机器学习——kNN(1)基本原理
=================================版权声明=================================
版权声明:原创文章 禁止转载
请通过右侧公告中的“联系邮箱(wlsandwho@foxmail.com)”联系我
勿用于学术性引用。
勿用于商业出版、商业印刷、商业引用以及其他商业用途。
本文不定期修正完善。
本文链接:http://www.cnblogs.com/wlsandwho/p/7512119.html
耻辱墙:http://www.cnblogs.com/wlsandwho/p/4206472.html
=======================================================================
很显然我没有足够的巩俐,啊功力去讲解机器学习的大道理,但是我愿意把我的读书笔记分享出来。
当然,我保留版权。
=======================================================================
关于kNN算法的伪代码描述,我这里得写一下,因为《机器学习实践》这本书里写的不是很清楚。(当然我的用词更通俗,毕竟不能照抄原文啊:)
1 计算目标点与数据集中每个点的距离。
这个求距离的算法应当是根据实际情况具体问题具体分析采取的。书中使用的是欧几里德几何体系里的两点之间的距离。对,就是初中学的那个。
2 对距离的结果按照从小到大的顺序排序。
这里要记录哪个结果是由哪个点产生的。总不能排序之后结果排序了,但是对应点找不到了吧?
3 从结果中取前k个点。
kNN算法之所以叫kNN算法,是因为它选取了前k个点。
4 记录这k个点对应类别的频率。
比方说在这k个点中,a类出现了5次,b类出现了2次,c类出现了7次
5 取出现频率最高的类别作为结果。
通俗地讲,就是发现跟a有5成像,跟b有2成像,跟c有7成像。当然是选最像的啦。
=======================================================================
话是这么说,看起来也很简单。但是用指定的编程语言实现,就得看对于该语言的熟练程度了。
比方说,我用C++写的话,比较麻烦的地方是矩阵运算,其他就很简单了。
但是用Python的话,我需要熟悉相关的类库和代码。
=======================================================================
对于我这种只看过《Python编程:从入门到实践》的人来说,看《机器学习与实践》的代码还是要查资料的。
要理解下面的内容:
1 tile(x,(m,n))
通俗的说就是把指定的块x,按行复制m次,按列复制n次。m和n是可以取0的,但这没有意义,因为把没有复制了0次,还是没有啊:)
为什么我说的是块x呢?因为这个x可以是一个数,也可以是一个矩阵。对,大学线性代数课程里对矩阵运算时,就是可以把某一部分看成一个子矩阵的。这个同理。
2 x.sum(axis=?)
手册上说,是垂直求和还是水平求和。
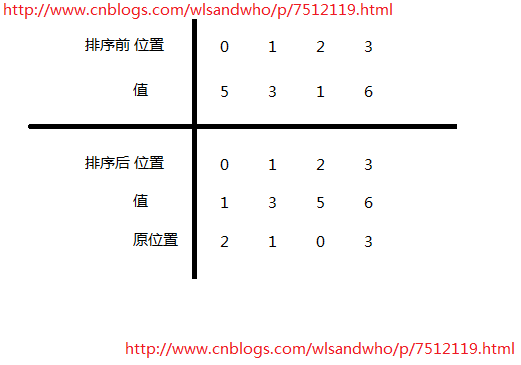
3 a.argsort()
这个得画个图。一图胜千言。输入5316,输出2103。
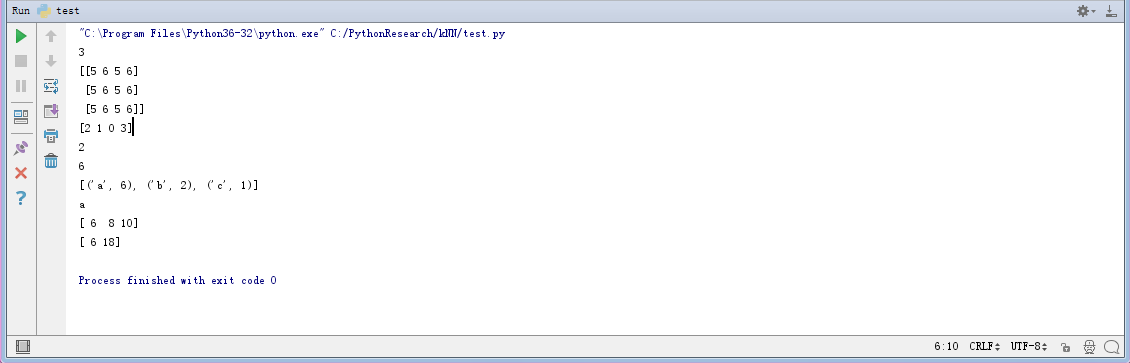
贴出示例小代码有助于理解。毕竟我们用事实说话。
from numpy import *
import operator r=array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
rows=r.shape[0]
print(rows) x=[5,6]
xxx=tile(x,(3,2))
print(xxx) a=array([5,3,1,6])
#1,3, 5, 6
#2,1, 0, 3
b=a.argsort()
print(b)
print(b[0]) c={}
c['c']=1
c["b"]=2
c["a"]=1
c["a"]=c.get('a')+5
print(c["a"]) d=sorted(c.items(),key=operator.itemgetter(1),reverse=True)
print(d)
print(d[0][0]) mm=array([[1,2,3],[5,6,7]])
print(mm.sum(axis=0))
print(mm.sum(axis=1))
=======================================================================
好了,可以贴我的kNN代码了。Python的风格不习惯,随手写了下。
from numpy import *
import operator def create_data_set():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=["A","A","B","B"] return group,labels def classify_kNN(dest,sample,labels,k):
rows=sample.shape[0]
dests=tile(dest,(rows,1))
res=(((dests-sample)**2).sum(axis=1))**0.5
resrank=res.argsort() clfy={} for i in range(k):
index=resrank[i]
sometype=labels[index]
clfy[sometype]=clfy.get(sometype,0)+1 sclfy=sorted(clfy.items(),key=operator.itemgetter(1),reverse=True) return sclfy[0][0]
这是算法。
下面是调用。
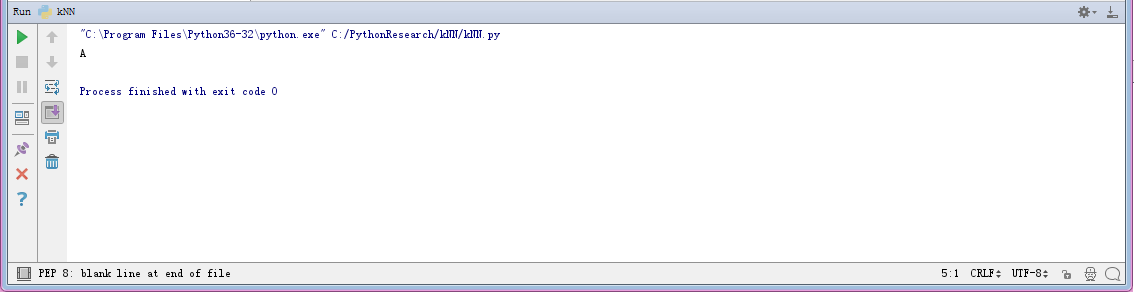
g,l=create_data_set()
r=classify_kNN([0.5,0.6],g,l,2)
print(r)
这个是结果
=======================================================================
那么问题来了:
新分类值是否可以加入样本扩充原来的数据?
机器学习——kNN(1)基本原理的更多相关文章
- [机器学习] ——KNN K-最邻近算法
KNN分类算法,是理论上比较成熟的方法,也是最简单的机器学习算法之一. 该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别 ...
- 机器学习--kNN算法识别手写字母
本文主要是用kNN算法对字母图片进行特征提取,分类识别.内容如下: kNN算法及相关Python模块介绍 对字母图片进行特征提取 kNN算法实现 kNN算法分析 一.kNN算法介绍 K近邻(kNN,k ...
- 机器学习-kNN
基于Peter Harrington所著<Machine Learning in Action> kNN,即k-NearestNeighbor算法,是一种最简单的分类算法,拿这个当机器学习 ...
- kNN算法基本原理与Python代码实践
kNN是一种常见的监督学习方法.工作机制简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k各训练样本,然后基于这k个“邻居”的信息来进行预测,通常,在分类任务中可使用“投票法”,即选择这k ...
- 机器学习-KNN算法详解与实战
最邻近规则分类(K-Nearest Neighbor)KNN算法 1.综述 1.1 Cover和Hart在1968年提出了最初的邻近算法 1.2 分类(classification)算法 1.3 输入 ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- 机器学习 KNN算法原理
K近邻(K-nearst neighbors,KNN)是一种基本的机器学习算法,所谓k近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表.比如:判断一个人的人品,只需要观察 ...
- 机器学习-KNN分类器
1. K-近邻(k-Nearest Neighbors,KNN)的原理 通过测量不同特征值之间的距离来衡量相似度的方法进行分类. 2. KNN算法过程 训练样本集:样本集中每个特征值都已经做好类别 ...
- ML02: 机器学习KNN 算法
摘要: 一张图说清楚KNN算法 看下图,清楚了吗? 没清楚的话,也没关系,看完下面几句话,就清楚了. KNN算法是用来分类的. 这个算法是如何来分类的呢? 看下图,你可以想想下图中的 『绿色圆点』 ...
随机推荐
- spring boot 遇到 supported setting property http://xml.org/sax/properties/lexical-handler
解决链接:http://apache-fop.1065347.n5.nabble.com/org-xml-sax-SAXNotSupportedException-thrown-by-FOP-td11 ...
- (python)leetcode刷题笔记03 Longest Substring Without Repeating Characters
3. Longest Substring Without Repeating Characters Given a string, find the length of the longest sub ...
- sql server 权限
-----是否存在有效的登录账号:是否被禁用,sql login还有:密码是否过期,是否被锁定 select is_disabled, loginproperty(name,'Isexpired') ...
- 更加清楚理解mvc结构
更加清楚理解mvc结构 文章来源:刘俊涛的博客 地址:http://www.cnblogs.com/lovebing 欢迎关注,有问题一起学习欢迎留言.评论.
- 通过window.location.search获取页面url传递的参数
function GetQueryString(name) { var reg = new RegExp("(^|&)" + name + "=([^&] ...
- SSH实战OA 11:BBS模块
<SSH实战OA>系列博客的系统管理.权限管理等内容后面再补上吧,先继续第三个模块:网上交流模块.网上交流主要做两个需求:论坛管理和论坛. BBS的一些基本术语: 板块:也叫做" ...
- (译)Web是如何工作的(2):客户端-服务器模型,以及Web应用程序的结构
原文地址:https://medium.freecodecamp.org/how-the-web-works-part-ii-client-server-model-the-structure-of- ...
- windows 驱动开发入门——驱动中的数据结构
最近在学习驱动编程方面的内容,在这将自己的一些心得分享出来,供大家参考,与大家共同进步,本人学习驱动主要是通过两本书--<独钓寒江 windows安全编程> 和 <windows驱动 ...
- 不要错过iost币的免费派发机会
2013 年 ripple 币曾经进行免费派发,而现在瑞波币兑CNY价格最高曾经达到20元, 如果你错过了 ripple 币,就不要错过这次李笑来和徐小平等背书 iost 币的免费派发
- 【转载】mysql主键的缺少导致备库hang
最近线上频繁的出现slave延时的情况,经排查发现为用户在删除数据的时候,由于表主键的主键的缺少,同时删除条件没有索引,或或者删除的条件过滤性极差,导致slave出现hang住,严重的影响了生产环境的 ...