Guava 源码分析之Cache的实现原理
Guava 源码分析之Cache的实现原理
前言
Google 出的 Guava 是 Java 核心增强的库,应用非常广泛。
我平时用的也挺频繁,这次就借助日常使用的 Cache 组件来看看 Google 大牛们是如何设计的。
缓存
本次主要讨论缓存。缓存在日常开发中举足轻重,如果你的应用对某类数据有着较高的读取频次,并且改动较小时那就非常适合利用缓存来提高性能。
缓存之所以可以提高性能是因为它的读取效率很高,就像是 CPU 的 L1、L2、L3 缓存一样,级别越高相应的读取速度也会越快。
但也不是什么好处都占,读取速度快了但是它的内存更小资源更宝贵,所以我们应当缓存真正需要的数据。其实也就是典型的空间换时间。下面谈谈 Java 中所用到的缓存。
JVM 缓存
首先是 JVM 缓存,也可以认为是堆缓存。
其实就是创建一些全局变量,如 Map、List 之类的容器用于存放数据。
这样的优势是使用简单但是也有以下问题:
- 只能显式的写入,清除数据。
- 不能按照一定的规则淘汰数据,如
LRU,LFU,FIFO等。 - 清除数据时的回调通知。
- 其他一些定制功能等。
Ehcache、Guava Cache
所以出现了一些专门用作 JVM 缓存的开源工具出现了,如本文提到的 Guava Cache。
它具有上文 JVM 缓存不具有的功能,如自动清除数据、多种清除算法、清除回调等。
但也正因为有了这些功能,这样的缓存必然会多出许多东西需要额外维护,自然也就增加了系统的消耗。
分布式缓存
刚才提到的两种缓存其实都是堆内缓存,只能在单个节点中使用,这样在分布式场景下就招架不住了。
于是也有了一些缓存中间件,如 Redis、Memcached,在分布式环境下可以共享内存。
具体不在本次的讨论范围。
Guava Cache 示例
之所以想到 Guava 的 Cache,也是最近在做一个需求,大体如下:
从 Kafka 实时读取出应用系统的日志信息,该日志信息包含了应用的健康状况。
如果在时间窗口 N 内发生了 X 次异常信息,相应的我就需要作出反馈(报警、记录日志等)。
对此 Guava 的 Cache 就非常适合,我利用了它的 N 个时间内不写入数据时缓存就清空的特点,在每次读取数据时判断异常信息是否大于 X 即可。
伪代码如下:
@Value("${alert.in.time:2}")
private int time ;
@Bean
public LoadingCache buildCache(){
return CacheBuilder.newBuilder()
.expireAfterWrite(time, TimeUnit.MINUTES)
.build(new CacheLoader<Long, AtomicLong>() {
@Override
public AtomicLong load(Long key) throws Exception {
return new AtomicLong(0);
}
});
}
/**
* 判断是否需要报警
*/
public void checkAlert() {
try {
if (counter.get(KEY).incrementAndGet() >= limit) {
LOGGER.info("***********报警***********");
//将缓存清空
counter.get(KEY).getAndSet(0L);
}
} catch (ExecutionException e) {
LOGGER.error("Exception", e);
}
}
首先是构建了 LoadingCache 对象,在 N 分钟内不写入数据时就回收缓存(当通过 Key 获取不到缓存时,默认返回 0)。
然后在每次消费时候调用 checkAlert() 方法进行校验,这样就可以达到上文的需求。
我们来设想下 Guava 它是如何实现过期自动清除数据,并且是可以按照 LRU 这样的方式清除的。
大胆假设下:
内部通过一个队列来维护缓存的顺序,每次访问过的数据移动到队列头部,并且额外开启一个线程来判断数据是否过期,过期就删掉。有点类似于我之前写过的 动手实现一个 LRU cache
胡适说过:大胆假设小心论证
下面来看看 Guava 到底是怎么实现。
原理分析
看原理最好不过是跟代码一步步走了:
示例代码在这里:
 8.png
8.png
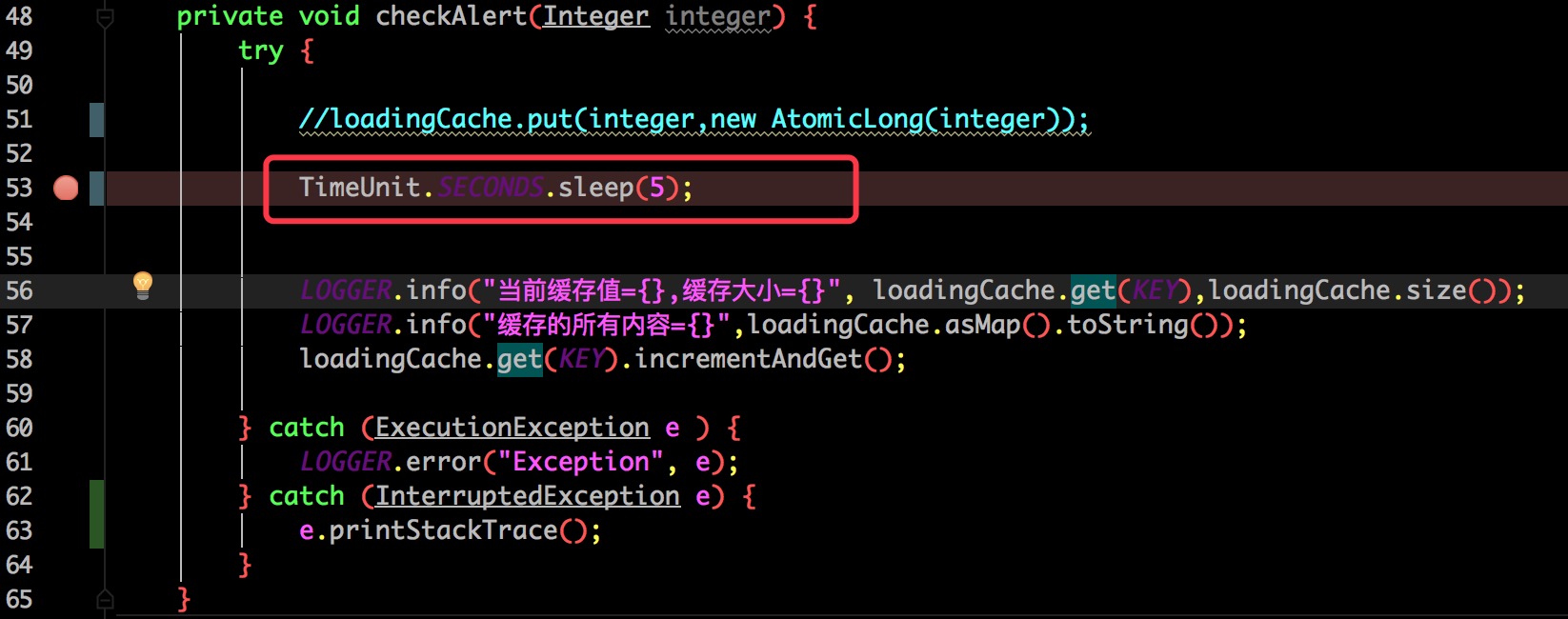
为了能看出 Guava 是怎么删除过期数据的在获取缓存之前休眠了 5 秒钟,达到了超时条件。
 2.png
2.png
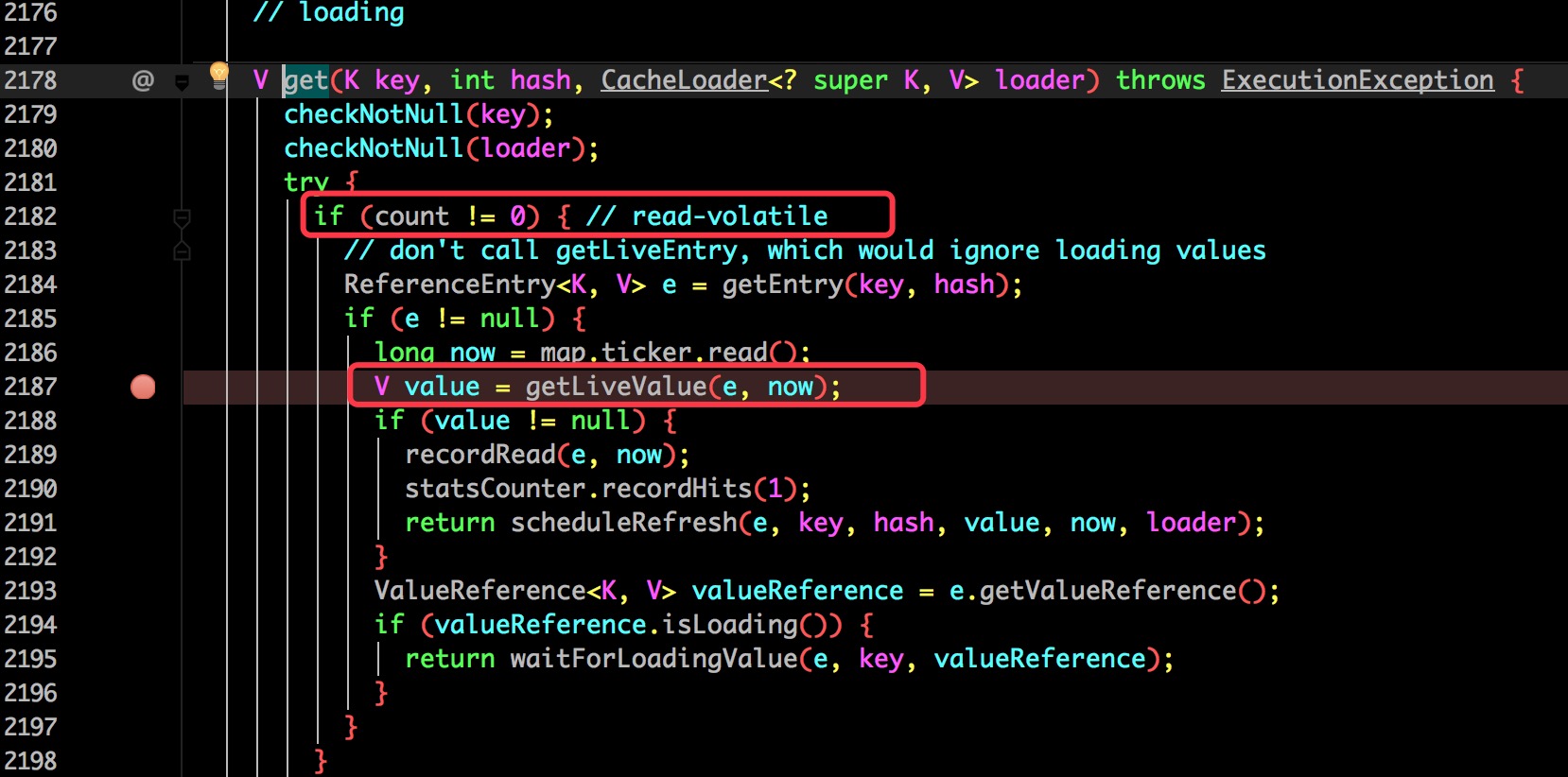
最终会发现在 com.google.common.cache.LocalCache 类的 2187 行比较关键。
再跟进去之前第 2182 行会发现先要判断 count 是否大于 0,这个 count 保存的是当前缓存的数量,并用 volatile 修饰保证了可见性。
更多关于 volatile 的相关信息可以查看 你应该知道的 volatile 关键字
接着往下跟到:
 3.png
3.png
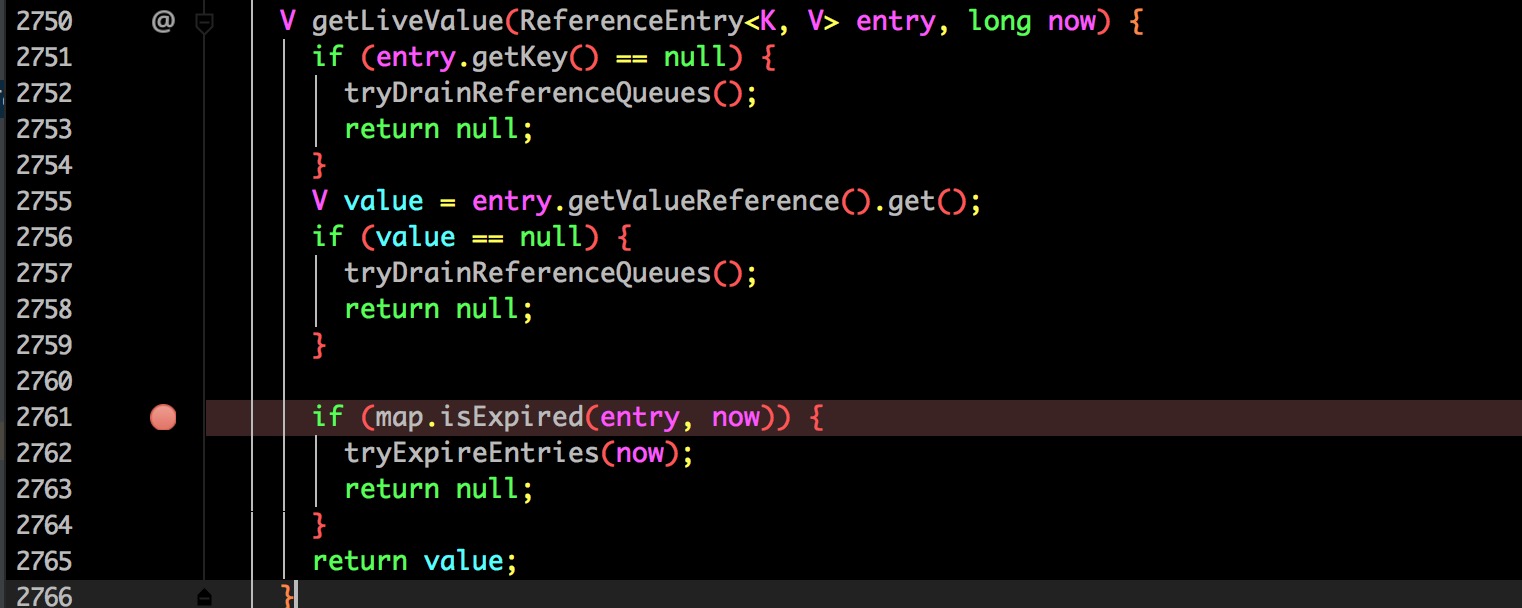
2761 行,根据方法名称可以看出是判断当前的 Entry 是否过期,该 entry 就是通过 key 查询到的。
 4.png
4.png
这里就很明显的看出是根据根据构建时指定的过期方式来判断当前 key 是否过期了。
 5.png
5.png
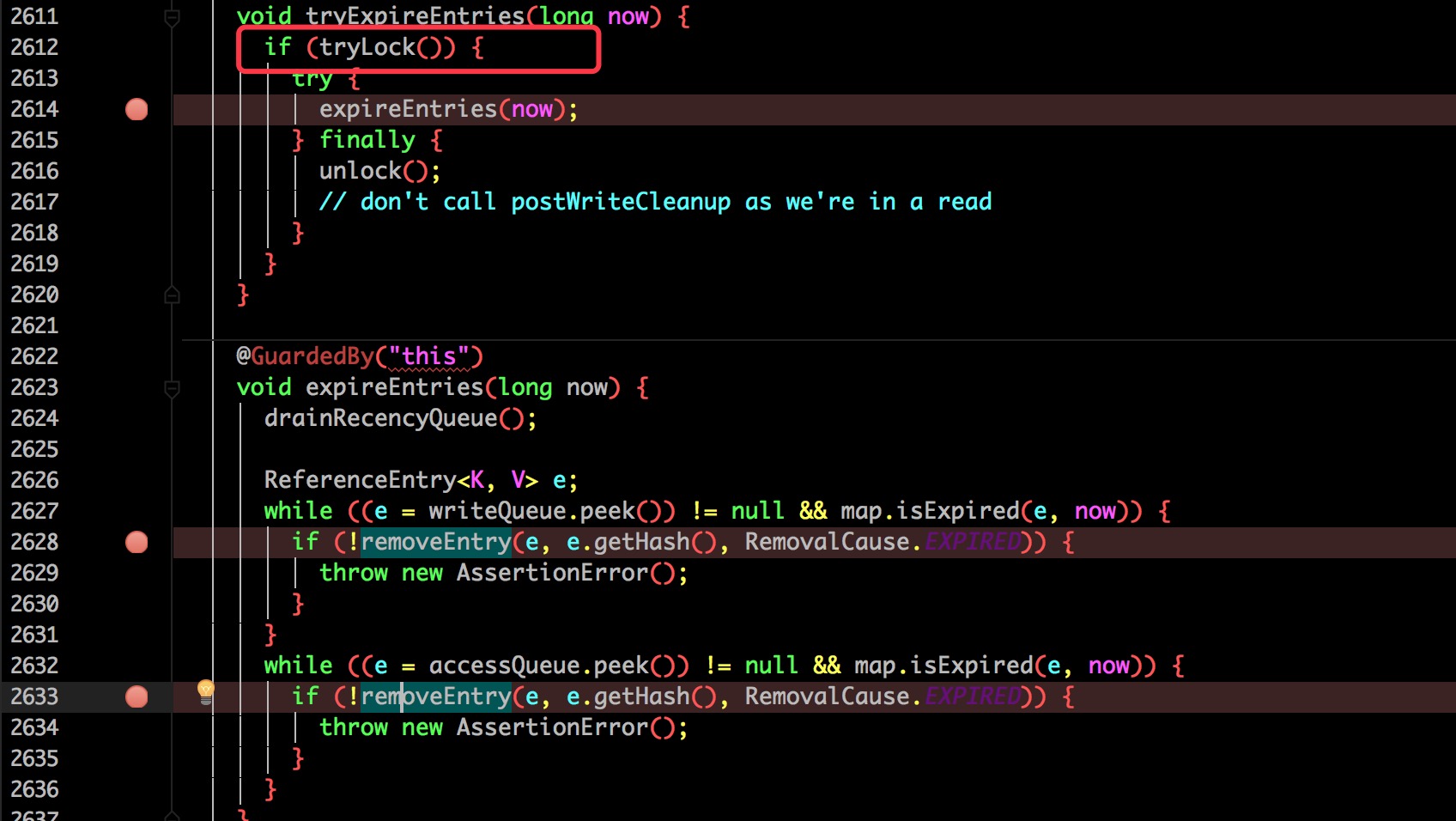
如果过期就往下走,尝试进行过期删除(需要加锁,后面会具体讨论)。
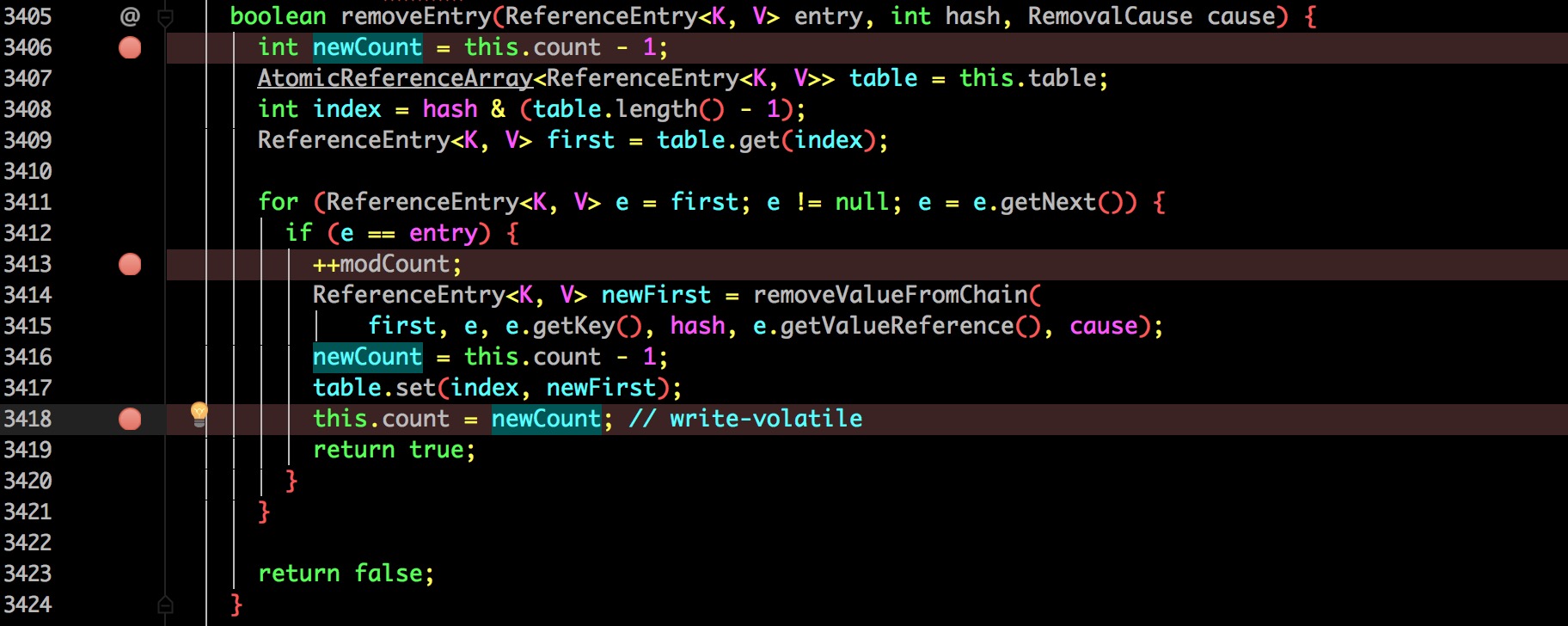 6.png
6.png
到了这里也很清晰了:
- 获取当前缓存的总数量
- 自减一(前面获取了锁,所以线程安全)
- 删除并将更新的总数赋值到 count。
其实大体上就是这个流程,Guava 并没有按照之前猜想的另起一个线程来维护过期数据。
应该是以下原因:
- 新起线程需要资源消耗。
- 维护过期数据还要获取额外的锁,增加了消耗。
而在查询时候顺带做了这些事情,但是如果该缓存迟迟没有访问也会存在数据不能被回收的情况,不过这对于一个高吞吐的应用来说也不是问题。
总结
最后再来总结下 Guava 的 Cache。
其实在上文跟代码时会发现通过一个 key 定位数据时有以下代码:
 7.png
7.png
如果有看过 ConcurrentHashMap 的原理 应该会想到这其实非常类似。
其实 Guava Cache 为了满足并发场景的使用,核心的数据结构就是按照 ConcurrentHashMap 来的,这里也是一个 key 定位到一个具体位置的过程。
先找到 Segment,再找具体的位置,等于是做了两次 Hash 定位。
上文有一个假设是对的,它内部会维护两个队列 accessQueue,writeQueue用于记录缓存顺序,这样才可以按照顺序淘汰数据(类似于利用 LinkedHashMap 来做 LRU 缓存)。
同时从上文的构建方式来看,它也是构建者模式来创建对象的。
因为作为一个给开发者使用的工具,需要有很多的自定义属性,利用构建则模式再合适不过了。
Guava 其实还有很多东西没谈到,比如它利用 GC 来回收内存,移除数据时的回调通知等。之后再接着讨论。
Guava 源码分析之Cache的实现原理的更多相关文章
- Guava 源码分析(Cache 原理 对象引用、事件回调)
前言 在上文「Guava 源码分析(Cache 原理)」中分析了 Guava Cache 的相关原理. 文末提到了回收机制.移除时间通知等内容,许多朋友也挺感兴趣,这次就这两个内容再来分析分析. 在开 ...
- Mybatis源码分析之Cache二级缓存原理 (五)
一:Cache类的介绍 讲解缓存之前我们需要先了解一下Cache接口以及实现MyBatis定义了一个org.apache.ibatis.cache.Cache接口作为其Cache提供者的SPI(Ser ...
- Mybatis源码分析之Cache一级缓存原理(四)
之前的文章我已经基本讲解到了SqlSessionFactory.SqlSession.Excutor以及Mpper执行SQL过程,下面我来了解下myabtis的缓存, 它的缓存分为一级缓存和二级缓存, ...
- Guava 源码分析(Cache 原理)
前言 Google 出的 Guava 是 Java 核心增强的库,应用非常广泛. 我平时用的也挺频繁,这次就借助日常使用的 Cache 组件来看看 Google 大牛们是如何设计的. 缓存 本次主要讨 ...
- 并发编程学习笔记(9)----AQS的共享模式源码分析及CountDownLatch使用及原理
1. AQS共享模式 前面已经说过了AQS的原理及独享模式的源码分析,今天就来学习共享模式下的AQS的几个接口的源码. 首先还是从顶级接口acquireShared()方法入手: public fin ...
- 从SpringBoot源码分析 配置文件的加载原理和优先级
本文从SpringBoot源码分析 配置文件的加载原理和配置文件的优先级 跟入源码之前,先提一个问题: SpringBoot 既可以加载指定目录下的配置文件获取配置项,也可以通过启动参数( ...
- 第九篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 cache table
/** Spark SQL源码分析系列文章*/ Spark SQL 可以将数据缓存到内存中,我们可以见到的通过调用cache table tableName即可将一张表缓存到内存中,来极大的提高查询效 ...
- [Guava源码分析]ImmutableCollection:不可变集合
摘要: 我的技术博客经常被流氓网站恶意爬取转载.请移步原文:http://www.cnblogs.com/hamhog/p/3888557.html,享受整齐的排版.有效的链接.正确的代码缩进.更好的 ...
- [Guava源码分析]Ordering:排序
我的技术博客经常被流氓网站恶意爬取转载.请移步原文:http://www.cnblogs.com/hamhog/p/3876466.html,享受整齐的排版.有效的链接.正确的代码缩进.更好的阅读体验 ...
随机推荐
- 使用linq对ado.net查询出来dataset集合转换成对象(查询出来的数据结构为一对多)
public async Task<IEnumerable<QuestionAllInfo>> GetAllQuestionByTypeIdAsync(int id) { st ...
- python每日经典算法题5(基础题)+1(较难题)
一:基础算法题5道 1.阿姆斯特朗数 如果一个n位正整数等于其各位数字的n次方之和,则称该数为阿姆斯特朗数.判断用户输入的数字是否为阿姆斯特朗数. (1)题目分析:这里要先得到该数是多少位的,然后再把 ...
- Python多任务—进程
一.进程以及状态 1.进程 正在运行的应用程序就是一个进程.进程是资源分配的基本单元. Python多进程可以在多核CPU上运行,多进程充分利用了多核的资源. 2. 进程的状态 工作中,任务数往往大于 ...
- 深浅赋值+orm操作+Django-admin简单配置
知识点 深浅copy 浅值深id orm操作 ManyToManyField 虚拟字段 告诉Django orm 自动帮你创建第三张表 查询的时候可以借助该字段跨表 外键属性可赋值外联对象 Model ...
- sqlserver 远程链接
远程链接的文档就不说了,网上好多. 这里就说下我遇到的情况,如果是阿里云的服务器的话,他的端口配置都是要到阿里云里的安全组里去配置的,第一次一直没想到,搞了一天才发现,在这里提醒各位好友.
- 【开发笔记】- MySQL中limit查询超级慢,怎么办?
有如下解决方法: (1).通过判断id的范围来分页 limit ; 也得到了分页的数据,但是我们发现如果id不是顺序的,也就是如果有数据删除过的话,那么这样分页数据就会不正确,这个是有缺陷的. (2) ...
- CSS 总结 [目录]
一.CSS 基础 1.CSS 初识 2.CSS 用法和特性 二.CSS 选择器 1.基本选择器 2.组合选择器 3.属性选择器 4.伪类选择器 5.伪元素选择器 三.CSS 字体样式 四.CSS 文本 ...
- Java生成前三位是字母循环的字典
title: Java生成前三位是字母循环的字典 date: 2018-08-17 18:52:22 tags: Java --- 最近要破解一个秘密,还好这个密码是有线索的,已知密码的前三位是三个字 ...
- Spring Boot 2 整合 Dubbo 框架 ,实现 RPC 服务远程调用
一.Dubbo框架简介 1.框架依赖 图例说明: 1)图中小方块 Protocol, Cluster, Proxy, Service, Container, Registry, Monitor 代 ...
- passwd修改密码失败,报鉴定令牌操作错误
出现这个情况,从四个方面来分析: 1./usr/bin/passwd 的权限中没有添加s即SUID特殊权限 即:-rwxr-xr-x. 1 root root 27000 8月 22 2010 /u ...