将博客转成pdf
前些天无意间看到了“birdben”的博客,写的比较详细,但是最新的文章更新时间是“2017-05-07”,时间很是久远,本打算有时间认真学习一下博主所写的文章,但是担心网站会因为某些原因停止服务,于是想到将博主写的所有文章爬下来保存成pdf,说干就干!
你们可以点击这里,查看博主的网站。
一、使用到的模块
pdfkit:可以将文本、html、url转成pdf,但是需要安装wkhtmltopdf.exe,并获取它的安装路径
pdfkit是基于wkhtmltopdf的python封装,支持url,本地文件,文本内容转成pdf,最终还是调用wkhtmltopdf的命令
PyPDF2:处理pdf的模块,可读可写可合并
二、思路分析
1、博客url分析
主页url:https://birdben.github.io/
第二页url:https://birdben.github.io/page/2/
最后一页url:https://birdben.github.io/page/14/
某篇文章的url:

查看主页的html
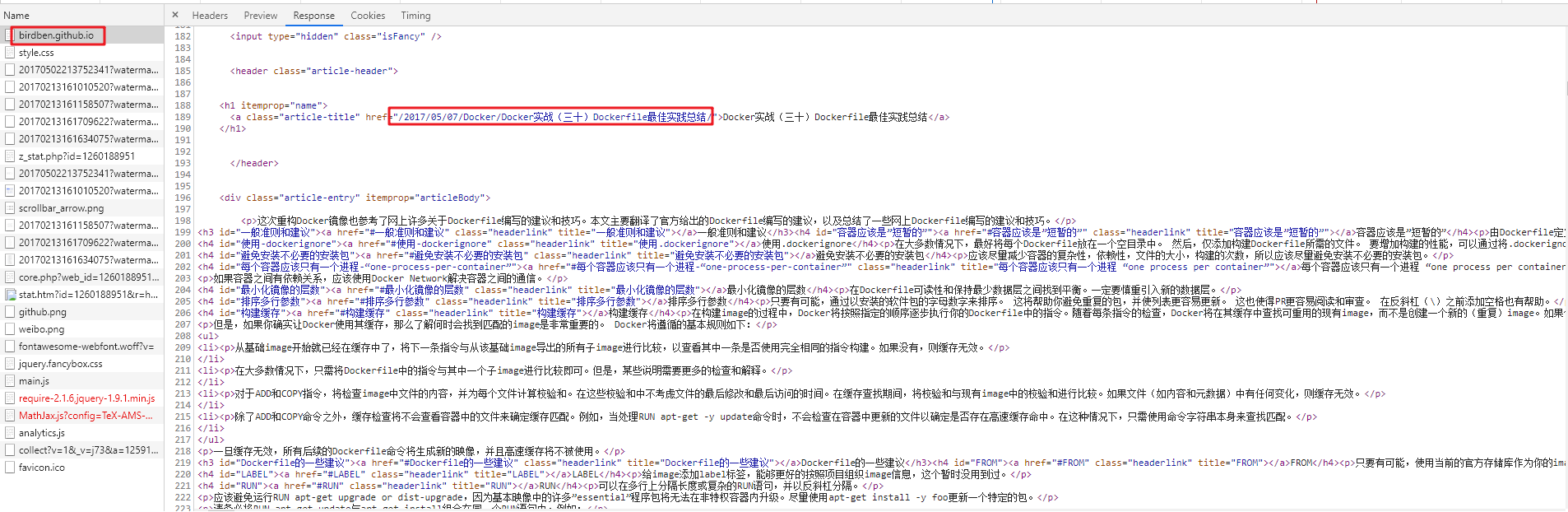
可以看出:该博客网站共有15个主页面,每篇文章的url可以使用 “主页url” + “href” (见上图)
2、整体思路
- 生成所有页面的url列表
- 遍历每个页面的url,在html中匹配出每个文章的href,拼接成每个文章的url
- 利用url生成pdf
- 合并pdf
三、代码过程
1、博客网站共有15个页面,生成这15个页面的url
def geturl():
url = "https://birdben.github.io/archives/"
list = [url]
for i in range(2,15):
str = "%spage/%d/" % (url,i)
list.append(str)
return list
返回的结果:

2、根据已经获得的页面url,读取url,查看html,匹配符合要求的href
def getname(url,):
r = requests.get ( url )
str = "".join(r.text)
pattern = re.compile(r'<a class="archive-article-title" href="(.*)">.*?</a>')
match = pattern.findall(str)
r.close()
return match
结果:

3、拼接url,生成每个文章的url,利用url转成pdf
4、合并pdf
四、最终代码
import requests
import re
import pdfkit
from PyPDF2 import PdfFileReader, PdfFileMerger
import os #获取一个页面所有的 文章全称 用于构建每篇文章的url路径
def getname(url,):
r = requests.get ( url )
str = "".join(r.text)
pattern = re.compile(r'<a class="archive-article-title" href="(.*)">.*?</a>')
match = pattern.findall(str)
r.close()
return match #获取他的所有页面,每个页面会有很多文章
def geturl():
url = "https://birdben.github.io/archives/"
list = [url]
for i in range(2,15):
str = "%spage/%d/" % (url,i)
list.append(str)
return list #将url转换成pdf
def savepdf(url,pdfname):
path_wkthmltopdf = r"C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe"
config = pdfkit.configuration ( wkhtmltopdf=path_wkthmltopdf )
pdfkit.from_url ( url , pdfname , configuration=config ) #爬取所有文章转成pdf
def do():
urllist = geturl()
for url in urllist:
namelist = getname(url)
for blog in namelist:
blogurl = "https://birdben.github.io" + blog
pdfname = r"pdf\%s.pdf" % blog.strip("/").split("/")[-1] #将pdf保存到当前目录下的pdf目录下,需提前创建
print(blogurl,pdfname)
savepdf(blogurl,pdfname) #合并pdf
def mergepdf(tmpdir,mergename): #合并文件存放的路径,合并后的pdf文件名
merger = PdfFileMerger()
listfile = [os.path.join(tmpdir, file) for file in os.listdir(tmpdir)]
for file in listfile:
if file.endswith('.pdf'):
filemsg = PdfFileReader(open(file, 'rb'))
label = file.split('\\')[-1].replace(".pdf", "")
merger.append (filemsg, bookmark=label , import_bookmarks=False)
merger.write(mergename)
merger.close()
以上代码是使用到的所有函数
执行:
if __name__ == '__main__':
do()
#mergepdf("merge",r"merge\docker.pdf") 当do函数执行完后,将需要合并的pdf放到merge目录下(提前创建),再将do注释,再执行mergepdf函数即可
爬取所有文章生成pdf,将生成的pdf放在pdf目录下,需提前创建
将每部分pdf拷贝到另外目录merge下
最终的pdf:

将博客转成pdf的更多相关文章
- 我是如何将博客转成PDF的
前言 只有光头才能变强 之前有读者问过我:"3y你的博客有没有电子版的呀?我想要份电子版的".我说:"没有啊,我没有弄过电子版的,我这边有个文章导航页面,你可以去文章导航 ...
- 将Medium中的博客导出成markdown
Medium(https://medium.com)(需要翻墙访问)是国外非常知名的一个博客平台.上面经常有很多知名的技术大牛在上面发布博客,现在一般国内的搬运的技术文章大多数都是来自于这个平台. M ...
- 爬取王垠的博客并生成pdf
尚未完善,有待改进 #!/usr/bin/env python3 # -*- coding: utf-8 -*- __author__ = 'jiangwenwen' import pdfkit im ...
- ahk打印成pdf记录
软工课程后记: 要求将博客打印成pdf存档.为了偷懒,不想自己点鼠标一个个保存,所以写了一个ahk小程序.博客教程推荐,建议一试,不难.还很方便.我也只学了点点皮毛,满足需求即止. 第一个成功的小例子 ...
- 推荐一款自己的软件作品[豆约翰博客备份专家],新浪博客,QQ空间,CSDN,cnblogs博客备份,导出CHM,PDF(转载)
推荐一款自己的软件作品[豆约翰博客备份专 豆约翰博客备份专家是完全免费,功能强大的博客备份工具,博客电子书(PDF,CHM和TXT)生成工具,博文离线浏览工具,软件界面美观大方,支持多个主流博客网站( ...
- MarkWord - 可发布博客的 Markdown编辑器 代码开源
因为前一段时间看到 NetAnalyzer 在Windows10系统下UI表现惨不忍睹,所以利用一段时间为了学习一下WPF相关的内容,于是停停写写,用了WPF相关的技术,两个星期做了一个Markdow ...
- 利用hexo+github+nodejs搭建自我博客的一天
放一张比较喜欢的背景图镇楼,伪文艺一波.因为刚刚抱着四个快递从公司大门走到宿舍,快递都比我高,坐电梯的时候电梯里面的灯一闪一闪,电梯还摇晃,上演了一波鬼吹灯,惊魂未定... 说正题:我喜欢的博客应该是 ...
- 基于 Hexo + GitHub Pages 搭建个人博客(二)
在 基于 Hexo + GitHub Pages 搭建个人博客(一) 这篇文章中,我们已经知道如何使用 Hexo + GitHub Pages 搭建一个个人博客,GitHub 为我们提供了免费的域名和 ...
- 历时25天,我的博客(www.ityouknow.com)终于又活了过来
时间回到2016年的7月10号,那时候我刚刚开始正式在博客园写博客,博客园的交流氛围很好,但鉴于博客园古老的界面,同时计划创建一个自己独立的博客,毕竟自己的博客怎么折腾都行. 那时候正在研究 Spri ...
随机推荐
- MVC 自己创建URL 对象处理路径
var url = new UrlHelper(filterContext.RequestContext); var url = new UrlHelper(HttpContext.Current.R ...
- python2和python3共存方法
拿到安装包,安装python3 centos: sudo yum install python36 ubuntu: sudo add-apt-repository ppa:deadsnakes/ppa ...
- Vue的单选/多选效果
includes()方法判断是否包含某一元素,返回true或false表示是否包含元素,对NaN一样有效 filter()方法用于把Array的某些元素过滤掉,filter()把传入的函数依次作用于每 ...
- 动态规划-多维DP
1.最大正方形 我的瞎猜分析: 我的瞎猜算法: #include <stdio.h> #include <memory.h> #include <math.h> # ...
- div模拟textarea且高度自适应
需求 我们知道文本超出 textarea 高度后,textarea 就会出现滚动条,需求就是让 textarea 高度跟随文本高度变化,屏蔽滚动条,原来做过用js去监听文本行数,然后改变文本框的高度, ...
- SHOI做题记录
LOJ #2027. 「SHOI2016」黑暗前的幻想乡 考虑到每个公司一条边,那就等价于没有任何一家公司没有边. 然后就可以容斥+矩阵树定理,没了. LOJ #2028. 「SHOI2016」随机序 ...
- JavaScript base64 加密解密
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 转载:关于思科交换机、路由器如何关闭telnet 开启ssh服务
等保测评要求: 必须关闭telnet服务,开启ssh服务 即用ssh方式登录网络设备,而不允许用telnet. 输入密码.en 再次输入密码.sh run 这些常规动作就不再赘述. 1.关闭telne ...
- 每天一个命令-cp 命令
cp命令用来将一个或多个源文件或者目录复制到指定的目的文件或目录.它可以将单个源文件复制成一个指定文件名的具体的文件或一个已经存在的目录下.cp命令还支持同时复制多个文件,当一次复制多个文件时,目标文 ...
- 使用analyze命令统计信息
① 搜集和删除索引.表和簇的统计信息② 验证表.索引和簇的结构③ 鉴定表和簇和行迁移和行链接针对analyze的搜集和删除统计信息功能而言Oracle推荐使用DBMS_STATS包来代替analyze ...