关于交叉熵(cross entropy),你了解哪些
二分~多分~Softmax~理预
一、简介
在二分类问题中,你可以根据神经网络节点的输出,通过一个激活函数如Sigmoid,将其转换为属于某一类的概率,为了给出具体的分类结果,你可以取0.5作为阈值,凡是大于0.5的样本被认为是正类,小于0.5则认为是负类
然而这样的做法并不容易推广到多分类问题。多分类问题神经网络最常用的方法是根据类别个数n,设置n个输出节点,这样每个样本神经网络都会给出一个n维数组作为输出结果,然后我们运用激活函数如softmax,将输出转换为一种概率分布,其中的每一个概率代表了该样本属于某类的概率。
比如一个手写数字识别这种简单的10分类问题,对于数字1的识别,神经网络模型的输出结果应该越接近\([0, 1, 0, 0, 0, 0, 0, 0, 0, 0]\)越好,其中\([0, 1, 0, 0, 0, 0, 0, 0, 0, 0]\)是最理想的结果了
但是如何衡量一个神经网络输出向量和理想的向量的接近程度呢?交叉熵(cross entropy)就是这个评价方法之一,他刻画了两个概率分布之间的距离,是多分类问题中常用的一种损失函数
二、交叉熵
给定两个概率分布:p(理想结果即正确标签向量)和q(神经网络输出结果即经过softmax转换后的结果向量),则通过q来表示p的交叉熵为:
\(H(p, q) = - \sum_xp(x)logq(x)\)
注意:既然p和q都是一种概率分布,那么对于任意的x,应该属于\([0, 1]\)并且所有概率和为1
\(\forall x p(X=x) \epsilon [0,1]\)且\(\sum_xp(X=x) =1\)
交叉熵刻画的是通过概率分布q来表达概率分布p的困难程度,其中p是正确答案,q是预测值,也就是交叉熵值越小,两个概率分布越接近
三、三分类实例讲解交叉熵
其中某个样本的正确答案即p是\([1,0, 0]\),某模型经过Softmax激活后的答案即预测值q是\([0.5, 0.4, 0.1]\),那么这个预测值和正确答案之间的交叉熵为:
\(H(p=[1,0,0], q=[0.5,0.4,0.1]) = -(1*log0.5 + 0*log0.4 + 0*log0.1) \approx 0.3\)
如果另外一个模型的预测值q是\([0.8, 0.1, 0.1]\),那么这个预测值和正确答案之间的交叉熵为:
\(H(p=[1,0,0], q=[0.8,0.1,0.1]) = -(1*log0.8 + 0*log0.1 + 0*log0.1) \approx 0.1\)
从直观上可以很容易的知道第二个预测答案要优于第一个,通过交叉熵计算得到的结果也是一致的(第二个交叉熵值更小)
而TF中很容易做到交叉熵的计算:
import tensorflow as tf cross_entropy = -tf.reduce_mean( y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)) )
上述代码包含了四种不同的TF运算,解释如下:
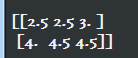
1)tf.clip_by_value():将一个张量中的数值限制在一个范围内,如限制在\([0.1, 1.0]\)范围内,可以避免一些运算错误,如预测结果q中元素可能为0,这样的话log0是无效的
v = tf.constant([[1.0, 2.0, 3.0], [4.0,5.0,6.0] ])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(tf.clip_by_value(v, 2.5, 4.5).eval())
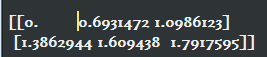
2)tf.log():对张量中的所有元素依次求对数
v = tf.constant([[1.0, 2.0, 3.0], [4.0,5.0,6.0] ])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(tf.log(v).eval())
3)乘法运算:*操作,是元素之间直接相乘,而矩阵相乘用tf.matmul函数来完成
v1 = tf.constant([ [1.0, 2.0], [3.0, 4.0]])
v2 = tf.constant([ [5.0, 6.0], [7.0, 8.0]])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print( (v1 * v2).eval() )
print( tf.matmul(v1, v2).eval() )

4)求和:上面三个运算完成了每个样例中每个类别的交叉熵\(p(x)logq(x)\)的计算,还未进行求和运算
即:三步计算后得到的结果是个n * m的二维矩阵,其中n为一个batch中样本数量,m为分类的类别数量,比如十分类问题,m为10.根据交叉熵公式
最后是要将每行中m个结果相加得到每个样本的交叉熵,然后再对这n行取平均得到一个batch的平均交叉熵,即-tf.reduce_mean()函数来实现
总结:因为交叉熵一般会与softmax一起使用,所以TF对这两个功能进行了封装,并提供了tf.nn.softmax_cross_entropy_with_logits函数
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y, y_)
#y:原始神经网络的输出结果
#y_:标准答案
#这样一个函数即可实现使用了Softmax后的交叉熵
关于Softmax计算过程,可以参考:实战Google深度学习框架-C4-深层神经网络
关于交叉熵(cross entropy),你了解哪些的更多相关文章
- 最大似然估计 (Maximum Likelihood Estimation), 交叉熵 (Cross Entropy) 与深度神经网络
最近在看深度学习的"花书" (也就是Ian Goodfellow那本了),第五章机器学习基础部分的解释很精华,对比PRML少了很多复杂的推理,比较适合闲暇的时候翻开看看.今天准备写 ...
- 交叉熵cross entropy和相对熵(kl散度)
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量真实分布p与当前训练得到的概率分布q有多么大的差异. 相对熵(relativ ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
- 『TensorFlow』分类问题与两种交叉熵
关于categorical cross entropy 和 binary cross entropy的比较,差异一般体现在不同的分类(二分类.多分类等)任务目标,可以参考文章keras中两种交叉熵损失 ...
- TensorFlow 实战(一)—— 交叉熵(cross entropy)的定义
对多分类问题(multi-class),通常使用 cross-entropy 作为 loss function.cross entropy 最早是信息论(information theory)中的概念 ...
- 【机器学习基础】交叉熵(cross entropy)损失函数是凸函数吗?
之所以会有这个问题,是因为在学习 logistic regression 时,<统计机器学习>一书说它的负对数似然函数是凸函数,而 logistic regression 的负对数似然函数 ...
- 关于交叉熵损失函数Cross Entropy Loss
1.说在前面 最近在学习object detection的论文,又遇到交叉熵.高斯混合模型等之类的知识,发现自己没有搞明白这些概念,也从来没有认真总结归纳过,所以觉得自己应该沉下心,对以前的知识做一个 ...
- 【联系】二项分布的对数似然函数与交叉熵(cross entropy)损失函数
1. 二项分布 二项分布也叫 0-1 分布,如随机变量 x 服从二项分布,关于参数 μ(0≤μ≤1),其值取 1 和取 0 的概率如下: {p(x=1|μ)=μp(x=0|μ)=1−μ 则在 x 上的 ...
- 熵(Entropy),交叉熵(Cross-Entropy),KL-松散度(KL Divergence)
1.介绍: 当我们开发一个分类模型的时候,我们的目标是把输入映射到预测的概率上,当我们训练模型的时候就不停地调整参数使得我们预测出来的概率和真是的概率更加接近. 这篇文章我们关注在我们的模型假设这些类 ...
随机推荐
- python爬虫requests模块
requests库的七个主要方法 1. requests.requests(method, url, **kwargs) 构造一个请求,支撑以下各方法的基础方法 method:请求方式,对应get/p ...
- python 模块之-time
python 模块time import time # 1 time() :返回当前时间的时间戳 time.time() #1473525444.037215 #------------------- ...
- 【hdu 6172】Array Challenge(数列、找规律)
多校10 1002 HDU 6172 Array Challenge 题意 There's an array that is generated by following rule. \(h_0=2, ...
- linux中监控CPU、内存和磁盘状态的shell脚本。(centos7)
这篇博客中所写的脚本,在实际工作中并没有什么卵用,工作中并不会用到这种脚本去监控.不过自己写一遍,可以让初学者对CPU.内存.磁盘等一些基础知识和基础命令更加了解. 1.利用vmstat工具监控CPU ...
- 【WC2018】即时战略(动态点分治,替罪羊树)
[WC2018]即时战略(动态点分治,替罪羊树) 题面 UOJ 题解 其实这题我也不知道应该怎么确定他到底用了啥.只是想法很类似就写上了QwQ. 首先链的部分都告诉你要特殊处理那就没有办法只能特殊处理 ...
- 【BZOJ5323】[JXOI2018]游戏(组合计数,线性筛)
[BZOJ5323][JXOI2018]游戏(组合计数,线性筛) 题面 BZOJ 洛谷 题解 显然要考虑的位置只有那些在\([l,r]\)中不存在任意一个约数的数. 假设这样的数有\(x\)个,那么剩 ...
- rt-thread之 for (fn_ptr = &__rt_init_rti_board_start; fn_ptr < &__rt_init_rti_board_end; fn_ptr++) 理解
@2019-01-30 [小记] 利用宏 INIT_EXPORT() --- __attribute__() 将函数重新放置在自定义段,执行时去该段获取函数地址 RT-Thread 的 INIT_BO ...
- 每天一个linux命令(1):wc命令
Linux系统中的wc(Word Count)命令的功能为统计指定文件中的字节数.字数.行数,并将统计结果显示输出. 1.命令格式: wc [选项]文件... 2.命令功能: 统计指定文件中的字节数. ...
- BZOJ4669抢夺(费用流+二分答案)
题目描述 大战将至, 美国决定实行计划经济.美国西部总共有 N 个城市,编号 为 0 ∼ N − 1,以及 M 条道路,道路是单向的.其中城市 0 是一个大城 市,里面住着 K 个人,而城市 N − ...
- LOJ6089 小Y的背包计数问题(根号优化背包)
Solutioon 这道题利用根号分治可以把复杂度降到n根号n级别. 我们发现当物品体积大与根号n时,就是一个完全背包,换句话说就是没有了个数限制. 进一步我们发现,这个背包最多只能放根号n个物品. ...