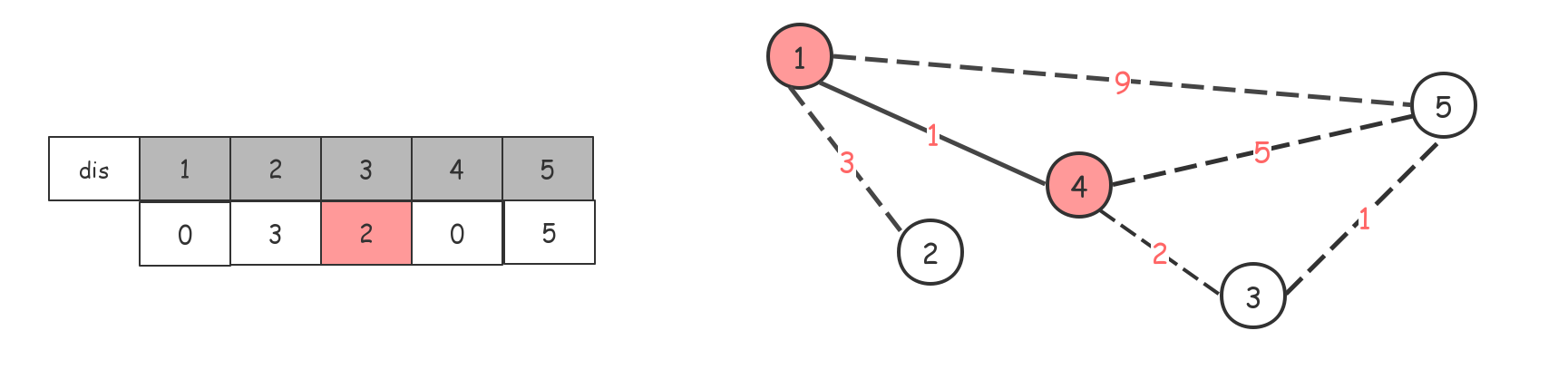
维护一个$dis$数组,记录只使用已访问节点能够到达各未访问节点最短的权值。
初始值为节点1(任意一个都可以)到各点的值,规定到自己是0,到不了的是$inf$(定义一个特别大的数)。
找当前能到达的权值最短的点。1-->4,节点4

将dis[4]赋值为0,标记为已访问过,同时借助4节点更新dis数组。
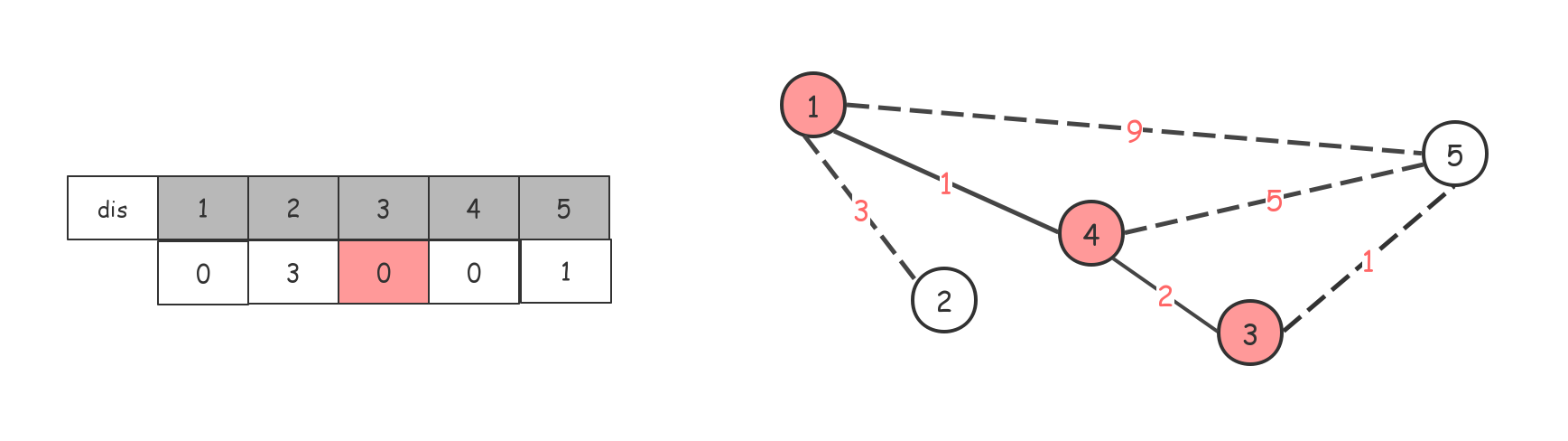
后面依次
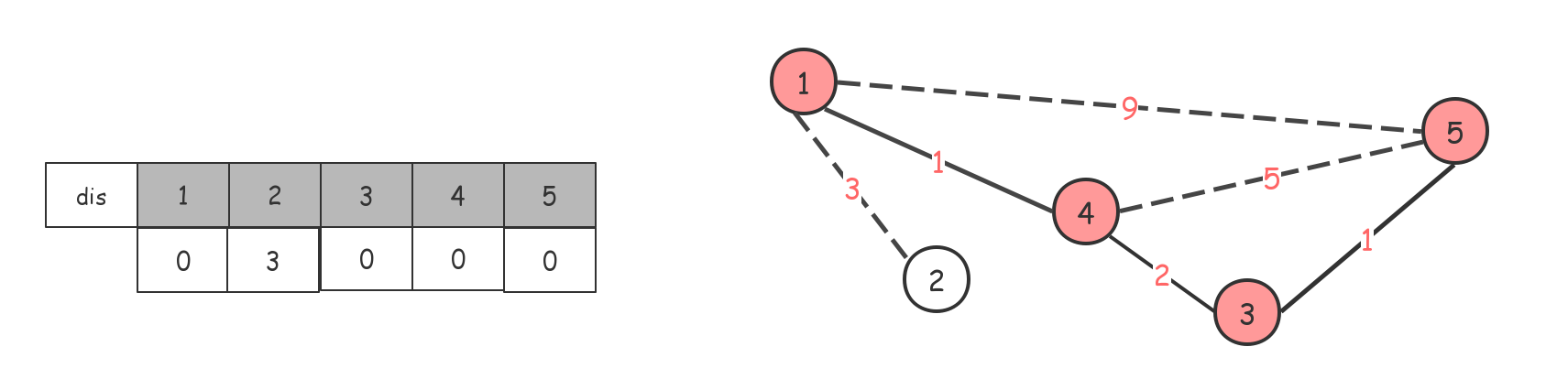
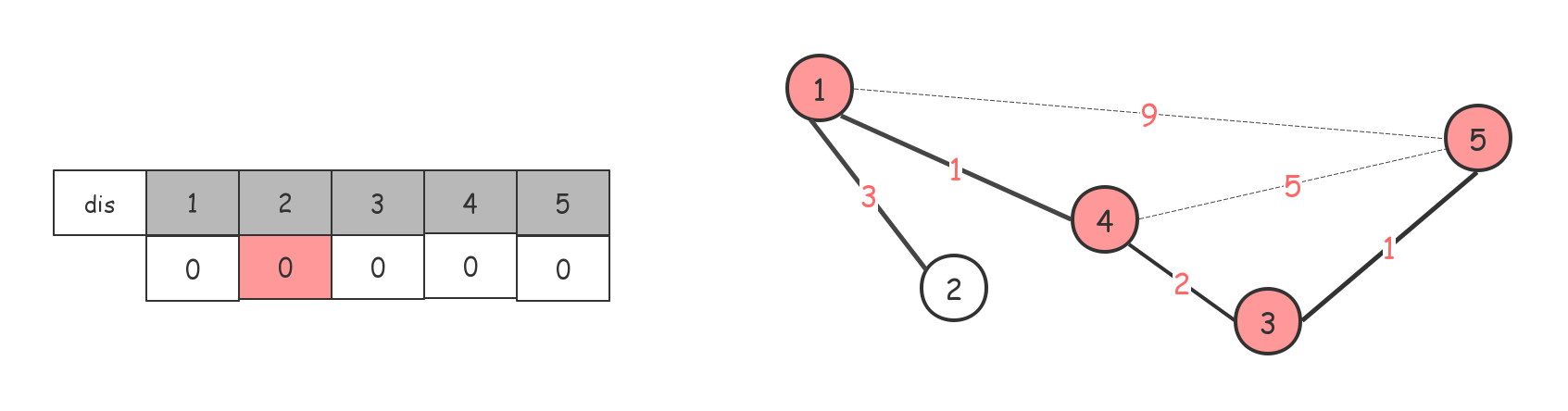
最后整个dis数组都是0了,最小生成树也就出来了,如果$dis$数组中还有 $inf$ 的话,说明这不是一个连通图。
还是上面那道模板题:https://www.luogu.org/problem/P3366
#include <iostream> #include <fstream>
using namespace std; struct ENode {
int dis, to;//权重、指向
ENode* next = NULL;
void push(int to, int dis) {
ENode* p = new ENode;
p->to = to; p->dis = dis;
p->next = next;
next = p;
}
}*head;
const int inf = << ;
int N, M;
int dis[]; int prim() {
int res = ; for (int i = ; i <= N; i++) {
dis[i] = inf;
} for (int i = ; i < N; i++) {//与kurskal区分,找边是N-1条边,找点是N个点
int v = , MIN = inf;
for (int j = ; j <= N; j++) {
//到不了的,访问过的不进行比较
if (dis[j] != && dis[j] < MIN) {
v = j;
MIN = dis[j];
}
}
if (MIN == inf && v != )//这里v!=1是为了把dis的初始化放在循环里面做,也可以放在循环外面做,但是外层循环就只需要做N-1次了
return -;//还没找够n个点,没路了
res += dis[v];
dis[v] = ;
ENode *p = head[v].next;
while (p) {
if (dis[p->to] > p->dis) {
dis[p->to] = p->dis;
}
p = p->next;
}
}
return res;
} int main() {
#ifdef LOCAL
fstream cin("data.in");
#endif // LOCAL cin >> N >> M;
head = new ENode[N + ];
for (int i = ; i < M; i++) {
int from, to, dis;
scanf("%d%d%d", &from, &to, &dis);
//cin >> from >> to >> dis;
head[from].push(to, dis);
head[to].push(from, dis);
}
int ans = prim();
if (ans != -)
cout << ans << endl;
else
cout << "orz" << endl;
return ;
}
两者区别
时间复杂度
prim算法
时间复杂度为$O(n^2)$,$n$为顶点的数量,其时间复杂度与边得数目无关,适合稠密图。

kruskal算法
时间复杂度为$O(e\cdot loge)$,$e$为边的数目,与顶点数量无关,适合稀疏图。

其实就是排序的时间,因为并查集的查询、合并操作都是$O(1)$。
总结
通俗点说就是,点多边少用Kruskal,因为Kruskal算法每次查找最短的边。 点少边多用Prim,因为它是每次找一个顶点。
具体选择用那个,可以用电脑算一下,题目给的数据级别,$n^2$和$e\cdot loge$看看那个小,比如上面的模板题,题目给的数据级别是$(n<=5000,e<=200000)$,粗略估算一下,kurskal算法一定是会快不少的,结果也确实如粗。
实现难度
明眼人都能看出来,kurskal算法要简单太多了。kurskal算法不需要把图表示出来,而Prim算法必须建表或者邻接矩阵,所以从上面的数据也能看出来当边的数目较大时,Prim算法所占用的空间比kurskal算法多了很多。
拓展
堆优化Prim算法
用堆存储当前所有可到达的点和距离,就是把dis数组里的内容一式两份,存在堆里,然后每次取堆顶元素,每次操作为$O(logn)$,所以使用堆优化后的Prim算法理论上时间复杂度为$O(nlogn)$,但是好像没有达到想要的效果

看了测试数据发现,有很多重边,那就合理了,做了很多次的无用循环,所以时间上也和kurskal比较相近。所以在数据可靠、无重边的情况下,这个算法一定是上述几种中最快的一个。
#include <iostream>
#include <fstream>
#include <cstdio>
#include <queue> using namespace std;
struct P {
int dis, v;
P(int d, int v) :dis(d), v(v) {};
bool operator<(P p)const {
return p.dis < dis;
}
};
struct ENode {
int dis, to;//权重、指向
ENode* next = NULL;
void push(int to, int dis) {
ENode* p = new ENode;
p->to = to; p->dis = dis;
p->next = next;
next = p;
}
}*head;
const int inf = << ;
int N, M;
int dis[];
bool fuck[]; int prim() {
priority_queue<P>pq;
pq.push(P(, ));
int res = , cnt = N;
dis[] = ;
fill(dis + , dis + N + , inf); while (!pq.empty() && cnt > ) {//与kurskal区分,找边是N-1条边,找点是N个点
int v = pq.top().v, d = pq.top().dis;
pq.pop();
if (fuck[v])continue;
fuck[v] = true;
res += d;
cnt--;
ENode* p = head[v].next;
while (p) {
if (dis[p->to] > p->dis) {
dis[p->to] = p->dis;
pq.push(P(p->dis, p->to));
}
p = p->next;
}
}
if (cnt > )
return -;
return res;
} int main() {
#ifdef LOCAL
fstream cin("data.in");
#endif // LOCAL
cin >> N >> M;
head = new ENode[N + ];
for (int i = ; i < M; i++) {
int from, to, dis;
scanf("%d%d%d", &from, &to, &dis);
//cin >> from >> to >> dis;
head[from].push(to, dis);
head[to].push(from, dis);
}
int ans = prim();
if (ans != -)
cout << ans << endl;
else
cout << "orz" << endl;
return ;
}
图论篇2——最小生成树算法(kurskal算法&prim算法)的更多相关文章
- 【数据结构】 最小生成树(三)——prim算法
上一期介绍到了kruskal算法,这个算法诞生于1956年,重难点就是如何判断是否形成回路,此处要用到并查集,不会用当然会觉得难,今天介绍的prim算法在kruskal算法之后一年(即1957年)诞生 ...
- 最小生成树-普利姆(Prim)算法
最小生成树-普利姆(Prim)算法 最小生成树 概念:将给出的所有点连接起来(即从一个点可到任意一个点),且连接路径之和最小的图叫最小生成树.最小生成树属于一种树形结构(树形结构是一种特殊的图),或者 ...
- 一步一步写算法(之prim算法 下)
原文:一步一步写算法(之prim算法 下) [ 声明:版权所有,欢迎转载,请勿用于商业用途. 联系信箱:feixiaoxing @163.com] 前两篇博客我们讨论了prim最小生成树的算法,熟悉 ...
- 一步一步写算法(之prim算法 中)
原文:一步一步写算法(之prim算法 中) [ 声明:版权所有,欢迎转载,请勿用于商业用途. 联系信箱:feixiaoxing @163.com] C)编写最小生成树,涉及创建.挑选和添加过程 MI ...
- 算法起步之Prim算法
原文:算法起步之Prim算法 prim算法是另一种最小生成树算法.他的安全边选择策略跟kruskal略微不同,这点我们可以通过一张图先来了解一下. prim算法的安全边是从与当前生成树相连接的边中选择 ...
- 一步一步写算法(之prim算法 上)
原文:一步一步写算法(之prim算法 上) [ 声明:版权所有,欢迎转载,请勿用于商业用途. 联系信箱:feixiaoxing @163.com] 前面我们讨论了图的创建.添加.删除和保存等问题.今 ...
- 图论---最小生成树----普利姆(Prim)算法
普利姆(Prim)算法 1. 最小生成树(又名:最小权重生成树) 概念:将给出的所有点连接起来(即从一个点可到任意一个点),且连接路径之和最小的图叫最小生成树.最小生成树属于一种树形结构(树形结构是一 ...
- 最小生成树的kruskal、prim算法
kruskal算法和prim算法 都说 kruskal是加边法,prim是加点法 这篇解释也不错:这篇 1.kruskal算法 因为是加边法,所以这个方法比较合适稀疏图.要码这个需要先懂并查集.因为我 ...
- 最小生成树(Minimum Spanning Tree)——Prim算法与Kruskal算法+并查集
最小生成树——Minimum Spanning Tree,是图论中比较重要的模型,通常用于解决实际生活中的路径代价最小一类的问题.我们首先用通俗的语言解释它的定义: 对于有n个节点的有权无向连通图,寻 ...
随机推荐
- .NET配置引用程序集的路径(分离exe和dll)
按照引用程序集路径的不同,程序集DLL分为两类: 1)全局DLL(在GAC中注册,GAC——全局程序集缓存),有关GAC的详细资料可以参考一下链接: http://dddspace.com/2011/ ...
- SVN版本管理系统使用教程
1.下载SVN安装包 https://tortoisesvn.net/downloads.html 2.下载SVN汉化包 网页下翻到下载处 3.下载服务端 https://www.visualsvn. ...
- Spring JdbcTemplate使用别名传参(NamedParameterJdbcTemplate)
原文地址http://www.voidcn.com/article/p-cwqegtpg-hx.html 在使用JdbcTemplate时,一般传参都是用的?来绑定参数,但是对于某种情况就不适用了,例 ...
- Beta冲刺(3/7)——2019.5.25
作业描述 课程 软件工程1916|W(福州大学) 团队名称 修!咻咻! 作业要求 项目Beta冲刺(团队) 团队目标 切实可行的计算机协会维修预约平台 开发工具 Eclipse 团队信息 队员学号 队 ...
- kubernetes学习一:安装及部署第一个Web应用
准备工作 首先准备Kubernets的环境,使用的是centos7.5 关闭防火墙: # systemctl disable firewalld # systemctl stop firewalld ...
- UI自动化实例:遍历点击带有滚动条的列表每一项
需求:验证列表每条资讯里的用户数是否正确.该列表分页请求数据,每页10条,每次滚动到底部自动增量请求10条. 实现自动化必要性: 1 资讯每天不定时更新需经常性验证, 程序更新或者环境切换需验证所有资 ...
- FreeSWITCH 总体架构
[1]总体结构 [2]代码结构目录 [3]模块简介 Applications应用 mod_abstraction – 提供了一个抽象的API调用(未来有更多功能)Provides an abstrac ...
- 最细的eclipse 安装maven踩过的坑
Eclipse安装maven插件踩过的坑 在线安装maven eclipse安装maven插件,在网上有各种各样的方法,博主使用过的也不止一种,但是留下的印象总是时好时不好,同样的方法也不确定那一次能 ...
- 解决:ElasticSearch ClusterBlockException[blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];
简记 使用SkyWalking用ES做存储,发现运行一段时间会提示ElasticSearch ClusterBlockException[blocked by: [FORBIDDEN/12/index ...
- 小知识点 之 JVM -XX:SurvivorRatio
JVM参数之-XX:SurvivorRatio 最近面试过程中遇到一些问JVM参数的,本着没用过去学习的办法看了些博客写得不准确,参考oracle的文档记录一下,争取每天记录一点知识点 -XX:Sur ...