Pandas 50题练习
f行的age改为1.
df.loc['f', 'age'] = 1.5
这样比 df.loc['f']['age'] 好
计算df中每个种类animal的数量
df['animal'].value_counts()
我是 计算df中每个种类animal的数量
df.groupby('animal').count()
不好
将priority列中的yes, no替换为布尔值True, False
df['priority'] = df['priority'].map({'yes': True, 'no': False})
我的做法
df['priority'] = df['priority'].str.replace('no','false')
df['priority'] = df['priority'].str.replace('yes','true')
对每种animal的每种不同数量visits,计算平均age,即,返回一个表格,行是aniaml种类,列是visits数量,表格值是行动物种类列访客数量的平均年龄
df.pivot_table(index='animal', columns='visits', values='age', aggfunc='mean')
我的做法
res = df.groupby(by=['animal','visits'])['age'].mean() 这样是不行的
一个全数值DatraFrame,每个数字减去该行的平均数
df = pd.DataFrame(np.random.random(size=(, )))
print(df)
df1 = df.sub(df.mean(axis=), axis=)
print(df1)
我的做法
for i in range(len(df)):
for j in (df.columns):
df.loc[i,j] = df.loc[i,j] - df.loc[i].mean()
一个有5列的DataFrame,求哪一列的和最小
df = pd.DataFrame(np.random.random(size=(, )), columns=list('abcde'))
print(df)
df.sum().idxmin()
我的做法
df.sum().sort_values() 然后自己肉眼识别
给定DataFrame,求A列每个值的前3的B的值的和
df = pd.DataFrame({'A': list('aaabbcaabcccbbc'),
'B': [,,,,,,,,,,,,,,]})
print(df)
df1 = df.groupby('A')['B'].nlargest().sum(level=)
print(df1)
给定DataFrame,有列A, B,A的值在1-(含),对A列每10步长,求对应的B的和
df = pd.DataFrame({'A': [,,,,,,,,,],
'B': [,,,,,,,,,]})
print(df)
df1 = df.groupby(pd.cut(df['A'], np.arange(, , )))['B'].sum()
print(df1)
我的做法大体类似,但是稍微繁琐,对pd.groupby 理解不到位。groupby第一个参数也可以接收series或者dict,应用在dataframe的第一列值。
s = pd.cut(df['a'],bins=,labels=['one','two','three','four','five','six','seven','eight','nine','ten'])
df['label'] = s
df.groupby('label')['b'].sum()
一个全数值的DataFrame,返回最大3个值的坐标
df = pd.DataFrame(np.random.random(size=(, )))
print(df)
df.unstack().sort_values()[-:].index.tolist()
我的做法是取每个column的最大值,排序后再选最大的三个。很明显,繁琐。
注意,df必须先unstack后才能 sort_values,要不然会报错。
dti = pd.date_range(start='2015-01-01', end='2015-12-31', freq='B')
s = pd.Series(np.random.rand(len(dti)), index=dti)
s.head()
所有礼拜三的值求和
s[s.index.weekday == ].sum()
还有这种方法?!!
求每个自然月的平均数
s.resample('M').mean() 索引为时间序列的重要方法 resample 重采样
每连续4个月为一组,求最大值所在的日期
s.groupby(pd.Grouper(freq='4M')).idxmax() 我的做法
还有个pd.Grouper方法? FlightNumber列中有些值缺失了,他们本来应该是每一行增加10,填充缺失的数值,并且令数据类型为整数
df['FlightNumber'] = df['FlightNumber'].interpolate().astype(int) 我的做法
series,dataframe 都有 interpolate 这个方法,记一下 将From_To列从_分开,分成From, To两列,并删除原始列
temp = df.From_To.str.split('_', expand=True)
temp.columns = ['From', 'To']
df = df.join(temp)
df = df.drop('From_To', axis=) 我的做法
df['from'] = df['From_To'].str.split('_',expand=True)[]
df['to'] = df['From_To'].str.split('_',expand=True)[] 很明显,join更简洁,换个角度,如果列更多,我的方法就麻烦多了。
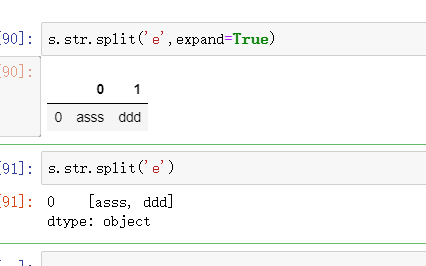
strip有个expand参数,很重要。python中的split 没有这个参数。
差别如下
Pandas 50题练习的更多相关文章
- POJ推荐50题
此文来自北京邮电大学ACM-ICPC集训队 此50题在本博客均有代码,可以在左侧的搜索框中搜索题号查看代码. 以下是原文: POJ推荐50题1.标记“难”和“稍难”的题目可以看看,思考一下,不做要求, ...
- JAVA经典算法50题(转)
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/51097928 JAVA经典算法50题 [程序1] 题目:古典问题:有一对兔子, ...
- 剑指offer 面试50题
面试50题: 题目:第一个只出现一次的字符 题:在一个字符串(1<=字符串长度<=10000,全部由字母组成)中找到第一个只出现一次的字符,并返回它的位置. 解题思路一:利用Python特 ...
- MySQL练习50题
介绍一个学习SQL的网站:https://sqlbolt.com/ 习题来源于网络,SQL语句是自己的练习答案,部分参考了网络上的答案. 花了一晚上的时间做完,个人认为其中的难点有:分组提取前几名的数 ...
- Java经典逻辑编程50题
Java经典逻辑编程50题 2016-11-03 09:29:28 0个评论 来源:Alias_fa的博客 收藏 我要投稿 [程序1] 題目:古典问题:有一对兔子,从出生后第 ...
- sql 经典查询50题 思路(一)
因为需要提高一下sql的查询能力,当然最快的方式就是做一些实际的题目了.选择了这个sql的50题,这次大概做了前10题左右,把思路放上来,也是一个总结. 具体题目见: https://zhuanlan ...
- 转:sql 经典50题--可能是你见过的最全解析
题记:从知乎上看到的一篇文章,刚好最近工作中发现遇到的题目与这个几乎一样,可能就是从这里来的吧.^_^ 里面的答案没有细看,SQL求解重在思路,很多时候同一种结果可能有多种写法,比如题中的各科成绩取前 ...
- 力扣50题 Pow(x,n)
本题是力扣网第50题. 实现 pow(x, n) ,即计算 x 的 n 次幂函数. 采用递归和非递归思路python实现. class Solution: #递归思路 def myPow_recurs ...
- sql语句练习50题(Mysql版-详加注释)
表名和字段 1.学生表 Student(s_id,s_name,s_birth,s_sex) --学生编号,学生姓名, 出生年月,学生性别 2.课程表 Course(c_id, ...
随机推荐
- C++ 中头文件<bits/stdc++.h>的优缺点
在编程竞赛中,我们常见一个头文件: #include <bits/stdc++.h> 发现它是部分C++中支持的一个几乎万能的头文件,包含所有的可用到的C++库函数,如<istrea ...
- 02-Django-views
# views 视图# 1. 视图概述- 视图即视图函数,接收web请求并返回web响应的事物处理函数.- 响应指符合http协议要求的任何内容,包括json,string, html等 # 2 其他 ...
- Codeforces 940 区间DP单调队列优化
A #include <bits/stdc++.h> #define PI acos(-1.0) #define mem(a,b) memset((a),b,sizeof(a)) #def ...
- JVM Direct Memory
JVM除了堆内存.栈内存,还有DirectMemory内存,DirectMemory是java nio引入的. 在JDK1.4中新加入了NIO(New INput/Output)类,引入了一种基于通道 ...
- Python(1) 整型与浮动型
整型与浮动型 整数/浮动数=浮点型整数/整数 = 浮点型 例如:>>> type(1/1)<class 'float'>>>> type(1/1.0)& ...
- 生成keystore
Android平台打包发布apk应用,需要使用数字证书(.keystore文件)进行签名,用于表明开发者身份,可以使用JRE环境中的keytool命令生成.以下是windows平台生成证书的方法: 安 ...
- kettle crontab java: command not found
contos6.5下,单独执行脚本无问题,添加到crontab 里保存 java: command not found ※(重点)接着,编写执行kettle任务的shell脚本创建test.sh,将以 ...
- 解决git 命令出现end问题
当使用git branch -r是当分支有很多的时候出现end 使用:q可以退出
- linux运维、架构之路-python2.6升级3.6
一.环境 1.系统 [root@m01 ~]# cat /etc/redhat-release CentOS release 6.9 (Final) [root@m01 ~]# uname -r -. ...
- 【rust】Rust变量绑定(3)
Rust 是一个静态类型语言,这意味着我们需要先确定我们需要的类型. 什么是变量绑定? 将一些值绑定到一个名字上,这样可以在之后使用他们. 如何声明一个绑定? 使用 let 关键字: fn main( ...