【操作系统之四】Linux常用命令之awk
一、概念
awk是一个报告生成器,拥有强大的文本格式化能力。
数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出;
依次对每一行进行处理,然后输出;
它在命令行中使用,但更多是作为脚本来使用。
grep、sed、awk被称为Linux三剑客:
grep适合单纯的查找或匹配文本;
sed适合编辑匹配到的文本;
awk适合格式化文本;
二、awk命令格式
- awk [options] 'pattern{action}' file
- options参数有三个:-F指定分隔符,-f调用脚本,-v定义变量 var=value
- '' 引用代码块;
- pattern表示待匹配的模式;
- {action}表示一系列的动作命令;
- file表示等待操作的数据文件;
三、内置变量
1、分隔符
FS : 输入字段分隔符(默认是任何空格)。
- [root@PCS101 ~]# cat test
- abc##dfhj#kfjda#kjd
- def##kjs#4sf#kks#09j
- [root@PCS101 ~]# awk '{print $1,$2}' test
- abc##dfhj#kfjda#kjd
- def##kjs#4sf#kks#09j
- [root@PCS101 ~]# awk -F# '{print $1,$2}' test
- abc
- def
- [root@PCS101 ~]# awk -v FS='#' '{print $1,$2}' test
- abc
- def
OFS : 输出字段分隔符(默认值是一个空格)。
- [root@PCS101 ~]# awk -v FS='#' -v OFS='------' '{print $1,$2}' test
- abc------
- def------
- [root@PCS101 ~]# awk -v FS='#' -v OFS='------' '{print $1 $2}' test
- abc123
- def456
2、NR和FNR
NR : 表示记录数,在执行过程中对应于当前的行号
FNR : 同NR ,但相对于当前文件,多文件记录不递增,每个文件都从1开始。
- [root@PCS101 ~]# cat t1.txt t2.txt
- abc def hij klm
- j2k tb3
- kkk djk zlm enjl
- fas 2d3 98s y67s 98sm
- [root@PCS101 ~]# awk '{print NR,$0}' t1.txt t2.txt
- abc def hij klm
- j2k tb3
- kkk djk zlm enjl
- fas 2d3 98s y67s 98sm
- [root@PCS101 ~]# awk '{print FNR,$0}' t1.txt t2.txt
- abc def hij klm
- j2k tb3
- kkk djk zlm enjl
- fas 2d3 98s y67s 98sm
3、RS和ORS
RS : 输入行分隔符, 默认为换行符
- [root@PCS101 ~]# awk -v RS=' ' '{print NR,$0}' t1.txt
- abc
- def
- hij
- klm
- j2k
- tb3
- [root@PCS101 ~]#
ORS : 输出行分隔符,默认值是一个换行符
- [root@PCS101 ~]# awk -v ORS='+++' '{print NR,$0}' t1.txt
- abc def hij klm+++ j2k tb3+++[root@PCS101 ~]#
4、FILENAME
FILENAME : 当前输入文件的名。
- [root@PCS101 ~]# awk '{print FILENAME,NR,$0}' t1.txt t2.txt
- t1.txt abc def hij klm
- t1.txt j2k tb3
- t2.txt kkk djk zlm enjl
- t2.txt fas 2d3 98s y67s 98sm
- [root@PCS101 ~]#
5、ARGC和ARGV
ARGC : 命令行参数的数目。
ARGV : 包含命令行参数的数组。
- [root@PCS101 ~]# awk 'BEGIN{print "aaa",ARGV[0],ARGV[1],ARGV[2],ARGC}' t1.txt t2.txt
- aaa awk t1.txt t2.txt
注意:ARGV[0]指不是'pattern{action}'
6、自定义变量
变量名区分大小写。
方式一:
- [root@PCS101 ~]# awk -v myVar='testVar' 'BEGIN{print myVar}'
- testVar
- [root@PCS101 ~]# abc=
- [root@PCS101 ~]# awk -v newVar=$abc 'BEGIN{print newVar}'
方式二:
- [root@PCS101 ~]# awk 'BEGIN{myvar=111;myvar2="222";print myvar,myvar2}'
其他内置变量:
- $n: 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
- $ : 这个变量包含执行过程中当前行的文本内容。
ARGIND : 命令行中当前文件的位置(从0开始算)。
CONVFMT : 数字转换格式(默认值为%.6g)。
ENVIRON : 环境变量关联数组。
ERRNO : 最后一个系统错误的描述。
FIELDWIDTHS : 字段宽度列表(用空格键分隔)。
IGNORECASE : 如果为真,则进行忽略大小写的匹配。
NF : 表示字段数,在执行过程中对应于当前的字段数。 print $NF对应一行中最后一个字段
OFMT : 数字的输出格式(默认值是%.6g)。
RSTART : 由match函数所匹配的字符串的第一个位置。
RLENGTH : 由match函数所匹配的字符串的长度。
SUBSEP : 数组下标分隔符(默认值是34)。
print 是awk打印指定内容的主要命令,printf格式化输出命令。
其他相关:
\t 制表符
\n 换行符
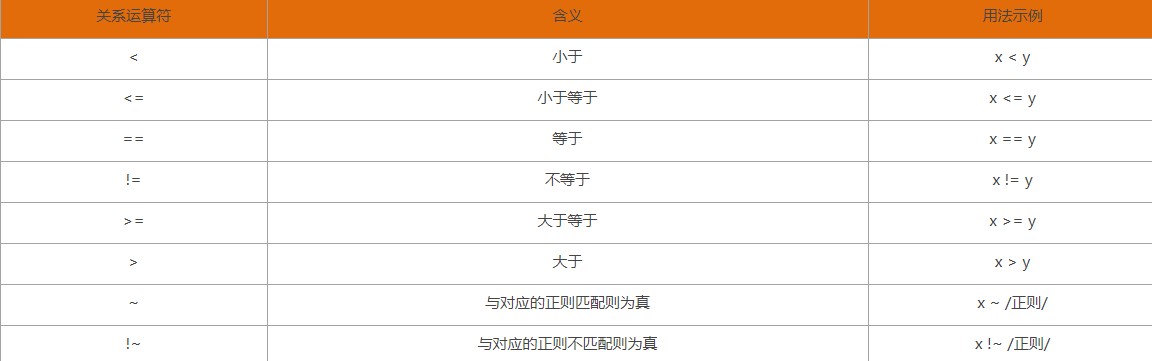
~ 匹配,与==相比不是精确比较
!~ 不匹配,不精确比较
+ 匹配时表示1个或1个以上
/[0-9][0-9]+/ 两个或两个以上数字
/[0-9][0-9]*/ 一个或一个以上数字
-F'[:#/]' 定义三个分隔符
四、格式化输出
使用格式化输出命令printf,默认不输出换行符。
- [root@PCS101 ~]# awk -F# '{printf "第一列:%s\t 第二列:%s\n" ,$1,$2}' test
- 第一列:abc 第二列:
- 第一列:def 第二列:
五、匹配
就是在进行命令操作之前做的条件匹配,只有符合条件的行才被操作。
1、BEGIN模式和END模式
2、关系表达式模式
可与逻辑运算符 (||, &&)一起使用
- [root@PCS101 ~]# awk 'NR==1 {print $0}' test
- abc##dfhj#kfjda#kjd
3、正则模式
- awk '/正则表达式/{...}' file
#查找以mysql开头的记录
- [root@PCS101 ~]# awk '/^mysql/{print $0}' /etc/passwd
- mysql:x::::/home/mysql:/bin/bash
4、行范围模式
- awk '/正则1/,/正则2/{...}' file
从被正则1匹配的行开始到被正则2匹配的行结束,之间的所有行都会被执行后面的操作。
六、动作
所有动作的最外侧都必须有{}包裹起来。
1、算术运算:(+,-,*,/,&,!,……,++,–)
所有用作算术运算符进行操作时,操作数自动转为数值,所有非数值都变为0
2、赋值运算:(=, +=, -=,*=,/=,%=,……=,**=)
3、逻辑运算: (||, &&,!)
4、关系运算:(<, <=, >,>=,!=, ==)
5、正则运算:(~,~!)(匹配正则表达式,与不匹配正则表达式)
6、三元运算:A ? B : C
7、流程控制
(1)条件分支控制
- [root@PCS101 ~]# awk '{if(NR==1) {print NR,NF}else if(NR==2){print NR,NF}}' test
(2)循环控制
- #for循环语法格式1
- for(初始化; 布尔表达式; 更新) {
- //代码语句
- }
- [root@PCS101 ~]# awk 'BEGIN{for(i=1;i<=3;i++){print i}}'
- #for循环语法格式2
- for(变量 in 数组) {
- //代码语句
- }
- #while循环语法
- while( 布尔表达式 ) {
- //代码语句
- }
- [root@PCS101 ~]# awk -v i= 'BEGIN{while(i<=5){print i;i++}}'
- #do...while循环语法
- do {
- //代码语句
- }while(条件)
- [root@PCS101 ~]# awk 'BEGIN{i=1;do{print i;i++}while(i<5)}'
continue:结束本次循环;
break:中断循环;
exit:不再执行动作,也不是退出awk,而是转向执行END;
- [root@PCS101 ~]# awk 'BEGIN{print 1;exit;print 2;}{print "middle"}END{print "end"}'
- end
next:结束对当前行的处理,转而处理下一行
- [root@PCS101 ~]# cat t1.txt
- abc def hij klm
- j2k tb3
- [root@PCS101 ~]# awk '{if(NR==2){next};print $0}' t1.txt
- abc def hij klm
七、数组
数组是一个包含一系列元素的表.
#将a定义为循环中的取值列表。从数组中取出的是数组的所有元素的下标
- [root@PCS101 ~]# awk 'BEGIN{a[0]="xiaohong";a[1]="xiaolan";for (i in a)print i;}'
- [root@PCS101 ~]#
八、内置函数
1、算数函数
- #rand是随机数函数,单独使用生成的值不变,需要配合srand使用,int截取整数部分
- [root@PCS101 ~]# awk 'BEGIN{print rand()}'
- 0.237788
- [root@PCS101 ~]# awk 'BEGIN{print rand()}'
- 0.237788
- [root@PCS101 ~]# awk 'BEGIN{srand();print rand()}'
- 0.0534209
- [root@PCS101 ~]# awk 'BEGIN{srand();print rand()}'
- 0.0632856
- [root@PCS101 ~]# awk 'BEGIN{srand();print int(100*rand())}'
2、字符串函数
gsub sub 字符串替换函数
index返回字符串出现的位置
spilt切割
3、其他函数
asort()排序函数
九、实际应用
- ()计算/home目录下,普通文件的大小,使用KB作为单位
- [root@PCS101 ~]# ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",int(sum/1024),"KB"}'
- total size is: KB
- ()统计netstat -anp 状态为LISTEN和CONNECT的连接数量分别是多少
- [root@PCS101 ~]# netstat -anp|awk '$6~/LISTEN|CONNECTED/{sum[$6]++} END{for (i in sum) printf "%-10s %-6s %-3s \n", i," ",sum[i]}'
- LISTEN
- CONNECTED
- ()统计/home/cluster目录下不同用户的普通文件的总数是多少?
- [root@PCS101 cluster]# ls -l|awk 'NR!=1 && !/^d/{sum[$3]++} END{for (i in sum) printf "%-6s %-5s %-3s \n",i," ",sum[i]}'
- cluster
- root
- 统计/home/cluster目录下不同用户的普通文件的大小总size是多少?
- [root@PCS101 cluster]# ls -l|awk 'NR!=1 && !/^d/{sum[$3]+=$5} END{for (i in sum) printf "%-6s %-5s %-3s %-2s \n",i," ",sum[i]/1024/1024,"MB"}'
- cluster 111.849 MB
- root 180.886 MB
- ()输出成绩表
- [root@PCS101 ~]# cat test0
- Marry
- Jack
- Tom
- Mike
- Bob
- [root@PCS101 ~]# awk 'BEGIN{math=0;eng=0;com=0;printf "Lineno. Name No. Math English Computer Total\n";printf "------------------------------------------------------------\n"}{math+=$3; eng+=$4; com+=$5;printf "%-8s %-7s %-7s %-7s %-9s %-10s %-7s \n",NR,$1,$2,$3,$4,$5,$3+$4+$5} END{printf "------------------------------------------------------------\n";printf "%-24s %-7s %-9s %-20s \n","Total:",math,eng,com;printf "%-24s %-7s %-9s %-20s \n","Avg:",math/NR,eng/NR,com/NR}' test0
- Lineno. Name No. Math English Computer Total
- ------------------------------------------------------------
- Marry
- Jack
- Tom
- Mike
- Bob
- ------------------------------------------------------------
- Total:
- Avg: 63.8 78.6
【操作系统之四】Linux常用命令之awk的更多相关文章
- linux操作系统2 linux常用命令
知识内容: 1.目录及文件操作 2.用户.群组与权限 3.重定向.管道 4.磁盘存储管理 5.系统命令 6.其他命令 参考: http://man.linuxde.net/ Linux命令规则:目录名 ...
- Linux常用命令之awk
标题:awk命令的使用 作用:awk是非常好用的数据处理工具,主要处理每一行的字段内的数据,默认的字段的分割符为空格键或[tab]键 一.awk脚本的基本结构: awk 'BEGIN{print &q ...
- 吴裕雄--天生自然Linux操作系统:Linux常用命令大全
系统信息 arch 显示机器的处理器架构 uname -m 显示机器的处理器架构 uname -r 显示正在使用的内核版本 dmidecode -q 显示硬件系统部件 - (SMBIOS / DMI) ...
- Linux学习笔记之四————Linux常用命令之文件管理
Linux命令——文件管理相关命令 <1>查看文件信息:ls ls是英文单词list的简写,其功能为列出目录的内容,是用户最常用的命令之一,它类似于DOS下的dir命令. Linux文件或 ...
- linux常用命令 、查看日志、web排查
linux常用命令 ps aux|grep xxx (比如 ps aux|grep tomcat ps aux|grep tomcat-portalvip ps aux|grep nginx 等) r ...
- 2020非常全的软件测试linux常用命令全集,linux面试题及参考答案
一.前言: 作为一名软件测试工程师,我相信大部分的人都和Linux打过交道,因为我们的服务器一般都是装的Linux操作系统,包括各种云服务器也都是用的Linux,目前主流是CentOS7,那么对于一个 ...
- 来不及解释!Linux常用命令大全,先收藏再说
摘要:Linux常用命令,很适合你的. 一提到操作系统,我们首先想到的就是windows和Linux.Windows以直观的可视化的方式操作,特别适合在桌面端PC上操作执行相应的软件.相比较Windo ...
- linux 常用命令大全
linux 常用命令大全 系统信息 arch 显示机器的处理器架构(1) uname -m 显示机器的处理器架构(2) uname -r 显示正在使用的内核版本 dmidecode -q 显示硬件系统 ...
- Linux常用命令整理 - imsoft.cnblogs
su 用户名 在不退出登陆的情况下,切换到另外一个人的身份如果用户名缺省,则切换到root状态会提示输入密码,密码不回显的. 在用su命令切换root用户时,使用“-”选项,这样可以将root的环境变 ...
随机推荐
- 使用Visual Studio的单元测试
步骤1:创建被测试项目 创建单元测试项目步骤2:在测试项目中写测试代码步骤3:运行测试 方法1 右键运行测试,方法2 点击测试 运行所有测试备注:单击方法 右测有提示可以看测试方法的输出
- asp.net chart美化+绑定数据--饼图
asp.net chart之饼图 开发环境VS2010 chart控件是vs自带控件 前台: <asp:Chart ID="Chart3" runat="serve ...
- el-upload进度条无效,on-progress无效问题解决方案
事先声明,本人系.net后端老菜鸟,vue接触没有多长时间,如果存在技术分享错误,切莫见怪,第一次写博,还请大佬们多多担待,转载请注明出处谢谢! 最近项目用到饿了么上传,于是参照官网接入el-uplo ...
- Vert.x(vertx) 认证和授权
每个线上系统几乎都是离不开认证和授权的,Vert.x提供了灵活.简单.便捷的认证和授权的支持.Vert.x抽象出了两个核心的认证和授权的接口,一个是 AuthProvider,另一个是User.通过这 ...
- 递归---Day29
递归的概述 递归:指在当前方法内自己调用自己的方式叫做递归 递归的分类: 1.直接递归称为方法自身调用自己. 2.间接递归可以用A方法调用B方法,用B方法调用C方法,用C方法调用A方法. 递归的注意事 ...
- combox绑定数据
HSMobile_Function.HSMobile_ProjectIDSelect(ProjectID, out dt_Machine);//取出表数据 comboBox_Ma ...
- 微信小程序开发--flex详细解读(2)
一.align-items和其参数 stretch / baseline 注:sretch只有在交叉轴没有设置固定长度的情况下才有作用 ...
- 人生物语——哲海拾贝
如今的这个社会,物欲横流.纸醉金迷.浮躁不安是这个时代的主旋律,在这样一个浮华年代的大染缸里,每个人内心都有那么一颗浮躁不安分的种子,或许它才开始发芽,或许它已经占据了你的心灵,人生当中追求 ...
- 使用gunicorn部署python web
gunicorn 是一款支持wsgi的web服务器, 支持gevent 首先安装setuptools. wget https://bootstrap.pypa.io/ez_setup.py $pyt ...
- ssh免密登录(公钥私钥)指令
1.在.ssh目录中执行ssh-keygen -t rsa命令生成两个秘钥,公钥(id_rsa.pub)和私钥(id_rsa) 2.ssh-copy-id -i id_rsa.pub 对方用户名@对方 ...