scrapy原理
scarpy据说是目前最强大的爬虫框架,没有之一。就是这么自信。
官网都是这么说的。

An open source and collaborative framework for extracting the data you need from websites. In a fast, simple, yet extensible way.
一个开源的,协作的框架从网络收集你需要的数据,是简单,快速以及可扩展的。
那么学习之前,首先要学习一个原理。
Scarpy有几个模块
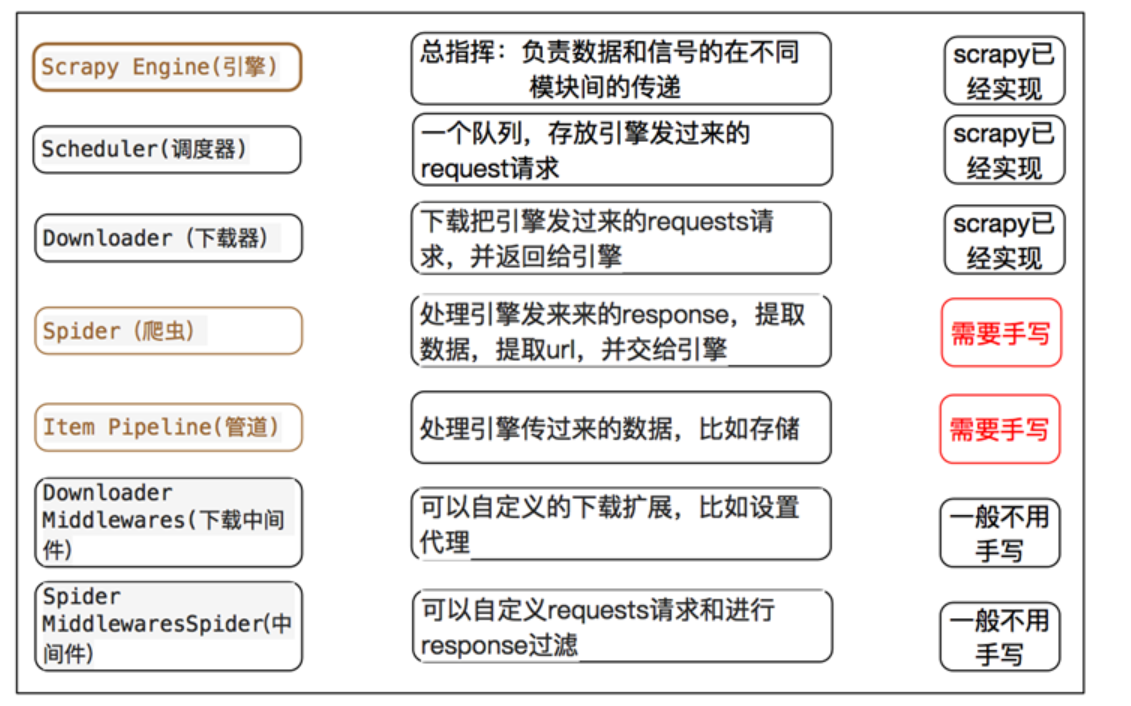
1.engine 引擎,框架已经实现,不需要我们写,它是scrapy能够进行的重要部件。好比车的发动机。
2.spiders 爬虫文件
3.schedule 调度器 对于发起的请求入队列
4.downloader下载器 从互联网中下载网页源代码
5,Itempipline 管道文件 ,用于可持续化存储数据,可以存储在MySQL,MongoDB,Redis,也可以保存于文件。
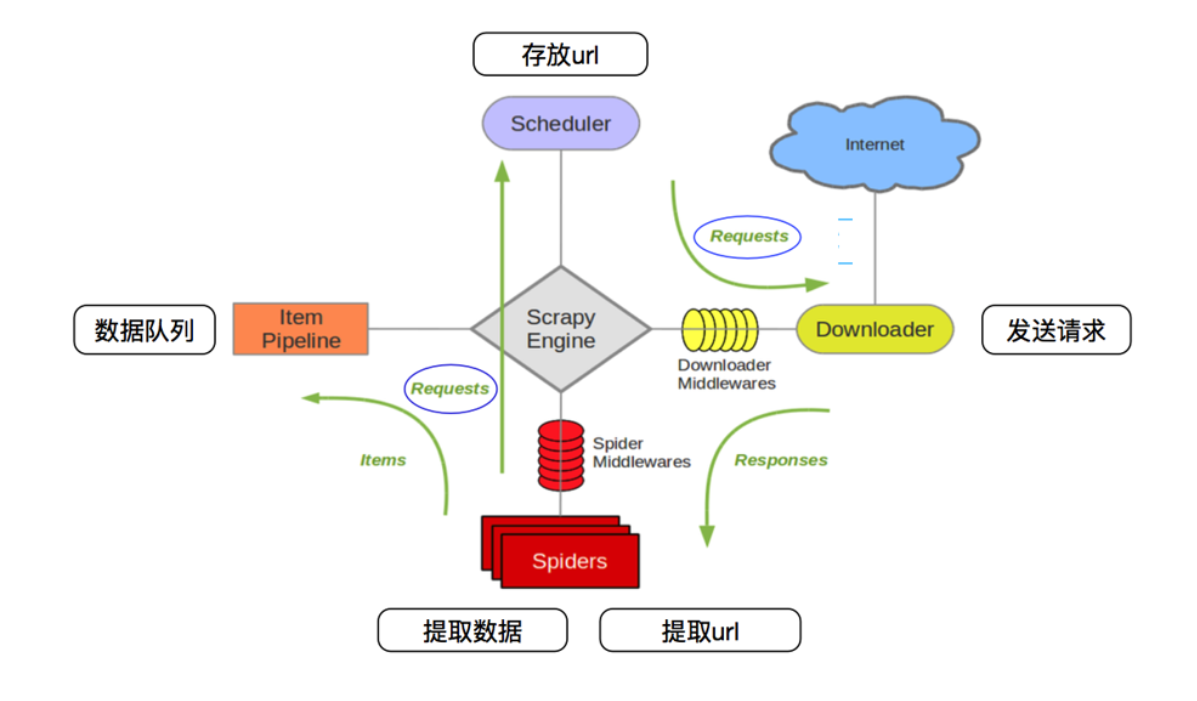
通过这个图可以看出scrapy工作的原理。
1,spiders 将发送的请求request(url)发送给 scrapy engine 引擎。然后引擎发送给调度器(scheduler),调度器对发送来的请求进行排序,入队列
2. scheduler调度器将请求request(url) ,发给scrapy engine引擎,然后引擎(Engine)将请求request 通过Downloader Middleware(下载器中间建)发送给Downloader下载器。
3,下载器Downloader 向互联网发送请求(request),下载网页源代码。得到response 响应,响应response通过 SpiderMiddleWares,发送给Spiders爬虫文件。
4.爬虫spiders对数据进行提取,然后发送数据交给Itempipeline 管道,管道将数据进行持久化操作或者保存。
spiders对下载器下载的网页源码进行数据机器,scrapy提供了css选择器。可以方便提取相关的数据。
通过这些步骤可以看出来,scrapy engine是占据很重要的位置。它负责联系各种组件之间的信号signals传递。
通过以下图,可以看出来,Scrapy需要我们书写的靳靳是spider,ItemPipeline,提取数据和持久化数据操作。其余的都已经替我们实现了。
scrapy原理的更多相关文章
- Scrapy 原理
Scrapy 原理 一.原理 scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列程序中. 二.工作流程 Scrapy Engi ...
- scrapy 原理,结构,基本命令,item,spider,selector简述
原理,结构,基本命令,item,spider,selector简述 原理 (1)结构 (2)运行流程 实操 (1) scrapy命令: 注意先把python安装目录的scripts文件夹添加到环境变量 ...
- 基于scrapy源码实现的自定义微型异步爬虫框架
一.scrapy原理 Scrapy 使用了 Twisted异步网络库来处理网络通讯.整体架构大致如下 Scrapy主要包括了以下组件: 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框 ...
- 学习scrapy框架爬小说
一.背景:近期学习python爬虫技术,感觉挺有趣.由于手动自制爬虫感觉效率低,了解到爬虫界有先进的工具可用,尝试学学scrapy爬虫框架的使用. 二.环境:centos7,python3.7,scr ...
- 01.scrapy入门
Scrapy快速入门 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,它使用Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求. ...
- java网络爬虫----------简单抓取慕课网首页数据
© 版权声明:本文为博主原创文章,转载请注明出处 一.分析 1.目标:抓取慕课网首页推荐课程的名称和描述信息 2.分析:浏览器F12分析得到,推荐课程的名称都放在class="course- ...
- python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程 在pycharm中打开此工程目录:并在Run中选择Edit Configuration 点击+创建一个Pytho ...
- scrapy暂停和重启,及url去重原理,telenet简单使用
一.scrapy暂停与重启 1.要暂停,就要保留一些中间信息,以便重启读取中间信息并从当前位置继续爬取,则需要一个目录存放中间信息: scrapy crawl spider_name -s JOBDI ...
- 第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理 网站树形结构 深度优先 是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)Scrapy默认 ...
随机推荐
- Django中的get()和filter()区别
前言 在django中,我们查询经常用的两个API中,会经常用到get()和filter()两个方法,两者的区别是什么呢? object.get()我们得到的是一个对象,如果在数据库中查不到这个对象或 ...
- MySQL中truncate误操作后的数据恢复案例
MySQL中truncate误操作后的数据恢复案例 这篇文章主要介绍了MySQL中truncate误操作后的数据恢复案例,主要是要从日志中定位到truncate操作的地方然后备份之前丢失的数据,需要的 ...
- thinkphp5 redis使用
参数参考位置:thinkphp\library\think\cache\driver class Redis extends Driver { protected $options = [ 'host ...
- <读书笔记>Javascript系列之6种继承(面向对象)
写在前面: 以下三选一: 阅读博文JavaScript 对象详解. 阅读<JavaScript权威指南>第6章. 阅读<JavaScript高级程序设计>第6章. 注意:只需要 ...
- Python中的内置函数和匿名函数
1. 内置函数 print用法 def print(self, *args, sep=' ', end='\n', file=None): # known special case of print ...
- 正则sub的使用
import re # unicode 编码匹配范围[u4e00-u9fa5] pattern = re.compile('(\w+) (\w+)') s = 'hello 123,hello 456 ...
- Dubbo 系列(07-4)集群容错 - 集群
BDubbo 系列(07-4)集群容错 - 集群 [toc] Spring Cloud Alibaba 系列目录 - Dubbo 篇 1. 背景介绍 相关文档推荐: Dubbo 集群容错 - 实战 D ...
- canvas---从基础到实战
canvas是H5新增的一个元素,可以用来描绘各种你想描绘的东西. canvas本身没有绘制能力,你可以把它当做一个容器,需要我们用脚本,也就是js来给他灌满水. 兼容性 1. IE9版本以上.Fir ...
- 深入Spring:自定义IOC
前言 上一篇文章讲了如何自定义注解,注解的加载和使用,这篇讲一下Spring的IOC过程,并通过自定义注解来实现IOC. 自定义注解 还是先看一下个最简单的例子,源码同样放在了Github. 先定义自 ...
- Charles IOS https抓包
步骤 1.下载charles: https://www.charlesproxy.com/download/ 只有一个30天试用版,每次打开只能30分钟,如果想时间长点,就找破解版或者买个licenc ...