2. 执行Spark SQL查询
2.1 命令行查询流程
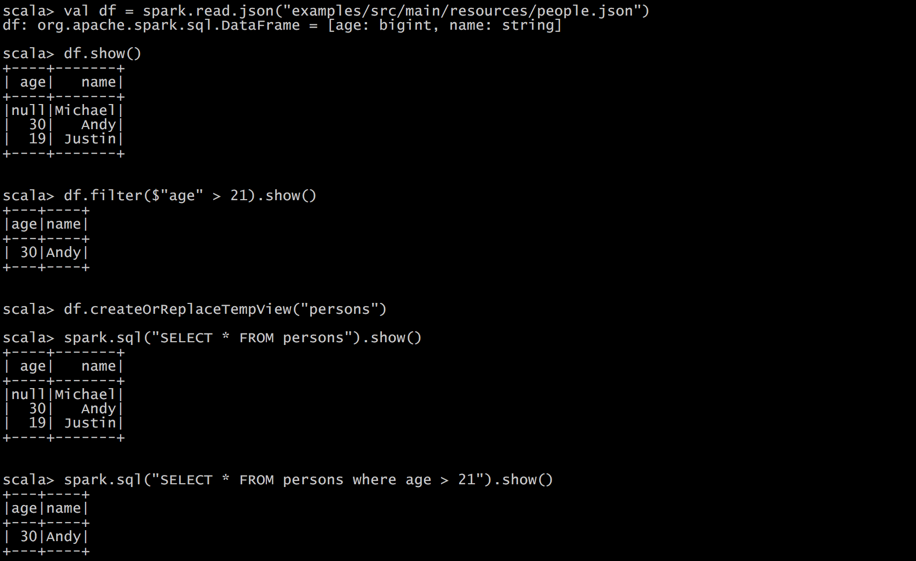
打开Spark shell
例子:查询大于21岁的用户
创建如下JSON文件,注意JSON的格式:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
2.2 IDEA创建Spark SQL程序
IDEA中程序的打包和运行方式都和SparkCore类似,Maven依赖中需要添加新的依赖项:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
程序如下:
package com.c.sparksql
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
/**
* Created by huicheng on 15/07/2019.
*/
object HelloWorld { val logger = LoggerFactory.getLogger(HelloWorld.getClass)
def main(args: Array[String]) {
//创建 SparkConf()并设置App名称
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
val df = spark.read.json("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
df.show()
df.filter($"age" > 21).show()
df.createOrReplaceTempView("persons")
spark.sql("SELECT * FROM persons where age > 21").show()
spark.stop()
}
}
2. 执行Spark SQL查询的更多相关文章
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- SQL Server-聚焦sp_executesql执行动态SQL查询性能真的比exec好?
前言 之前我们已经讨论过动态SQL查询呢?这里为何再来探讨一番呢?因为其中还是存在一定问题,如标题所言,很多面试题也好或者有些博客也好都在说在执行动态SQL查询时sp_executesql的性能比ex ...
- Django文档阅读之执行原始SQL查询
Django提供了两种执行原始SQL查询的方法:可以使用Manager.raw()来执行原始查询并返回模型实例,或者可以完全避免模型层直接执行自定义SQL. 每次编写原始SQL时都要关注防止SQL注入 ...
- 在sql server中怎样获得正在执行的Sql查询
方法1:使用DBCC inputbuffer(spid) 使用SP_WHO获得SPID,然后再执行上面的DBCC command,参见下图 执行一段sql语句 打开另一个query窗口并执行SP_WH ...
- spark sql 查询hive表并写入到PG中
import java.sql.DriverManager import java.util.Properties import com.zhaopin.tools.{DateUtils, TextU ...
- Databricks 第11篇:Spark SQL 查询(行转列、列转行、Lateral View、排序)
本文分享在Azure Databricks中如何实现行转列和列转行. 一,行转列 在分组中,把每个分组中的某一列的数据连接在一起: collect_list:把一个分组中的列合成为数组,数据不去重,格 ...
- Spark SQL基本概念与基本用法
1. Spark SQL概述 1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了两个编程抽象分别叫做DataFrame和DataSet,它们用于作为 ...
- 自适应查询执行:在运行时提升Spark SQL执行性能
前言 Catalyst是Spark SQL核心优化器,早期主要基于规则的优化器RBO,后期又引入基于代价进行优化的CBO.但是在这些版本中,Spark SQL执行计划一旦确定就不会改变.由于缺乏或者不 ...
- C# EF使用SqlQuery直接操作SQL查询语句或者执行过程
Entity Framework是微软出品的高级ORM框架,大多数.NET开发者对这个ORM框架应该不会陌生.本文主要罗列在.NET(ASP.NET/WINFORM)应用程序开发中使用Entity F ...
随机推荐
- 手工部署yugabyte的几点说明
ntp 时间同步 ntp 时间同步对于yugabyte 是一个比较重要的服务,需要注意时间的同步 YB-Master 个数的说明 原则 YB-Master 的个数,必须和复制因子的个数一样,同时mas ...
- 微信小程序音乐播放器组件
wxml <image bindtap="click" src="{{isPlay?'/images/':'/images/'}}"/> JS Pa ...
- 2019 SDN第三次上机作业
作业要求: 利用Mininet仿真平台构建给定的网络拓扑,配置主机h1和h2的IP地址(h1:10.0.0.1,h2:10.0.0.2),测试两台主机之间的网络连通性: 利用Wireshark工具,捕 ...
- 作业:分布式文件系统HDFS 练习
这个作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3292. 利用Shell命令与HDFS进行交互 1.目录操作 H ...
- Unity创作赛车游戏的四款插件
本文,我们将介绍其中4款:Racing Game Starter Kit.GeNa 2 .NWH Vehicle Physics.Curvy Splines. Racing Game Starter ...
- Spring Boot方式的Dubbo项目
项目依赖 需要org.apache.dubbo.dubbo-dependencies-bom, 需要org.apache.dubbo.dubbo-spring-boot-starter, 当前版本有2 ...
- auto-sklearn
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003&u ...
- 修改LINUX 默认的22端口
Linux远程端口修改操作手册 一.修改端口前需要检查selinux状态,并把selinux永久关闭 关闭方法: 1. 执行setenforce 0 2. vi /etc/selinux/confi ...
- PHP用curl抓取网站数据,仿造IP、伪造来源等,防屏蔽解决方案教程
1.伪造客户端IP地址,伪造访问referer:(一般情况下这就可以访问到数据了) curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:1 ...
- Laya的滚动容器
想实现一个简单的滚动容器.例如水平排列10个图标,可以左右滑动查看的. Egret里有布局容器可以滚动 Laya看了教程和示例,没有找到一个滚动容器,只有一个list,需要设置item,显然不是我想要 ...