Censys

Censys
Censys持续监控互联网上所有可访问的服务器和设备,以便您可以实时搜索和分析它们,了解你的网络攻击面,发现新的威胁并评估其全球影响。从互联网领先的扫描仪ZMap的创造者来说,我们的使命是通过数据驱动安全。
Censys跟国外的Shodan和国内的ZoomEye类似,可以搜索世界范围内的联网设备。Shodan和ZoomEye是个人用的比较多的两款,当然国内还有傻蛋和fofa, 国外也有其他类似的搜索引擎,这里就不一一列举了。
Censys与Shodan相比是一款免费搜索引擎,当然也有一定的限制(速度和搜索结果),而新改版后的ZoomEye对国内的搜索结果做了处理,几乎没有什么价值,对于非天朝的搜索还是可以适用的,如果对这两款搜索引擎感兴趣的朋友可以去试用一下,博客中也有关于这两款搜索引擎介绍,可自行查找。
先来膜拜一下发表在信息安全顶会CCS'15 : A Search Engine Backed by Internet-Wide Scanning 。
Censys提供6种API的使用方式,如下:
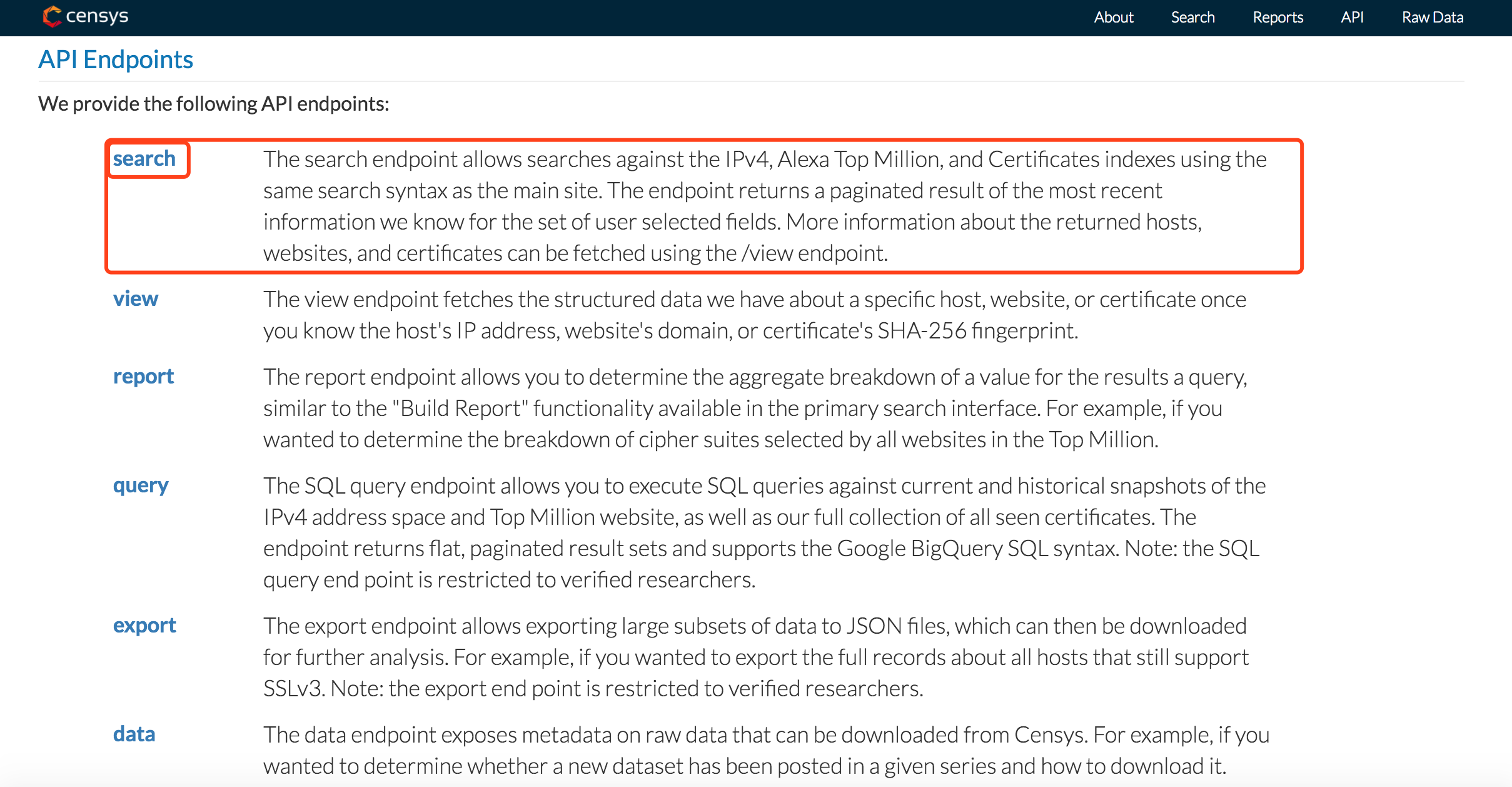
不过这里我们仅介绍第一种的使用,即获取搜索条件下的ip地址,这个也是我们用的最多的。
使用说明
当然在使用之前也是需要注册一个账号的,因为在使用API时需要提供API Credentials即你的ID和Secret,可以在个人信息中看到。
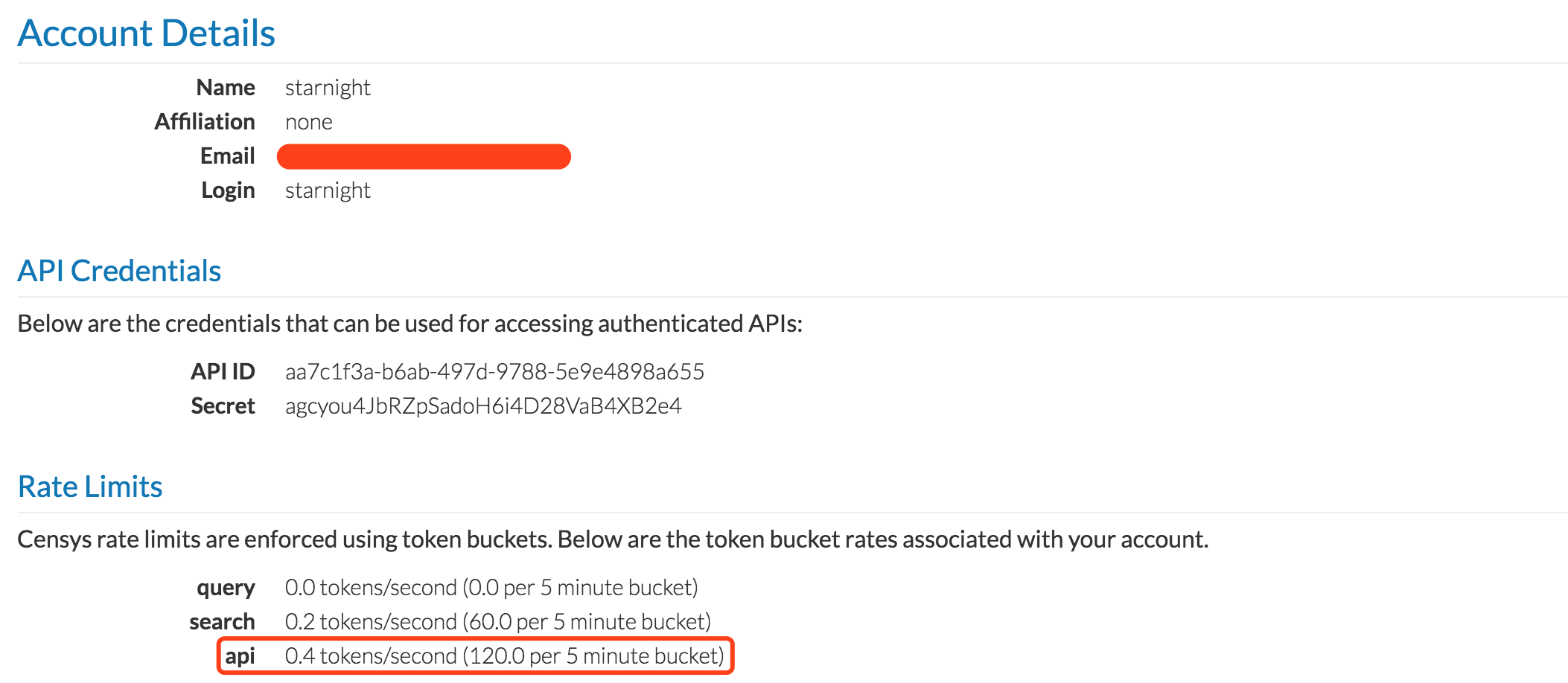
最下面是使用的速度限制,我们可以在程序中设置一个延时,比如每查询一次睡眠三秒钟,总体来说,速度还是比较可观的。
官方示例
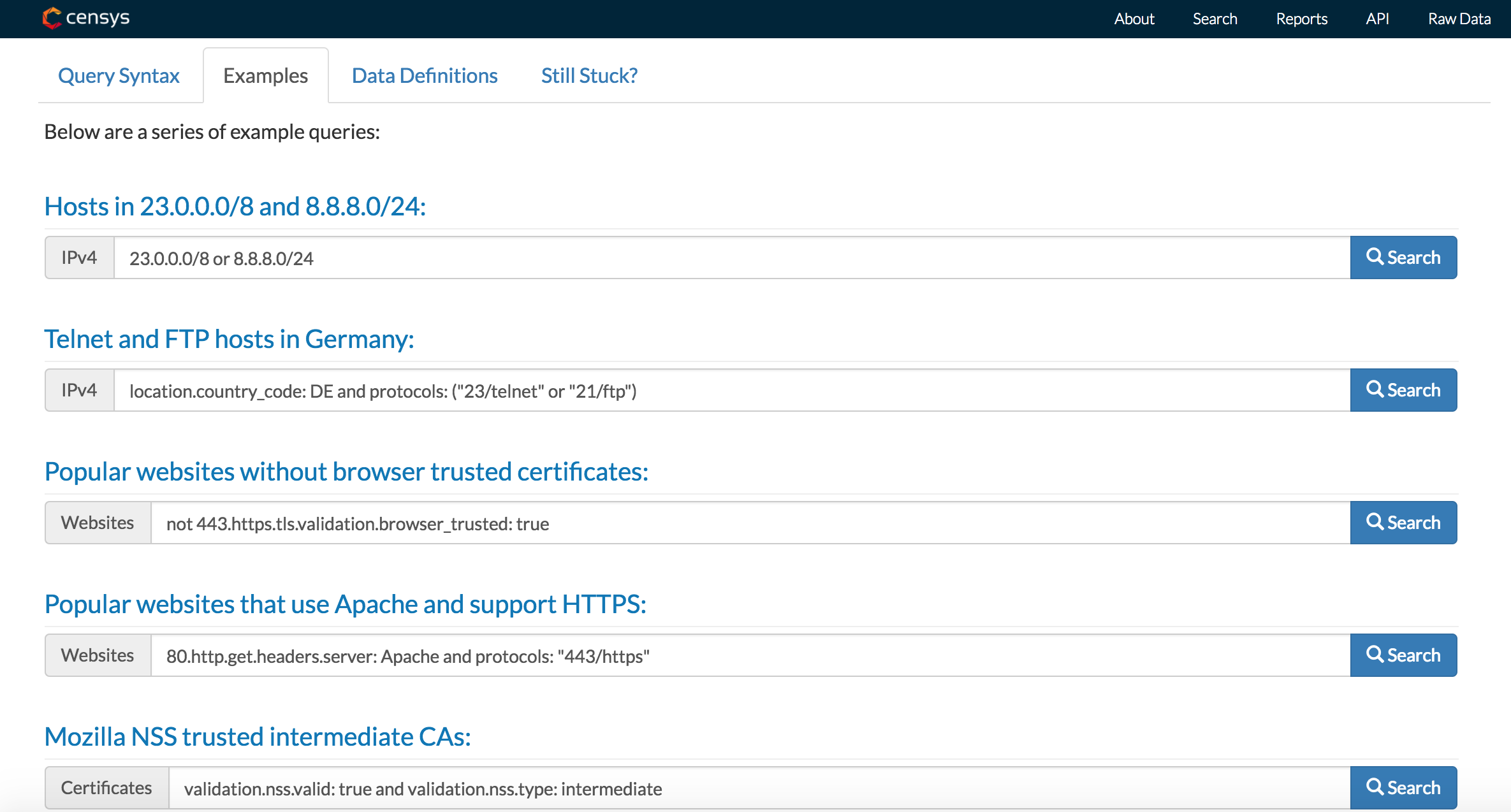
初看确实感觉搜索语法好像略微繁琐,没有Shodan和ZoomEye那么简练,而且文档也不够,怎么说呢,简单明了吧。不信你点开看看
查询语法
Search 的Data Parameters 主要有四个,分别是
- query:查询语句
- page:查询页
- fields:查询的结果域(可选)
- flatten:平整的结果(可选)
Example:
{
"query":"80.http.get.headers.server: Apache",
"page":1,
"fields":["ip", "location.country", "autonomous_system.asn"],
"flatten":true
}
好了,说明部分差不多到这里了,下面给出一个完整的示例。
示例
一般来说我们在查询的时候,会加上一定的限制条件,比如天朝的某些设备,如:"query": "weblogic and location.country_code: CN"。
#!/usr/bin/env python
# -*- coding:utf-8 -*- import sys
import json
import requests
import time API_URL = "https://www.censys.io/api/v1"
UID = "aa7c1f3a-b6ab-497d-9788-5e9e4898a655"
SECRET = "pay3u4ytGjbdZGftJ8ow50E8hBQVLk7j"
page = 1
PAGES = 50 # the pages you want to fetch def getIp(query, page):
'''
Return ips and total amount when doing query
'''
iplist = []
data = {
"query": query,
"page": page,
"fields": ["ip", "protocols", "location.country"]
}
try:
res = requests.post(API_URL + "/search/ipv4", data=json.dumps(data), auth=(UID, SECRET))
except:
pass
try:
results = res.json()
except:
pass
if res.status_code != 200:
print("error occurred: %s" % results["error"])
sys.exit(1)
# total query result
iplist.append("Total_count:%s" % (results["metadata"]["count"])) # add result in some specific form
for result in results["results"]:
for i in result["protocols"]:
# iplist.append(result["ip"] + ':' + i + ' in ' + result["location.country"][0])
iplist.append(result["ip"] + ':' + i)
# return ips and total count
return iplist, results["metadata"]["count"] if __name__ == '__main__': query = input('please input query string : ')
print('---', query, '---')
ips, num = getIp(query=query, page=page) print("Total_count:%s" % num) dst = input('please input file name to save data (censys.txt default) : ') # 保存数据到文件
if dst:
dst = dst + '.txt'
else:
dst = 'censys.txt' # get result and save to file page by page
with open(dst, 'a') as f:
while page <= PAGES:
print('page :' + str(page))
iplist, num = (getIp(query=query, page=page))
page += 1 for i in iplist:
print i[:i.find('/')] for i in iplist:
f.write(i[:i.find('/')] + '\n')
time.sleep(3)
print('Finished. data saved to file', dst)
Sample:
starnight:censys starnight$ python script.py
please input query string : "weblogic"
('---', 'weblogic', '---')
Total_count:11836
please input file name to save data (censys.txt default) : "weblogic"
page :1
Total_count:1183
46.244.104.198:80
46.244.104.198:8080
31.134.202.10:2323
31.134.202.10:80
31.134.202.10:8080
31.134.203.85:2323
31.134.203.85:80
31.134.203.85:8080
31.134.205.92:2323
31.134.205.92:80
31.134.205.92:8080
31.134.206.202:2323
31.134.206.202:80
31.134.206.202:8080
31.134.201.249:80
31.134.201.249:8080
31.134.202.233:80
31.134.202.233:8080
31.134.200.94:80
31.134.200.94:8080
31.134.201.248:80
31.134.201.248:8080
31.134.200.6:80
31.134.200.6:8080
46.244.105.216:80
46.244.105.216:8080
31.134.206.131:80
31.134.206.131:2323
31.134.206.131:8080
31.134.204.127:80
31.134.204.127:8080
46.244.10.173:80
46.244.10.173:23
46.244.10.173:8080
31.134.202.82:80
31.134.202.82:8080
46.244.105.252:80
46.244.105.252:2323
46.244.105.252:8080
31.134.205.186:2323
31.134.205.186:80
31.134.205.186:8080
31.134.204.223:80
31.134.204.223:8080
31.134.207.182:2323
31.134.207.182:80
31.134.207.182:8080
好像结果不是很准确 ~ 哈哈 ~ 另外,个人可以对返回iplist做相应的改变以方便自己使用 ~
今天上午收到一封邮件,说Censys的商业版本要出来了 ~ 敬请期待 (2017.11.14)

最后,Github地址: censys
References
Censys的更多相关文章
- 利用Shodan和Censys进行信息侦查
在渗透测试的初始阶段,Shodan.Censys等在线资源可以作为一个起点来识别目标机构的技术痕迹.本文中就以二者提供的Python API为例,举例介绍如何使用它们进行渗透测试初期的信息侦查. Sh ...
- 信息收集之censys
一.摘要 Censys提供了search.view.report.query.export以及data六种API接口. search接口的请求地址是https://www.censys.io/api/ ...
- APT 信息收集——shodan.io ,fofa.so、 MX 及 邮件。mx记录查询。censys.io查询子域名。
信息收集 目标是某特殊机构,外网结构简单,防护严密.经探测发现其多个子机构由一家网站建设公司建设. 对子域名进行挖掘,确定目标ip分布范围及主要出口ip. 很多网站主站的访问量会比较大.往往主站都是挂 ...
- Recon ASRC Conference
场景 ASRC漏洞挖掘 方法论 1.Brands https://www.crunchbase.com/ https://en.wikipedia.org Footers & about us ...
- 2018-2019-2 网络对抗技术 20165304 Exp6 信息搜集与漏洞扫描
2018-2019-2 网络对抗技术 20165304 Exp6 信息搜集与漏洞扫描 原理与实践说明 1.实践原理 信息搜集:渗透测试中首先要做的重要事项之一,搜集关于目标机器的一切信息 间接收集 D ...
- google搜索引擎正确打开姿势
Google搜索引擎 原文来自黑白之道微信公众号 https://mp.weixin.qq.com/s/Ey_ODP_mG00of5DPwcQtfg 这里之所以要介绍google搜索引 ...
- 2018-2019-2 网络对抗技术 20165318 Exp6 信息搜集与漏洞扫描
2018-2019-2 网络对抗技术 20165318 Exp6 信息搜集与漏洞扫描 原理与实践说明 实践原理 实践内容概述 基础问题回答 实践过程记录 各种搜索技巧的应用 DNS IP注册信息的查询 ...
- 使用PLC作为payload/shellcode分发系统
这个周末,我一直在鼓捣Modbus,并利用汇编语言开发了一个stager,它可以从PLC的保持寄存器中下载payload.由于有大量的PLC都暴露在互联网上,我情不自禁地想到,是否可以利用它们提供的处 ...
- ssl tls 证书链 根证书和叶证书查询
你基本上需要做的是构建一个证书链,如果你没有得到它作为一个链.证书链基本上由第零个位置的最终实体证书(也是叶证书,链中最重要的证书)组成,其次是次要证书. CA证书是最不重要的. 所以这是通常的X.5 ...
随机推荐
- tyvj/joyoi 1336 火车进栈
比原题水了很多(因为原题要高精度) 输出字典序前20种出栈序列. 其实是贪心题:我们每次确定一个出栈的数. 当栈里有数时,字典序显然比从后面拿数要小,所以先搜这个. 之后依次搜后面队列里的数,因为字典 ...
- 【洛谷P1226 【模板】快速幂||取余运算】
题目描述 输入b,p,k的值,求b^p mod k的值.其中b,p,k*k为长整型数. 输入输出格式 输入格式: 三个整数b,p,k. 输出格式: 输出“b^p mod k=s” s为运算结果 作为初 ...
- bfs退出条件
找到结果即退出? Possibly Not! 如拓展(x)将导致距离增加0(x)或1(x+1),[这种情况用优先队列] 那么该拓展得到的结果也许并不是最优的,后面还有x. 所以最好的是遍历(不知怎么说 ...
- pytest 2.测试用例setup和teardown
之前我写的unittest的setup和teardown,还有setupClass和teardownClass(需要配合@classmethod装饰器一起使用),接下来就介绍pytest的类似于这类的 ...
- Mac下如何生成SSH Key-使用GitLab
步骤1.检查是否已经存在SSH Key 打开电脑终端,输入以下命令: ls -al ~/.ssh 会出现两种情况 步骤2. 生成/设置SSH Key 继续上一步可能出现的情况 (1)情况一:终端出现文 ...
- mysql中使用存储过程方法中的注意事项
public function getFxOrderList($openId,$condition='',$curentPage=1,$pagesize =10){ return $this-> ...
- (线段判交的一些注意。。。)nyoj 1016-德莱联盟
1016-德莱联盟 内存限制:64MB 时间限制:1000ms 特判: No通过数:9 提交数:9 难度:1 题目描述: 欢迎来到德莱联盟.... 德莱文... 德莱文在逃跑,卡兹克在追.... 我们 ...
- python之三元表达式、列表推导、生成器表达式、递归、匿名函数、内置函数
目录 一 三元表达式 二 列表推到 三 生成器表达式 四 递归 五 匿名函数 六 内置函数 一.三元表达式 def max(x,y): return x if x>y else y print( ...
- Python三十个常见的脚本汇总
1.冒泡排序 2.计算x的n次方的方法 这里有我自己整理了一套最新的python系统学习教程,包括从基础的python脚本到web开发.爬虫.数据分析.数据可视化.机器学习等.送给正在 ...
- mysql 将一张表的数据更新到另外一张表中
update 更新表 set 字段 = (select 参考数据 from 参考表 where 参考表.id = 更新表.id); update table_2 m set m.column = ...