python自动化-unittest批量执行用例(discover)
前言
我们在写用例的时候,单个脚本的用例好执行,那么多个脚本的时候,如何批量执行呢?这时候就需要用到unittet里面的discover方法来加载用例了。
加载用例后,用unittest里面的TextTestRunner这里类的run方法去一次执行多个脚本的用例。
一、新建测试项目
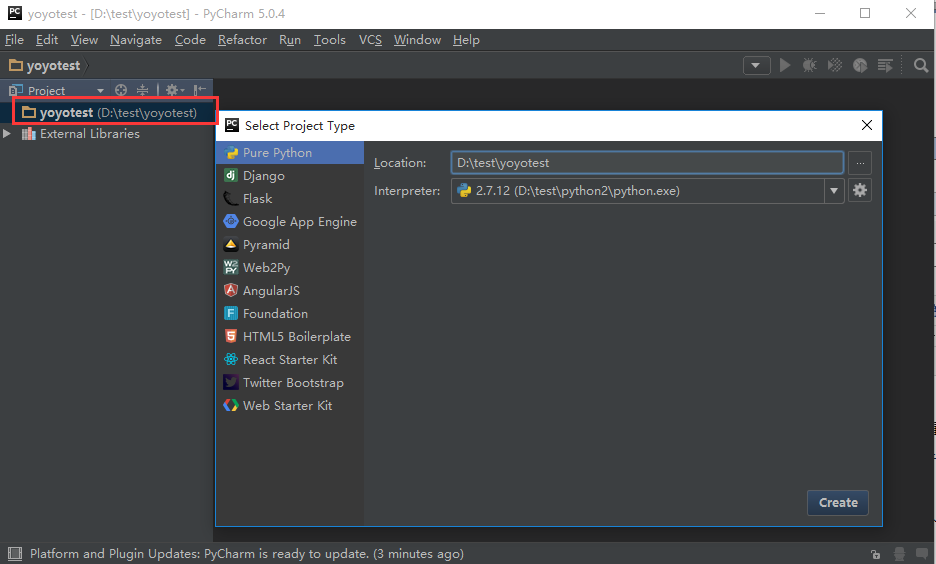
1.pycharm左上角File>New Projetc>Pure Python,在location位置命名一个测试工程的名称:yoyotest,然后保存
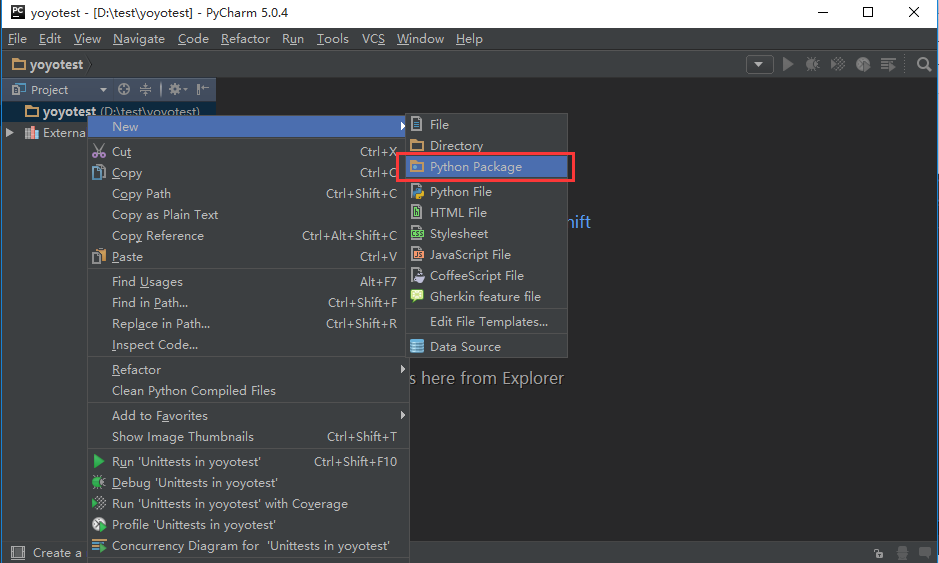
2.选中刚才新建的工程右键>New>Python Package>新建一个case文件夹
3.重复第2步的操作,新建一个case的文件夹,在里面添加一个baidu和一个blog的文件夹,里面分别有两个用例的脚本,如下图所示。
test_01,test_02,test_03,test_04是我们写用例的脚本
4.test_01创建完后,打开脚本,写入用例

5.在yoyotest这个项目下面创建一个脚本run_all_case.py,接下来用这个脚本去批量执行所有的用例。

二、diascover加载测试用例
1.discover方法里面有三个参数:
-case_dir:这个是待执行用例的目录。
-pattern:这个是匹配脚本名称的规则,test*.py意思是匹配test开头的所有脚本。
-top_level_dir:这个是顶层目录的名称,一般默认等于None就行了。
2.discover加载到的用例是一个list集合,需要重新写入到一个list对象testcase里,这样就可以用unittest里面的TextTestRunner这里类的run方法去执行。

3.运行后结果如下,就是加载到的所有测试用例了:
<unittest.suite.TestSuite tests=[<baidu.test_01.Test testMethod=test01>, <baidu.test_01.Test testMethod=test02>, <baidu.test_01.Test testMethod=test03>, <baidu.test_02.Test testMethod=test01>, <baidu.test_02.Test testMethod=test02>, <baidu.test_02.Test testMethod=test03>, <bolg.test_03.Test testMethod=test01>, <bolg.test_03.Test testMethod=test02>, <bolg.test_03.Test testMethod=test03>, <bolg.test_04.Test testMethod=test01>, <bolg.test_04.Test testMethod=test02>, <bolg.test_04.Test testMethod=test03>]>
三、run测试用例
1.为了更方便的理解,可以把上面discover加载用例的方法封装下,写成一个函数

2.参考代码:
# coding:utf-8
import unittest
import os
# 用例路径
case_path = os.path.join(os.getcwd(), "case")
# 报告存放路径
report_path = os.path.join(os.getcwd(), "report")
def all_case():
discover = unittest.defaultTestLoader.discover(case_path,
pattern="test*.py",
top_level_dir=None)
print(discover)
return discover
if __name__ == "__main__":
runner = unittest.TextTestRunner()
runner.run(all_case())
python自动化-unittest批量执行用例(discover)的更多相关文章
- python接口自动化(二十六)--批量执行用例 discover(详解)
简介 我们在写用例的时候,单个脚本的用例好执行,那么多个脚本的时候,如何批量执行呢?这时候就需要用到 unittest 里面的 discover 方法来加载用例了.加载用例后,用 unittest 里 ...
- Selenium2+python自动化53-unittest批量执行(discover)
前言 我们在写用例的时候,单个脚本的用例好执行,那么多个脚本的时候,如何批量执行呢?这时候就需要用到unittet里面的discover方法来加载用例了. 加载用例后,用unittest里面的Text ...
- Selenium2+python自动化53-unittest批量执行(discover)【转载】
前言 我们在写用例的时候,单个脚本的用例好执行,那么多个脚本的时候,如何批量执行呢?这时候就需要用到unittet里面的discover方法来加载用例了. 加载用例后,用unittest里面的Text ...
- selenium+python自动化90-unittest多线程执行用例
前言 假设执行一条脚本(.py)用例一分钟,那么100个脚本需要100分钟,当你的用例达到一千条时需要1000分钟,也就是16个多小时... 那么如何并行运行多个.py的脚本,节省时间呢?这就用到多线 ...
- Python自动化学习--批量执行.py用例
这段时间在摸索自动化,学到执行测试用例的时候发现,执行单用例的时候很简单,如果想多条用例执行的话就没那么简单了,经过几番查找,找到如下方法: unittest模块中的TestLoader类有一个dis ...
- python:unittest之discover()方法批量执行用例
自动化测试过程中,自动化覆盖的功能点和对应测试用例之间的关系基本都是1 VS N,如果每次将测试用例一个个单独执行,不仅效率很低, 无法快速反馈测试结果,而且维护起来很麻烦.在python的单元测试框 ...
- Python 中使用 ddt 来进行数据驱动,批量执行用例,修改ddt代码
1. 什么是数据驱动? 使用数据驱动有什么好处? 用例执行是靠数据来驱动的,每条测试用例除了测试数据不一样意外,所有的用例代码都是一样的,为了使用例批量执行,我们会使用数据驱动的思想来批量执行测试用例 ...
- 3.3 unittest批量执行
3.3 unittest批量执行 我们在写用例的时候,单个脚本的用例好执行,那么多个脚本的时候,如何批量执行呢?这时候就需要用到unittet里面的discover方法来加载用例了.加载用例后,用un ...
- unittest(执行用例)
from selenium import webdriver from time import sleep import unittest#导入unittest库 import HTMLTestRun ...
随机推荐
- 迅为4412开发板QtE系统源码-屏幕横竖屏切换修改方法
迅为4412开发板QtE系统源码-屏幕横竖屏切换修改方法 详情了解:http://topeetboard.com 更多了解:https://arm-board.taobao.com/ 用户在开发板上运 ...
- 使用flask_socketio实现客户端间即时通信
前期没有来得及好好总结,现在复习总结一下: Socket.IO 背后主要的思想是你可以发送和接收想要的任何事件,携带你想要的任何数据.任何可以编码为 JSON 的对象都可以做到,并且也支持二进制数据. ...
- javascript判断节点是否在dom
在项目中碰到同事写的一段代码: //焦点必须在实时dom树中 if (ele && typeof this.document.contains === "function&q ...
- Linux中find命令的用法汇总
Linux中find命令的用法汇总 https://www.jb51.net/article/108198.htm
- ASP.NET MVC - 发布web应用程序、部署到IIS
发布项目 右击项目 - 发布 选择IIS - 点击发布 发布方法 - 文件系统,目标位置 - 选择与项目所在目录不同的目录(也即,指定一个发布生成文件的目录),文件发布选项 - 不选 - 点击发布 安 ...
- 1421 - Wavio Sequence
题目大意:求一个序列中 先严格递增后严格递减的子序列的数目(要求这个子序列对称). 题目思路:正一遍DP,反一遍DP,因为n<=1e5,dp要把时间压缩到nlogn #include<st ...
- light oj 1254 - Prison Break 最短路
题目大意:n个点m条边的有向图,q次询问c,s,t,表示汽车邮箱容量为c,求从起点s到终点t的最小费用.汽车在每个点可以加任意的油,每个点的单位油价为a[i]. 题目思路:利用最小费优先队列优化最短路 ...
- SQL操作json类型数据的函数
MySQL5.7之后对json数据格式进行了函数支持 Json_contains(字段名, '值') 1.表中json格式的某个字段 2.json里的某个键值 Json_search(字段名, 'on ...
- 【Linux】时间同步设置+防火墙设置+SELinux设置
时间同步设置 在大数据集群环境中,要求每台集群的时间必须是同步的,这样我们就会要求每台集群的时间必须和一台服务的时间是同步的.接下来介绍一下步骤: 1,设置ntp客户端 yum -y install ...
- C++ 模式设计
只写了MinGw/Linux API部分.所有相关的代码都是参考C++ API C++ 11智能指针参考http://blog.csdn.net/zy19940906/article/details/ ...