机器学习实战-Logistics回归
Logistics回归:实战,有两个特征X0,X1.100个样本,进行Logistics回归
1.导入数据
def load_data_set():
"""
加载数据集
:return:返回两个数组,普通数组
data_arr -- 原始数据的特征
label_arr -- 原始数据的标签,也就是每条样本对应的类别
"""
data_arr=[]
label_arr=[]
f=open('TestSet.txt','r')
for line in f.readlines():
line_arr=line.strip().split()
#为了方便计算,我们将x0的值设为1.0,也就是在每一行的开头添加一个1.0,作为x0
data_arr.append([1.0,np.float(line_arr[0]),np.float(line_arr[1])])
label_arr.append(int(line_arr[2]))
return data_arr,label_arr
2. Logistics回归梯度上升优化算法
def sigmoid(x):
return 1.0/(1+np.exp(-x)) def grad_ascent(data_arr,class_labels):
"""
梯度上升法,其实就是因为使用了极大似然估计,这个大家有必要去看推导,只看代码感觉不太够
:param data_arr: 传入的就是一个普通的数组,当然你传入一个二维的ndarray也行
:param class_labels: class_labels 是类别标签,它是一个 1*100 的行向量。
为了便于矩阵计算,需要将该行向量转换为列向量,做法是将原向量转置,再将它赋值给label_mat
:return:
"""
data_mat=np.mat(data_arr)
#变成矩阵之后进行转置
label_mat=np.mat(class_labels).transpose()
#获得数据的样本量和特征维度数
m,n=np.shape(data_mat)
#学习率
alpha=0.001
#最大迭代次数
max_cycles=500
# 生成一个长度和特征数相同的矩阵,此处n为3 -> [[1],[1],[1]]
# weights 代表回归系数, 此处的 ones((n,1)) 创建一个长度和特征数相同的矩阵,其中的数全部都是 1
weights=np.ones((n,1))
for k in range(max_cycles):
h=sigmoid(data_mat*weights)
error=label_mat-h
weights=weights+alpha*data_mat.transpose()*error
return weights
3. 画出决策边界,即画出数据集合Logistics回归最佳拟合直接的函数
def plot_best_fit(weights):
"""
可视化
:param weights:
:return:
"""
import matplotlib.pyplot as plt
data_mat, label_mat = load_data_set()
data_arr = np.array(data_mat)
n = np.shape(data_mat)[0]
x_cord1 = []
y_cord1 = []
x_cord2 = []
y_cord2 = []
for i in range(n):
if int(label_mat[i]) == 1:
x_cord1.append(data_arr[i, 1])
y_cord1.append(data_arr[i, 2])
else:
x_cord2.append(data_arr[i, 1])
y_cord2.append(data_arr[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(x_cord1, y_cord1, s=30, color='k', marker='^')
ax.scatter(x_cord2, y_cord2, s=30, color='red', marker='s')
x = np.arange(-3.0, 3.0, 0.1)
y = (-weights[0] - weights[1] * x) / weights[2]
"""
y的由来,卧槽,是不是没看懂?
首先理论上是这个样子的。
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
w0*x0+w1*x1+w2*x2=f(x)
x0最开始就设置为1叻, x2就是我们画图的y值,而f(x)被我们磨合误差给算到w0,w1,w2身上去了
所以: w0+w1*x+w2*y=0 => y = (-w0-w1*x)/w2
"""
ax.plot(x, y)
plt.xlabel('x1')
plt.ylabel('y1')
plt.show()
4. 测试数据,画图
def test():
"""
这个函数只要就是对上面的几个算法的测试,这样就不用每次都在power shell 里面操作,不然麻烦死了
:return:
"""
data_arr, class_labels = load_data_set()
# 注意,这里的grad_ascent返回的是一个 matrix, 所以要使用getA方法变成ndarray类型
weights = grad_ascent(data_arr, class_labels).getA()
# weights = stoc_grad_ascent0(np.array(data_arr), class_labels)
#weights = stoc_grad_ascent1(np.array(data_arr), class_labels)
plot_best_fit(weights) if __name__ == '__main__':
test()
5. 结果如下
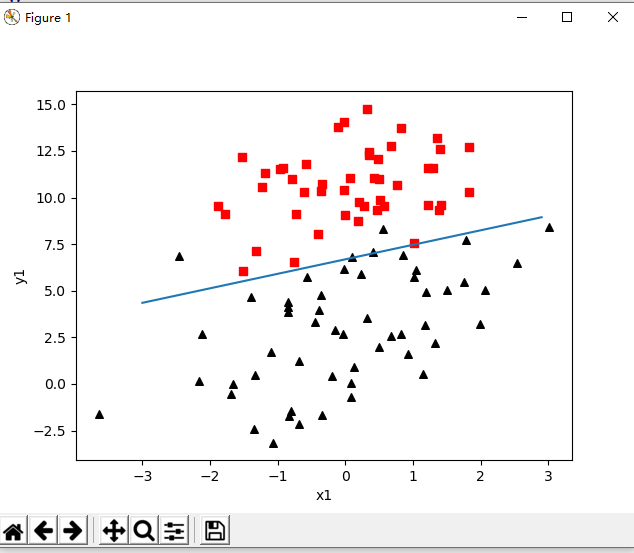
另外,还有
真实训练数据和测试数据-------从疝气病症预测病马的死亡率------
如何预测的代码也附加~
github实现地址:https://github.com/CynthiaWendy/Machine-Learning-in-Action-Logistics
机器学习实战-Logistics回归的更多相关文章
- [机器学习实战-Logistic回归]使用Logistic回归预测各种实例
目录 本实验代码已经传到gitee上,请点击查收! 一.实验目的 二.实验内容与设计思想 实验内容 设计思想 三.实验使用环境 四.实验步骤和调试过程 4.1 基于Logistic回归和Sigmoid ...
- 机器学习实战-logistic回归分类
基于LR的回归分类实例 概念 前提理解: 机器学习的三个步骤:模型,损失函数(即样本误差),优化求解(通过损失函数,使得模型的样本误差最小或小于阈值,求出满足条件的参数,优化求解包括:最小二乘法,梯度 ...
- 机器学习-对数logistics回归
今天 学习了对数几率回归,学的不是很明白x1*theat1+x2*theat2...=y 对于最终的求解参数编程还是不太会,但是也大致搞明白了,对数几率回归是由于线性回归函数的结果并不是我们想要的,我 ...
- 机器学习实战--logistic回归
#encoding:utf-8 from numpy import * def loadDataSet(): #加载数据 dataMat = []; labelMat = [] fr = open(' ...
- 机器学习实战 logistic回归 python代码
# -*- coding: utf-8 -*- """ Created on Sun Aug 06 15:57:18 2017 @author: mdz "&q ...
- 机器学习算法的Python实现 (1):logistics回归 与 线性判别分析(LDA)
先收藏............ 本文为笔者在学习周志华老师的机器学习教材后,写的课后习题的的编程题.之前放在答案的博文中,现在重新进行整理,将需要实现代码的部分单独拿出来,慢慢积累.希望能写一个机器学 ...
- 机器学习实战笔记(Python实现)-08-线性回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-04-Logistic回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记5(logistic回归)
1:简单概念描写叙述 如果如今有一些数据点,我们用一条直线对这些点进行拟合(改线称为最佳拟合直线),这个拟合过程就称为回归.训练分类器就是为了寻找最佳拟合參数,使用的是最优化算法. 基于sigmoid ...
随机推荐
- Codeforces 981 共同点路径覆盖树构造 BFS/DP书架&最大值
A /*Huyyt*/ #include<bits/stdc++.h> #define mem(a,b) memset(a,b,sizeof(a)) #define pb push_bac ...
- 安装php多进程模块pcntl
在使用函数pcntl_fork()时报错 Fatal error: Uncaught Error: Call to undefined function pcntl_fork()....,原因是没有 ...
- Nginx 502 Bad Gateway 的错误的解决方案
我用的是nginx反向代理Apache,直接用Apache不会有任何问题,加上nginx就会有部分ajax请求502的错误,下面是我收集到的解决方案. 一.fastcgi缓冲区设置过小 出现错误,首先 ...
- 【NOIP2017提高组模拟12.24】B
题目 现在你有N个数,分别为A1,A2,-,AN,现在有M组询问需要你回答.每个询问将会给你一个L和R(L<=R),保证Max{Ai}-Min{Ai}<=R-L,你需要找出并输出最小的K( ...
- 16. ClustrixDB Rebalancer
管理平衡 Clustrix Rebalancer被设计成自动作为后台进程运行,以便跨集群重新平衡数据.介绍如何配置和监视rebalancer,但是大多数部署不需要用户干预. Rebalancer主要通 ...
- python调用Opencv库和dlib库
python是一门胶水语言,可以调用C++编译好的dll库 python调用opencv-imggui.dll文件 https://www.cnblogs.com/zhangxian/articles ...
- Oracle --45 个非常有用的 Oracle 查询语句
日期/时间 相关查询 1.获取当前月份的第一天运行这个命令能快速返回当前月份的第一天.你可以用任何的日期值替换 “SYSDATE”来指定查询的日期.SELECT TRUNC (SYSDATE, 'MO ...
- uiautomatorviewer报错 Error taking device screenshot: EOF
报以下错误 估计是端口冲突 解决方法: 1. netstat -ano | findstr 5037 查看占用5037端口的进程 2. taskkill /pid 10508 /f 杀掉此进程 3 ...
- centos7 修改ali yum源
centos7 修改yum源为阿里源,某下网络下速度比较快 首先是到yum源设置文件夹里 安装base reop源 cd /etc/yum.repos.d 接着备份旧的配置文件 sudo mv Cen ...
- 理解BFC以及BFC相关布局问题解决
写页面时会遇到: 子元素float父元素的高度不会撑开; 在布局时,box1and box2,其中box1 float:left,这是box2会在box1下面,(如果文字过多就会形成文字环绕效果),但 ...