关于SVM数学细节逻辑的个人理解(一)
网上,书上有很多的关于SVM的资料,但是我觉得一些细节的地方并没有讲的太清楚,下面是我对SVM的整个数学原理的推导过程,其中我理解的地方力求每一步都是有理有据,希望和大家讨论分享。
首先说明,目前我的SVM的数学原理还没有过多的学习核函数,所以下面的整理都不涉及到核函数。而且因为很多地方我还没理解太透,所以目前我整理的部分主要分为:
①最大间隔分类器,其中包括优化目标的一步步推导,还有关于拉格朗日函数,KKT条件,以及对偶问题等数学优化的知识
②软间隔优化形式,即加入了松弛变量的优化目标的一步步推导
③SMO算法
下面是第一部分,得到SVM的基本形式。
一.前言:
虽然还是有很多地方不能理解,但是我觉得目前理解的程度已经进入了一个瓶颈了,或许从头整理一遍会突破呢。(后来证明确实自己整理推导一遍有很大的收获)
不得不说SVM是真的难,神经网络如果说难就难在反向传播算法,不过那也只是个链式求导法则,而SVM则涉及到最优化的大量数学知识,毕竟光是一个SVM就能写本书(《支持向量机导论》)的...
OK,开始整理整个SVM的思路。可能一开始还是有很多不清楚的地方,不过慢慢修改吧。
而且想要自己画一些图,但是目前还没找到好的工具,所以就先剪切一些书上的图,我会标注好来源的。
二.得到最最基本的形式
(不知道起什么题目更好)

(图来自于《机器学习》P121)
我觉得很多人可能对SVM要做什么很熟悉了,现在还是啰嗦一下:
现在给你训练数据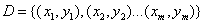 ,其中
,其中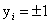 (牢记这个,在后面很重要),我们要做的就是找到一个超平面可以把这两类数据给分开。现在假设,这个数据集是线性可分的(先考虑数据集是线性可分的情况),那么我们其实可以找到很多超平面来分开这两类数据,比如上面这个图中可以看到由很多情况。那么我们该找哪种情况呢?
(牢记这个,在后面很重要),我们要做的就是找到一个超平面可以把这两类数据给分开。现在假设,这个数据集是线性可分的(先考虑数据集是线性可分的情况),那么我们其实可以找到很多超平面来分开这两类数据,比如上面这个图中可以看到由很多情况。那么我们该找哪种情况呢?
直观上看,我们需要找的这个超平面,它离两边的不同类型的数据集距离“最远”,就比如上面加粗的那条直线。这个直线看起来距离两类数据集是“最远的”,这样在预测时可能更准确一些。但这是直观上的说法,如果要使用数学原理来解决,我们首先需要找到衡量平面到数据集的距离远近的标准,这就引出了“函数间隔”和“几何间隔”的概念。
(寻找最大间隔直观上看是最优的,而且其实背后有很多数学原理,我记得在《支持向量机导论》中应该是第四章讲了,但是目前还是没太理解,大家有兴趣可以看一看)
1.函数间隔与几何间隔定义
首先我们定义超平面的表达式为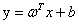 ,那么复习一下高中学的知识我们知道,平面上一个点x到这个平面的距离是
,那么复习一下高中学的知识我们知道,平面上一个点x到这个平面的距离是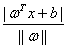 ,而这个就是几何间隔的定义。
,而这个就是几何间隔的定义。
(如果不熟悉这个,那肯定熟悉一个点(x,y)到Ax+By+C=0,的距离公式是 )
)
而函数间隔是什么呢?这里就需要强调的取值了: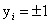 ,对于正样例它的label是+1,对于负样例它的label是-1。(所以乘上不改变原来的绝对值)
,对于正样例它的label是+1,对于负样例它的label是-1。(所以乘上不改变原来的绝对值)
我们用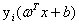 来表示一个样本点
来表示一个样本点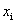 到这个超平面的函数间隔。
到这个超平面的函数间隔。
(关于函数间隔的定义是在《支持向量机导论》第二章中找到的)
2.函数间隔与几何间隔的关系
需要注意的是,如果找到了一个超平面可以正确分开这个数据集,那么意味着对于每个样本点x来说,其实它的函数间隔都大于等于0,即:

我觉得这一步理解很关键。具体解释就是:对于正样例,因为它的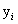 =1,而因为它被正确分类了,所以它的
=1,而因为它被正确分类了,所以它的 ,所以可以得到
,所以可以得到 ,对于负样例同理。
,对于负样例同理。
(很多书上直接给出 ,我觉得思维跨度就有点大了,关于
,我觉得思维跨度就有点大了,关于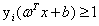 的说明后面讲)
的说明后面讲)
然后进一步我们其实可以得到,如果这个样本被正确分类了,那么:

所以函数间隔其实也可以用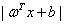 表示。
表示。
回顾之前几何间隔的计算式子 ,很多时候其实分子都不用绝对值符号来表示,我们可以把分子的绝对值换成函数间隔,那么这个样本到超平面的几何间隔其实就可以写成:
,很多时候其实分子都不用绝对值符号来表示,我们可以把分子的绝对值换成函数间隔,那么这个样本到超平面的几何间隔其实就可以写成:
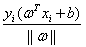
所以我觉得这就是函数间隔和几何间隔之间的关系,即在样本集线性可分的情况下,对于某一个成功分类的超平面来说,每个样本点到这个超平面的几何间隔就是函数间隔再除以的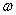 范数。
范数。
3.定义超平面到训练集的间隔
然后我们之前的几何间隔,函数间隔什么的都是点到平面的距离,现在我们定义一个超平面到训练集的间隔为这个超平面到训练集的每个点的几何距离中最小的距离。
(关于这个的定义我是参考了《Pattern Recognition and Machine Learning 》关于SVM的讲解,这本书是我见过的讲的最细的了)
这个平面到数据集的间隔就是我们一开始直观感受时所需要的那个衡量远近的数值。
从这个意义上来说,其实我们在衡量一个平面到数据集的“远近”时,我们其实只需要看的是到所有的样本点距离中最近的那个。
所以对于一个超平面(ω,b)我们可以得到它到给定训练集的间隔为:
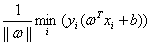
这个式子很容易理解,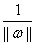 如果放进min里面,即
如果放进min里面,即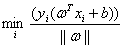 ,就表示在每个几何间隔中找最小的。因为
,就表示在每个几何间隔中找最小的。因为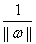 和具体样本点无关所以被提了出来,然后后面的
和具体样本点无关所以被提了出来,然后后面的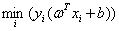
就是表示训练集中每个点到这个超平面的函数间隔中的最小值。
这里还需要理解的是,如果给定了这个分类超平面,那么这个超平面到训练集的距离就定了,因为训练集是给定了每个点是固定的。所以超平面如果调整,这个间隔就会变化。
4.得到最最原始的优化目标
所以我们现在需要找到这么一个超平面,它不但可以正确分类,而且它到训练集的间隔是所有可正确分类的超平面中最大的。这也是我们一开始提出的那个直观上的问题。
然后我们就可以得到我们的最最原始的优化目标了:

(写到这里我在想一个问题,如何能保证按照这个优化目标找出来的超平面它正好到正样本集和负样本集的间隔是一样的。经过思考后发现,这个已经被包含在了这个优化目标内部。可以这么解释:因为其实我觉得我们可以把平面优化分为ω的最优化和b的最优化,对于相同的ω,不同的b的平面都是平行的。当ω固定时,这时一个正样本到这个平面的距离和一个负样本到这个平面的距离之和的最小值也固定了!后面补图说明。
但是不同的b会导致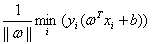 不同,不同的b会导致平面保持相同的“斜率”平移。发现因为这里取最小值。所以我们假设这个平面从正负样本的正中间往正样本方向偏离一小段距离,那么可能是到正样本距离变小,到负样本的距离变大,但是注意到
不同,不同的b会导致平面保持相同的“斜率”平移。发现因为这里取最小值。所以我们假设这个平面从正负样本的正中间往正样本方向偏离一小段距离,那么可能是到正样本距离变小,到负样本的距离变大,但是注意到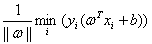 是取最小值,所以这个最小值就会从原来的1/2变小,并不是我们最后的最优的结果,所以从这个角度看,直线位于正中间是最优的。)
是取最小值,所以这个最小值就会从原来的1/2变小,并不是我们最后的最优的结果,所以从这个角度看,直线位于正中间是最优的。)
(这个最原始的优化目标很多书上都没有,我也是在《Pattern Recognition and Machine Learning》这本书上找到的,这本书相当不错)
三.得到SVM的基本形式
得到这个最最原始的优化目标后,直接尝试解决它是很复杂的。我们还可以进一步简化。注意到如果我们对ω和b同时进行缩放,即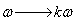 ,
, ,然后把kω和kb代入原来的式子
,然后把kω和kb代入原来的式子 ,会发现对原来的优化问题并没有影响,因子都被约了。那我们就可以通过这个特性来简化式子。
,会发现对原来的优化问题并没有影响,因子都被约了。那我们就可以通过这个特性来简化式子。
所以我们不如就让这个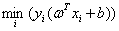 为1,即我们通过同时缩放ω和b让距离超平面最近的那些样本点的函数间隔为1,这样调整后,不仅对原来的优化问题没有影响,而且还能简化计算。
为1,即我们通过同时缩放ω和b让距离超平面最近的那些样本点的函数间隔为1,这样调整后,不仅对原来的优化问题没有影响,而且还能简化计算。
(这里缩放需要理解到位,同时缩放ω和b,会改变每个样本点到这个超平面的函数间隔,但是并不会改变每个样本点到这个超平面的几何间隔,所以我们不如就让距离这个超平面最近的那些点的函数间隔为1,简化了计算,但是也带来了约束)
但是既然设置了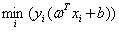 =1,那么就意味着增加了约束:
=1,那么就意味着增加了约束:
对于离超平面最近的那些样本点,它们的
对于其他的样本点,它们的
所以现在可以说:当可以找到一个超平面正确分类给定的训练集时,每个样本点的函数间隔满足:

这个就是简化所带来的约束条件
现在我们看一看简化后的优化式子变成了:
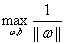
约束就是上面的对于每个样本点满足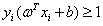
但是我们一般把这个优化问题转化为和它等价的:

而且一般会加上系数1/2,书上说是为了之后推导的方便。
所以现在我们的优化问题变成了:
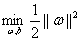
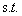
 其中i=1,2,3...m
其中i=1,2,3...m
这个就是《机器学习》书上说的SVM的基本形式。
现在整理一下推导出这个基本形式的过程:
(1)最最原始的优化目标: ,即我们需要在每个可以正确分类的平面中,找到一个到数据集的间隔最大的平面,其中间隔被定义为这个数据集样本到这个平面的最小距离
,即我们需要在每个可以正确分类的平面中,找到一个到数据集的间隔最大的平面,其中间隔被定义为这个数据集样本到这个平面的最小距离
(2)根据w和b缩放后优化目标不变,我们就可以让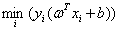 为1来简化这个问题,得到
为1来简化这个问题,得到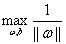 ,然后再转化为等价的
,然后再转化为等价的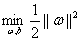
,但是注意此时就有了约束条件了!
可以看到光是得到这个最基本的形式的推导其实就有很多很多需要思考和理解的细节。
PS:谁知道如何把word上的公式方便的粘贴到网页上?必须得一个一个复制...
参考资料汇总:
[1]《机器学习》
[2]《支持向量机导论》
[3]《Pattern Recognition and Machine Learning》
关于SVM数学细节逻辑的个人理解(一)的更多相关文章
- 关于SVM数学细节逻辑的个人理解(二):从基本形式转化为对偶问题
第二部分:转化为对偶问题进一步简化 这一部分涉及的数学原理特别多.如果有逻辑错误希望可以指出来. 上一部分得到了最大间隔分类器的基本形式: 其中i=1,2,3...m 直接求的话一看就很复杂,我们 ...
- 关于SVM数学细节逻辑的个人理解(一) :得到最大间隔分类器的基本形式
网上,书上有很多的关于SVM的资料,但是我觉得一些细节的地方并没有讲的太清楚,下面是我对SVM的整个数学原理的推导过程,其中逻辑的推导力求每一步都是有理有据.现在整理出来和大家讨论分享. 因为目前我的 ...
- 关于SVM数学细节逻辑的个人理解(三) :SMO算法理解
第三部分:SMO算法的个人理解 接下来的这部分我觉得是最难理解的?而且计算也是最难得,就是SMO算法. SMO算法就是帮助我们求解: s.t. 这个优化问题的. 虽然这个优化问题只剩下了α这一个变 ...
- SVM数学原理推导&鸢尾花实例
//看了多少遍SVM的数学原理讲解,就是不懂,对偶形式推导也是不懂,看来我真的是不太适合学数学啊,这是面试前最后一次认真的看,并且使用了sklearn包中的SVM来进行实现了一个鸢尾花分类的实例,进行 ...
- SVM(支持向量机)的一点理解
最近有被问到SVM的问题,不懂装懂,羞愧不已.百度有很多深入浅出介绍SVM的文章,我就不赘述了,这里写一点自己肤浅的理解. SVM的核心思想是把求解低维空间上的高维分类器转化为求解高维函数空间上的线性 ...
- KKT原理以及SVM数学的理论推导分析
一直很好奇机器学习实战中的SVM优化部分的数学运算式是如何得出的,如何转化成了含有内积的运算式,今天上了一节课有了让我很深的启发,也明白了数学表达式推导的全过程. 对于一个SVM问题,优化的关键在于 ...
- SVM数学原理推导
//2019.08.17 #支撑向量机SVM(Support Vector Machine)1.支撑向量机SVM是一种非常重要和广泛的机器学习算法,它的算法出发点是尽可能找到最优的决策边界,使得模型的 ...
- HDU 4611 Balls Rearrangement (数学-思维逻辑题)
题目地址:http://acm.hdu.edu.cn/showproblem.php?pid=4611 题意:给你一个N.A.B,要你求 AC代码: #include <iostream> ...
- Cortex-M3 内核中悬起标志位细节逻辑
对于外设中断,如果通过NVIC_DisableIRQ(xxx)关闭对应NVIC里面的使能位,会导致对应中断Pend位置起,如果清除Pend位时不清外设的中断标志位将导致对应Pend位立刻再次置起.所以 ...
随机推荐
- Can not issue data manipulation statements with executeQuery().解决的方法
query是查询用的,而update是插入和更新,删除修改用的. executeQuery()语句是用于产生单个结果集的语句,如select语句,在什么情况下用,当你的数据库已经保存了数据后,要进行查 ...
- 【有意思的BUG】默认置灰的属性的值传递
数据由Client发送给Server,如下图所示,Server在收到请求后会响应Client. 比如Client发送给Server一组数据:Name:sean&Hobby:movies& ...
- JAVASCRIPT 调用 OCX 的那些坑
这个东西我之前已经想写了,但是在我写完"制作OCX","MFC应用OCX" 之后,html 调用OCX 就一直不成功,搞了好久,都快要放弃了.昨天领导需要我这边 ...
- Apriori关联分析算法概述
概念 关联分析:从大规模数据集中寻找物品间的隐含关系.物品间关系又分为两种:频繁项集或关联规则,频繁项集是经常出现一块的物品集合:关联规则则暗示物品间存在很强的联系 关联评判标准:支持度和可信度.支持 ...
- CentOS 7 服务器配置--安装nginx
#安装pcre yum install -y pcre-devel #安装zlib-devel yum install -y zlib-devel #下载nginx wget -r -np -nd h ...
- shell学习笔记(一)
1.第一行必须以#!/bin/bash #!表示脚本使用后面的解释器解释执行 2.echo 打印输出 例如 echo "hello world" > aa.txt 3.接 ...
- js 小数计算为啥和想象中不一样!
今天遇到了一个比较有趣的事,如果要你计算0.1+0.2等于多少你会怎么回答? "0.3啊!"你可能都不会考虑.我也一样,当a=0.1,b=0.2时 if(a+b === 0.3){ ...
- 【Zookeeper】角色、顺序号、读写机制
角色 leader 负责进行投票的发起和决议,更新系统状态 learner 包括follower和observer follower用于接受客户端请求并向客户端返回结果,在选举过程中参与投票 obse ...
- OpenCV中phase函数计算方向场
一.函数原型 该函数参数angleInDegrees默认为false,即弧度,当置为true时,则输出为角度. phase函数根据函数来计算角度,计算精度大约为0.3弧度,当x,y相等时,angle ...
- win7系统中如何使文件显示出扩展名或显示文件后缀名
win7系统中如何使文件显示出扩展名-------------------- 1.点击计算机-->>点击组织,然后选择“文件夹及搜索选项”-->> -------------- ...