python爬取今日头条关键字图集
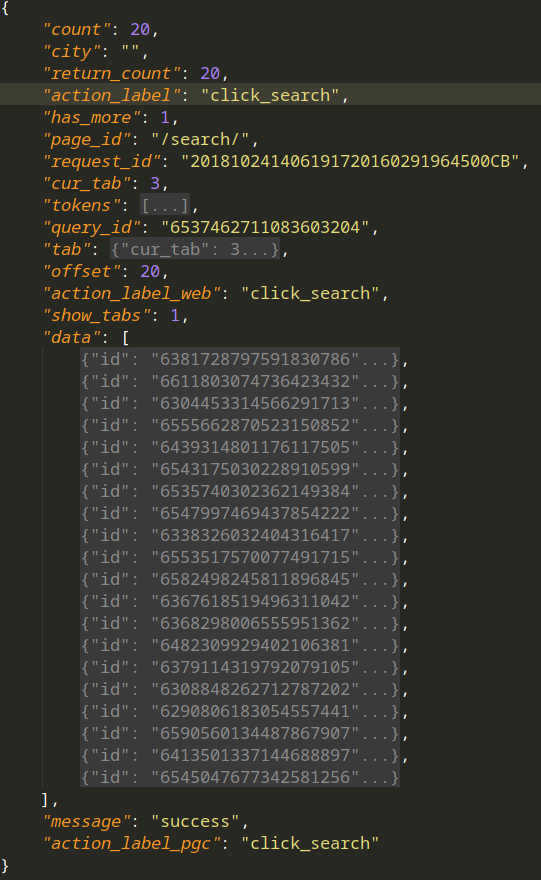
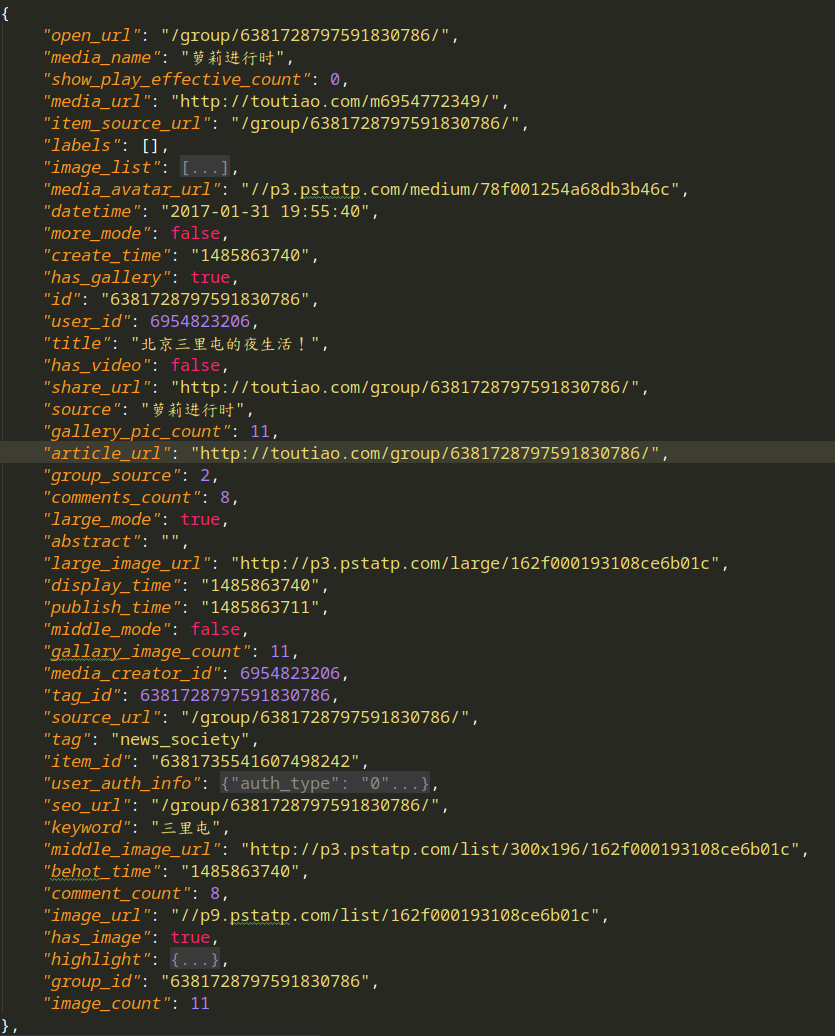
1.访问搜索图集结果,获得json如下(右图为data的一条的详细内容).页面以Ajax呈现,每次请求20个图集,其中
title --- 图集名字
artical_url --- 图集的地址
count --- 图集图片数量
2. 访问其中的图集
访问artical_url,获得图集图片详细信息,其中图片url为下载地址

展现出爬虫关键部分,整体项目地址在https://github.com/GeoffreyHub/toutiao_spider
#!/usr/bin/env python
# encoding: utf-8 """
@version: python37
@author: Geoffrey
@file: spider.py
@time: 18-10-24 上午11:15
"""
import json
import re
from multiprocessing import Pool
import urllib3
urllib3.disable_warnings()
from requests import RequestException from common.request_help import make_session
from db.mysql_handle import MysqlHandler
from img_spider.settings import * class SpiderTouTiao: def __init__(self, keyword):
self.session = make_session(debug=True)
self.url_index = 'https://www.toutiao.com/search_content/'
self.keyword = keyword
self.mysql_handler = MysqlHandler(MYSQL_CONFIG) def search_index(self, offset):
url = self.url_index
data = {
'offset': f'{offset}',
'format': 'json',
'keyword': self.keyword,
'autoload': 'true',
'count': '',
'cur_tab': '',
'from': 'gallery'
} try:
response = self.session.get(url, params=data)
if response.status_code is 200:
json_data = response.json()
with open(f'../json_data/搜索结果-{offset}.json', 'w', encoding='utf-8') as f:
json.dump(json_data, f, indent=4, ensure_ascii=False)
return self.get_gallery_url(json_data)
except :
pass
print('请求失败') @staticmethod
def get_gallery_url(json_data):
dict_data = json.dumps(json_data)
for info in json_data["data"]:
title = info["title"]
gallery_pic_count = info["gallery_pic_count"]
article_url = info["article_url"]
yield title, gallery_pic_count, article_url def gallery_list(self, search_data):
gallery_urls = {}
for title, gallery_pic_count, article_url in search_data:
print(title, gallery_pic_count, article_url)
response = self.session.get(article_url)
html = response.text
images_pattern = re.compile('gallery: JSON.parse\("(.*?)"\),', re.S)
result = re.search(images_pattern, html) if result:
# result = result.replace('\\', '')
# result = re.sub(r"\\", '', result)
result = eval("'{}'".format(result.group(1)))
result = json.loads(result)
# picu_urls = zip(result["sub_abstracts"], result["sub_titles"], [url["url"] for url in result["sub_images"]])
picu_urls = zip(result["sub_abstracts"], [url["url"] for url in result["sub_images"]])
# print(list(picu_urls))
gallery_urls[title] = picu_urls
else:
print('解析不到图片url') with open(f'../json_data/{title}-搜索结果.json', 'w', encoding='utf-8') as f:
json.dump(result, f, indent=4, ensure_ascii=False) break # print(gallery_urls)
return gallery_urls def get_imgs(self, gallery_urls):
params = []
for title, infos in (gallery_urls.items()):
for index, info in enumerate(infos):
abstract, img_url = info
print(index, abstract)
response = self.session.get(img_url)
img_content = response.content
params.append([title, abstract, img_content]) with open(f'/home/geoffrey/图片/今日头条/{title}-{index}.jpg', 'wb') as f:
f.write(img_content) SQL = 'insert into img_gallery(title, abstract, imgs) values(%s, %s, %s)'
self.mysql_handler.insertOne(SQL, [title, abstract, img_content])
self.mysql_handler.end() print(f'保存图集完成' + '-'*50 )
# SQL = 'insert into img_gallery(title, abstract, imgs) values(%s, %s, %s)'
# self.mysql_handler.insertMany(SQL, params)
# self.mysql_handler.end() def main(offset):
spider = SpiderTouTiao(KEY_WORD)
search_data = spider.search_index(offset)
gallery_urls = spider.gallery_list(search_data)
spider.get_imgs(gallery_urls)
spider.mysql_handler.dispose() if __name__ == '__main__':
groups = [x*20 for x in range(GROUP_START, GROPE_END)] pool = Pool(10)
pool.map(main, groups) # for i in groups:
# main(i)
项目结构如下:
.
├── common
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-37.pyc
│ │ └── request_help.cpython-37.pyc
│ ├── request_help.py
├── db
│ ├── __init__.py
│ ├── mysql_handle.py
│ └── __pycache__
│ ├── __init__.cpython-37.pyc
│ └── mysql_handle.cpython-37.pyc
├── img_spider
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-37.pyc
│ │ └── settings.cpython-37.pyc
│ ├── settings.py
│ └── spider.py
└── json_data
├── 沐浴三里屯的秋-搜索结果.json
├── 盘点三里屯那些高逼格的苍蝇馆子-搜索结果.json
├── 搜索结果-0.json
├── 搜索结果-20.json
├── 搜索结果-40.json
python爬取今日头条关键字图集的更多相关文章
- Python爬取今日头条段子
刚入门Python爬虫,试了下爬取今日头条官网中的段子,网址为https://www.toutiao.com/ch/essay_joke/源码比较简陋,如下: import requests impo ...
- python爬取今日头条图片
import requests from urllib.parse import urlencode from requests import codes import os # qianxiao99 ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- python 简单爬取今日头条热点新闻(一)
今日头条如今在自媒体领域算是比较强大的存在,今天就带大家利用python爬去今日头条的热点新闻,理论上是可以做到无限爬取的: 在浏览器中打开今日头条的链接,选中左侧的热点,在浏览器开发者模式netwo ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
随机推荐
- windows与mac下安装nginx
window下 下载链接,自己选一个版本下载 nginx官网下载 本人放在D盘: 启动nginx 有很多种方法启动nginx (1)直接双击nginx.exe,双击后一个黑色的弹窗一闪而过 (2)打开 ...
- 进程与程序 并行 并发 串行 阻塞 join函数
进程是正在运行的程序,程序是程序员编写的一对代码,也就是一堆字符,当这堆代码被系统加载到内存并执行,就有了进程. (需要注意的是:一个程序是可以产生多个程序,就像我们可以同时运行多个QQ程序一样,会形 ...
- jsp 错误处理
JSP提供了很好的错误处理能力.除了在Java代码 中可以使用try语句,还可以指定一个特殊页面.当应 用页面遇到未捕获的异常时,用户将看到一个精心设计 的网页解释发生了什么,而不是一个用户无法理解的 ...
- CF1005F
这题不错... 首先,不难看到他想让你求出的是最短路树 然后,考虑到所有边权均为1,所以可以采用bfs直接生成最短路树 至于方案的储存,可以在加边的时候同时记录边的编号,然后对每个点维护一个能转移他的 ...
- this容易混淆的示例
[注]this 永远不会混乱,混乱的是我们而已. /* this永远指向当前函数的主人. this混乱: 1.添加了定时器/延时器 2.事件绑定 [注]函数如果发生了赋值,this就混乱了. */ 示 ...
- Python(列表操作应用实战)方法二
# 输入一个数据,删除一个列表中的所有指定元素# 给定的列表数据data = [1,2,3,4,5,6,7,8,9,0,5,4,3,5,"b","a",&quo ...
- HDU 1671 Phone List (qsort字符串排序与strncmp的使用 /字典树)
Phone List Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total ...
- POJ 1002 487-3279(字典树/map映射)
487-3279 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 309257 Accepted: 5 ...
- python基础知识之zip
names =['zhangning','lsl','lyq','xww']age = [1,2,3,4]for a,b in zip(names,age): print(a,b)S = 'abcde ...
- node.js vue-axios和vue-resource
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...