CDH5.11..0安装
文件下载
- Cloudera Manager
地址:http://archive.cloudera.com/cm5/cm/5/
这里下载的是5.13.1的版本,https://archive.cloudera.com/cm5/cm/5/cloudera-manager-el6-cm5.13.1_x86_64.tar.gz
- CDH安装包
地址:http://archive.cloudera.com/cdh5/parcels
本文基于CentOS6,下载的parcels包及manifest文件对应的版本为el6:
CDH-5.13.1-1.cdh5.13.1.p0.2-el6.parcel
CDH-5.13.1-1.cdh5.13.1.p0.2-el6.parcel.sha1
将.sha1修改为.sha
- JDBC
地址:https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.17/mysql-connector-java-5.1.17.jar
这里用的jdbc驱动版本是:mysql-connector-java-5.1.17.jar
我这3台机器node1,node2,node3。系统为centos6.5
配置静态IP(可不配)
vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=08:00:27:BA:1A:B9
TYPE=Ethernet
UUID=27ccadb3-93ce-4a0a-8e5c-9bf7709931a0
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
DNS1=192.168.1.1
IPADDR=192.168.1.6
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
如果是克隆虚拟机导致配置失败的话:
rm -rf /etc/udev/rules.d/70-persistent-net.rules //去除克隆之后的网络适配器
reboot //生成新的网络适配器
ifconfig //查看自己新生成的HWaddr,复制!
vi /etc/sysconfig/network-scripts/ifcfg-eth0 //编辑这个文件,替换刚刚复制的HWaddr
service network restart
一.网络配置(所有节点)
1.修改主机名
vi /etc/sysconfig/network修改hostname :
NETWORKING=yes
HOSTNAME=node1
通过service network restart重启网络服务生效
临时修改主机名hostname node1
2. 修改ip与主机名的对应关系
vi /etc/hosts
192.168.101.71 node1
192.168.101.72 node2
192.168.101.73 node3
3.设置SSH无密码访问(所有节点)
1.生成公钥私钥,每一台都要生成
ssh-keygen -t rsa
2.node1上将id_rsa.pub公钥内容拷贝到机器A的authorized_keys文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3.其他主机的id_rsa.pub拷贝到同一台机器node1的authorized_keys
ssh-copy-id root@node1
如果没有ssh-copy-id 执行sudo yum -y install openssh-clients
4.复制机器node1的authorized_keys文件拷贝到其它主机
scp /root/.ssh/authorized_keys root@node2:/root/.ssh
5.如果启动无效果,需要修改ssh配置vim /etc/ssh/sshd_config
RSAAuthentication yes #启用 RSA 认证
PubkeyAuthentication yes #启用公钥私钥配对认证方式
AuthorizedKeysFile .ssh/authorized_keys #公钥文件路径(和上面生成的文
StrictModes no设置完之后记得重启SSH服务,才能使刚才设置有效。service sshd restart
4.安装Oracle Java(所有节点)
Linux可能自带OpenJDK,但运行CDH5需要使用Oracle的JDK,需要Java 7以上版本的支持
卸载自带的OpenJDK** 使用下述命令查询相关的java包
rpm -qa | grep java
使用-e选项填入包名卸载
rpm -e --nodeps packageName
安装oracle jdk
配置环境变量 vi /etc/profile
JAVA_HOME=/opt/modules/jdk1.8.0_11/
export PATH=\$PATH:\$JAVA_HOME/bin:\$JAVA_HOME/sbin
source /etc/profile 使其生效
5.安装配置MySQL(主节点)
通过yum install mysql-server安装mysql服务器。
chkconfig mysqld on设置开机启动
service mysqld start启动mysql服务
设置root的初试密码:mysqladmin -u root password '123456'
mysql -uroot -p123456进入mysql命令行,创建以下数据库:
#为hive建库hive
create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
#activity monitor
create database amon DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
#为oozie建库oozie
create database oozieDEFAULT CHARSET utf8 COLLATE utf8_general_ci;
#为hue建库hue
create database hueDEFAULT CHARSET utf8 COLLATE utf8_general_ci;
#授权root用户在主节点拥有所有数据库的访问权限
grant all privileges on *.* to 'root'@'node1' identified by '123456' with grant option;
flush privileges;
6.关闭防火墙和SELinux(所有节点)
注意: 需要在所有的节点上执行,因为涉及到的端口太多了,临时关闭防火墙是为了安装起来更方便,安装完毕后可以根据需要设置防火墙策略,保证集群安全。
关闭防火墙:
service iptables stop (临时关闭)
chkconfig iptables off (重启后生效)
关闭SELINUX(实际安装过程中发现没有关闭也是可以的,不知道会不会有问题,还需进一步进行验证):
setenforce 0 (临时生效)
vi /etc/selinux/config :
SELINUX=disabled (重启后永久生效)
7.配置NTP服务(所有节点)
集群中所有主机必须保持时间同步,如果时间相差较大会引起各种问题,例如主机运行状态不良等。 具体思路如下:
master节点作为ntp服务器与外界对时中心同步时间,随后对所有datanode节点提供时间同步服务。
所有datanode节点以master节点为基础同步时间。
所有节点安装相关组件:yum install ntp。配置开机启动:chkconfig ntpd on,检查是否设置成功:chkconfig --list ntpd其中2-5为on状态就代表成功。
主节点配置
在配置之前,先使用ntpdate手动同步一下时间,免得本机与对时中心时间差距太大,使得ntpd不能正常同步。这里选用103.226.213.30作为对时中心,ntpdate -u 103.226.213.30。
vi /etc/ntp.conf
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server 103.226.213.30 prefer
配置文件完成,启动服务:service ntpd start
配置ntp客户端(所有子节点)
同上 ,不过这里是主节点的主机名或者ip
server node5
启动服务:service ntpd start
检查是否成功,用ntpstat命令查看同步状态,出现以下状态代表启动成功:
synchronised to NTP server () at stratum 2
time correct to within 74 ms
polling server every 128 s
这里可能出现同步失败的情况,一般需要等待5-10分钟才可以正常同步。
二,Cloudera Manager安装与集群配置
1,主节点安装CM
解压:tar xzvf cloudera-manager*.tar.gz将解压后的cm-5.13.1和cloudera目录放到/opt目录下。
建立数据库:
将下载好的mysql-connector-java-5.1.17.jar放到/opt/cm-5.13.1/share/cmf/lib/
初始化数据库:
/opt/cm-5.13.1/share/cmf/schema/scm_prepare_database.sh mysql cm -hnode1 -uroot -p123456 --scm-host node1 scm scm scm
参数分别是:数据库类型 数据库名称 -h数据库主机名 -u数据库用户名 -p数据库密码--scm-host cmserver主机名 scm scm scm
2.agent配置
vi /opt/cm-5.13.1/etc/cloudera-scm-agent/config.ini
server_host为主节点的主机名。
同步Agent到其他所有节点: scp -r /opt/cm-5.13.1 root@node2:/opt/
在所有节点创建cloudera-scm用户
useradd --system --home=/opt/cm-5.13.1/run/cloudera-scm-server/ --no-create-home --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm
3.准备Parcels,用以安装CDH5
将CHD5相关的Parcel包放到主节点的/opt/cloudera/parcel-repo/目录中
4.启动
主节点:/opt/cm-5.13.1/etc/init.d/cloudera-scm-server start启动服务端。
所有节点:/opt/cm-5.13.1/etc/init.d/cloudera-scm-agent start启动Agent服务。
我们启动的其实是个service脚本,需要停止服务将以上的start参数改为stop就可以了,重启是restart。
5.CDH5安装配置
这时可以通过浏览器访问主节点的7180端口测试一下了,默认的用户名和密码均为admin:
各个Agent节点正常启动后,可以在当前管理的主机列表中看到对应的节点。选择要安装的节点,点继续

继续,如果配置本地Parcel包无误,那么下图中的已下载,应该是瞬间就完成了,然后就是耐心等待分配过程就行了,这个过程的速度就取决于节点之间的传输速度。

下一步主机检查,遇到以下问题:

第一个警告:
Cloudera 建议将 /proc/sys/vm/swappiness 设置为 10。当前设置为 60。
echo 10 > /proc/sys/vm/swappiness
这样操作重启机器还是还原,要永久改变
第二个警告,提示执行命令:
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
执行完毕,重启后,警告依然,暂时不处理
安装服务
注意:一般选择自定义服务,手动在CM管理页面一个一个添加
分步安装服务步骤为:
点击页面上Cloudera MANAGER,回到主节点页面

出现cluster1群集1,点击下拉,选择“添加服务”

HDFS,Hive, HUE,Oozie, YARN, ZOOKEEPER是核心Hadoop的几个服务,分别安装,由于这些节点存在依赖关系,需注意先后顺序(当然,安装时CM会警告),顺序是:
Zookeeper, hdfs, yarn, hive, oozie, hue
注意:在安装hive, hue和oozie时,要将MySQL驱动jar拷贝到相应位置
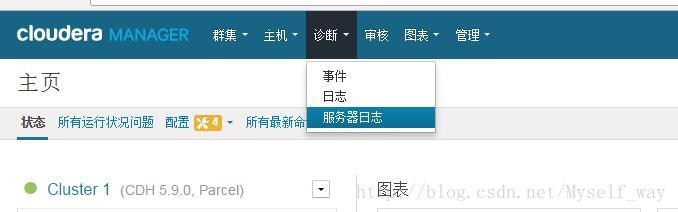
查看日志
CM虽然配置麻烦,但日志齐全,每个操作,都能找到相应的运行日志,日志对于配合、调试和查看任务进度都有很大的帮助
6.Q&A
1,Hadoop Datanode节点无法启动(All directories in dfs.data.dir are invalid)
2.执行 hadoop jar时候 输出目录可能需要手动添加和设置权限,否则执行时候会提示
3.Permission denied: user=root, access=WRITE, inode="/":hdfs:supergroup:drwxr-xr-x
1,Version information not found
2,javax.jdo.JDODataStoreException: Required table missing : "`VERSION`" in Catalog "" Schema "". DataNucleus requires this table to perform its persistence operations. Either your MetaData is incorrect, or you need to enable "datanucleus.autoCreateTables"
Unexpected error. Unable to verify database connection
CDH5.11..0安装的更多相关文章
- CentOS7+CDH5.14.0安装全流程记录,图文详解全程实测-总目录
CentOS7+CDH5.14.0安装全流程记录,图文详解全程实测-总目录: 0.Windows 10本机下载Xshell,以方便往Linux主机上上传大文件 1.CentOS7+CDH5.14.0安 ...
- CentOS7+CDH5.14.0安装全流程记录,图文详解全程实测-8CDH5安装和集群配置
Cloudera Manager Server和Agent都启动以后,就可以进行CDH5的安装配置了. 准备文件 从 http://archive.cloudera.com/cdh5/par ...
- Navicat Premium 12.1.11.0安装与激活
本文介绍Navicat Premium 12.1.11.0的安装.激活与基本使用. 博主所提供的激活文件理论支持Navicat Premium 12.0.x系列和Navicat Premium 12. ...
- Windows下MySQL8.0.11.0安装教程
1.mysql下载地址:https://dev.mysql.com/downloads/installer/ 2.下载安装MySQL 8.0.11.0 https://cdn.mysql.com//D ...
- hive-0.11.0安装
一.安装 . 下载安装hive hive-0.11.0.tar.gz(稳定版) 目录:/data tar –zxvfhive-0.11.0.tar.gz . 配置 把所有 ...
- hive-0.11.0安装方法具体解释
先决条件: 1)java环境,须要安装java1.6以上版本号 2)hadoop环境,Hadoop-1.2.1的安装方法參考hadoop-1.2.1安装方法具体解释 本文採用的hado ...
- k8s1.11.0安装、一个master、一个node、查看node名称是主机名、node是扩容进来的、带cadvisor监控服务
一个master.一个node.查看node节点是主机名 # 安装顺序:先在test1 上安装完必要组件后,就开始在 test2 上单独安装node组件,实现node功能,再返回来配置test1加入集 ...
- k8s1.11.0安装、一个master、一个node、查看node名称是ip、node是扩容进来的、带cadvisor监控服务
一个master.一个node.查看node节点是ip # 安装顺序:先在test1 上安装完必要组件后,就开始在 test2 上单独安装node组件,实现node功能,再返回来配置test1加入集群 ...
- CentOS7+CDH5.14.0安装CDH错误排查:Hue错误: Load Balancer 该角色的进程启动失败
Hue错误: Load Balancer 该角色的进程启动失败 解决办法:主机能够联网情况下,直接运行如下命令即可在线安装openssl.httpd 需要提前安装环境 httpd, mod_ssl ...
随机推荐
- OpenWRT UCI命令实现无线中继
本文主要功能主要是利用OpenWRT系统uci命令实现无线中继,主要是利用uci程序修改/etc/congfig/目录下的配置文件.实现步骤如下主要分为以下几步: 1) 安装 relayd (opkg ...
- css实现的交互运动
<style type="text/css"> .filter-mix { position: absolute; top: 50%; left: 50%; trans ...
- ThreeJS之动画交互逻辑及特效
工作需要,研究了一下 threejs 简单逻辑动画交互方法.写了一个小示例,分享一下,挺丑的. 第一步 当然就是初始化 threejs 的渲染场景了. var camera; //相机 var sce ...
- LeetCode 162. Find Peak Element (找到峰值)
A peak element is an element that is greater than its neighbors. Given an input array where num[i] ≠ ...
- LeetCode 110. Balanced Binary Tree (平衡二叉树)
Given a binary tree, determine if it is height-balanced. For this problem, a height-balanced binary ...
- MySql数据库的基本原理及指令
1.什么是数据库 数据库就是存储数据的仓库,其本质是一个文件系统,数据按照特定的格式将数据存储起来,用户可以通过SQL对数据库中的数据进行增加,修改,删除及查询操作. 2.简介 MySQL是一个开放源 ...
- JS框架设计读书笔记之-异步
setTimeout/setInterval 1. 如果回调执行时间大于间隔时间,真正的间隔时间会大一些. 2. 存在一个最小的时间间隔,即使seTimeout(fn,0),在IE6-IE8中大概为1 ...
- 简单的计算100000以内的质数(JAVA实现)
public class TestPrimeNumber(int i){ public static void main(String[] args) { long start = System.cu ...
- Leetcode题解(30)
98. Validate Binary Search Tree 题目 分析:BST按照中序遍历之后所得到的序列是一个递增序列,因此可以按照这个思路,先中序遍历,保存好遍历的结果,然后在遍历一遍这个序列 ...
- 2301: [HAOI2011]Problem b ( 分块+莫比乌斯反演+容斥)
2301: [HAOI2011]Problem b Time Limit: 50 Sec Memory Limit: 256 MBSubmit: 6015 Solved: 2741[Submit] ...