离散型特征编码方式:one-hot与哑变量
在机器学习问题中,我们通过训练数据集学习得到的其实就是一组模型的参数,然后通过学习得到的参数确定模型的表示,最后用这个模型再去进行我们后续的预测分类等工作。在模型训练过程中,我们会对训练数据集进行抽象、抽取大量特征,这些特征中有离散型特征也有连续型特征。若此时你使用的模型是简单模型(如LR),那么通常我们会对连续型特征进行离散化操作,然后再对离散的特征,进行one-hot编码或哑变量编码。这样的操作通常会使得我们模型具有较强的非线性能力。那么这两种编码方式是如何进行的呢?它们之间是否有联系?又有什么样的区别?是如何提升模型的非线性能力的呢?下面我们一一介绍:
one-hot encoding
关于one-hot编码的具体介绍,可以参考我之前的一篇博客,博客地址:特征提取方法: one-hot 和 IF-IDF。这里,不再详细介绍。one-hot的基本思想:将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。举个例子,假设我们以学历为例,我们想要研究的类别为小学、中学、大学、硕士、博士五种类别,我们使用one-hot对其编码就会得到:

dummy encoding
哑变量编码直观的解释就是任意的将一个状态位去除。还是拿上面的例子来说,我们用4个状态位就足够反应上述5个类别的信息,也就是我们仅仅使用前四个状态位 [0,0,0,0] 就可以表达博士了。只是因为对于一个我们研究的样本,他已不是小学生、也不是中学生、也不是大学生、又不是研究生,那么我们就可以默认他是博士,是不是。(额,当然他现实生活也可能上幼儿园,但是我们统计的样本中他并不是,^-^)。所以,我们用哑变量编码可以将上述5类表示成:

one-hot编码和dummy编码:区别与联系
通过上面的例子,我们可以看出它们的“思想路线”是相同的,只是哑变量编码觉得one-hot编码太罗嗦了(一些很明显的事实还说的这么清楚),所以它就很那么很明显的东西省去了。这种简化不能说到底好不好,这要看使用的场景。下面我们以一个例子来说明:
假设我们现在获得了一个模型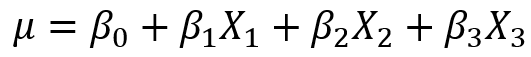 ,这里自变量满足
,这里自变量满足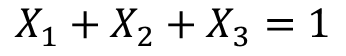 (因为特征是one-hot获得的,所有只有一个状态位为1,其他都为了0,所以它们加和总是等于1),故我们可以用
(因为特征是one-hot获得的,所有只有一个状态位为1,其他都为了0,所以它们加和总是等于1),故我们可以用 表示第三个特征,将其带入模型中,得到:
表示第三个特征,将其带入模型中,得到:
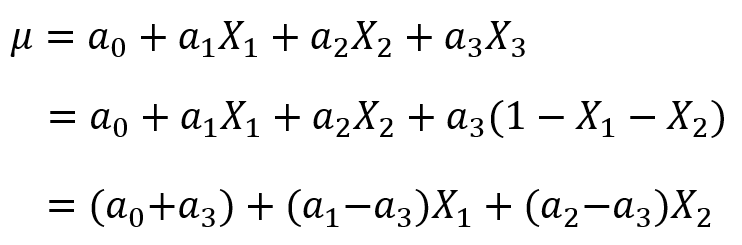
这时,我们就惊奇的发现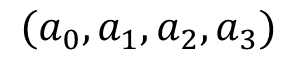 和
和 这两个参数是等价的!那么我们模型的稳定性就成了一个待解决的问题。这个问题这么解决呢?有三种方法:
这两个参数是等价的!那么我们模型的稳定性就成了一个待解决的问题。这个问题这么解决呢?有三种方法:
(1)使用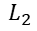 正则化手段,将参数的选择上加一个限制,就是选择参数元素值小的那个作为最终参数,这样我们得到的参数就唯一了,模型也就稳定了。
正则化手段,将参数的选择上加一个限制,就是选择参数元素值小的那个作为最终参数,这样我们得到的参数就唯一了,模型也就稳定了。
(2)把偏置项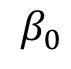 去掉,这时我们发现也可以解决同一个模型参数等价的问题。
去掉,这时我们发现也可以解决同一个模型参数等价的问题。
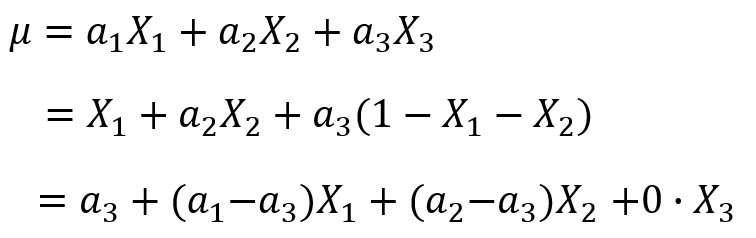
因为有了bias项,所以和我们去掉bias项的模型是完全不同的模型,不存在参数等价的问题。
(3)再加上bias项的前提下,使用哑变量编码代替one-hot编码,这时去除了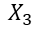 ,也就不存在之前一种特征可以用其他特征表示的问题了。
,也就不存在之前一种特征可以用其他特征表示的问题了。
总结:我们使用one-hot编码时,通常我们的模型不加bias项 或者 加上bias项然后使用正则化手段去约束参数;当我们使用哑变量编码时,通常我们的模型都会加bias项,因为不加bias项会导致固有属性的丢失。
选择建议:我感觉最好是选择正则化 + one-hot编码;哑变量编码也可以使用,不过最好选择前者。虽然哑变量可以去除one-hot编码的冗余信息,但是因为每个离散型特征各个取值的地位都是对等的,随意取舍未免来的太随意。
连续值的离散化为什么会提升模型的非线性能力?
简单的说,使用连续变量的LR模型,模型表示为公式(1),而使用了one-hot或哑变量编码后的模型表示为公式(2)
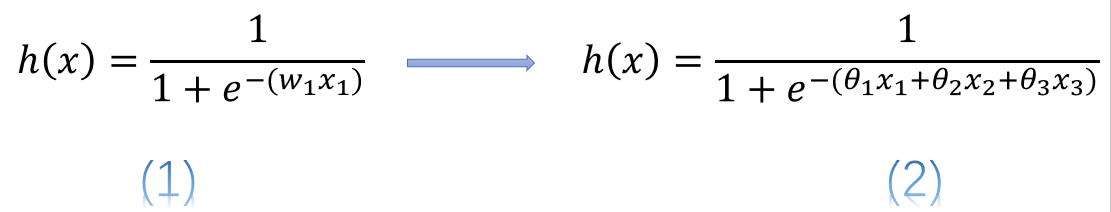
式中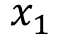 表示连续型特征,
表示连续型特征,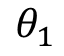 、
、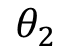 、
、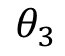 分别是离散化后在使用one-hot或哑变量编码后的若干个特征表示。这时我们发现使用连续值的LR模型用一个权值去管理该特征,而one-hot后有三个权值管理了这个特征,这样使得参数管理的更加精细,所以这样拓展了LR模型的非线性能力。
分别是离散化后在使用one-hot或哑变量编码后的若干个特征表示。这时我们发现使用连续值的LR模型用一个权值去管理该特征,而one-hot后有三个权值管理了这个特征,这样使得参数管理的更加精细,所以这样拓展了LR模型的非线性能力。
这样做除了增强了模型的非线性能力外,还有什么好处呢?这样做了我们至少不用再去对变量进行归一化,也可以加速参数的更新速度;再者使得一个很大权值管理一个特征,拆分成了许多小的权值管理这个特征多个表示,这样做降低了特征值扰动对模型为稳定性影响,也降低了异常数据对模型的影响,进而使得模型具有更好的鲁棒性。
离散型特征编码方式:one-hot与哑变量的更多相关文章
- 【彩票】彩票预测算法(一):离散型马尔可夫链模型C#实现
前言:彩票是一个坑,千万不要往里面跳.任何预测彩票的方法都不可能100%,都只能说比你盲目去买要多那么一些机会而已. 已经3个月没写博客了,因为业余时间一直在研究彩票,发现还是有很多乐趣,偶尔买买,娱 ...
- HotSpot关联规则算法(2)-- 挖掘连续型和离散型数据
本篇代码可在 http://download.csdn.net/detail/fansy1990/8502323下载. 前篇<HotSpot关联规则算法(1)-- 挖掘离散型数据>分析了离 ...
- 【年终分享】彩票数据预测算法(一):离散型马尔可夫链模型实现【附C#代码】
原文:[年终分享]彩票数据预测算法(一):离散型马尔可夫链模型实现[附C#代码] 前言:彩票是一个坑,千万不要往里面跳.任何预测彩票的方法都不可能100%,都只能说比你盲目去买要多那么一些机会而已. ...
- ROM型启动方式概述
ROM 型启动方式概述 所有的VxWorks 内核映像类型中,只有VxWorks 类型使用的bootrom 引导程序进行启动,此时VxWorks 内核映像放置在主机端,由目标板bootrom 完成Vx ...
- 处理离散型特征和连续型特征共存的情况 归一化 论述了对离散特征进行one-hot编码的意义
转发:https://blog.csdn.net/lujiandong1/article/details/49448051 处理离散型特征和连续型特征并存的情况,如何做归一化.参考博客进行了总结:ht ...
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- 含有分类变量(categorical variable)的逻辑回归(logistic regression)中虚拟变量(哑变量,dummy variable)的理解
版权声明:本文为博主原创文章,博客地址:,欢迎大家相互转载交流. 使用R语言做逻辑回归的时候,当自变量中有分类变量(大于两个)的时候,对于回归模型的结果有一点困惑,搜索相关知识发现不少人也有相同的疑问 ...
- one-hot encoding与哑变量的区别
one-hot encoding与哑变量的区别 one-hot比哑变量的特征位多一位,即哑变量是精简版的one-hot,即在线性回归中用截距项来表示最后一维,但由于最初很难分辨特征的主次关系,且机器学 ...
- 数据预处理 | 使用 OneHotEncoder 及 get_dummuies 将分类型数据转变成哑变量矩阵
[分类数据的处理] 问题: 在数据建模过程中,很多算法或算法实现包无法直接处理非数值型的变量,如 KMeans 算法基于距离的相似度计算,而字符串则无法直接计算距离 如: 性别中的男和女 [0,1] ...
随机推荐
- 转载 iOS拦截导航栏返回按钮事件的正确方式
原文链接:http://www.jianshu.com/p/25fd027916fa 当我们使用了系统的导航栏时,默认点击返回按钮是 pop 回上一个界面.但是在有时候,我们需要在点击导航栏的返回按钮 ...
- program 1 : python codes for login program(登录程序python代码)
#improt time module for count down puase time import time #set var for loop counting counter=1 #logi ...
- JSP入门 Listener
实现HttpSessionListener 编写一个OnlineUserListener类 package anni; import java.util.List; import javax.serv ...
- 洗礼灵魂,修炼python(7)--元组,集合,不可变集合
前面已经把列表的基本用法讲解完 接着讲python的几大核心之--元组(tuple) 1.什么是元组? 类似列表,但为不可变对象,之前提到列表是可变对象,所谓可变对象就是支持原处修改,并且在修改前后对 ...
- Codeforces Round #425 (Div. 2)C
题目连接:http://codeforces.com/contest/832/problem/C C. Strange Radiation time limit per test 3 seconds ...
- nodejs+express+mongoose无法获取数据库数据问题解决
通过mongoose与mongodb进行操作.而mongoose是通过model来创建mongodb中对应的collection的,这样你通过如下的代码: mongoose.model('User', ...
- Java历程-初学篇 Day09 冒泡排序
冒泡排序 冒泡排序(Bubble Sort)是一种简单的排序算法.它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.走访数列的工作是重复地进行直到没有再需要交换,也就是 ...
- 学习如何看懂SQL Server执行计划(一)——数据查询篇
一.数据查询部分 1. 看到执行计划有两种方式,对sql语句按Ctrl+L,或按Ctrl+M打开显示执行计划窗口每次执行sql都会显示出相应的执行计划 2. 执行计划的图表是从右向左看的 3. SQL ...
- 使用HDFS客户端java api读取hadoop集群上的信息
本文介绍使用hdfs java api的配置方法. 1.先解决依赖,pom <dependency> <groupId>org.apache.hadoop</groupI ...
- 2017年十大奇葩画风的H5页面案例,原来脑洞可以这样大
每个人都是视觉动物,画面精美.体验奇特的H5,用户在内心一般都会满分打出,毫不吝啬,同时也毫不犹豫分享,因为此时的分享不掉价儿~ 今天给大家准备了十支H5,画风超级奇特,非常值得一看所有案例均可在19 ...