python爬虫(5)——BeautifulSoup & docker基础
BeautifulSoup基础实战
安装:pip install beautifulsoup4
常用指令:
from bs4 import BeautifulSoup as bs
import urllib.request
data=urllib.request.urlopen("https://www.cnblogs.com/mcq1999/").read().decode("utf-8","ignore")
bs1=bs(data)
print(bs1.prettify()) #格式化输出
print(bs1.title) #获取标签title,bs对象.标签名
print(bs1.title.string) #获取标签title的文字
print(bs1.title.name) #获取标签名,如title
print(bs1.a.attrs) #获取属性列表 键值对
print(bs1.a['name']) #获取某个属性对应的值
print(bs1.find_all('a')) #提取所有某个节点的内容,传参是标签名
print('---------------------------------')
print(bs1.find_all(['a','ul']))
k1=bs1.ul.contents #提取当前节点的所有子节点,返回一个列表
k2=bs1.ul.children #返回一个生成器
allulc=[i for i in k2]
PhantomJS基础实战
效率不高,但可以解决很多反爬问题,本质是一个无界面的浏览器,通过命令行(或python)操纵。通常难点部分通过PhantomJS写,然后将数据交给urllib或scrapy进行后续处理。
目前已PhantomJS和selenium分手,以后再学。
分布式爬虫之docker基础
镜像:不可以改变内容
容器:可以改变内容,相当于虚拟机,默认情况下彼此封闭
优点:轻部署、省成本、部署迁移方便
安装:yum -y install docker
启动和关闭:
systemctl start docker
systemctl stop docker
启动时如果出现
可以参考下面这篇博客,我的就这样成功了,其他的方法都没用
https://blog.csdn.net/w1316022737/article/details/83692701
最好再修改一下docker的镜像源,不然运行的很慢:
https://blog.csdn.net/julien71/article/details/79760919
查看已有镜像:docker images
下载镜像:docker pull
创建容器:docker run -tid
查看容器:docker ps -a
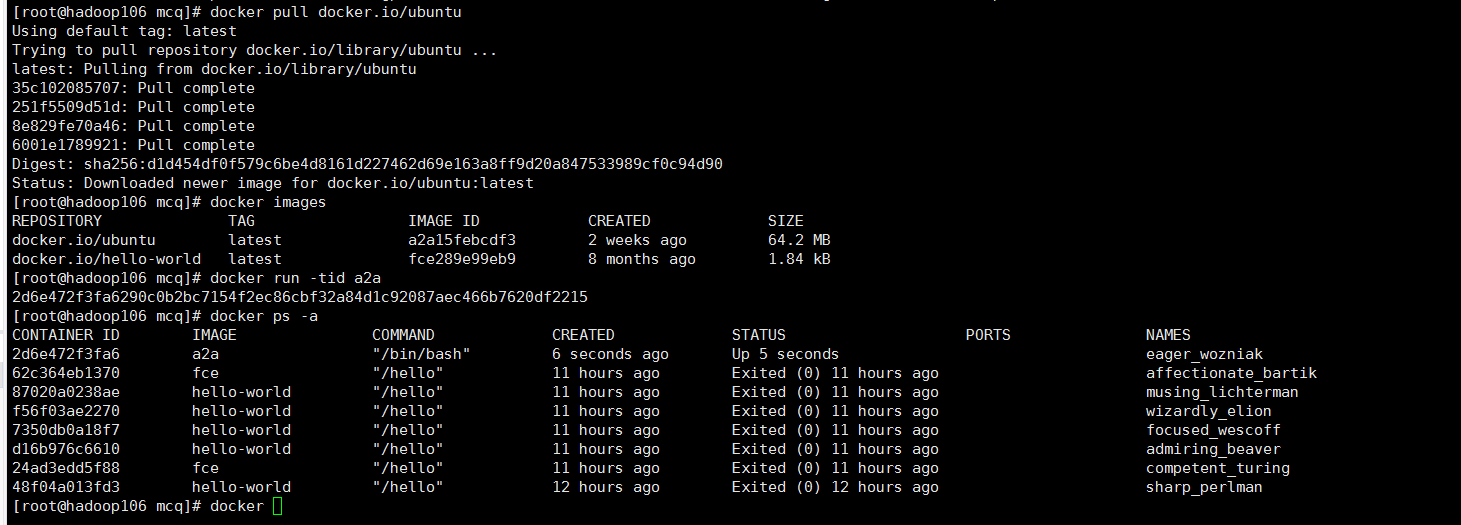
进入容器:docker attach
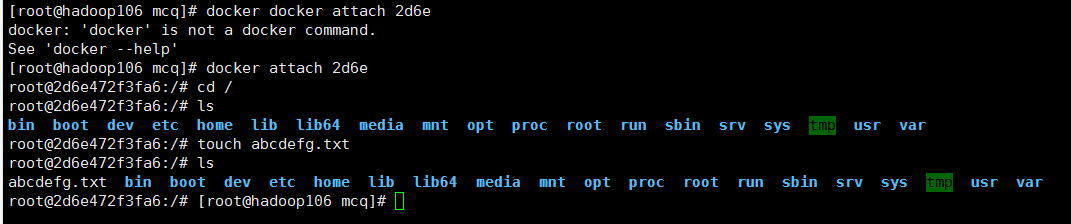
退出容器:一般不用exit,因为会停止容器。我们用ctrl+p+q即可。
在容器里的操作不会影响本机,相当于在虚拟机里再开了个虚拟机
启动容器:docker start …
封装容器成镜像:docker commit 2d6 mytest:v1

基于镜像给容器起名字: docker run -tid --name testabc a2a (基于a2a这个镜像创建一个名为testabs的容器)
docker run -tid --name h1 mytest:v1
docker run -tid --name h2 --link h1 mytest:v1 (将容器h2链接到h1,即让h2和h1通信)
这里我用ubuntu的镜像发现ping、yum等等命令都没有,所以改用了centos的镜像。
[root@hadoop106 mcq]# docker attach fe3
[root@fe3489945006 /]# cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.17.0.6 c1 4c3dab0e013c
172.17.0.7 fe3489945006
[root@fe3489945006 /]# ping 172.17.0.6
将docker镜像封装为文件:docker save -o /mytest.tar c3e8
python爬虫(5)——BeautifulSoup & docker基础的更多相关文章
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- python爬虫之Beautiful Soup基础知识+实例
python爬虫之Beautiful Soup基础知识 Beautiful Soup是一个可以从HTML或XML文件中提取数据的python库.它能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档 ...
- Python爬虫入门有哪些基础知识点
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫之BeautifulSoup的用法
之前看静觅博客,关于BeautifulSoup的用法不太熟练,所以趁机在网上搜索相关的视频,其中一个讲的还是挺清楚的:python爬虫小白入门之BeautifulSoup库,有空做了一下笔记: 一.爬 ...
- Python爬虫——用BeautifulSoup、python-docx爬取廖雪峰大大的教程为word文档
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 廖雪峰大大贡献的教程写的不错,写了个爬虫把教程保存为word文件,供大家方便下载学习:http://p ...
- 【Python爬虫】BeautifulSoup网页解析库
BeautifulSoup 网页解析库 阅读目录 初识Beautiful Soup Beautiful Soup库的4种解析器 Beautiful Soup类的基本元素 基本使用 标签选择器 节点操作 ...
- Python爬虫系列-BeautifulSoup详解
安装 pip3 install beautifulsoup4 解析库 解析器 使用方法 优势 劣势 Python标准库 BeautifulSoup(markup,'html,parser') Pyth ...
- Python爬虫之Beautifulsoup模块的使用
一 Beautifulsoup模块介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Be ...
- Python 爬虫—— requests BeautifulSoup
本文记录下用来爬虫主要使用的两个库.第一个是requests,用这个库能很方便的下载网页,不用标准库里面各种urllib:第二个BeautifulSoup用来解析网页,不然自己用正则的话很烦. req ...
随机推荐
- JAVA SE学习路径
- Tensorflow之MNIST手写数字识别:分类问题(2)
整体代码: #数据读取 import tensorflow as tf import matplotlib.pyplot as plt import numpy as np from tensorfl ...
- cidr地址段
CIDR采用各种长度的"网络前缀"来代替分类地址中的网络号和子网号,其格式为:IP地址 = {<网络前缀>,<主机号>}.为了区分网络前缀,通常采用&quo ...
- BASIC合集
握手包 给你握手包,flag是Flag_is_here这个AP的密码,自己看着办吧. 提交格式:flag{WIFI密码} 破解wifi密码 丢到kali,用aircrack-ng kali有一个包含常 ...
- SpringCloud微服务常见组件理解
概述 毫无疑问,Spring Cloud是目前微服务架构领域的翘楚,无数的书籍博客都在讲解这个技术.不过大多数讲解还停留在对Spring Cloud功能使用的层面,其底层的很多原理,很多人可能并不知晓 ...
- node爬虫之图片下载
背景:针对一些想换头像的玩家,而又不知道用什么头像的,作为一名代码爱好者,能用程序解决的,就不用程序来换头像,说干就干,然后就整理了一下. 效果图 环境配置 安装node环境 node -v node ...
- LeetCode 160: 相交链表 Intersection of Two Linked Lists
爱写Bug(ID:iCodeBugs) 编写一个程序,找到两个单链表相交的起始节点. Write a program to find the node at which the intersectio ...
- vue开发 element的select下拉框设定初值后,不能重新选择的问题
问题描述: 用的element的select可多选的下拉选框,在回显后有初始值的情况下,不能修改,也不能再选择 如图,明明点击了一般内勤主管,但没有任何反应 <el-select v-model ...
- python asyncio as_completed
#asyncio 没有提供http协议的接口 aiohttp import asyncio import socket from urllib.parse import urlparse async ...
- [新概念英语] Lesson 12 : GOODBYE AND GOOD LUCK
Lesson 12 : GOODBYE AND GOOD LUCK New words and expressions : luck (n) 运气 例句 You're not having much ...