DevOps-ISC,CSS,Prometheus,Ansible ,Terraform,zabbix
Terraform
Use Infrastructure as Code to provision and manage any cloud, infrastructure, or service
Terraform:简介
在 DevOps 实践中,基础设施即代码如何落地是一个绕不开的话题。像 Chef,Puppet 等成熟的配置管理工具,都能够满足一定程度的需求,但有没有更友好的工具能够满足我们绝大多数的需求?笔者认为 Terraform 是一个很有潜力的工具,目前各大云平台也都支持的不错,尤其是使用起来简单明了。本文会简单的介绍一下 Terraform 相关的概念,然后通过一个小 demo 带大家一起进入 Terraform 的世界。说明:本文的演示环境为 ubuntu 16.04。
Terraform 是什么?
Terraform 是一种安全有效地构建、更改和版本控制基础设施的工具(基础架构自动化的编排工具)。它的目标是 "Write, Plan, and create Infrastructure as Code", 基础架构即代码。Terraform 几乎可以支持所有市面上能见到的云服务。具体的说就是可以用代码来管理维护 IT 资源,把之前需要手动操作的一部分任务通过程序来自动化的完成,这样的做的结果非常明显:高效、不易出错。

Terraform 提供了对资源和提供者的灵活抽象。该模型允许表示从物理硬件、虚拟机和容器到电子邮件和 DNS 提供者的所有内容。由于这种灵活性,Terraform 可以用来解决许多不同的问题。这意味着有许多现有的工具与Terraform 的功能重叠。但是需要注意的是,Terraform 与其他系统并不相互排斥。它可以用于管理小到单个应用程序或达到整个数据中心的不同对象。
Terraform 使用配置文件描述管理的组件(小到单个应用程序,达到整个数据中心)。Terraform 生成一个执行计划,描述它将做什么来达到所需的状态,然后执行它来构建所描述的基础结构。随着配置的变化,Terraform 能够确定发生了什么变化,并创建可应用的增量执行计划。
Terraform 是用 Go 语言开发的开源项目,你可以在 github 上访问到它的源代码。
Terraform 核心功能
- 基础架构即代码(Infrastructure as Code)
- 执行计划(Execution Plans)
- 资源图(Resource Graph)
- 自动化变更(Change Automation)
基础架构即代码(Infrastructure as Code)
使用高级配置语法来描述基础架构,这样就可以对数据中心的蓝图进行版本控制,就像对待其他代码一样对待它。
执行计划(Execution Plans)
Terraform 有一个 plan 步骤,它生成一个执行计划。执行计划显示了当执行 apply 命令时 Terraform 将做什么。通过 plan 进行提前检查,可以使 Terraform 操作真正的基础结构时避免意外。
资源图(Resource Graph)
Terraform 构建的所有资源的图表,它能够并行地创建和修改任何没有相互依赖的资源。因此,Terraform 可以高效地构建基础设施,操作人员也可以通过图表深入地解其基础设施中的依赖关系。
自动化变更(Change Automation)
把复杂的变更集应用到基础设施中,而无需人工交互。通过前面提到的执行计划和资源图,我们可以确切地知道 Terraform 将会改变什么,以什么顺序改变,从而避免许多可能的人为错误。
安装 Terraform
Terraform 的安装非常简单,直接把官方提供的二进制可执行文件保存到本地就可以了。比如笔者习惯性的把它保存到 /usr/local/bin/ 目录下,当然这个目录会被添加到 PATH 环境变量中。完成后检查一下版本号:

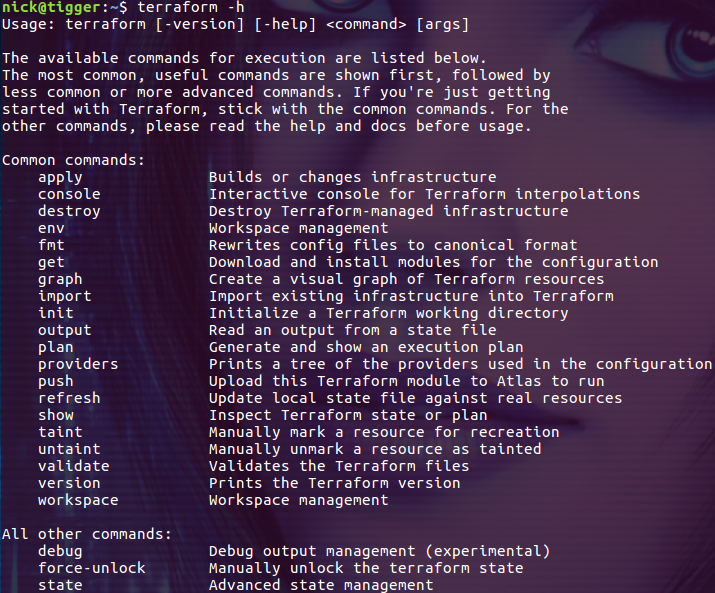
通过 -h 选项我们可以看到 terraform 支持的所有命令:
在 Azure 上创建一个 Resource Group
要让 Terraform 访问 Azure 订阅中的资源,需要先创建 Azure service principal,Azure service principa 允许你的 Terraform 脚本在 Azure 订阅中配置资源。请参考这里创建 Azure service principal。
配置 Terraform 环境变量
若要配置 Terraform 使用 Azure service principal,需要设置以下环境变量:
- ARM_SUBSCRIPTION_ID
- ARM_CLIENT_ID
- ARM_CLIENT_SECRET
- ARM_TENANT_ID
- ARM_ENVIRONMENT
这些环境变量的值都可以从前面创建 Azure service principal 的过程中获得。方便起见,我们把设置这些环境变量的步骤可以写到脚本文件 azureEnv.sh 中:

#!/bin/sh
echo "Setting environment variables for Terraform"
export ARM_SUBSCRIPTION_ID=your_subscription_id
export ARM_CLIENT_ID=your_appId
export ARM_CLIENT_SECRET=your_password
export ARM_TENANT_ID=your_tenant_id
# Not needed for public, required for usgovernment, german, china
export ARM_ENVIRONMENT=public
这样在执行 Terraform 命令前通过 source 命令执行该脚本就可以了!
创建 Terraform 配置文件
为了在 Azure 上创建一个 Resource Group,我们创建名称为 createrg.tf 的配置文件,并编辑内容如下:
provider "azurerm" {
}
resource "azurerm_resource_group" "rg" {
name = "NickResourceGroup"
location = "eastasia"
}
用 init 命令用来初始化工作目录
把当前目录切换到 createrg.tf 文件所在的目录,然后执行 init 命令:
$ terraform init
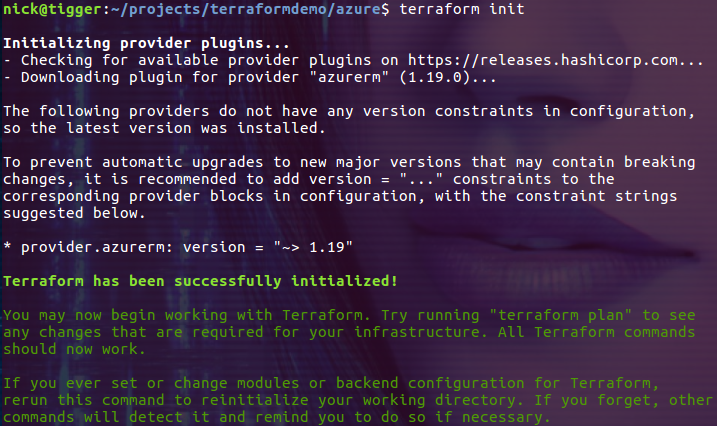
其实就是把 createrg.tf 文件中指定的驱动程序安装到当前目录下的 .terraform 目录中:

通过 plan 命令检查配置文件
plan 命令会检查配置文件并生成执行计划,如果发现配置文件中有错误会直接报错:
$ . azureEnv.sh
$ terraform plan
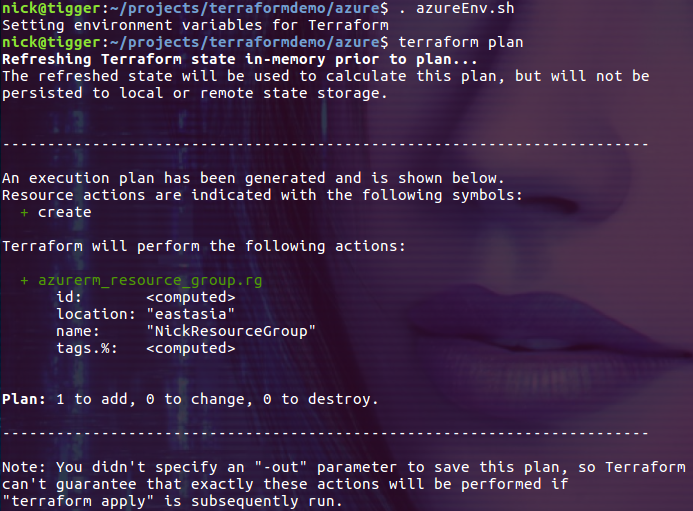
通过 plan 命令的输出,我们可以清楚的看到即将在目标环境中执行的任务。
使用 graph 命令生成可视化的图表
其实 graph 命令只能生成相关图表的数据(dot 格式的数据),我们通过 dot 命令来生成可视化的图表,先通过下面的命令安装 dot 程序:
$ sudo apt install graphviz
然后生成一个图表:
$ terraform graph | dot -Tsvg > graph.svg
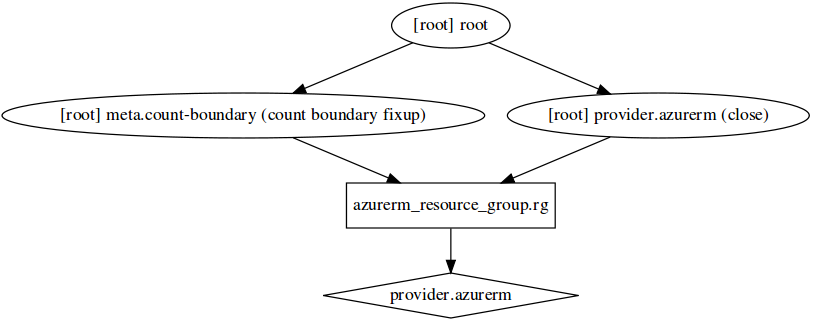
上图描述了我们通过 azurerm 驱动创建了一个 Resource Group。
使用 apply 命令完成部署操作
在使用 apply 命令执行实际的部署时,默认会先执行 plan 命令并进入交互模式等待用户确认操作,我们已经执行过 plan 命令了,所以可以使用 -auto-approve 选项跳过这些步骤直接执行部署操作:
$ terraform apply -auto-approve
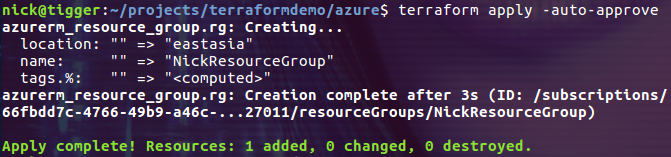
到 Azure 站点上检查一下,发现名称为 NickResourceGroup 的 Resource Group 已经创建成功了。
总结
Terraform 支持的平台非常多,像 AWS,Azure 等大厂自然是不用说了,一些小的厂商也可以通过提供 provider 支持 Terraform,从而让整个生态变得非常活跃。如果大家想在 DevOps 实践中引入基础设施即代码,无论是面对的是公有云还是私有云,相信 Terraform 都不会让你失望。
参考:
Introduction to Terraform
Terraform github
安装和配置 Terraform
Prometheus : 入门
Prometheus 是一个开源的监控系统。支持灵活的查询语言(PromQL),采用 http 协议的 pull 模式拉取数据等特点使 Prometheus 即简单易懂又功能强大。
Prometheus 的主要特点
多维度数据模型
灵活的查询语言
不依赖分布式存储,单个服务器节点是自主的
通过 pull 方式采集时序数据
可以通过中间网关进行时序列数据推送
通过服务发现或者静态配置来发现目标服务对象
支持多种界面展示方案,比如 grafana 等
Prometheus 由 server, client, push gateway, exporter, alertmanager 等核心组件构成。Prometheus server 主要用于抓取和存储数据。Client libraries 可以用来连接 server 并进行查询等操作。Push gateway 用于批量,短期的监控数据的汇总节点,主要用于业务数据汇报等。不同的 exporter 用于不同场景下的数据收集,如收集主机信息的 node_exporter,收集 MongoDB 信息的 MongoDB exporter 等等。下图是 Prometheus 官方提供的架构图:

从这个架构图,我们可以看出它的运行逻辑大概是这样的:
Prometheus server 定期从数据源拉取数据,然后将数据持久化到磁盘。Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将 alert 推送到配置的 Alertmanager。Alertmanager 收到警告的时候,可以根据配置,聚合,去重,降噪,最后发送警告。同时还可以使用 API, Prometheus Console 或者 Grafana 查询和聚合数据。
本文将介绍在 ubuntu 16.04 系统中安装 Prometheus Server,并配置它从一台主机上拉取监控信息,然后通过 Prometheus Server 提供的简易 UI 查询数据。
在 Ubuntu 16.04 中安装 Prometheus Server
请从 Prometheus 官方下载 linux 版的二进制压缩包。注意在下载前要选择操作系统为 linux。
执行下面的命令把 prometheus server 安装到 /usr/local/share/prometheus 目录:
$ tar -xf prometheus-1.7.2.linux-amd64.tar.gz
$ sudo mv prometheus-1.7.2.linux-amd64 /usr/local/share/prometheus
理论上来说这样就算是安装完成了,但是无论如何这都太简陋了。因为每次启动 Prometheus server 都需要手动执行命令:
$ /usr/local/share/prometheus/prometheus -config.file=/usr/local/share/prometheus/prometheus.yml
这实在是太不方便了!应该把它配置成服务,用 systemd 来管理。
先创建一个名为 prometheus 的用户:
$ sudo adduser prometheus
把目录 /usr/local/share/prometheus/ 的所有者设置为 prometheus 用户:
$ sudo chown -R prometheus:prometheus /usr/local/share/prometheus/
然后创建文件 /etc/systemd/system/prometheus.service,内容如下:
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target [Service]
User=prometheus
Restart=on-failure
WorkingDirectory=/usr/local/share/prometheus/
ExecStart=/usr/local/share/prometheus/prometheus \
-config.file=/usr/local/share/prometheus/prometheus.yml [Install]
WantedBy=multi-user.target
好了,现在可以通过 systemd 来控制 Prometheus 服务了,先启动服务:
$ sudo systemctl daemon-reload
$ sudo systemctl start prometheus
再把服务配置为开机时启动:
$ sudo systemctl enable prometheus
检查一下服务的状态:
$ sudo systemctl status prometheus

到此为止 Prometheus Server 已经开始运行了。接下来我们就可以收集数据了。
使用 Node Exporter 收集主机信息
数据收集的任务由不同的 exporter 来完成,如果要收集 linux 主机的信息,可以使用 node exporter。然后由 Prometheus Server 从 node exporter 上拉取信息。接下来我们介绍如何安装并配置 node exporter。
请从 Prometheus 官方下载 node exporter 的二进制压缩包。执行下面的命令把 node exporter 安装到 /usr/local/share/ 目录:
$ tar -xf node_exporter-0.14.0.linux-amd64.tar.gz
$ sudo cp node_exporter-0.14.0.linux-amd64/node_exporter /usr/local/sbin/
同样的我们把 node exporter 也配置成通过 systemd 管理。创建文件 /etc/systemd/system/node-exporter.service,内容如下:
[Unit]
Description=Prometheus Node Exporter
After=network.target [Service]
ExecStart=/usr/local/sbin/node_exporter
User=nobody [Install]
WantedBy=multi-user.target
执行下面的命令设置为开机启动并启动服务:
$ sudo systemctl daemon-reload
$ sudo systemctl enable node-exporter
$ sudo systemctl start node-exporter
node exporter 默认监听 9100 端口,让我们检查一下端口的监听情况:
$ ss -tunl

Node exporter 已经可以收集主机上的信息了,接下来我们还需要配置 Prometheus Server 从 node exporter 那里拉取数据。
配置 Prometheus 从 Node Exproter 拉取数据
Prometheus Server 可以从不同的 exporter 上拉取数据,对于上面的 node exporter 我们可以利用 Prometheus 的 static_configs 来拉取 node exporter 的数据。编辑 Prometheus server 的配置文件:
$ sudo vim /usr/local/share/prometheus/prometheus.yml
在 scrape_configs 中添加一个 名称为 node 的 static_configs:
- job_name: "node"
static_configs:
- targets: ["127.0.0.1:9100"]
注意,要把上面的 IP 地址替换为运行 node exporter 的主机的 IP。

保存文件然后重启 prometheus 服务!重启后 prometheus 服务会每隔 15s 从 node exporter 上拉取一次数据。
查询数据
Prometheus Server 提供了简易的 WebUI 可以进数据查询并展示,它默认监听的端口为 9090。接下来我们进行一次简单的查询来验证本文安装配置的系统。
在浏览器中访问 Prometheus Server 的 9090 端口:

在下拉菜单中选择 "node_memory_Buffers",然后点击 "Execute" 按钮:

查询出来的结果略微有些粗犷,连单位都没带。请选择 "Graph" 标签页:

通过图表查看查询结果就好多了!
总结
Prometheus 是当下比较流行的开源监控工具,这里只是简单的介绍了安装过程及一个最基本的用例。但是不难看出 Prometheus 虽然支持灵活的查询语言,但是自身只支持简单的展示能力。如果要友好的展示 Prometheus 的查询结果,还需要使用更专业的展示工具 Grafana。
Ansible 简介
Ansible 是一个开源的基于 OpenSSH 的自动化配置管理工具。可以用它来配置系统、部署软件和编排更高级的 IT 任务,比如持续部署或零停机更新。Ansible 的主要目标是简单和易用,并且它还高度关注安全性和可靠性。基于这样的目标,Ansible 适用于开发人员、系统管理员、发布工程师、IT 经理,以及介于两者之间的所有人。Ansible 适合管理几乎所有的环境,从拥有少数实例的小型环境到有数千个实例的企业环境。
使用 Ansible 无须在被管理的机器上安装代理,所以不存在如何升级远程守护进程的问题,也不存在由于卸载了守护进程而无法管理系统的问题。
Ansible 的主要功能
管理员可以通过 Ansible 在成百上千台计算机上同时执行指令(任务)。
对于管理员来说,经常需要执行下面的任务:
- 维护现存的比较复杂的服务器时,手动登录的方式很容易遗漏一些操作,或者是执行一些未预期的操作。
- 手动初始化新的服务器耗时耗力!
对于这两种情况,如果完全通过 shell 脚本实现。脚本会过于复杂,极难维护。当然我们也可以使用同类的工具,比如 Puppet and Chef。这两个工具的特点是:需要学习新的知识栈(其实 Ansible 也是有学习成本的)。
相比 Puppet 和 Chef 使用 Ansible 可以延续之前使用 shell 脚本的工作习惯和方式,因而其学习成本会低一些。下面是 Ansible 的一些优势:
- 可以逐行的执行 shell 命令。
- 不需要另外的客户端工具(linux 一般会自带 ssh 工具)。
- 相同的配置只被执行一次(多次执行同一配置不会出问题)。
Ansible 的工作方式
使用 Ansible 无须在被管理的客户端电脑上安装代理之类的组件。它通过普通的 SSH 进行通信,以便从远程计算机检索信息、发出命令和复制文件。这是 Ansible 简化服务器管理的一种方式。任何公开 SSH 端口的服务器都可以通过 Ansible 进行配置和管理。
Ansible 采用模块化的设计,所以非常容易扩展到各种特定的使用场景。模块可以用任何语言编写,并使用标准 JSON 进行通信。Ansible 的配置文件是用 YAML 格式编写的,因为它使用起来非常简单,并且与主流的标记语言很相似。除了通过命令行工具 Ansible 还可以通过配置脚本(Playbooks)与客户端交互。
安装 Ansible
本文介绍在 Ubuntu 16.04 环境中安装并使用 Ansible。由于 Ubuntu 官方库提供的版本比较老,所以我们从第三方的库安装,这样就能安装到比较新的版本:
$ sudo apt-add-repository -y ppa:ansible/ansible
$ sudo apt-get update
$ sudo apt-get install -y ansible
安装完成后检查一下版本:
$ ansible --version

2.7.1 是笔者在写本文时的最新版本。
配置客户端主机的 SSH 秘钥
对于自动化来说,最后是通过秘钥进行认证,这样就不会把用户的密码以明文的方式写在脚本里。下面的命令把安装了 ansible 的主机上当前用户的 SSH 公钥安装到了被管理的客户端 192.168.21.145 和 192.168.21.148 上:
$ ssh-copy-id -i ~/.ssh/id_rsa.pub nick@192.168.21.145
$ ssh-copy-id -i ~/.ssh/id_rsa.pub nick@192.168.21.148
说明:这两台被管理的客户端主机运行的也都是 Ubuntu 16.04。
然后尝试通过下面的命令以不输密码的方式连接到远程主机中:
$ ssh nick@192.168.21.145
$ ssh nick@192.168.21.148
如果能够成功登陆,说明 SSH 的配置已经 OK 了。
配置用户执行 sudo 时不需要密码
在我们执行的自动化操作中,有很大一部分是需要 root 权限的,比如执行更新、安装软件等等。这样的操作会因为在以 sudo 方式执行是提升用户输入密码而失败,比如下面的命令:
$ ansible testservers -b -u nick -a "apt update"

-b 选项默认把用户 nick 提升为 root 权限,但是需要输入用户 nick 的密码,所以自动化执行的命令失败了。当然我们可以同时添加 -K 选项,这是 ansible 会停下来与用户交互,等待用户输入密码:

但这真的不是我想要的结果,我需要的是脚本能够自动化的不需要交互的完成任务!
这个问题的解决方法是把用户设置为执行 sudo 命令时不需要输入密码,让我们在客户机 192.168.21.148 上执行下面的命令:
$ sudo visudo
为用户 nick 添加下面的行:
nick ALL=(ALL) NOPASSWD: ALL
该行内容配置用户 nick 在执行 sudo 命令时不需要输入密码,保存后让我们再次执行下面的命令:
$ ansible testservers -b -u nick -a "apt update"

这次终于可以执行 root 权限的命令了!
清单(inventory)
清单是 ansible 的一个配置文件,在清单中我们可以指定被管理的客户端机器。Ansible 默认的清单文件为 /etc/ansible/hosts,当然我们也可以通过 -i 选项指定其它的清单文件,比如下面的例子:
$ ansible myservers -i /etc/ansible/myhosts -b -u nick -a "apt update"
在清单文件中,我们可以指定 ansible 命令操作的主机对象。对于单个的主机,可以在清单中写主机域名,也可以直接写 IP 地址:

如果要同时对对个主机进行操作,可以把它们定义在一个组中:

在执行 ansible 命令时,指定清单中定义的主机名称或者组名就可以了。比如我们在 /etc/ansible/hosts 文件中定义了一个名称为 testservers 的组,它包含了两个主机:

然后通过下面的命令分别在这两台主机上执行 df -h 命令:
$ ansible testservers -u nick -a "df -h"

从输出的结果可以看出 df -h 命令在两台目标主机上都执行了。
模块
Ansible 把类似的操作封装到模块中,这样就可以通过插件的方式对 Ansible 进行扩展了。每个模块都能接收参数,几乎所有的模块都接受键值对(key=value)参数,这些参数通过空格进行分隔。也有一些模块不接收参数,只需在命令行输入相关的命令就能调用。如果要执行单个命令,可以使用 command 模块:
$ ansible testservers -m command -u nick -a "df -h"
$ ansible webservers -m command -a "/sbin/reboot -t now"
因为 command 是 ansible 执行命令是使用的默认模块,所以我们可以在命令行中省略它:
$ ansible testservers -u nick -a "df -h"
$ ansible testservers -b -u nick -a "/sbin/reboot -t now"
这样的写法本质上和前面的写法是一样的。
如果要执行其它模块中的命令就需要通过 -m 选项显式的指定模块的名称,比如执行 service 模块中的命令:
$ ansible testservers -m service -a "name=httpd state=started"
如果要把文件从本机拷贝到客户端主机上去,就需要使用 copy 模块:
$ ansible testservers -m copy -u nick -a "src=./app.js dest=./myapp/app.js"
Ansible 默认内置了很多好用的模块,你可以从其官方文档中的模块部分了解更多模块相关的内容。
playbook
如果 Ansible 的功能仅仅是能够执行当个的命令和脚本就显得太弱了。Ansible 的 laybook 功能支持把命令以 yaml 的格式写在配置文件中,然后一次性执行配置文件中的所有命令(这一点类似于 chef 中的 cookbook)。比如我们可以把前面演示的 df -h 命令以配置文件的方式写在 playbook 中:
---
- hosts: testservers
become: true
become_user: root
tasks:
- name: check disk
command: df -h
把上面的代码保存在文件 playbook.yml 中,当然你可以根据自己的喜好命名这个文件。其中 hosts 表示对哪些主机进行操作,become 就是我们在命令行上用过的 -b 选项,这里我们通过 become_user: root 显式的指定把当前用户的权限提升为 root 用户权限来执行命令。下面的 tasks 则是对任务的定义,name 是独一无二的一个任务名(如果有多个同名的 task,只执行第一个),接着是 task 中的命令,这里我们还是简单的执行 df -h 命令。然后执行下面的命令,注意这次执行的是 ansible-playbook 命令,并且需要指定编辑好的 playbook 的文件名称作为参数:
$ ansible-playbook -u nick playbook.yml

这样一个简单的 playbook 就可以正常工作了,当然实际的生产环境中你可能会把 playbook 编写的非常复杂!
跳过首次 ssh 连接时的确认提示
这是一个在自动化的过程中经常碰到的问题,所以有必要提一下。如果你不是通过 ssh-copy-id 命令把公钥添加到目标机器上的(多数的环境都不是这么做的),在首次执行 ansible 命令时需要用户确认连接的安全性:

这是非常悲催的,因为我们要实现的目标是自动化的执行命令,而不需要进行交互式的操作。
这个问题的解决方案是配置 ansible,跳过这一步的检查。具体的做法是在配置文件 /etc/ansible/ansible.cfg 中找到行 host_key_checking = False,并去掉行头的注释字符:

然后再执行 ansible 命令就不会提示用户进行交互式验证了。
总结
Ansible 是一个强大的自动化工具,并以其简介的用法,对开发者(系统运维工程师)友好的特点在自动化的流程中占据了一席之地。在这个 devops 已经成为主流的时代,如果能够熟练的使用 ansible ,相信必定会让你的 devops 实践如虎添翼。
用什么监控我们的容器?
本文介绍常见监控工具 zabbix 和 prometheus 的主要特点以及应用于容器监控时各自的优缺点,希望能够帮助同学们选择适合项目的监控工具。
说明:本文介绍的两个工具 zabbix 和 prometheus 都是开源、免费的。
Zabbix 的主要特点
作为老牌监控工具,zabbix 历史悠久,功能全面且强大。下面罗列一些它的主要特点:
数据收集方式灵活全面
- 支持可用性和性能检查
- 支持 SNMP(包括主动轮训和被动获取),IPMI,JMX,VMware 监控
- 支持自定义检查
- 按照自定义的间隔收集需要的数据
- 支持 server/proxy+agents 的模式
自动发现监控对象
- 自动发现网络设备
- 监控代理自动注册
- 发现文件系统,网络接口等等
高度可配置化的报警
- 支持收敛的报警策略
- 可以使用宏变量让报警通知更加高效
- 在报警的同时可以执行应对策略
强大的模板功能
- 在模板中分组检查
- 模板可以关联其他模板
完善的权限管理系统
- 安全用户认证
- 特定用户可以限制访问特定的视图
近乎无限的扩展能力
- 支持通过脚本进行扩展
看一眼 zabbix 提供的菜单感受下它的丰富功能:

Prometheus 的主要特点
Prometheus 是一个开源的系统监控和警报工具包,许多公司和组织都采用了 Prometheus,该项目拥有非常活跃的开发人员和用户社区。下面是 prometheus 的一些主要特点:
- 多维度数据模型
- 灵活的查询语言
- 不依赖分布式存储,单个服务器节点是自主的
- 通过 pull 方式采集时序数据
- 可以通过中间网关进行时序列数据推送
- 通过服务发现或者静态配置来发现目标服务对象
- 支持多种界面展示方案,比如 grafana 等
事实上,业界多把 prometheus 用于容器监控的解决方案,比如与 k8s 的集成。使用 cadvisor + prometheus + grafana 搭建容器监控事实上已经成为了中小企业的首选方案。下图是由 grafana 展示的单台主机上运行容器的汇总信息(当然,数据源来自 prometheus):

其实,prometheus 的扩展性也很好,通过扩展不同的 exporter 可以收集不同应用、设备的信息。
使用 zabbix 监控容器的缺点
Zabbix 的功能非常全面,以至于仅仅用它来监控容器让我们觉着是大材小用了,同时也难免会觉着它不太专业(就监控容器来说)。
事实上 zabbix 监控容器的能力一点也不弱,特别是从版本 4.2 开始,zabbix 也支持 prometheus 做为数据源了。这样一来,zabbix 也就是在视觉展示上比 grafana 差些罢了。
当然 zabbix 还有其它一些问题,比如功能过多(优点有时候也会变成缺点),如果仅仅需要容器监控功能,会觉着 zabbix 用起来太繁琐了。
Zabbix 使用的是 mysql 数据库,对于时序型的数据,性能上肯定没法和专门的时序型数据库相比。
最后,zabbix 的安装和配置虽然不是很难,但离开箱即用还是有段距离的。
使用 prometheus 监控容器的优缺点
Prometheus 和 zabbix 比起来就轻多了,它就是为容器监控而生的。特别是它使用的是时序型的数据库,对于监控类的场景而言性能非常好。
Prometheus + grafana 做出来的视觉效果非常的棒:

并且多数情况下你都不需要自己动手设计这些图表,下载大家做好的模板,直接就能用,效果棒棒的!
但与 zabbix 相比,grafana 的报警功能却不够灵活。
关于监控信息的收集,zabbix 支持 pull/push 两种模式,而 prometheus 只支持 pull 模式。关于 pull/push 模式,大家的关注点似乎都在性能上。而对于我管理的较小的系统来说基本上没有性能问题,我更关注的是安全性。使用 pull 模式,需要生产环境对外暴露端口号,我们需要为此提供安全性相关的配置,而使用 push 模式则没有这个问题(其实是需要提供监控服务器端的安全配置)。
结论
不管是 zabbix 还是 prometheus 都能够完成容器监控的任务。Zabbix 大而全,在传统的监控领域依然是主流的解决方案。而 prometheus 作为一个轻量级的后起之秀,在性能和展示方面优势比较明显,对容器监控支持的非常好。个人认为,在中小企业中搭建 zabbix 监控平台是非常必要的,它能把大大小小、各式各样的设备管理起来。而对于那些运行在云端的容器,选择 prometheus 搭建独立的监控系统会是个不错的选择。
参考:
Zabbix Documentation 3.4 功能点
Zabbix 4.2 发布:支持 Prometheus 数据收集
《Zabbix 企业级分布式监控系统》
《Zabbix 监控系统深度实践第2版》
Prometheus : 入门
Prometheus and the Debate Over 'Push' Versus 'Pull' Monitoring
https://www.cnblogs.com/sparkdev/category/1092445.html
Vargrant 构建 linux 开发环境
什么是 Vargrant ?
Vagrant 是一个简单易用的部署工具,用英文说应该是 Orchestration Tool 。它能帮助开发人员迅速的构建一个开发环境,帮助测试人员构建测试环境, Vagrant 基于 Ruby 开发,使用开源 VirtualBox 作为虚拟化支持,可以轻松的跨平台部署。
通俗的来说,就是在本地部署一个和Linux 虚拟机上的同步文件夹,这样所有的操作都方便了许多
准备工作
- 下载 VirtualBox 虚拟器 : https://www.virtualbox.org/
- 下载安装 Vagrant : http://www.vagrantup.com/
- 下载使用的 box (这里的 box 指的是系统) : http://www.vagrantbox.es/
- 在本地建立一个工作文件夹
部署环境
1.进入工作文件夹

2.把下载的Box 镜像包放到工作目录下-这里我以 **ubuntu 14.04 **为例

3.打开终端进入工作目录, 或者你可以在当前目录按住 shift+鼠标右键 可快速打开当前目录的终端

4.我们执行 vagrant box list 可查看当前添加进 vagrant 的镜像
5.如果没有添加 box 镜像, 我们执行 vagrant box add 系统名字 box镜像

6.这时候我们执行 vagrant box list 就可以查看我们添加的 box 镜像

7.box 镜像添加到 vagrant 里面后我们就可以执行 vagrant init 系统名 初始化, 初始成功后我们可以看见当前工作目录下会生成一个 Vagrantfile 的配置文件

8.因为我们虚拟机默认只分配一个访问外网的 IP, 项目使用的 IP 得手动设置打开 Vagrantfile 找到29行(我的配置文件在29行)设置一个私有 IP

9.到这里所有配置工作都完成了, 我们可以 vagrant up 正式启动了, 启动成功后会在当前目录生成一个 .vagrant 的隐藏文件夹

10.在工作目录中, 使用了 vagrant up 命令, 我们虚拟机会自动的帮我们配置一个系统, 然后自动后台启动, 以后都无须管理虚拟机 让虚拟机在后台玩儿去吧

11.我们可以在当前目录使用 vagrant ssh 直接连接到虚拟机里面, 也可以使用第三方工具进行连接如 Putty, Xshell, IP 为我们刚刚在 Vagrantfile 配置文件中设置的私有 IP

特别注意: 如果是第三方工具连接, 用户名和密码都是 vagrant
12.虚拟机里面的 /vagrant 这个文件夹是和我们本地同步的文件夹

13.下面我们就来看看vagrant神奇的地方, 我们在 /vagrant 同步文件夹里面创建一个文件 a, 看看我们本地发生了什么....., 同样我们在本地把这个 a 文件删除, 看看虚拟机里面发生了什么...

14.这样我们以后从服务器拉取下来的项目, 就可以直接在同步文件夹操作, 操作本地文件, 就相当于操作虚拟机, 目前已经有很多大型公司使用 vagrant, 因为这可以提升他们的开发效率
最后附上vagrant一些常用的命令, 希望这能帮助你们, 别忘记点赞哟!
- $ vagrant box add NAME URL #添加一个box
- $ vagrant box list #查看本地已添加的box
- $ vagrant box remove NAME virtualbox #删除本地已添加的box,如若是版本1.0.x,执行$ vagrant box remove NAME
- $ vagrant init NAME #初始化,实质应是创建Vagrantfile文件
- $ vagrant up #启动虚拟机
- $ vagrant halt #关闭虚拟机
- $ vagrant destroy #销毁虚拟机
- $ vagrant reload #重启虚拟机
- $ vagrant package #当前正在运行的VirtualBox虚拟环境打包成一个可重复使用的box
- $ vagrant ssh #进入虚拟环境
windows下vargrant的安装与使用
转载于:https://blog.51cto.com/jhomephper/1596695
Vagrant 入门指南
Vagrant 简介
Vagrant 是一个用来构建和管理虚拟机环境的工具。Vagrant 有着易于使用的工作流,并且专注于自动化,降低了开发者搭建环境的时间,提高了生产力。解决了“在我的机器上可以工作”的问题。
Vagrant 是为了方便的实现虚拟化环境而设计的,使用 Ruby 开发,基于 VirtualBox 等虚拟机管理软件的接口,提供了一个可配置、轻量级的便携式虚拟开发环境。使用 Vagrant 可以很方便的就建立起来一个虚拟环境,而且可以模拟多台虚拟机,这样我们平时还可以在开发机模拟分布式系统。
团队新员工加入,常常会遇到花一天甚至更多时间来从头搭建完整的开发环境,而有了Vagrant,只需要直接将已经打包好的 package(里面包括开发工具,代码库,配置好的服务器等)拿过来就可以工作了,这对于提升工作效率非常有帮助。
为什么选择 Vagrant
Vagrant 提供了一个易于配置,可重复使用,兼容的环境,通过一个单一的工作流程来控制,帮助你和团队最大化生产力和灵活性。
为了实现 Vagrant 的魔力,Vagrant 站在了巨人的肩膀上。虚拟机的配置基于 VirtualBox,VMware,AWS 或者其他提供商。然后一些配置工具,比如 shell 脚本,Chef 或者 Puppet 可以自动化地在虚拟机安装并配置软件。
对于开发者人员
如果你是一个开发者,Vagrant 将在一个一次性的、一致的环境中隔离依赖项及其配置,而不会影响你习惯使用的任何工具(编辑器、浏览器、调试器等)。一旦你或者其他人创建了一个 Vagrantfile,你只需要执行 vagrant up 所有的东西就自动安装和配置了。你团队中的其他成员使用同一个配置文件来创建开发环境,因此不管你工作在 Linux,MacOS X 还是 Windows, 所有团队的成员都可以在统一的环境环境中运行代码,这样就可以避免“在我的机器上可以工作”的问题。
对于运维人员
如果你是一个运维工程师或者 DevOps 工程师,Vagrant 给予你一个一次性的环境来开发和测试基础架构管理脚本。你可以使用本地虚拟机(比如 VirtualBox 或者 VMware)马上测试一些东西,比如 shell 脚本,Chef cookbooks,Puppet 模块等。然后,你可以用同样的配置在远程云上,比如 AWS 或者 RackSpace,来测试这些脚本。抛弃之前自定义脚本来回收 EC2 实例吧,停止使用 SSH 在各种机器之间跳来跳去,请开始使用 Vagrant 来给你的工作带来更多便利。
Vagrant 和 Terraform 的区别
Vagrant 和 Terraform 都出自同一个公司 HashiCorp,该公司主要做一些开源软件,相关的产品还有 Packer,Consul,Vault,Nomad 等。
Terraform 的主要用途是管理云提供商的远程资源,比如 AWS。Terraform 可以管理横跨多个云提供商巨量的基础设施。而 Vagrant 主要用来管理仅使用少量虚拟机的本地开发环境。
Vagrant 用于开发环境,Terraform 普遍用于基础设施管理。
VirtualBox 安装
VirtualBox 是 Oracle 开源的虚拟化系统,和 VMware 是同类产品,支持多个平台,可以到官方网站:https://www.virtualbox.org/wiki/Downloads 下载适合你平台的 VirtualBox 最新版本并安装。
提示:对于 Mac 用户,如果系统为 OSX 10.13.3(mac OS High Sierra) 或者更高版本,安装过程可能会失败,报错提示
安装失败,安装器遇到了一个错误导致安装失败...,原因是新版本 Mac 系统的安全机制阻止外部内核扩展安装,导致安装失败。两种解决方法:
1. 进入系统偏好设置>安全性与隐私>通用,然后手动允许;
2. 在终端敲命令禁用此安全特性:sudo spctl --master-disable;
Vagrant 安装
到官方网站下载相应系统平台的安装包:http://www.vagrantup.com/downloads.html
直接根据向导进行操作即可完成安装,安装完后就可以在终端输入 vagrant 命令了。
提示:尽量下载最新的程序,因为VirtualBox经常升级,升级后有些接口会变化,老的Vagrant 可能无法使用。
Vagrant 启动第一台虚拟机
到此准备工作(VirtualBox 和 Vagrant 安装)基本上做完了,接下来就可以通过 Vagrant 来启动一台虚拟机了。
在启动虚拟机之前先简单介绍下 Vagrant box:box 是一个打包好的操作系统,是一个后缀名为 .box 的文件,其实是一个压缩包,里面包含了 Vagrant 的配置信息和 VirtualBox 的虚拟机镜像文件。vagrant up 启动虚拟机是基于 box 文件的,因此在启动虚拟机前必须得把 box 文件准备好。或者也可以在启动的时候指定远程 box 地址,在这里我把 box 文件下载下来,然后启动时指定该文件。
我使用网上分享的 ubuntu-server-16.04 这个 box,由于vagrant 官方 box 下载速度特别慢,所以在此提供一下该 box 的百度网盘下载地址,加速下载:https://pan.baidu.com/s/1wJCeWEyxKQLVPi1IH1IlYg
1.新建一个目录作为 Vagrant 的工程目录
$haohao cd /Users/haohao
$haohao mkdir vagrant- 1
- 2
2.添加前面下载的 box
添加 box 命令格式:vagrant box add <本地 box 名称> <box 文件>
- 本地
box名称:自定义名称,该名称是本地vagrant管理时使用的名称; box文件:前面下载的vagrant box文件或者远程boxurl 地址;
$haohao vagrant box add ubuntu-server-16.04 ubuntu-server-16.04-amd64-vagrant.box
==> box: Box file was not detected as metadata. Adding it directly...
==> box: Adding box 'ubuntu-server-16.04' (v0) for provider:
box: Unpacking necessary files from: file:///Users/haohao/vagrant/ubuntu-server-16.04-amd64-vagrant.box
==> box: Successfully added box 'ubuntu-server-16.04' (v0) for 'virtualbox'!3.查看 box 是否添加成功
查看当前 vagrant 中有哪些 box:vagrant box list
$haohao vagrant box list
ubuntu-server-16.04 (virtualbox, 0)- 1
- 2
4.初始化上面添加的 box
初始化命令格式:vagrant init <本地 box 名称>
本地 box 名称:第 2 步中添加的 box 名称
这里初始化前面添加的 box,初始化后会在当前目录生产一个 Vagrantfile 文件,里面包含了虚拟机的各种配置,关于具体每个配置项是什么意思,后面会介绍。
$haohao vagrant init 'ubuntu-server-16.04'
A `Vagrantfile` has been placed in this directory. You are now
ready to `vagrant up` your first virtual environment! Please read
the comments in the Vagrantfile as well as documentation on
`vagrantup.com` for more information on using Vagrant.5.启动虚拟机
虚拟机启动命令:vagrant up
启动虚拟机时会自动将当前目录(即 Vagrantfile 文件所在目录),和虚拟机的 /vagrant 目录共享。
$haohao vagrant up
Bringing machine 'default' up with 'virtualbox' provider...
==> default: Importing base box 'ubuntu-server-16.04'...
==> default: Matching MAC address for NAT networking...
==> default: Setting the name of the VM: vagrant_default_1524288099752_62326
==> default: Clearing any previously set network interfaces...
.....
==> default: Mounting shared folders...
default: /vagrant => /Users/haohao/vagrant- 6.连接虚拟机
命令格式:vagrant ssh
$haohao vagrant ssh
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-98-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
0 packages can be updated.
0 updates are security updates.
Last login: Sat Apr 21 05:28:37 2018 from 10.0.2.2
ubuntu@ubuntu-xenial:~$7.查看 Vagrant 共享目录
进入虚拟机后执行 df -h 可以看到 Vagrant 默认把宿主机 Vagrantfile 所在的目录和虚拟机的 /vagrant 目录共享,可以通过 ls /vagrant/ 查看该目录内容,内容和宿主机对应目录一致。
ubuntu@ubuntu-xenial:~$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 490M 0 490M 0% /dev
tmpfs 100M 3.1M 97M 4% /run
/dev/sda1 9.7G 857M 8.8G 9% /
tmpfs 497M 0 497M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 497M 0 497M 0% /sys/fs/cgroup
vagrant 234G 49G 185G 21% /vagrant
tmpfs 100M 0 100M 0% /run/user/1000
# ls 查看该共享目录内容和宿主机内容一致
ubuntu@ubuntu-xenial:~$ ls /vagrant/
ubuntu-xenial-16.04-cloudimg-console.log VagrantfileVagrant 配置文件浅析
前面我们执行 vagrant init <本地 box 名称> 会在当前目录生成 Vagrantfile 文件,这个文件是非常重要的,一般给别人共享自己的环境时都是提供一个 Vagrantfile 和一个 box 文件,这样就可以很轻松地将环境共享给别人,别人能得到一模一样的统一的环境,这就是使用 Vagrant 的好处。
Vagrantfile 主要包括三个方面的配置,虚拟机的配置、SSH配置、Vagrant 的一些基础配置。Vagrant 是使用 Ruby 开发的,所以它的配置语法也是 Ruby 的,对于没有学过 Ruby 的朋友也没关系,根据例子模仿下就会了。
修改完配置后需要执行 vagrant reload 重启 VM 使其配置生效。
以下简单介绍下常用配置的配置项:
1. box 名称设置config.vm.box = "base"
上面这配置展示了 Vagrant 要去启用那个box作为系统,也就是前面我们输入 vagrant init <本地 box 名称>时所指定的 box,如果沒有输入 box 名称的话,那么默认就是 base。
2.VM 相关配置
VirtualBox 提供了 VBoxManage 这个命令行工具,可以让我们设定 VM,用modifyvm这个命令让我们可以设定 VM 的名称和内存大小等等,这里说的名称指的是在 VirtualBox 中显示的名称,我们也可以在 Vagrantfile 中进行设定,举例如下:
调用 VBoxManage 的
modifyvm的命令,设置 VM 的名称为ubuntu,内存为 1024 MB。你可以类似的通过定制其它 VM 属性来定制你自己的 VM。
config.vm.provider "virtualbox" do |v|
v.customize ["modifyvm", :id, "--name", "ubuntu", "--memory", "1024"]
end- 1
- 2
- 3
3.网络设置
Vagrant 有两种方式来进行网络连接,一种是 host-only (主机模式),这种模式下所有的虚拟系统是可以互相通信的,但虚拟系统和真实的网络是被隔离开的,虚拟机和宿主机是可以互相通信的,相当于两台机器通过双绞线互联。另一种是Bridge(桥接模式),该模式下的 VM 就像是局域网中的一台独立的主机,可以和局域网中的任何一台机器通信,这种情况下需要手动给 VM 配 IP 地址,子网掩码等。我们一般选择 host-only 模式,配置如下:
config.vm.network :private_network, ip: "11.11.11.11"- 1
4.hostname 设置hostname 的设置非常简单:
config.vm.hostname = "kubernetes"- 1
5.目录共享
我们前面介绍过/vagrant目录默认就是当前的开发目录,这是在虚拟机开启的时候默认挂载同步的。我们还可以通过配置来设置额外的同步目录:
# 第一个参数是主机的目录,第二个参数是虚拟机挂载的目录
config.vm.synced_folder "/Users/haohao/data", "/vagrant_data"- 1
- 2
6.端口转发
对宿主机器上 8080 端口的访问请求 forward 到虚拟机的 80 端口的服务上:
config.vm.network :forwarded_port, guest: 80, host: 8080- 1
Vagrant 常用命令清单
vagrant box add添加boxvagrant init初始化 boxvagrant up启动虚拟机vagrant ssh登录虚拟机vagrant box list列出 Vagrant 当前box列表vagrant box remove删除相应的boxvagrant destroy停止当前正在运行的虚拟机并销毁所有创建的资源vagrant halt关机vagrant package把当前的运行的虚拟机环境进行打包为box文件vagrant plugin安装卸载插件vagrant reload重新启动虚拟机,重新载入配置文件vagrant resume恢复被挂起的状态vagrant status获取当前虚拟机的状态vagrant suspend挂起当前的虚拟机vagrant global-status查看当前 vagrant 管理的所有 vm 信息
$ vagrant global-status
id name provider state directory
------------------------------------------------------------------------
aeb2f19 default virtualbox running /Users/haohao/vagrant
2cd1f42 default virtualbox aborted /Users/haohao/vagrant-test
943c1bf default virtualbox aborted /Users/haohao/work/vmvagrant ssh-config输出用于 ssh 连接的一些信息
$ vagrant ssh-config
Host default
HostName 127.0.0.1
User ubuntu
Port 2222
UserKnownHostsFile /dev/null
StrictHostKeyChecking no
PasswordAuthentication no
IdentityFile /Users/haohao/vagrant/.vagrant/machines/default/virtualbox/private_key
IdentitiesOnly yes
LogLevel FATAL1Vagrant 启动虚拟机集群
前面我们都是通过一个 Vagrantfile 配置启动单台机器,如果我们要启动一个集群,那么可以把需要的节点在一个 Vagrantfile 写好,然后直接就可以通过 vagrant up 同时启动多个 VM 组成一个集群。以下示例配置一个 web 节点和一个 db 节点,两个节点在同一个网段,并且使用同一个 box 启动:
Vagrant.configure("2") do |config|
config.vm.define :web do |web|
web.vm.provider "virtualbox" do |v|
v.customize ["modifyvm", :id, "--name", "web", "--memory", "512"]
end
web.vm.box = "ubuntu-server-16.04"
web.vm.hostname = "web"
web.vm.network :private_network, ip: "11.11.1.1"
end
config.vm.define :db do |db|
db.vm.provider "virtualbox" do |v|
v.customize ["modifyvm", :id, "--name", "db", "--memory", "512"]
end
db.vm.box = "ubuntu-server-16.04"
db.vm.hostname = "db"
db.vm.network :private_network, ip: "11.11.1.2"
end
end相关连接
https://www.vagrantup.com/intro/index.html
https://blog.csdn.net/rickiyeat/article/details/55097687
https://github.com/astaxie/go-best-practice/blob/master/ebook/zh/01.0.md
Chef 的安装与使用
Chef 是一款自动化服务器配置管理工具,可以对所管理的对象实行自动化配置,如系统管理,安装软件等。Chef 由三大组件组成:Chef Server、Chef Workstation 和 Chef Node。
Chef Server 是核心服务器,维护了一套配置脚本(Cookbook),与每个被管节点(Chef Node)交互并给出配置指令。
Chef Workstation 提供了我们与 Chef Server 交互的接口:我们在 Workstation 上创建定义 Cookbook,并将 Cookbook 上传到 Chef Server 上以保证被管机器能从 Chef Server 上取得最新的配置指令。
Chef Node 是安装了 chef-client 并注册了的被管理节点,可以是物理机或者虚拟机或者其他对象。Chef Node 每次运行 chef-client 时都会从 Chef Server 端取得最新的配置指令(Cookbook)并按照指令配置自己。
一套 Chef 环境包含一个 Chef Server,至少一个 Chef Workstation,以及一到多个 Chef Node。
Chef 环境的安装
Chef 环境的安装步骤一般是:先安装 Chef Server,然后配置 Chef Workstation, 最后根据需要在客户端机器上安装 Chef Client 并将其注册成 Chef Node。Chef Server 和 Chef Workstation 可以配在一台机器上,也可以分开配置。由 Chef Server、Chef Workstation 和多个 Chef Node 组成整个 Chef 环境。
在 Chef 的官网上有详细的 Chef 安装步骤说明,官网提供的是在有外部网络环境的前提下利用网络自动下载和安装软件。本文将根据实践提供一个无外部网络环境下的 Chef 环境安装过程。
介质准备
由于服务器是无外部网络环境的,事先将所需的软件包下载到本地准备好。
从 Chef 官网(http://www.opscode.com/chef/install)下载 Chef Server 和 Chef Client 的安装包以及 Chef Repository 包。
- Chef Server 安装包
打开http://www.opscode.com/chef/install, 点击"Chef Server"页,选择合适的操作系统,版本等,选择最新的 Chef Server 版本下载。
- Chef Client 安装包
打开http://www.opscode.com/chef/install, 点击"Chef Client"页,选择合适的操作系统,版本等,选择最新的 Chef Client 版本下载。
- 从https://github.com/opscode/chef-repo下载 Chef Repository (chef-repo-master.zip )
由于我们服务器的操作系统是 64 位的 Redhat 6.4,所以在下载的时候选择 Enterprise Linux 版本 6,下载下来的 Chef Server 和 Chef Client 安装包都是 RPM 格式,下面的安装就以我们的环境为例: Chef Server 安装包为 chef-server-11.0.11-1.el6.x86_64.rpm, Chef Client 安装包为 chef-11.10.4-1.el6.x86_64.rpm。
安装 Chef Server
将 Chef Server 的安装包上传到 Chef Server 服务器上。登陆到 Chef Server 服务器上,按照如下步骤配置 Chef Server:
- 安装 Chef Server 安装包:
$ rpm -ihv chef-server-11.0.11-1.el6.x86_64.rpm
- 配置 Chef Server 11.x: (确保防火墙已关闭)
$ sudo chef-server-ctl reconfigure
此命令会创建 Chef Server11.x 的所有必需组件,包括 Erchef、RabbitMQ,、PostgreSQL 等。
- 验证服务器的 hostname 是合法的带域名的全名称。
可运行以下命令将 hostname 加到/etc/hosts 文件中:
$ echo -e "Chef_Server_IP `hostname` `hostname -s`" | sudo tee -a /etc/hosts
- 验证 Chef Server 11.x 是否安装成功。
可通过两种方式验证:一是在 Chef Server 上运行"$ sudo chef-server-ctl test"命令,此命令会运行 chef-pedant 的测试组件并报告所有组件正常工作,安装正确。二是直接在浏览器中打开 Chef Server 的页面: https://Chef_Server_IP,若能出现登录界面,说明 Chef Server 已经正确启动。
安装 Chef Workstation
将 Chef Client 安装包和 Chef Repository 上传到 Chef Workstation 服务器上。登陆到 Chef Workstation 服务器上,按照如下步骤配置 Chef Workstation:
- 安装 Chef Client 安装包:
# rpm -ihv chef-11.10.4-1.el6.x86_64.rpm
- 验证 chef-client 已经安装成功:
# chef-client -v
Chef: 11.10.4
- 确定一个作为 Chef Repository 的目录,如创建/home/chef 目录(后面将以此为例)。将 Chef Repository 包(chef-repo-master.zip)解压并拷贝到/home/chef 目录,重命名为 chef-repo。
- 在/home/chef 下创建.chef 目录。
- 将 Chef Server 上的 admin.pem 和 chef-validator.pem 文件(位于/etc/chef-server) 拷贝到 Chef Repository 的.chef 目录中。
- 运行"knife configure --initial" 命令配置 Chef Workstation,示例如下:
清单 1.配置 Chef Workstation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
[root@chefwst .chef]# knife configure --initialWhere should I put the config file? (/root/.chef/knife.rb) /home/chef/chef-repo/.chef/knife.rbPlease enter the chef server URL: [https://localhost:443] https://Chef_Server_IP:443Please enter a name for the new user: [root]Please enter the existing admin name: [admin]Please enter the location of the existing admin's private key: [/etc/chef-server/admin.pem]/home/chef/chef-repo/.chef/admin.pemPlease enter the validation clientname: [chef-validator]Please enter the location of the validation key: [/etc/chef-server/chef-validator.pem]/home/chef/chef-repo/.chef/chef-validator.pemPlease enter the path to a chef repository (or leave blank): /home/chef/chef-repoCreating initial API user...Please enter a password for the new user:Created user[root]Configuration file written to /home/chef/chef-repo/.chef/knife.rb[root@chefwst .chef]# lsadmin.pem chef-validator.pem knife.rb root.pem - 添加环境变量:
# echo 'export PATH="/opt/chef/embedded/bin:$PATH"' >> ~/.bash_profile && source ~/.bash_profile
- 验证 Chef Workstation 是否配置成功:
一个 Workstation 安装成功的标志是可以使用"Knife"命令与 Server 端进行通信。运行"knife client list"和"knife user list"进行验证,如清单 2 所示。
清单 2. 验证 Chef Workstation
1
2
3
4
5
6
7
[root@chefwst ~]# cd /home/chef/chef-repo[root@chefwst chef-repo]# knife client listchef-validatorchef-webui[root@chefwst chef-repo]# knife user listadminroot
安装 Chef Client
将 Chef Client 安装包上传到目标机器上,登陆到此机器上,按照如下步骤配置 Chef Client:
- 安装 Chef Client 安装包:
# rpm -ihv chef-11.10.4-1.el6.x86_64.rpm
- 验证 chef-client 已经安装成功:
# chef-client -v
Chef: 11.10.4
- 确保 Chef Client 机器时钟与 Server 的时钟是同步的 (相差少于 15 分钟)
- 将安装了 Chef Client 的此机器注册成一个 Chef Node。
在 Chef Workstation 上运行 bootstrap 命令:
# knife bootstrap Chef_Client_IP -x username -P password
bootstrap 命令会检查客户端有没有安装 chef-client 软件,如果没有安装,会从网络上直接下载安装包去安装然后注册;如果已经安装了,则会直接将这个客户端注册成一个 Chef Node。可以接着在 workstation 上执行 node list 命令查看是否多了一个 node:
# knife node list
Chef 的使用
Chef 环境安装完成以后,我们来看看如何使用这套环境来进行配置管理。总体来说,Chef 的配置过程是:
- 在 Workstation 上定义各个 Chef Client 应该如何配置自己,然后将这些信息上传到 Server 端。
- 每个 Chef Client 连到 Server 查看如何配置自己,然后进行自我配置。
在 Workstation 上使用 Cookbook 来定义配置方法。Cookbook 使用 Ruby 脚本定义对 Chef Client 的各种操作,具体 Cookbook 的写法本文不做叙述。一旦 Cookbook 写好之后,就可以重复使用,可以对多个 Chef Client 进行批量配置。一般从创建 Cookbook 到使用 Cookbook 会包括以下几个过程。
- 在 Workstation 上创建 Cookbook
使用 knife 命令可以快速创建一个 Cookbook,如:
# knife cookbook create db2
- 编辑 Cookbook
根据实际需要,编辑 Cookbook 里的 Recipe,可以定义各种对服务器的配置操作,如系统管理,安装软件等。
- 同步 Cookbook
将在 Workstation 上写的 Cookbook 同步上传到 Server 上,可以通过 upload 命令实现:
# knife cookbook upload db2
此命令将最新的 db2 Cookbook 上传到 Server 端,这样 Client 端就能从 Server 端得到最新的配置指令。
也可以将所有的 Cookbook 都一起上传到 Server 端:
# knife cookbook upload --all
- 将 Cookbook 添加到要配置的 Node 的 Run List 中,如:
# knife node run_list add chef-node2 recipe[db2]
此命令将名为 db2 的 Cookbook 下的默认 Recipe(default.rb)添加到名为 chef-node2 的 Node 的 run_list 中。
也可以指定 Cookbook 里的某个特定 Recipe 添加,如:
# knife node run_list add chef-node2 recipe[db2::createdb]
此命令就将特定的 Recipe(created.rb)添加到 Node 的 Run List 里。可以通过 knife 的 node show 命令查看某个 Node 的具体信息:
# knife node show chef-node2
此命令可以看到 Node 的 Run List。
查看更详细的 Node 信息可以加上-l 参数:
# knife node show –l chef-node2
- 运行 Cookboo
在 Chef Node 上直接运行chef-client命令,Chef Client 就会从 Server 端下载最新的配置脚本,然后按照配置脚本配置自己(即脚本运行的过程)。
除掉在 Client 端直接运行chef-client命令,也可以在 Workstation 上运行 knife ssh 命令来达到同样的效果。不同的是,在 Client 端运行 chef-client 命令只是对自己一个 Node 进行配置,而在 Workstation 上运行的 knife ssh 命令可以同时对多个 Client 端进行批量配置。
Chef 的 API 调用
在实际使用中,我们经常需要将 Chef 集成到已有的系统中,这个时候就需要调用 Chef 的 API 来完成。Chef 本身提供了 REST API,可以方便的被调用。只是有少许特殊功能 REST API 不能完成(如注册 Chef Node),还需要调用 Chef 的命令行。本节先介绍 Chef 的 REST API,然后讨论 Chef 的命令调用。
调用 Chef REST API
Chef 的 REST API 提供了对 Chef 内对象的增删改查操作,如增加、删除一个节点、修改节点属性;查询一个 Cookbook 等。具体的每个 API 可以在 Chef 官网中找到,本章节我们主要对调用一个 REST API 的具体过程做出说明。
首先,调用 Chef 的 REST API 之前需要与 Chef Server 端建立认证。
Chef 的认证是基于公私钥的非对称加密机制对用户进行认证。Chef Server 为每个客户端(Workstation,Node 或是其他向 Chef Server 发送请求的应用)生成一对独立的公钥和私钥,将私钥返回给客户端而自己持有所有客户端的公钥。当持有私钥的客户端发送请求时,必须用自己的私钥对请求内容制作数字签名,并随同请求一起发送。Chef Server 用该客户端的公钥对请求中的数字签名进行验证,如果成功,则认为请求发送方可以信任。
这里的一个特殊情况是,当客户端第一次向 Chef Server 发送请求,即请求为自己生成公钥私钥对时,尚未持有自己的私钥。此时客户端必须通过某种方式获取 Chef Server 的默认私钥,通常命名为 Chef-validator.pem。客户端必须用这一私钥执行上述签名过程,否则将无法建立与 Chef Server 的信任。
认证过程如下图所示,
图 1 Chef 认证流程

在上图的第四步,数字签名的必须包含如清单 3 所示的内容。签名的值被放到一个特定的 HTTP Header 'X-Ops-Authorization-N'里发送。这里 N 表示这个 header 可以出现多次,每次出现时它的值不能超过 60 个字符。一个典型的带有签名的客户端请求如清单 4 所示。
这里我们可以看到,被用作数字签名的属性,在请求中再次出现了,包括 HTTP Method,X-Ops-Content-Hash,X-Ops-Timestamp,X-Ops-UserId。而 Hash Path 可以通过计算请求路径直接得到。这样 Chef Server 就可以用 X-Ops-Sign 中指定的算法,这里为 SHA1,重新执行哈希过程以验证请求内容是否被第三方篡改过。
清单 3.Chef 所要求的数字签名内容
|
1 2 3 4 5 |
|
清单 4.带有数字签名的请求范例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
这一认证过程同样发生在用户使用 Knife 命令行或者 Chef 管理页面的时候,只是这些情况下用户无需关心认证的细节。
认证完成后,客户端就可以向 Chef Server 请求对各种 Chef 资源的访问和管理权。以 Node 这一资源为例,Chef Server 提供了如下 API,分别用于获取所有 Nodes,以及对单个 Node 的创建、获取、修改和删除操作,如表 1 所示。
表 1 Chef Server 提供的 Node 资源 REST API
| HTTP METHOD | URL | REQUEST BODY | RESPONSE BODY |
|---|---|---|---|
| GET | /nodes | { "latte": "http://localhost:4000/nodes/latte" } |
|
| POST | /nodes | { "name": "latte", "chef_type": "node", "json_class": "Chef::Node", "attributes": { "hardware_type": "laptop" }, "overrides": {}, "defaults": {}, "run_list": [ "recipe[unicorn]" ] } |
{ "uri": "http://localhost:4000/nodes/latte" } |
| DELETE | /nodes/NAME | { "overrides": {}, "name": "latte", "chef_type": "node", "json_class": "Chef::Node", "attributes": { "hardware_type": "laptop" }, "run_list": [ "recipe[apache2]" ], "defaults": {} } |
|
| GET | /nodes/NAME | { "name": "node_name", "chef_environment": "_default", "run_list": [ "recipe[recipe_name]" ] "json_class": "Chef::Node", "chef_type": "node", "automatic": { ... }, "normal": { "tags": [ ] }, "default": { }, "override": { } } |
|
| PUT | /nodes/NAME | { "overrides": {}, "name": "latte", "chef_type": "node", "json_class": "Chef::Node", "attributes": { "hardware_type": "laptop" }, "run_list": [ 'recipe[cookbook_name::recipe_name], role[role_name]' ], "defaults": {} } |
Response codes:
200 OK |
通过调用 Chef 的 REST API,就可以完成对 Chef 资源的管理。
调用 Chef 命令
为了实现上层系统调用 Chef 的完全自动化,有时候需要自动化 Chef Client 的配置。将一个非 Chef Client 的普通机器自动注册成 Chef Client,能提高整个系统的自动化程度。Chef 的 REST API 没有提供注册 Chef Client 的功能,而 Chef 的 bootstrap 命令是用来完成这个工作的。所以上层系统需要使用某些机制(如使用 JSch)来在 Chef Workstation 上运行 bootstrap 命令。
通常我们用如下命令来将一个普通机器注册成 Chef Node:
knife bootstrap client_IP -x username -P password
如果客户端已经安装了 chef-client 软件,此命令会直接将这个客户端注册成一个 Chef Node;如果客户端没有安装 chef-client 软件,此命令会试图从网络上直接下载安装包去安装 chef-client 然后注册。对于没有外部网络连接的客户端,又没有安装 chef-client 软件,我们可以自定义 bootstrap 所用的模板,让其不从网络下载 chef-client,而直接从本地服务器下载 chef-client 进行安装(前提是配置一个本地服务器如 HTTP 服务器,将 chef-client 软件预先放到服务器上)。如果是默认安装,bootstrap 所用的模板位于 Workstation 的/opt/chef/embedded/lib/ruby/gems/1.9.1/gems/chef-11.10.4/lib/chef/knife/bootstrap/目录下。我们可以在此目录下新建一个模板,命名为 ubuntu12.04-gems-mine,在原有的 ubuntu12.04-gems 模板基础上进行修改,如将安装 chef-client 软件的部分自定义为清单 5 所示。
清单 5.自定义 bootstrap 模板
|
1 2 3 4 5 6 7 8 |
|
然后我们使用自定义的模板来运行 bootstrap 命令:
# knife bootstrap client_ip -x username -P password –d ubuntu12.04-gems-mine
这样在 bootstrap 一个普通的没有安装 chef-client 的机器时,Chef 就会从本地的服务器上下载 chef-client 软件(无需外部网络连接),安装在客户机上,然后注册成 Chef Node。
可见,对于没有提供 Chef REST API 的一些特殊 Chef 功能,可以通过调用 Chef 的命令行来完成。
Chef 的异常处理机制
Chef Client 运行完相关配置后,运行结果是成功还是失败,成功或者失败之后怎么处理,这些在集成 Chef 的系统中非常重要。一方面,上层系统需要监控 Chef 的运行状态;另外一方面,对于 Chef 的运行结果,上层系统一般需要做一些处理。为此,Chef 提供了两种类型的 Handler 来分别处理失败和成功的运行结果:Exception Handler 和 Report Handler。Chef 提供一个基础的 chef_handler 资源,我们可以自定义自己的 Handler 来支持业务需求。自定义 Handler 需要继承 Chef 提供的基础 Handler 类。下面我们自定义一个调用某业务 REST API 的 Handler 名为"CallRestAPI":
清单 6.自定义 Chef Handler require 'chef/handler'
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
|
在这个自定义的 Handler 中,首先初始化传来的参数。然后根据 Chef 内置的变量(run_status)来判断运行结果是成功还是失败,如果失败,还可以得到失败的异常消息。接着就是调用具体业务的 REST API 将此结果返回。对于这样一个自定义的 Handler,我们可以将其作为一个文件放到一个 Cookbook 的 files 的 default 目录下(假设命名为 chef-handler-mine.rb),然后在此 Cookbook 的 Recipe 中启动这个 Handler。启动示例如下:
清单 7.启动(调用)自定义 Chef Handler include_recipe "chef_handler"
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
在清单 7 中,首先将自定义的 Handler 传到 Chef Client 端,然后启动这个 Handler。启动之后,当此 Recipe 运行完成之后,无论成功失败(因为将 report 和 exception 两者都设置成了 true),都会自动调用这个自定义 Handler,将结果返回给上层业务系统。
如果多个 Cookbook 需要相同的 Handler 机制,我们可以将这样的 Handler 抽取出来写成一个单独的 Cookbook,比如,创建一个名为 myhandler 的 Cookbook,然后将自定义的"CallRestAPI"Hander 放到 files 的 default 目录下,再将清单 7 中的代码写到 myhandler 的 default 的 Recipe 中。在其他需要调用这个 Handler 的 Cookbook 里,只需要加上 include_recipe "myhandler"就可以了。
结束语
本文介绍了 Chef 环境的安装与使用方法,主要是根据实际经验来介绍的,文中更多的是举例和成功实践。如果要全面详细的了解 Chef 的各个组件如何配合工作,Chef 提供了哪些内置的资源方便使用者开发 Cookbook,可以参考 Chef 的官网。在当前大势所趋的云环境中,自动化部署也是其中一个重要工作,对于虚机的部署可以调用相关的虚拟化平台接口,而对于虚机的配置,以及软件和应用的自动化部署,就能用到 Chef 这个自动化工具了,而事实也证明,Chef 在当下正变得越来越流行,已被很多企业级云平台采用,相信它会越来越广泛地应用到自动化领域中
DevOps-ISC,CSS,Prometheus,Ansible ,Terraform,zabbix的更多相关文章
- ansible、zabbix、tcpdump
Ansible 源码安装 https://blog.csdn.net/williamfan21c/article/details/53439307 Ansible安装过程中常遇到的错误 http:// ...
- Ansible实现zabbix服务器agent端批量部署
项目需求:由于搭建zabbix,需要每台服务器都需要安装监控端(agent)正常的的操作是一台一台去安装,这样确实有点浪费时间,这里为大家准备了一款开源 的自动化运维工具Ansible,相信大家也很熟 ...
- 《为什么说 Prometheus 是足以取代 Zabbix 的监控神器?》
为什么说 Prometheus 是足以取代 Zabbix 的监控神器? Kuberneteschina 致力于提供最权威的 Kubernetes 技术.案例与Meetup! 关注他 12 人赞同 ...
- ansible 批量安装zabbix agentd客户端
目录结构 # tree /etc/ansible/ /etc/ansible/ ├── ansible.cfg ├── hosts ├── roles │ └── zabbix-agentd │ ...
- Ansible 快速部署 Zabbix 4
阅读本文章需要具有Ansible.Zabbix基础.本次教程基于如下环境: CentOS 7.x Zabbix 4.0 Ansible 2.5 服务器初始化 关闭防火墙.selinux,添加epel常 ...
- DevOps“五宗罪”,这样向DevOps过渡注定会失败
云计算提供的速度响应.敏捷性和规模效应,契合了如今不断变化的数字商业环境.企业基于最新的IT技术,重构IT架构,加速产品创新和服务交付的速度,从而提高运营效率和市场占有. 不过,企业IT管理者在利用云 ...
- zabbix批量操作
利用zabbix-api来实现zabbix的主机的批量添加,主机的查找,删除等等操作. 代码如下: #!/usr/bin/env python #-*- coding: utf- -*- import ...
- ansible结合zabbix_api批量添加主机
批量添加zabbix监控 .使用ansible配置zabbix客户端 ①修改服务器的IP(域名),为了方便使用ansible来批量操作 等同于如下sed语句 sed -i 's#Server=1.1. ...
- kubernetes生态--交付prometheus监控及grafana炫酷dashboard到k8s集群
由于docker容器的特殊性,传统的zabbix无法对k8s集群内的docker状态进行监控,所以需要使用prometheus来进行监控: 什么是Prometheus? Prometheus是由Sou ...
随机推荐
- 腾讯云 Tencent Hub工作流通过钉钉通知
增加一个Job即可. 使用工作流组件为:hub.tencentyun.com/tencenthub/notice_dingding 其他的看填写说明就可以了. PS也可以通过TFTT来实现,也很好用.
- 用OKR让你的员工嗨起来
在<OKR工作法>这本书中,作者主要用了叙述故事的方式来讲解了在OKR实践的整个过程,这样的讲解方式让整本书显得生动有趣,却又处处是引人深思的道理.比如说TeaBee在第一次OKR实践失败 ...
- 如何使用Microsoft的驱动程序验证程序解释无法分析的崩溃转储文件
这篇文章解释了如何使用驱动程序验证工具来分析崩溃转储文件. 使用Microsoft驱动程序验证工具 如果您曾经使用Windows的调试工具来分析崩溃转储,那么毫无疑问,您已经使用WinDbg打开了一个 ...
- Hibernate的级联保存、级联删除
级联操作: 属性:cascade 值:save-update(级联保存) delete(级联删除) all(级联保存+级联删除) 优点:虽然,不用级联操作也能解决问题.但是级联操作可以减少代码量,使得 ...
- pwd函数实现
/* * 文件名:mypwd.c * 描述: 实现简单的pwd命令 */ #include<stdio.h> #include<stdlib.h> #include<di ...
- redis(三) 集群 codis
参考文档 http://blog.csdn.net/ztsinghua/article/details/48134377
- dubbo源码分析之过滤器Filter-12
https://blog.csdn.net/luoyang_java/article/details/86682668 Dubbo 是阿里巴巴开源的一个高性能优秀的服务框架,使得应用可通过高性能的 R ...
- java 把 PEM 格式的公钥证书转换为 X.509 格式的证书
代码: @UtilityClass public final class X509Certs { private static final CertificateFactory CERTIFICATE ...
- lastlogon
function Get-ADUserLastLogon($userName) { $dcs = Get-ADDomainController -Filter {Name -like "*& ...
- C#实体类对应SQL数据库的自增长ID怎么设置?
/// <summary> /// 自增长ID /// </summary> [DatabaseGenerated(DatabaseGeneratedOption.Identi ...