Dependency Parsing
句子的依赖结构表现在哪些单词依赖哪些单词。单词之间的这种关系及可以表示为优先级之间的关系等。
Dependency Parsing
通常情况下,对于一个输入句子:\(S=w_{0} w_{1} \dots w_{n}\)。 我们用 \(w_{0}\) 来表示 ROOT,我们将这个句子转换成一个图 G。
依赖性解析通常分为训练与预测两步:
- 使用已经解析的注释库训练模型 M
- 得到模型 M之后,对于句子 S,通过模型解析出图 G。
基于转换的依赖性解析
该方法就是通过训练数据训练一个状态机,通过状态机转换对源语句进行解析。
基于贪心确定性过渡的解析
这个转换的系统本质也是一个状态机,但是不同的是,对于一个初始状态,会有多个终止状态。
对于每一个源语句 \(S=w_{0} w_{1} \dots w_{n}\) 每个状态可以表示成三部分 \(c=(\sigma, \beta, A)\) 。
- 第一部分 \(\sigma\) 用来存储来自 S 的 \(w_i\) ,使用栈存储
- \(\beta\) 表示一个来自 S 的缓冲
- A 表示 \(\left(w_{i}, r, w_{j}\right)\) 的集合,其中 \(w_{i}, w_{j}\) 来自 S,然后 r 表示 \(w_{i}, w_{j}\)之间的关系。
状态初始化:
- 初始状态是 \(C_0\) 可以表示为 \(\left[w_{0}\right]_{\sigma},\left[w_{1}, \ldots, w_{n}\right]_{\beta}, \varnothing\)。可以看到只有 \(w_0\) 在 \(\sigma\) 中,其它的 \(w_i\) 都在 \(\beta\) 中。还没有任何关系。
- 终止状态就是 \(\sigma,[ ]_{\beta}, A\) 形式。
状态转换的方法:
- 从缓存中移除一个单词兵放在 \(\sigma\) 栈顶,
- \(\mathrm{L} \mathrm{EFT}-\mathrm{A} \mathrm{RC}_{r}(l)\):将 \(\left(w_{j}, r, w_{i}\right)\) 添加至集合 A,\(w_{i}\) 是栈 \(\sigma\) 的第二个数据,\(w_{j}\) 是栈顶的单词,将 \(w_{i}\) 从栈中移除,这个 ARC 关系用 \(l\) 表示。
- \(\mathrm{RIGHT}-\mathrm{ARC}_{r}(l)\):将 \(\left(w_{i}, r, w_{j}\right)\) 添加到集合 A, \(w_{i}\)是栈的第二个单词,
神经依赖性解析
神经以来解析的效果要好于传统的方法。主要区别是神经依赖解析的特征表示。
我们描述的模型使用 arc 系统作为变换,我们的目的就是将原序列变成一个目的序列。就是完成解析树。这个过程可以看作是一个 encode 的过程。
Feature Selection:
第一步就是要进行特征的选择,对于神经网络的输入,我们需要定义一些特征,一般有以下这些:
\(S_{w o r d}\):S 中一些单词的向量表示
\(S_{\text {tag}}\):S 中一些单词的 Part-of-Speech (POS) 标签,POS 标签包含一个小的离散的集合:\(\mathcal{P}=\{N N, N N P, N N S, D T, J J, \dots\}\)
\(S_{l a b el}\):S 中一些单词的 arc-labels ,这个标签包含一个小的离散集合,描述依赖关系:\(\mathcal{L}=\{\) $amod, tmod $, \(n s u b j, c s u b j, d o b j\), \(\ldots\}\)
在神经网络中,我们还是首先会对这个输入处理,将这些编码从 one-hot 编码变成稠密的向量编码
对于单词的表示我们使用 \(e_{i}^{w} \in \mathbb{R}^{d}\)。使用的转换矩阵就是 \(E^{w} \in \mathbb{R}^{d \times N_{w}}\)。其中 \(N_w\) 表示字典的大小。\(e_{i}^{t}, e_{j}^{l} \in \mathbb{R}^{d}\) 分别表示第 \(i\) 个POS标签与第 \(j\) 个ARC 标签。对应的矩阵就是 \(E^{t} \in \mathbb{R}^{d \times N_{t}}\) and \(E^{l} \in \mathbb{R}^{d \times N_{l}}\)。其中 \(N_t\) 和 \(N_L\) 分别表示所有的 POS标签 与 ARC标签的个数。我们用 \(S^{w}, S^{t}, S^{l}\) 来表示 word, POS,ARC 的信息。
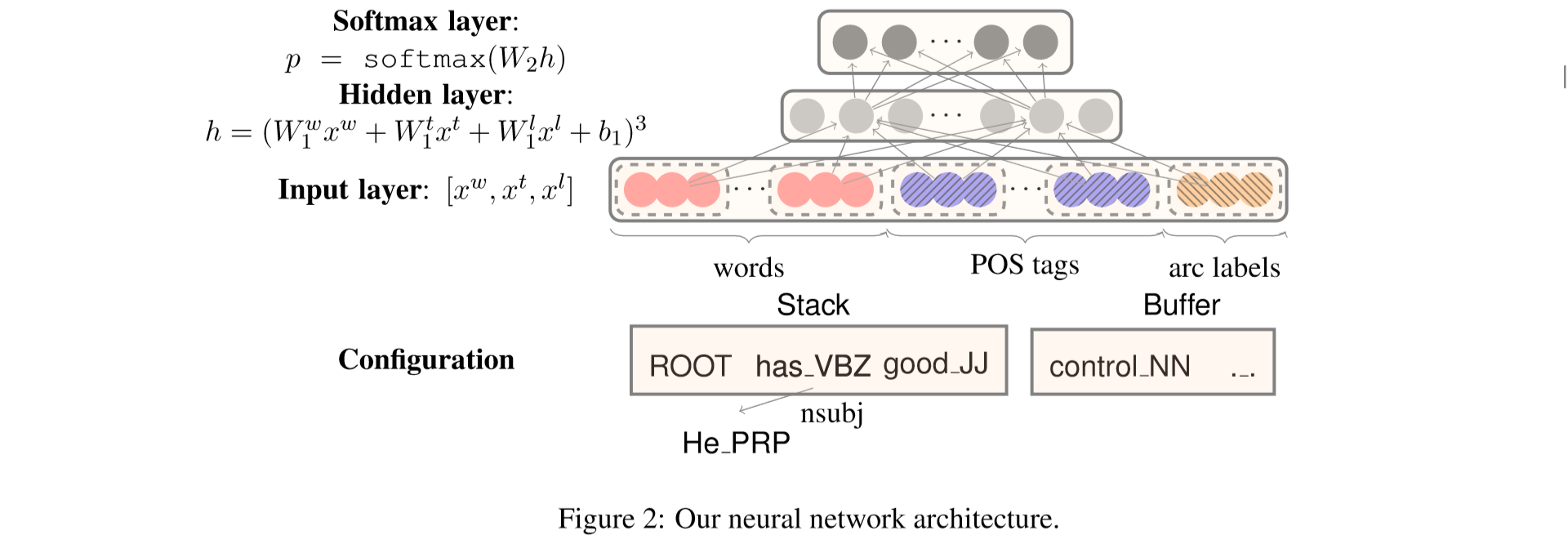
例如对于上面的这个图:
\(S_{tag}= \left\{l c_{1}\left(s_{2}\right) . t, s_{2} .t, r c_{1}\left(s_{2}\right) . t, s_{1} .t\right\}\)。然后我们将这些信息变成输入层的向量,比如对于单词来说,\(x^{w}=\left[e_{w_{1}}^{w} ; e_{w_{2}}^{w} ; \ldots e_{w_{n} w}^{w}\right]\)。其中 \(S_{word}=\left\{w_{1}, \ldots, w_{n_w}\right\}\),表示输入层的信息。同样的方式,我们可以获取到 \(x^t\) 与 \(x^l\)。然后我们经过一个隐含层,这个比较好理解:
\[
h=\left(W_{1}^{w} x^{w}+W_{1}^{t} x^{t}+W_{1}^{l} x^{l}+b_{1}\right)^{3}
\]
然后再经过一个 \(softmax\) 的输出层 \(p=\operatorname{softmax}\left(W_{2} h\right)\), 其中 \(W_2\) 是一个输出的矩阵,\(W_{2} \in \mathbb{R}|\mathcal{T}| \times d_{h}\)。
POS and label embeddings
就像单词的词典一样,我们对 POS 与 ARC 也有一个集合,其中 \(\mathcal{P}=\{\mathrm{NN}, \mathrm{NNP} ,\mathrm{NNS}, \mathrm{DT}, J J, \ldots \}\) 表示单词的一些性质, 例如 \(NN\) 表示单数名词。对于 \(\mathcal{L}=\{\)$ amod, tmod, nsubj, csubj, dobj$, \(\ldots\}\)表示单词间的关系。
Dependency Parsing的更多相关文章
- Dependency Parsing -13 chapter(Speech and Language Processing)
https://web.stanford.edu/~jurafsky/slp3/13.pdf constituent-based 基于成分的phrasal constituents and phras ...
- 依存分析 Dependency Parsing
依存分析 Dependency Parsing 句子成分依存分析主要分为两种:句法级别的和语义级别的 依存句法分析 syntactic dependency parsing 语义依存分词 semant ...
- 【神经网络】Dependency Parsing的两种解决方案
一.Transition-based的依存解析方法 解析过程:首先设计一系列action, 其就是有方向带类型的边,接着从左向右依次解析句子中的每一个词,解析词的同时通过选择某一个action开始增量 ...
- Transaction Replication6:Transaction cleanup
distribution中暂存的Transactions和Commands必须及时cleanup,否则,distribution size会一直增长,最终导致数据更新耗时增加,影响replicatio ...
- ZH奶酪:自然语言处理工具LTP语言云调用方法
前言 LTP语言云平台 不支持离线调用: 支持分词.词性标注.命名实体识别.依存句法分析.语义角色标注: 不支持自定义词表,但是你可以先用其他支持自定义分词的工具(例如中科院的NLPIR)把文本进行分 ...
- (转) The major advancements in Deep Learning in 2016
The major advancements in Deep Learning in 2016 Pablo Tue, Dec 6, 2016 in MACHINE LEARNING DEEP LEAR ...
- RNN and LSTM saliency Predection Scene Label
http://handong1587.github.io/deep_learning/2015/10/09/rnn-and-lstm.html //RNN and LSTM http://hando ...
- 我和NLP的故事(转载)
正值ACL录用结果发布,国内的老师和同学们又是一次大丰收,在这里再次恭喜所有论文被录用的老师和同学们!我人品爆发,也收获了自己硕士阶段的第二篇ACL论文.本来只是想单纯分享下自己中论文的喜悦,但没成想 ...
- awesome-nlp
awesome-nlp A curated list of resources dedicated to Natural Language Processing Maintainers - Keon ...
随机推荐
- DataPipeline CTO 陈肃:我们花了3年时间,重新定义数据集成
目前,中国企业在大数据流通.交换.利用等方面仍处于起步阶段,但是企业应用数据集成市场却是庞大的.根据 Forrester 数据看来,2017 年全球数据应用集成市场纯软件规模是 320 亿美元,如果包 ...
- nrm 工具的使用
一.什么是nrm? 这是官方的原话: 开发的npm registry 管理工具 nrm, 能够查看和切换当前使用的registry, 最近NPM经常 down 掉, 这个还是很有用的哈哈 顾名思义,就 ...
- php和mysql交互 面向对象
不返回结果集 <?php //使用对象属性和方法来插入数据 header('Content-type:text/html;carset=utf8'); $con=new mysqli('loca ...
- 了解 npm install -S -D 的区别,看这篇就完事了
一.npm install -S -D 的区别 npm install module_name -S 即 npm install module_name --save 写入dependencies n ...
- python_多线程
1.多线程的实现与阻塞 import time import threading def fun_yellow(num): for i in range(1,num+1): print('正在拿第:' ...
- Linux操作系统的进程管理和作业管理
Linux操作系统的进程管理和信号 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.lsof命令详解 1>.lsof概述 list open files查看当前系统文件的工 ...
- PAT甲级1002水题飘过
#include<iostream> #include<string.h> using namespace std; ]; int main(){ int n1, n2; wh ...
- Kotlin字节码生成机制详尽分析
通过注解修改Kotlin的class文件名: 对于Kotlin文件在编译之后生成的class文件名默认是有一定规则的,比如: 而其实这个生成字节码的文件名称是可以被改的,之前https://www.c ...
- Python开发AI应用-国际象棋应用
AI 部分总述 AI在做出决策前经过三个不同的步骤.首先,他找到所有规则允许的棋步(通常在开局时会有20-30种,随后会降低到几种).其次,它生成一个棋步树用来随后决定最佳决策.虽然树的大小随 ...
- CentOS7.6安装docker最新版
注意Centos7.4系统以下需要升级内核,否则会安装失败 yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config ...