[编织消息框架][netty源码分析]10 ByteBuf 与 ByteBuffer
因为jdk ByteBuffer使用起来很麻烦,所以netty研发出ByteBuf对象维护管理内存
使用ByteBuf有几个概念需要知道
1.向ByteBuf提取数据时readerIndex记录最后读取坐标,目的是下次从readerIndex开始读
2.向ByteBuf写入数据时writerIndex记录最后写数据坐标
3.提取数据范围是readerIndex<=writerIndex,因为先写入数据然后才能读取数据
4.自动扩容,当writerIndex达到一定阈值时,会扩大capacity
所以ByteBuf只需要维护readerIndex,writerIndex记录就能简化jdk提供的ByteBuffer api
分析ByteBuf有几个疑问
1.ByteBuf是如何扩容的,扩容后已读的数据如何减少或容量缩少
2.ByteBuf是如何创建、维护的
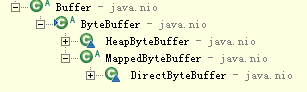
在分析之前先了解java分配内存有几种方式
1.HeapByteBuffer是分配在堆上的,直接由Jvm负责垃圾收集,你可以把它想象成一个字节数组的包装类
2.DirectByteBuffer是通过JNI在Jvm外的内存中分配了一块,该内存块并不直接由jvm负责垃圾收集,
但是在DirectByteBuffer包装类被回收时,会通过Java Reference机制来释放该内存块,也可手动调用clean回收
Direct空间大小通过设置JVM参数-Xmx,如果没设置-XX:MaxDirectMemorySize,则默认与-Xmx参数值相同
3.MappedByteBuffer是高效处理文件I/O,实现子类是DirectByteBuffer,里面维护了一个address是逻辑地址,通过FileChannel提供map方法把文件映射到虚拟内存,通常情况可以映射整个文件
对MappedByteBuffer兴趣的读者可以阅读 http://www.jianshu.com/p/f90866dcbffc
public abstract class ByteBuffer
extends Buffer
implements Comparable<ByteBuffer>
{
final byte[] hb; // Non-null only for heap buffers
final int offset;
boolean isReadOnly; // Valid only for heap buffers ByteBuffer(int mark, int pos, int lim, int cap,
byte[] hb, int offset)
{
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
//创建直接内存
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
//创建heap内存
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
}
import java.lang.reflect.Field;
import java.nio.ByteBuffer;
import java.util.concurrent.TimeUnit; import sun.nio.ch.DirectBuffer; public class DirectByteBufferTest {
public static void main(String[] args) throws InterruptedException {
testa();
testb();
} private static void testa() throws InterruptedException {
printlnDirectInfo("test a");
// 分配512MB直接缓存
ByteBuffer bb = ByteBuffer.allocateDirect(1024 * 1024 * 512);
printlnDirectInfo("init");
// 清除直接缓存
((DirectBuffer) bb).cleaner().clean();
TimeUnit.SECONDS.sleep(2);
printlnDirectInfo("clear");
System.out.println("end");
} private static void testb() throws InterruptedException {
printlnDirectInfo("test b");
// 分配512MB直接缓存
ByteBuffer bb = ByteBuffer.allocateDirect(1024 * 1024 * 512);
printlnDirectInfo("init");
// 删除引用
bb=null;
System.gc();
TimeUnit.SECONDS.sleep(2);
printlnDirectInfo("clear");
System.out.println("end");
} private static void printlnDirectInfo(String tag) {
try {
Class<?> c = Class.forName("java.nio.Bits");
Field field1 = c.getDeclaredField("maxMemory");
field1.setAccessible(true);
Field field2 = c.getDeclaredField("reservedMemory");
field2.setAccessible(true);
synchronized (c) {
Object max = (Object) field1.get(null);
Object reserve = (Object) field2.get(null);
System.out.println(tag + " ##### " +max + " " + reserve);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
小结:
DirectByteBuffer 是分配是堆外的,所以创建跟回收是比较占CPU时间,如果对象生命周期短不建议放在DirectByteBuffer
HeapByteBuffer 是分配是堆内的,回收很快,但频烦创建大量对象无疑增加GC回收次数
netty有基于Heap实现UnpooledHeapByteBuf,也有Direct实现UnpooledDirectByteBuf
还有内存池PooledByteBuf这种黑科技,之所有出现这么多实现是参照jdk的设计,目的是降低api复杂、方便维护、减少创建回收频率
了解jdk ByteBuffer 内存分配有几种方式同使用场景,直接内存如果不手动回收的话一定要注意引用否则会出现内存泄漏
[编织消息框架][netty源码分析]10 ByteBuf 与 ByteBuffer的更多相关文章
- [编织消息框架][netty源码分析]11 ByteBuf 实现类UnpooledHeapByteBuf职责与实现
每种ByteBuf都有相应的分配器ByteBufAllocator,类似工厂模式.我们先学习UnpooledHeapByteBuf与其对应的分配器UnpooledByteBufAllocator 如何 ...
- [编织消息框架][netty源码分析]13 ByteBuf 实现类CompositeByteBuf职责与实现
public class CompositeByteBuf extends AbstractReferenceCountedByteBuf implements Iterable<ByteBuf ...
- [编织消息框架][netty源码分析]12 ByteBuf 实现类UnpooledDirectByteBuf职责与实现
public class UnpooledDirectByteBuf extends AbstractReferenceCountedByteBuf { private final ByteBufAl ...
- [编织消息框架][netty源码分析]1分析切入点
在分析源码之前有几个疑问 1.BOSS线程如何转交给handle(业务)线程2.职业链在那个阶段执行3.socket accept 后转给上层对象是谁4.netty控流算法 另外要了解netty的对象 ...
- [编织消息框架][netty源码分析]2 eventLoop
eventLoop从命名上看是专门处理事件 事件系统主要由线程池同队列技术组成,有以下几个优点 1.任务出队有序执行,不会出现错乱,当然前提执行线程池只有一个 2.解偶系统复杂度,这是个经典的生产者/ ...
- [编织消息框架][netty源码分析]11 UnpooledHeapByteBuf 与 ByteBufAllocator
每种ByteBuf都有相应的分配器ByteBufAllocator,类似工厂模式.我们先学习UnpooledHeapByteBuf与其对应的分配器UnpooledByteBufAllocator 如何 ...
- [编织消息框架][netty源码分析]6 ChannelPipeline 实现类DefaultChannelPipeline职责与实现
ChannelPipeline 负责channel数据进出处理,如数据编解码等.采用拦截思想设计,经过A handler处理后接着交给next handler ChannelPipeline 并不是直 ...
- [编织消息框架][netty源码分析]4 eventLoop 实现类NioEventLoop职责与实现
NioEventLoop 是jdk nio多路处理实现同修复jdk nio的bug 1.NioEventLoop继承SingleThreadEventLoop 重用单线程处理 2.NioEventLo ...
- [编织消息框架][netty源码分析]5 eventLoop 实现类NioEventLoopGroup职责与实现
分析NioEventLoopGroup最主有两个疑问 1.next work如何分配NioEventLoop 2.boss group 与child group 是如何协作运行的 从EventLoop ...
随机推荐
- 学习笔记:HTML+CSS 基础知识
1.<q>标签,短文本引用 <q>引用文本</q> <q>标签的真正关键点不是它的默认样式双引号(如果这样我们不如自己在键盘上输入双引号就行 ...
- Vbs脚本实现radmin终极后门
Vbs脚本实现radmin终极后门 代码如下: on error resume next const HKEY_LOCAL_MACHINE = &H80000002 strComputer = ...
- SQLyog-12.4.2版下载,SQLyog最新版下载,SQLyog官网下载,SQLyog Download
SQLyog-12.4.2版下载,SQLyog最新版下载,SQLyog官网下载,SQLyog Download >>>>>>>>>>> ...
- VR全景加盟-了解VR就来全景智慧城市
关于什么是真正的VR说了这么多,面对刚刚起步的VR,如何辨别判断一个真正的VR形式呢.除了我们所说几个参数或者大家关注的眩晕感.临场感,真正的VR究竟带给大家什么样的特性呢?这个就要从VR的本质谈起. ...
- 20155212 实验四 《Android程序设计》 实验报告
20155212 实验四 <Android程序设计> 实验报告 (一)Android Stuidio的安装测试 参考<Java和Android开发学习指南(第二版)(EPUBIT,J ...
- 销量预测和用户行为的分析--基于ERP的交易数据
写在前面: 这段时间一直都在看一些机器学习方面的内容,其中又花了不少时间在推荐系统这块,然后自己做了一套简单的推荐系统,但是跑下来的结果总觉得有些差强人意,我在离线实验中得到Precision,Rec ...
- OpenCV探索之路(十一):轮廓查找和多边形包围轮廓
Canny一类的边缘检测算法可以根据像素之间的差异,检测出轮廓边界的像素,但它没有将轮廓作为一个整体.所以要将轮廓提起出来,就必须将这些边缘像素组装成轮廓. OpenCV中有一个很强大的函数,它可以从 ...
- 使用redis做mybaties的二级缓存(2)-Mybatis 二级缓存小心使用
Mybatis默认对二级缓存是关闭的,一级缓存默认开启: 下面就说说为什么使用二级缓存需要注意: 二级缓存是建立在同一个namespace下的,如果对表的操作查询可能有多个namespace,那么得到 ...
- 第 7 章 MySQL 数据库锁定机制
前言: 为了保证数据的一致完整性,任何一个数据库都存在锁定机制.锁定机制的优劣直接应想到一个数据库系统的并发处理能力和性能,所以锁定机制的实现也就成为了各种数据库的核心技术之一.本章将对 MySQ ...
- 前端小课堂 js:函数的创建方式及区别
js 函数的创建大体有这几种方式: -1-函数表达式(函数字面量): 说白了就是把一个函数赋值给了一个变量. var fun1 = function(index){ alert(index); } f ...