face detection[CNN casade]
本文是基于《 A convolutional neural network cascade for face detection》的解读,所以时间线是2015年。
0 引言
人脸检测是CV社区中一直研究的问题,现在大多的人脸检测器都可以很容易的检测正脸或者接近正脸。所以人们开始关心如何解决在无约束条件下的人脸检测问题。而无约束条件下的人脸包含:姿态变化,夸张的表情和极端的光照变化,而这些也会引起人脸外观的变化,所以就很容易导致人脸检测器都不够鲁棒。
人脸检测的问题主要来自两方面:
- 在嘈杂背景下的人脸的视觉变化;
- 人脸位置和人脸大小导致的超大搜索空间。
前者需要人脸检测器加速处理一个二分类问题;而后者需要处理时间复杂度问题。而且不同于通用的目标检测任务,无约束人脸检测使得其无法直接使用RCNN这种方法去实现,主要是因为图片中,有些人脸十分小,而且有复杂的外观变化。
前人在级联人脸检测上的工作较为成功的是用haar做特征,用前面的模型过滤大量的背景位置,从而减少搜索空间。后人的工作多是如何提取更有效的特征来提升准确度,且因为采用了更复杂的特征每一层模型消耗时间增加了,可是级联的层数也少了。所以相对的,总体时间反而比最初直接haar的多级联模型时间更少了。这也给作者启示,用现在大热的CNN来作为特征的提取方式。用级联cnn的方式,
- 先在开始的低分辨率阶段,快速的拒绝大量的假阳性窗口;
- 然后在后面的高分辨率阶段,小心的验证检测结果。
在cpu上达到了14FPS;gpu上100FPS。
本文贡献有:
- 提出CNN级联来快速的做人脸检测;
- 引入一个窗口校正阶段用于帮助加速CNN级联然后获得高质量的定位。
- 提出一个多分辨率CNN结构,比单分辨率CNN有更好的辨别性;
- 提升了FDDB数据集上的最好结果记录。
1 级联CNN
如图1所示,就是通过不断的级联来减少候选区域

给定一个测试图片:
- 12-net扫描整个图片:基于不同尺度的图片快速扫描,并拒绝90%的检测框;(此时网络输入为12×12,检测框大小为12x12)
- 剩下的框先裁剪出来,然后resize成12x12以适应12-calibration-net的输入,获取其校正变量,来校正检测框大小。通过调整大小和定位来接近潜在的人脸区域;(此时网络输入为12x12,检测框大小被该网络调整,假定为AxB)
- 用NMS去消除一些高度重复的检测框;
- 剩下的检测窗口被裁剪出来,然后resize成24x24大小的作为24-net的输入,并拒绝90%的检测窗口;(此时网络输入为24x24,检测框大小为AxB)
- 如之前的流程,剩下的检测窗口被24-calibration-net所调整,然后用NMS消除高度重复的框;(此时网络输入为24x24,检测框大小被该网络调整,检测框大小为CxD)
- 最后的48-net接收48x48大小的框并评估这些检测窗口。NMS用一个大于之前阈值的IOU比例去消除重复的检测窗口;
- 最后用48-calibration-net去校正剩下的框,然后作为结果输出。(最后输出的检测框大小为ExF)
1.1 12-net
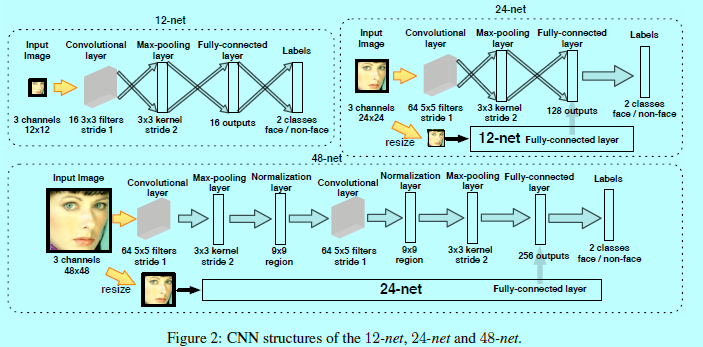
如图2所示,12-net是一个十分浅的网络,其能快速的扫描整个测试图片。假设一个图片的输入为\(W\times H\),以4个像素为间隔,那么一共有\((\left \lfloor (W-12)/4 \right \rfloor + 1)\times (\left \lfloor (H-12)/4 \right \rfloor +1)\)个\(12\times12\)大小的划框,这么多划框可以组成一个置信得分map,其中每个点就是对应的一个划框的评估值。
在实际实现中,如果最小人脸大小为\(F\times F\)。首先将测试图片以图片金字塔进行构建,每一层的缩放因子为\(\frac{12}{F}\),将这些作为12-net的输入。假设图片大小为\(800\times 800\),最小接受人脸为\(40x40\),间隔为4个像素,那么首先进行一次缩放,为\(240\times 180\),将该图片输入到12-net中,可得到2494个划框。
1.2 12-calibration-net
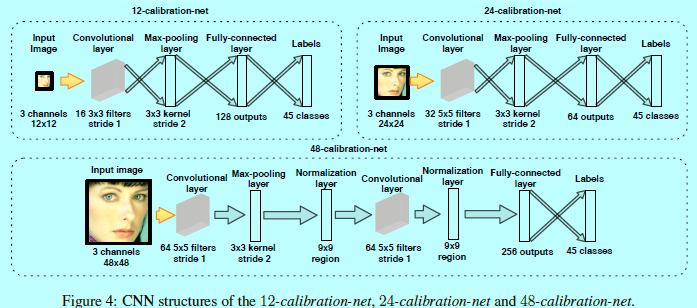
如图4所示,12-calibration-net是接在12-net后面的,用于后选框的校正。该网络也是一个较为浅的网络。先预定义N个校对模式,该N个校准模式被预定义为一组3维尺度变化和偏移矢量\({\left [ s_n,x_n,y_n \right ]}^N_{n=1}\)。假定一个检测框为\((x,y,w,h)\),表示为左上角坐标\((x,y)\),宽高为\((w,h)\),那么调整该窗口的校对模式为:
\[(x-\frac{x_nw}{s_n}, y-\frac{y_nh}{s_n}, \frac{w}{s_n}, \frac{h}{s_n})\]
本文中,\(N=45\),即从下面的参数组合而来:

给定一个检测窗口,将该区域裁剪出来,然后resize到12x12大小,然后输入到12-calibration-net,该网络输出一个置信度得分向量\([c_1,c_2,...,c_N]\)。因为calibration模式不是相互正交的,所以将高置信度的平均结果作为调整\([s,x,y]\),如:
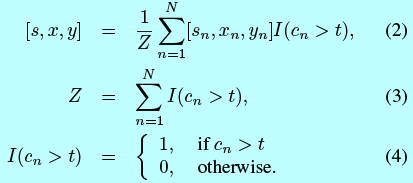
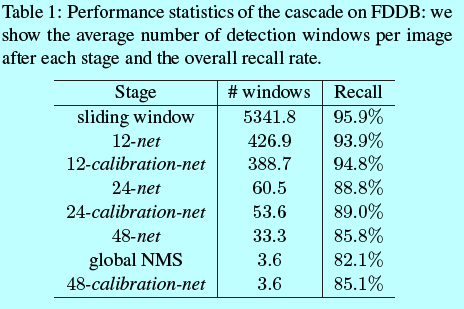
这里t是过滤低置信模式的阈值。在实验中(如表1),FDDB数据集上,12-net和12-calibration-net就能拒绝92.7%的检测窗口,并且保持94.8%的召回率
1.3 24-net
24-net是一个中间的二分类CNN,用来进一步减少检测框的数量,将12-calibration-net输出的检测框裁剪出来,然后resize成24x24,并用24-net进行评估。这里有一个多分辨率网络结构设计,如图2所示,这些裁剪出来的检测框还会进一步resize成12x12,然后用12-net进行评估,将其全连接层拼接到24-net的全连接层,然后再进行最后的分类,增加12-net的输入是为了检测那些小尺寸人脸,使得总的CNN结构更具有分辨性,且12-net的网络计算量也并不大。如图3,这里做了有和没有多分辨率网结构的24-net,可以看到在相同的召回率上,有多分辨率设计的结构可以得到更少的假检测窗口。在更高的召回率上,差距就更明显了

1.4 24-calibration-net
类似12-calibration-net,实验中,24-net和24-calibration-net可以拒绝86.2%的检测框,并且在经过24-calibration-net的修正之后,还能保持89.0%的召回率。
1.5 48-net
类似24-net,如图2,增加了一个多分辨率结构设计,其中的子网络结构就是24-net。
1.6 48-calibration-net
如图4,采用了45个校对模式,这里只是用一层池化层来保证更多精确的校正。
1.7 NMS
在12-calibration-net和24-calibration-net后面,基于相同的尺度检测框下进行NMS,以避免召回率的下降;而在48-net之后,是针对所有检测框进行NMS,以保证在正确的尺度上能够避免较多的冗余。
2 CNN的校对网络

如图5。置信度最高的检测框可能并不能够很好地框住人脸,而如果没有校对这一过程,那么在级联的下一层就需要评估更多地区域来维持一个较高的召回率。总的检测时间就会上升。
参考文献:
- Li H, Lin Z, Shen X, et al. A convolutional neural network cascade for face detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 5325-5334.
face detection[CNN casade]的更多相关文章
- 利用神经网络进行网络流量识别——特征提取的方法是(1)直接原始报文提取前24字节,24个报文组成596像素图像CNN识别;或者直接去掉header后payload的前1024字节(2)传输报文的大小分布特征;也有加入时序结合LSTM后的CNN综合模型
国外的文献汇总: <Network Traffic Classification via Neural Networks>使用的是全连接网络,传统机器学习特征工程的技术.top10特征如下 ...
- Applied Deep Learning Resources
Applied Deep Learning Resources A collection of research articles, blog posts, slides and code snipp ...
- ImageNet && 医学图像的识别
医学图像识别的问题 如果将CNN应用于医学图像,首要面对的问题是训练数据的缺乏.因为CNN的训练数据都需要有类别标号,这通常需要专家来手工标记.要是标记像ImageNet这样大规模的上百万张的训练图像 ...
- Machine Learning 资料
Awesome系列 Awesome Machine Learning Awesome Deep Learning Awesome TensorFlow Awesome TensorFlow Imple ...
- Paper List ABOUT Deep Learning
Deep Learning 方向的部分 Paper ,自用.一 RNN 1 Recurrent neural network based language model RNN用在语言模型上的开山之作 ...
- caffeModels--models-caffes-大全
caffe的伯克利主页:http://caffe.berkeleyvision.org/caffe的github主页:https://github.com/BVLC/caffe caffe的model ...
- Deep learning_CNN_Review:A Survey of the Recent Architectures of Deep Convolutional Neural Networks——2019
CNN综述文章 的翻译 [2019 CVPR] A Survey of the Recent Architectures of Deep Convolutional Neural Networks 翻 ...
- Deep Learning方向的paper
转载 http://hi.baidu.com/chb_seaok/item/6307c0d0363170e73cc2cb65 个人阅读的Deep Learning方向的paper整理,分了几部分吧,但 ...
- 【零基础】speech driven animation中文安装使用指南
注:原项目名叫Speech-Driven Animation,所以我这里就简称为SDA 开局一张图,后面自动编 相信前段时间爆火的DeepNude(AI扒衣)让很多人惊掉了大牙,AI还能干这个?!如果 ...
随机推荐
- CSS3 Transform、Transition和Animation属性总结
CSS3的三个与变形和动画啊相关的属性: Transform 浏览器支持情况: Internet Explorer 10.Firefox.Opera 支持 transform 属性. Internet ...
- python安装小结
一.python下载地址:http://www.activestate.com/activepython/downloads 二.1.没有安装request会出一下错误: 2.解决办法:pip ins ...
- MFC 键盘响应
键盘响应 插入函数:在...对话框/menu中进入建立类模式,建立preTranslateMessage(MSG * pMsg) 在CXXXView类中,添加: BOOL CMy9_1View::Pr ...
- 上了IPD和CMMI,为什么还要搞敏捷?
文/资深顾问 杨学明 现在国内许多产品创新型企业一旦研发团队上了规模,就会进行IPD体系的变革或CMMI的认证,但现在还有一种更加流程的开发模式,就是敏捷,华为公司早在2009年正式发文在全公司现在流 ...
- 2014年11月17~11月18日,杨学明老师《企业IT需求收集和实施》内训在湖南长沙某酒店成功举办!
2014年11月17至18日,受湖南某软件企业的邀请,杨学明老师<企业IT需求收集和实施>内训在某长沙某五星级酒店成功举办!来自全国各地的IT高管和企业负责人参加了此次培训.杨学明老师分别 ...
- HttpWebRequest 请求带OAuth2 授权的webapi
OAuth 2.0注意事项: 1. 获取access_token时,请使用POST private static string GetAuthorization(string username, st ...
- 批量修改所有服务器的dbmail配置
最近遇到这样一个案例,需要修改所有SQL Server的Database Mail的SMTP,原来的SMTP为10.xxx.xxx.xxx, 现在需要修改为192.168.xxx.xxx, 另外需要规 ...
- myBase7.0破解
永久性破解 Mybase7Pro破解版下载:链接:https://pan.baidu.com/s/1ezb8bSqI0OPZnVgx-snA_Q 提取码:n72t 1.下载后安装 myBase-De ...
- Mysql内置优化工具show profiles
一.概述: Mysql的explain工具目前还没有Oracle的explain plan工具那么强大,但是结合show profiles工具可以实现相似的效果.show profiles语句用于在当 ...
- win7 中 sql server2005 卸载简介
注:卸载前一定要做好备份,一定要清理干净,不然重装会出错(只针对完全卸载,没试过只删除一个版本的) 工具:①Windows Install Clean Up ②SrvInstw.exe 1.停止所有 ...