Big Data(二)分布式文件系统那么多,为什么hadoop还需要一个hdfs文件系统?
提纲
- 存储模型
- 架构设计
- 角色功能
- 元数据持久化
- 安全模式
- 副本放置策略
- 读写流程
- 安全策略
存储模型
- 文件线性按字节切割成块(block),具有offset,id
- 文件与文件的block大小可以不一样
- 一个文件除最后一个block,其他block大小一致
- block的大小依据硬件的I/O特性调整
- block被分散存放在集群的节点中,具有location
- Block具有副本(replication),没有主从概念,副本不能出现在同一个节点
- 副本是满足可靠性和性能的关键
- 文件上传可以指定block大小和副本数,上传后只能修改副本数
- 一次写入多次读取,不支持修改
- 支持追加数据
架构设计
- HDFS是一个主从(Master/Slaves)架构
- 由一个NameNode和一些DataNode组成
- 面向文件包含:文件数据(data)和文件元数据(metadata)
- NameNode负责存储和管理文件元数据,并维护了一个层次型的文件目录树
- DataNode负责存储文件数据(block块),并提供block的读写
- DataNode与NameNode维持心跳,并汇报自己持有的block信息
- Client和NameNode交互文件元数据和DataNode交互文件block数据
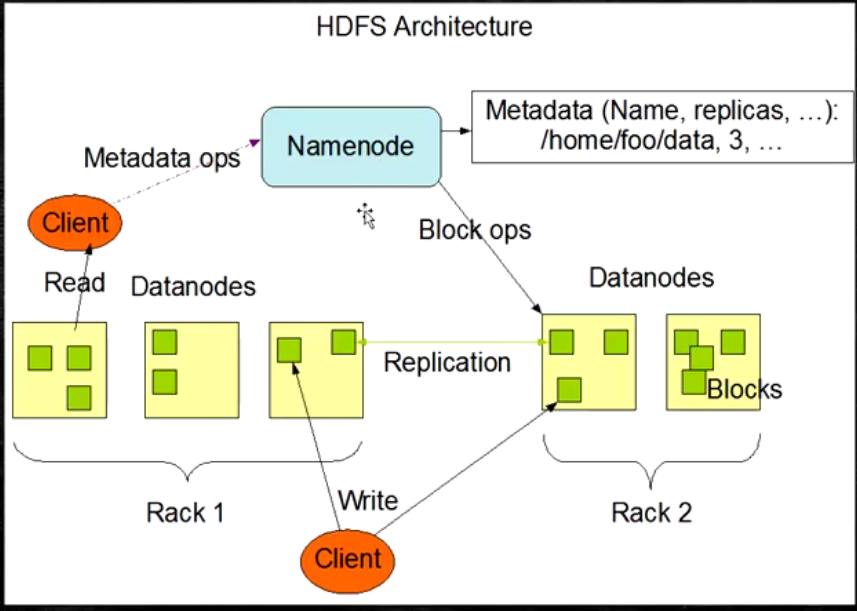
HDFS的架构图

角色功能
- NameNode
- 完全基于内存存储文件、目录结构,文件block的映射
- 需要持久化方案保证数据的可靠性
- 提供副本放置策略
- DataNode
- 基于本地磁盘存储block(文件的形式)
- 保存block的校验和数据保证block的可靠性
- 与NameNode保持心跳,汇报block列表状态
元数据持久化
- 任何对文件系统元数据产生修改的操作,NameNode都会生成一个EditLog的事务进行记录下来
- 使用FsImage存储所有元数据的状态
- 使用本地磁盘保存EditLog和FsImage
- EditLog具有完整性,数据丢失少,但恢复速度慢,并且有提及膨胀风险
- FsImage具有恢复速度快,提及与内存数据相当,但不能实时保存,数据丢失多
- NameNode使用了FsImage+EditLog整合方案:
- 滚动将增量的EditLog更新到FsImage,以保证更近时点的FsImage和更小的EditLog体积
(科普:EditsLog:log恢复日志,FsImage:镜像,快照恢复,HDFS采用FsImage+增量的EditLog进行记录)
安全模式
- HDFS搭建时会格式化,格式化操作会产生一个空的FsImage
- 当NameNode启动时,它从磁盘中读取EditLog和FsImage
- 将所有EditLog中的事务作用在内存中的FsImage上
- 并且将新版本的FsImage从内存中保存在磁盘上
- 删除旧的EditLog,因为这个旧的EditLog的事务已经作用在了FsImage上了
- NameNode启动后会进行一个称为安全模式的特殊状态
- 处于安全模式的NameNode是不会进行数据块的复制的
- NameNode从所有的DataNode接收心跳信号和状态报告
- 每当NameNode检测确认某个数据块的副本数目达到这个最小值,那么该数据库会被认为是副本安全(safely replicated)的
- 在一定百分比的数据被NameNode检测确认是安全之后,NameNode将会退出安全模式状态
- 接下来它会确定还有哪些数据库的副本没有达到指定书目,并将数据块复制到DataNode上
HDFS中的SNN
SecondaryNameNode(SNN)
- 在非Ha模式下,SNN一般是独立的节点,周期完成对NN的EditLog向FsImage合并,减少EditLog大小,减少NN启动时间
- 根据配置文件设置的时间间隔fs.checkpoint.period默认3600秒
- 根据配置文件设置edits log大小fs.checkpoint.size规定edits文件的最大值默认是64MB
(1.x无Ha模式,2.x开始有Ha模式,Ha模式下2个NameNode,NameNode的个数与版本没有任何关系)
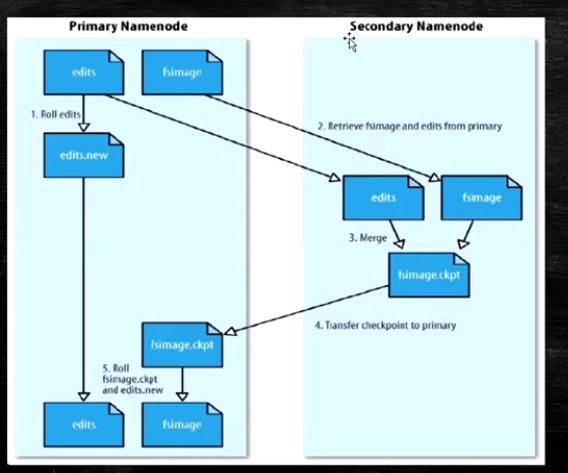
SecondaryNameNode功能图
服务器科普:

塔式服务器(Tower servers )

机架服务器(Rack server )

刀片服务器(blade Server)
关于服务器选择,PC一般选择塔式服务器。机架服务器一般用于公司,公司中使用多台机架服务器进行叠加,使用交换机来进行交换讯息。刀片服务器最贵,用于大型企业或者特殊服务
副本放置策略
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点
- 第二个副本:放在于第一个副本不同的机架的节点
- 第三个副本:与第二个副本相同机架的节点
- 更多副本:随机节点

HDFS的读写流程
HDFS的写流程

- Client和NN连接创建文件元数据
- NN判定元数据是否有效
- NN触发副本放置策略,返回一个有序的DN列表
- Client和DN简历Pipeline连接
- Client将块分成packet(64KB),并使用chunk(512B)
- Client将packet发送队列dataqueue中,并向第一个DN发送
- 第一个DN收到packet后本地保存发送给第二个DN
- 第二个DN收到packet后本地保存并发给第三个DN
- 这个过程中,上游节点同时同时发送下一个packet
- 类似工厂流水线
- HDFS使用这种传输方式,副本数对于Client是透明的
- 当block传输完成,DN分别向各自的NN汇报,同时Client继续传输下一个blcok
- 所以client传输和block汇报也是并行的
HDFS读流程
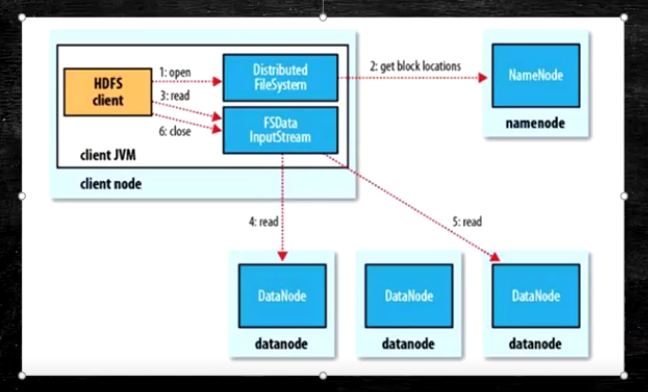
- 为了降低整体的带宽消耗和读延迟,HDFS会尽量让读取程序读取离他最近的副本
- 如果再读取程序的同一个机架上有一个副本,那么就读该副本
- 如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本
- 语义:
- download a file
- Client和NN交互文件元数据获取fileBlockLocation
- NN按距离策略排序返回
- Client尝试下载Block并且校验数据完整性(校验盒校验)
- 语义:下载一个文件其实是获取文件的所有的Block元数据,那么子集获取block应该成立
- Hdfs支持Client输出文件的offset自定义连接哪些Block的DN,自定义获取数据
- 这个是支持计算层的分治,并行计算的核心(牢记)
Big Data(二)分布式文件系统那么多,为什么hadoop还需要一个hdfs文件系统?的更多相关文章
- hadoop(三)HDFS 文件系统
Hadoop 附带了一个名为 HDFS(Hadoop 分布式文件系统)的分布式文件系统,专门 存储超大数据文件,为整个 Hadoop 生态圈提供了基础的存储服务. 本章内容: 1) HDFS 文件系统 ...
- Hadoop Java API操作HDFS文件系统(Mac)
1.下载Hadoop的压缩包 tar.gz https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/ 2.关联jar包 在 ...
- [原创] hadoop学习笔记:重新格式化HDFS文件系统
所谓的重新格式化HDFS文件系统,实际意味着重新的创建一个HDFS文件系统.也就是说,必须将先前的已经有的文件系统配置删除.如下: 笔者采用的是最小化安装 这个是core-site.xml配置 这个是 ...
- 使用 /proc 文件系统来访问 linux操作系统 内核的内容 && 虚拟文件系统vfs及proc详解
http://blog.163.com/he_junwei/blog/static/19793764620152743325659/ http://www.01yun.com/other/201304 ...
- HDFS文件系统基本文件命令、编程读写HDFS
基本文件命令: 格式为:hadoop fs -cmd <args> cmd的命名通常与unix对应的命令名相同.例如,文件列表命令: hadoop fs -ls 1.添加目录和文件 HDF ...
- CYQ.Data V5 分布式自动化缓存设计介绍(二)
前言: 最近一段时间,开始了<IT连>创业,所以精力和写的文章多数是在分享创业的过程. 而关于本人三大框架CYQ.Data.Aries.Taurus.MVC的相关文章,基本都很少写了. 但 ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- HDFS之二:HDFS文件系统JavaAPI接口
HDFS是存取数据的分布式文件系统,HDFS文件操作常有两种方式,一种是命令行方式,即Hadoop提供了一套与Linux文件命令类似的命令行工具.HDFS操作之一:hdfs命令行操作 另一种是Java ...
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
随机推荐
- 查看Linux基本系统信息
#! /bin/bash #The scripts will return the system infomation #return hostname and version infomation ...
- P2010 回文日期
P2010 回文日期 题解 回文日期,一共8位,只需要枚举4位就好了其实,然后判断它是否合法 代码 #include<bits/stdc++.h> using namespace std; ...
- IDEA全局配置
进入全局设置界面: 取消每次启动IDEA就默认打开上一次最后关闭的项目 编译器代码字体设置: 控制台字体大小和颜色设置 同一个文件代码里面的各个不同方法之间显示分割线 代码自动提示不区分大小写 格式化 ...
- c#端口扫描器wpf+socket
布局如下 <Window x:Class="PortTest.MainWindow" xmlns="http://schemas.microsoft.com/win ...
- Computer Network Homework3’ s hard question
Computer Network Homework3’ s hard question 1. Which kind of protocol does CSMA belong to? A. Random ...
- ControlTemplate in WPF —— ComboBox
<ResourceDictionary xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" x ...
- Linux 常用命令之 mv cp scp
1.mv 命令是move的缩写,用于文件(或文件夹)移动的. 1)将 luna 目录下的文件 a.txt,移动到 miracle 目录下: mv ./luna/a.txt ./miracle/ 2)将 ...
- matlab2012a过期问题解决办法(转载)
转载:http://blog.sina.com.cn/s/blog_4a46812b0102x694.html 以前安装过Matlab2013a等高版本,发现自己win7 系统每次重启后,Matl ...
- 使用var提升变量声明
使用var 定义变量还会提升变量声明,即使用var定义:function hh(){ console.log(a); var a = 'hello world';}hh() //undefined 不 ...
- FPGA VGA时序的理解
最近在做FPGA毕业设计,毕业设计规划的是摄像头采集图像,经过均值滤波,中值滤波,高斯滤波,然后通过VGA接口控制显示器显示出来,所以最近学习了一下FPGA的VGA驱动的相关内容. VGA接口 如上图 ...