c语言基础学习03
=============================================================================
涉及到的知识点有:编码风格、c语言的数据类型、常量、计算机里面的进制、原码反码补码、int类型、整数的溢出、大端对齐与小端对齐、char类型(字符类型)、
浮点类型float \ double \ long double、类型限定、字符串格式化输出与输入、基本运算符、运算符的优先级、类型转换等。
=============================================================================
gcc -o a1.s -S a1.c gcc把c语言代码转换为汇编代码
-----------------------------------------------------------------------------
关于编码风格的说明:
int dog_name; linux编码风格
int dog_age;
int iDogName; 微软编码风格
int iDogAge;
编码一定要工整,这是初学者容易忽略的。
=============================================================================
C语言的数据类型:
1、常量:在此程序运行中不可变化的量(注意常量也是有类型的哦!)
第一种定义常量的方法:
#define MAX 100 这种定义常量的方法一般叫宏常量,所以有时也叫定义了一个宏,宏常量的常量名一般是大写字母。
第二种定义常量的方法:
const int max = 0; const常量,
一般区别:c语言里面用宏常量比较多,c++用const比较多。
-----------------------------------------------------------------------------
"你好" 字符串常量
500 500本身是整数常量
比如:
int a = 500;
500 = 0; //这句是错误的
=============================================================================
计算机里面的进制:
十进制 二进制 八进制 十六进制
0 0 0 0
1 1 1 1
2 10 2 2
3 11 3 3
4 100 4 4
5 101 5 5
6 110 6 6
7 111 7 7
8 1000 10 8
9 1001 11 9
10 1010 12 a
11 1011 13 b
12 1100 14 c
13 1101 15 d
14 1110 16 e
15 1111 17 f
16 10000 20 10
17 10001 21 11
-----------------------------------------------------------------------------
一个二进制的位就是一个bit(比特)
8个bit是一个BYTE(字节)
2个BYTE是一个WORD(字)
2个WORD是一个DWORD(双字)
1024个BYTE 是1KBYTE
1024K 是1M
1024M 是1G
1024G 是1T
1024T 是1P
1024P 是1E
1024E 是1Z
1024Z 是1Y
-----------------------------------------------------------------------------
512GB 硬盘(单位是字节)
12Mb 网络带宽(单位是比特)
200MB 文件的大小(单位是字节)
100Mb 网卡(单位是比特)
-----------------------------------------------------------------------------
进制之间的转换:
10101010111111010101011
把一个二进制数转化为10进制是很困难的,但是计算机使用的就是二进制。
从右到左起,每3个一组,不够的补零。
010 101 010 111 111 010 101 011 转化为8进制
2 5 2 7 7 2 5 3
从右到左起,每4个一组,不够的补零。
0101 0101 0111 1110 1010 1011 转化为16进制
5 5 7 e a b
二进制其实和8进制、16进制是一一对应的,在计算机语言中一般不直接用二进制,c语言更多的用8进制或者16进制
-----------------------------------------------------------------------------
把十进制的56转化为2进制
先把这个数转化为8进制,然后把8进制直接对应为2进制
用56除以8,分别取余数和商数
8 56
7 0
0 7
70 转化为8进制的结果
111 000 转化为2进制的结果
-----------------------------------------------------------------------------
16 100
6 4
0 6
64 转化为8进制的结果
0110 0100 转化为2进制的结果
-----------------------------------------------------------------------------
2 100
50 0
25 0
12 1
6 0
3 0
1 1
0 1
1100100 直接转化为2进制的结果
=============================================================================
这些数对于计算机来讲,他们是怎么放的呢??
1、原码
例如:7的二进制是多少?(即7的二进制原码如下)
111
0000 0111 用一个BYTE(字节)表示
0000 0000 0000 0111 用一个WORD(字)表示(即用2个字节来表示)
0000 0000 0000 0000 0000 0000 0000 0111 用一个DWORD(双字)表示(即用4个字节来表示)
那么 -7 该如何表示呢?原则是:最高位为符号位,符号位0代表正数,1代表负数
-7的二进制是多少?(即 -7 的二进制原码如下)
1000 0111 用一个BYTE(字节)表示
1000 0000 0000 0111 用一个WORD(字)表示(即用2个字节来表示)
1000 0000 0000 0000 0000 0000 0000 0111 用一个DWORD(双字)表示(即用4个字节来表示)
-----------------------------------------------------------------------------
2、反码:一个数若为正值,则反码和原码相同;一个数若为负值,则符号位为1,其余各位与原码相反。
7的反码
0000 0111 用一个BYTE(字节)表示
0000 0000 0000 0111 用一个WORD(字)表示(即用2个字节来表示)
0000 0000 0000 0000 0000 0000 0000 0111 用一个DWORD(双字)表示(即用4个字节来表示)
-7的反码
1111 1000 用一个BYTE(字节)表示
1111 1111 1111 1000 用一个WORD(字)表示(即用2个字节来表示)
1111 1111 1111 1111 1111 1111 1111 1000 用一个DWORD(双字)表示(即用4个字节来表示)
-----------------------------------------------------------------------------
3、补码:一个数若为正值,则补码和原码相同;一个数若为负值,则符号位为1,其余各位与原码相反,最后对整个数 +1 。
7的补码
0000 0111 用一个BYTE(字节)表示
0000 0000 0000 0111 用一个WORD(字)表示(即用2个字节来表示)
0000 0000 0000 0000 0000 0000 0000 0111 用一个DWORD(双字)表示(即用4个字节来表示)
-7的补码(在计算机内部,正数和负数都是以补码的方式存放的。又因为正数的补码是其本身,所以简言之:所有的负数都是以补码的方式存放的。好处是:用补码进行运算,得到补码,减法可以通过加法来实现,也即不用考虑符号位了!!)
1111 1001 用一个BYTE(字节)表示
1111 1111 1111 1001 用一个WORD(字)表示(即用2个字节来表示)
1111 1111 1111 1111 1111 1111 1111 1001 用一个DWORD(双字)表示(即用4个字节来表示)
-----------------------------------------------------------------------------
小例题:
知道补码如何求原码?答:符号位不变,先 -1 再取反即可;或者符号位不变,先取反,再 +1 也可以哦!
补码
1111 1111 1111 1111 1111 1111 1111 0101 如果是负数,是负几?
1000 0000 0000 0000 0000 0000 0000 1011
这个数是-11的补码。
=============================================================================
sizeof 关键字作用是:得到某一数据类型在内存中占用的大小,单位是:字节
sizeof 不是函数,所以不需要包含任何头文件
其实呢,sizeof返回值的类型是size_t,size_t类型在32位操作系统下是一个无符号的整数。
例如:
int a = 0;
int b = 0;
b = sizeof(a);//得到a在内存中占用的大小,单位是:字节
0000 0000 0000 0000 0000 0000 0000 0000 int a = 0;
0000 0000 0000 0000 0000 0000 0000 1010 int a = 10;
1111 1111 1111 1111 1111 1111 1111 0110 int a = -10;
-----------------------------------------------------------------------------
有符号数的最高位0代表正数,1代表负数;(即有正有负)
无符号数的最高位就是数的一部分,不是正负的意思(即无符号数只有正数)
例如:
有符号数的原码
0000 0000 0
0000 1000 8
1000 1000 -8
无符号数的原码
0000 0000 0
0000 1000 8
1000 1000 88(16进制的88)
-----------------------------------------------------------------------------
一个BYTE(字节)作为有符号数,最小是多少-128,最大是多少127
-128 -127 ...... -1 0 1 2 ...... 127
一个BYTE(字节)无符号数,最小是0,最大是255
0 1 2 ...... 254 255
-----------------------------------------------------------------------------
有符号数才区分原码补码,无符号数都是原码
=============================================================================
c语言从来不规定数据类型的大小,具体某种数据类型多大,和系统相关。
也即:在同一个系统下,具体的一种数据类型大小是相同的。
-----------------------------------------------------------------------------
变量:就是在程序运行中可以更改值的量
int a; //定义了一个变量
a = 0;
a = 2;
-----------------------------------------------------------------------------
如果直接写一个整数,默认是10进制的整数
20 表示10进制的20
020 表示8 进制的20
0x20 表示16进制的20
-----------------------------------------------------------------------------
%d 的意思是按照十进制的有符号整数输出
%u 的意思是按照十进制的无符号整数输出
%o 的意思是按照八进制的有符号整数输出
%x 的意思是按照十六进制的有符号整数输出(小写)
%X 的意思是按照十六进制的有符号整数输出(大写)
-----------------------------------------------------------------------------
例如:-11在内存中存放是以补码的形式存放的。-11的补码如下:
1111 1111 1111 1111 1111 1111 1111 0101
f f f f f f f 5
-11转换成十进制就是:4294967285
=============================================================================
signed int a; //定义了一个有符号的int(关键字signed一般不用写)
unsigned int b; //定义了一个无符号的int
long int 是长整型,在32位系统下是4个字节,在64位linux系统下是8个字节,在64位的windows系统下是4个字节。(大小是不稳定的)
long long int 是长长整型,在32位系统和64位系统下都是8个字节。(大小是稳定的)
unsigned short int 无符号的短整数类型(大小为2个BYTE(字节))
unsigned long int 无符号的长整数类型(大小是不稳定的)
unsigned long long int 无符号的长长整数类型(大小是稳定的)
-----------------------------------------------------------------------------
100 直接这样写表示是一个有符号的int
100u 直接这样写表示是一个无符号的int
100l 直接这样写表示是一个有符号的long
100ul 直接这样写表示是一个无符号的long
100ll 直接这样写表示是一个有符号的long long
100ull 直接这样写表示是一个无符号的long long
注意:在c语言中表达一个整数的常量,如果什么标示都不加,那么默认类型是signed int(有符号的int)
=============================================================================
整数的溢出:当超过一个整型能够存放最大的范围时,整数会溢出。
有两种溢出:
符号位溢出:该溢出会导致数的正负发生改变。
最高位溢出:该溢出会导致最高位的丢失。
-----------------------------------------------------------------------------
1、符号位溢出例子:该溢出会导致数的正负发生改变。
例如:
int a = 0x7fffffff;
a = a + 3;
printf("%d\n",a);
int(默认为有符号的int)
0111 1111 1111 1111 1111 1111 1111 1111
7 f f f f f f f
+1得到:
1000 0000 0000 0000 0000 0000 0000 0000
+2得到:
1000 0000 0000 0000 0000 0000 0000 0001
+3得到:(+3后该数变为负数了,而在计算机中,负数都是以补码的方式存放的,即该负数就是补码啦,那么知道补码求原码)
1000 0000 0000 0000 0000 0000 0000 0010
因为printf("%d\n",a);%d的意思是按照十进制的有符号整数输出的,即输出的是有符号的原码,
所以知道补码如何求原码?答:符号位不变,先取反,再 +1 即得;或者 符号位不变,先 -1 再取反也可以哦!
求得原码是:
1111 1111 1111 1111 1111 1111 1111 1110
7 f f f f f f e
则输出的结果是:-2147483646
-----------------------------------------------------------------------------
2、最高位溢出例子:该溢出会导致最高位的丢失。
例如:
int 6 = 0xffffffff;
b = b + 3;
printf("%u\n",b);
unsigned int(无符号的int)
1111 1111 1111 1111 1111 1111 1111 1111
1 0000 0000 0000 0000 0000 0000 0000 0000
1 0000 0000 0000 0000 0000 0000 0000 0001
1 0000 0000 0000 0000 0000 0000 0000 0010
因为printf("%u\n",b);%u的意思是按照十进制的无符号整数输出的,即输出的是无符号的原码,
原码是:
0000 0000 0000 0000 0000 0000 0000 0010 (把高位1丢掉了)
则输出的结果是:2
=============================================================================
大端对齐与小端对齐
计算机的内存最小单位是什么?是BYTE,是字节。
一个大于BYTE的数据类型在内存中存放的时候要有先后顺序。
高内存地址放整数的高位,低内存地址放整数的低位,这种方式叫倒着放,术语叫小端对齐。电脑X86和手机ARM都是小端对齐的。
高内存地址放整数的低位,低内存地址放整数的高位,这种方式叫正着放,术语叫大端对齐。很多Unix服务器的cpu都是大端对齐的。
如下图例子:(有个图片)
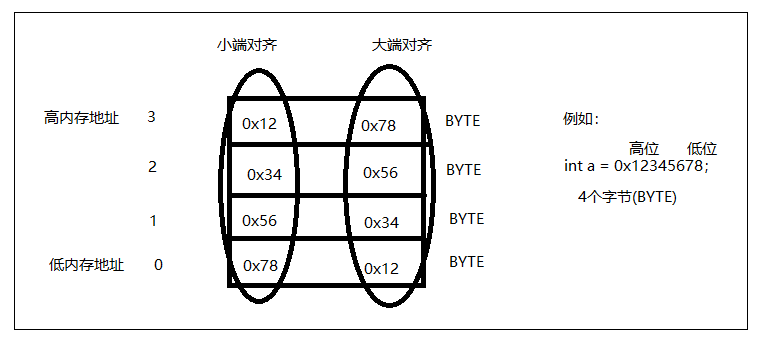
=============================================================================
char类型(字符类型)
单引号引起来的字符就是char常量
'a' 是一个字符类型的常量a,'a'其实指的是字符a的ASCII码,即所有的英文字符都是一个BYTE的整数,这个整数就是ASCII码。
"a" 是一个字符串类型的常量
'2' 这个是字符型的2,而不是数字2
-----------------------------------------------------------------------------
char a; //定义了一个字符类型的变量,名字叫a。
char a = 'a'; //等号左边是一个变量,名字叫a;右边是一个字符常量,就是字母a。
-----------------------------------------------------------------------------
本质问题,至关重要:
char的本质其实是一个整数,大小是一个BYTE(字节),在c语言中没有BYTE这种数据类型,用char替代。
-----------------------------------------------------------------------------
1 #include <stdio.h>
2
3 int main()
4 {
5 char a = 'a'; //等号左边是一个变量,名字叫a;右边是一个字符常量,就是字母a。
6 int i = sizeof(a);
7 printf("%d\n", i); //输出1
8 a = 4; //此时char是一个有符号的char,也即有符号的int(只是该int的大小为1个字节)
9 a = a + 5;
10 printf("%d\n", a); //输出9
11 a = 0x7f;
12 a += 3;
13 printf("%d\n", a); //输出-126
14 unsigned char b = 0xff; //此时char是一个无符号的char,也即无符号的int(只是该int的大小为1个字节)
15 b = b +2;
16 printf("%u\n", b); //输出1
17 a = 'B'; //把字符B的ASCII码赋值给了a。
18 printf("%d\n", a); //输出66
19 a = 'b'; //把字符b的ASCII码赋值给了a。
20 printf("%d\n", a); //输出98
21 a = 99;
22 printf("%c\n", a); //输出c c% 输出一个char类型的常量或者变量
23 return 0;
24 }
符号位溢出:该溢出会导致数的正负发生改变。
//此时char是一个有符号的char,也即有符号的int(只是该int的大小为1个字节)
7 f
0111 1111
先加1得:
1000 0000
再加1得:
1000 0001
再加1得:
1000 0010 得到的就是负数了,而负数就是补码,就是知补码,求原码?
求原码得:
1111 1101 +1 得 1111 1110 输出的是:-126
最高位溢出:该溢出会导致最高位的丢失。
//此时char是一个无符号的char,也即无符号的int(只是该int的大小为1个字节)
f f
1111 1111
先加1得:
1 0000 0000
再加1得:
1 0000 0001 得到1;因为一个char最大能放8个比特(bit),从左往右
-----------------------------------------------------------------------------
signed char min:-128 ~ max:127
unsigned char min: 0 ~ max:255
-----------------------------------------------------------------------------
键盘的ASCII很多,有些ASCII没法输入,比如退格效果(Backspace)怎么输入呢?用转义字符 \ 例如:
char a = 'a'; //等号左边是一个变量,名字叫a;右边是一个字符常量,就是字母a。
printf("hello world");
a = '\b'; //'\b'表示一个退格的ASCII
printf("%c",a); //输出结果为:hello worl
printf("%c%c",a,a); //输出结果为:hello wor
不可打印的字符(char)如下:
\a 警报
\b 退格
\n 换行
\r 回车
\t 制表符
\\ 斜杠
\' 单引号
\" 双引号
\? 问号
=============================================================================
浮点类型:float、double、long double
char、short、int、long、long long这些类型都是存放整型,但这些类型无法处理小数
浮点类型 Linux系统下大小 windows系统下大小
float 4个字节 4个字节
double 8个字节 8个字节
long double 16个字节 12个字节
long 8个字节 4个字节
%f %lf 用来输出一个浮点数,不能用输出整型的转移符来输出一个浮点数
-----------------------------------------------------------------------------
小练习:
一个浮点数变量,小数点后面有一位
例如:
3.5
3.7
2.8
1.1
核心代码:
double a = 4.5
int b = a + 0.5;
a = b;
printf("%lf\n", a); //输出的时候要四舍五入,例如4.5输出5.000000
=============================================================================
类型限定:
const 是定义一个常量,不可以被改变的
volatile 代表定义一个变量,这个变量可能在cpu指令之外被改变
volatile int a; //定义了一个volatile类型的int变量,通过volatile定义的变量,编译器不会自作聪明的去优化这个变量相关的代码。
register int a; //定义了一个变量,是寄存器变量。建议把一个变量放入cpu的寄存器可以提升程序的运行效率。
//register是建议型指令,而不是命令型指令,如果cpu有空闲寄存器,那么register就生效,如果没有空闲寄存器,那么register无效。
例如: int b = 0; register b = 0;
b = b + 1; b = b + 1;
mov b, 0 mov eax, 0
mov eax, b add eax, 1
add eax 1
mov b, eax
=============================================================================
字符串格式化输出和输入:
字符串在计算机内部的存储方式:字符串是内存中一段连续的char空间,以 \0 结尾。
'a' 在内存里就是一个字符a
"a" 在内存里是两个连续的字符,第一个是'a',第二个是'\0'
"hello world" 相当于 'h' 'e' ....... 'd' '\0'
-----------------------------------------------------------------------------
1、字符串格式化输出:
putchar 一次只能输出一个char
例如:
putchar(100); //输出的是ASCII d
putchar('a'); //输出的是 a
putchar(\n'); //输出的是 换行
printf 一次只能输出一个字符串
例如:
printf("hello world\n"); //输出的是 hello world
int a = 100;
printf(a); //这样是错误的,应该如下:
int a = 100;
printf("%d\n", a);
-----------------------------------------------------------------------------
printf的格式:
对应的数据类型: 含义:
%d int 输出一个十进制的有符号的整数
%hd short int 输出有符号的短整数
%hu unsigned short int 输出无符号的短整数
%o unsigned int 输出无符号的8进制整数
%u unsigned int 输出无符号的10进制整数
%x unsigned int 输出无符号的16进制整数(abcdef)
%X unsigned int 输出无符号的16进制整数(ABCDEF)
%f float或者double 输出单精度浮点数/双精度浮点数
%e/E double 输出科学计数法表示的数
%c char 可以把输入的数字按照ASCII相应转换为对应的字符
%s char * 输出字符串中的字符直至字符串中的空字符(字符串以'\0'结尾,这个'\0'即是空字符)
%S wchar t *
%p void * 以16进制形式输出指针
%% % 输出一个百分号
例如: printf("%p\n", &a); //&a 的意思是:取变量a在内存中的地址(输出地址用 %p)
-----------------------------------------------------------------------------
printf的附加格式:
%l ld、lu、lo、lx 表示长整数
%m 表示输出数据的最小宽度,默认为右对齐
%- 左对齐
%0 将输出的前面补上0,直到占满指定列宽为止(不可以搭配使用 - 哦)
例如:
long int 用%ld
long long int 用%lld
例如:
printf("(%6d)\n", a); //输出的是:( 100)
printf("(%-6d)\n", a); //输出的是:(100 )
printf("(%06d)\n", a); //输出的是:(000100)
-----------------------------------------------------------------------------
2、字符串格式化输入:
getchar 函数:是从标准输入设备读取到一个char。需要包含头文件stdio.h,返回值是一个int,不需要传入参数。
scanf 函数:通过%d转义的方式可以得到用户通过标准输入设备输入的整数。
例如:
int a = getchar();
printf("%d\n", a); //输出对应的一个字符的ASCII,假如键盘输入a,则输出97
例如:
int a;
scanf("%d", &a); //特别注意:第二个参数是变量的地址,而不是变量本身
printf("%d\n", a); //假如键盘输入300,则输出300
=============================================================================
VS2013的C4996错误解决方法?
由于微软在VS2013中不建议再使用c的传统库函数scanf,strcpy,sprintf等,
所以直接使用这些库函数会提示C4996错误,在源文件中添加以下指令就可以避免这个错误提示:
法一:
#define _CRT_SECURE_NO_WARNINGS
把这个宏定义一定要放到.c文件的第一行
法二:
在主函数任意一行加上
#pragma warning(disable:4996)
如下图所示:

=============================================================================
基本运算符
% 取余运算
int a = 7 % 2;
printf("%d\n", a); //输出的是:1
-----------------------------------------------------------------------------
a += 3; //相当于 a = a + 3;
a -= 3; //相当于 a = a - 3;
a *= 3; //相当于 a = a * 3;
a /= 3; //相当于 a = a / 3;
-----------------------------------------------------------------------------
a++; //相当于a += 1;或者a = a + 1;
a--; //相当于a -= 1;或者a = a - 1;
b = a++; //先计算表达式的值,即先把a赋值给了b;然后a再自加1。
b = ++a; //先a自加1后;然后把a自加后得到的赋值给b。
小结:谁在前面先计算谁!!!
例如:
int a = 3;
int b = a++; //先计算表达式的值,即先把a的赋值给了b(b = a = 3);然后a再自加1(a = a + 1)。
printf("%d. %d\n",a, b); //输出的是:4,3
int a = 3;
int b = ++a; //先a自加1得a = 4(a = a + 1),再把a的赋值给了b(b = a = 4)
printf("%d. %d\n",a, b); //输出的是:4,4
-----------------------------------------------------------------------------
不同厂家的编译器会有不同的结果:
在gcc的编译下:
int a = 3;
int b = ++a + a++; //输出的是:5,9
int b = a++ + ++a; //输出的是:5,8
printf("%d. %d\n",a, b);
在VS2013的编译下:
int a = 3;
int b = ++a + a++; //输出的是:5,8
int b = a++ + ++a; //输出的是:5,8
printf("%d. %d\n",a, b);
-----------------------------------------------------------------------------
逗号运算符:先计算逗号左边的值,再计算逗号右边的值,但整个语句的值是逗号右边的值。
(为什么呢?要注意先计算逗号左边的值是否对计算逗号右边的值有影响)
例如:
int a = 2;
int b = 3;
int c = 4;
int d = 5;
int i = (a = b, c + d); //得到i的值为:9
int a = 2;
int b = 3;
int c = 4;
int d = 5;
int i = (a = b, a + d); //得到i的值为:8
-----------------------------------------------------------------------------
运算符的优先级
优先级编号 运算符 优先级一样时:
1(优先级高) []数组下标、()圆括号、()调用函数、{}语句块 从左到右运算
2 ++、--、+前缀、-前缀、!前缀、~前缀、sizeof、
*取指针值、&取地址值、(type)类型转换 从右到左运算(注意)
3 *、/、%取余 从左到右运算
4 +、- 从左到右运算
5 <<、>> 从左到右运算
6 <、>、<=、>= 从左到右运算
7 ==、!= 从左到右运算
8 & 从左到右运算
9 ^ 从左到右运算
10 | 从左到右运算
11 && 从左到右运算
12 || 从左到右运算
13 ? 从右到左运算(注意)
14 =、*=、%=、+=、-=、<<=、>>=、&=、|=、^= 从右到左运算(注意)
15(优先级低) ,逗号运算符 从左到右运算
注意:如果不能确定优先级,或者要改变默认的优先级,用()小括号。
-----------------------------------------------------------------------------
类型转换
double f = (double)5/2; //强制转换,把int的5强转为double类型的5.000000,输出是:2.500000
double f = (double)(5/2); //强制转换,把int的5/int的2的结果强转为double类型,输出是:2.000000
c语言约定:
1、两个整数计算的结果也是一个整数
2、浮点数与整数计算的结果是浮点数,浮点数和浮点数计算的结果还是浮点数
=============================================================================
c语言基础学习03的更多相关文章
- D03——C语言基础学习PYTHON
C语言基础学习PYTHON——基础学习D03 20180804内容纲要: 1 函数的基本概念 2 函数的参数 3 函数的全局变量与局部变量 4 函数的返回值 5 递归函数 6 高阶函数 7 匿名函数 ...
- Golang 汇编asm语言基础学习
Golang 汇编asm语言基础学习 一.CPU 基础知识 cpu 内部结构 cpu 内部主要是由寄存器.控制器.运算器和时钟四个部分组成. 寄存器:用来暂时存放指令.数据等对象.它是一个更快的内存. ...
- D02-R语言基础学习
R语言基础学习——D02 20190423内容纲要: 1.前言 2.向量操作 (1)常规操作 (2)不定长向量计算 (3)序列 (4)向量的删除与保留 3.列表详解 (1)列表的索引 (2)列表得元素 ...
- D01-R语言基础学习
R语言基础学习——D01 20190410内容纲要: 1.R的下载与安装 2.R包的安装与使用方法 (1)查看已安装的包 (2)查看是否安装过包 (3)安装包 (4)更新包 3.结果的重用 4.R处理 ...
- D03-R语言基础学习
R语言基础学习——D03 20190423内容纲要: 1.导入数据 (1)从键盘输入 (2)从文本文件导入 (3)从excel文件导入 2.用户自定义函数 3.R访问MySQL数据库 (1)安装R ...
- go语言基础学习
go基础学习,面向对象-方法在Go语言中,可以给任意自定义类型(包括内置类型,但不包括指针类型)添加相应的方法 使用= 和:=的区别: // = 使用必须使用先var声明例如: var a a=100 ...
- C# 语言基础学习路线图
一直以来,对于很多知识点都是存于收藏夹中,随着时间地变更,收藏夹中链接也起来越多,从未进行整理,也很零散,所以想对曾经遇到并使用过的一些知识形成文档,作为个人知识库的一部分. 就从C# 语言基础开始, ...
- C语言基础学习基本数据类型-变量的命名
变量的命名 变量命名规则是为了增强代码的可读性和容易维护性.以下为C语言必须遵守的变量命名规则: 1. 变量名只能是字母(A-Z,a-z),数字(0-9)或者下划线(_)组成. 2. 变量名第一个字母 ...
- java基础学习03(java基础程序设计)
java基础程序设计 一.完成的目标 1. 掌握java中的数据类型划分 2. 8种基本数据类型的使用及数据类型转换 3. 位运算.运算符.表达式 4. 判断.循环语句的使用 5. break和con ...
随机推荐
- android测试
1.测试是否知道源代码: --黑盒测试 不知道代码 --白盒测试 知道源代码 2.按照测试粒度: --方法测试 --单元测试 Junit测试 --集成测试 --系统测试 3.按照测试暴力程度 --冒烟 ...
- nginx php上传配置
.file_uploads 设为On,允许通过HTTP上传文件 2.upload_tmp_dir 文件上传至服务器时用于临时存储的目录,如果没指定,系统会使用默认的临时文件夹(我的机器是/tmp). ...
- 用原生实现点击删除点击的li
简单的实现方式 <!DOCTYPE html> <html> <head> <title></title> <meta charset ...
- ntopng 推送solr
1.修改代码在且不说 2.修改完之后先卸载原先的ntopng 使用 whereis ntopng 找到安装目录,然后删除 /usr/local/bin/ntopng /usr/local/share/ ...
- 关于md5的使用方法
本周工作,学习中用到了,md5. 在我们需要用到md5密码的时候,可以使用: System.Web.Security.FormsAuthentication.HashPasswordForStorin ...
- node 使用koa2 异步读文件
目的:在一个文件夹(image)中有很多文件夹和文件,排除掉文件,将所有文件夹找出来 知识点: async 函数与 await .只有在async函数内部,才能使用await,await等的必须是p ...
- 通过ArcMap发布服务
打开ArcMap,添加一个空地图 单击添加数据按钮 单击之后出现下图 点击 (连接到文件夹)按钮选择要添加的文件.添加之后如下. 保存为mxd文件 点击保存按钮就可以保存为mxd格式文件. 选择 Fi ...
- J2EE 项目本地发布路径及修改
J2EE的项目Run on Server后,在tomcat安装目录下的webapps没有出现所建立的工程名字. 很明显项目并没有自动部署到tomcat的webapps中而是部署在了别的容器中. 在内置 ...
- 前端MVC Vue2学习总结(七)——ES6与Module模块化、Vue-cli脚手架搭建、开发、发布项目与综合示例
使用vue-cli可以规范项目,提高开发效率,但是使用vue-cli时需要一些ECMAScript6的知识,特别是ES6中的模块管理内容,本章先介绍ES6中的基础与模块化的内容再使用vue-cli开发 ...
- JavaScript时间处理插件
摘要:代码返回的有两种时间格式 一种是/// 另外一种是---分割的 两个接收参数的说明 timestr 是接收的时间 mark是格式 默认返回的格式是/// 加上- 返回的格式是- ...