python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。(引用自:百度百科)
scrapy官方网站:https://scrapy.org/
scrapy官方文档:https://doc.scrapy.org/en/latest/
scrapy框架安装
首先我们安装scrapy,使用如下命令
pip install scrapy
此时很多人应该都会遇到如下问题
error: Microsoft Visual C++ 10.0 is required.
Get it with "Microsoft Windows SDK 7.1": www.microsoft.com/download/details.aspx?id=8279
这是因为scrapy中使用了许多C++的内容,所以在安装时需要首先有C++ 10.0环境。最直接的解决办法就是下载并安装Microsoft Visual C++ 10.0。但为此下一个这么大的环境,配置又是蛋疼的巨硬风,实在令人畏惧。
所以笔者建议采用第二种方式,我们仔细观察到pip报错前正在运行
Running setup.py clean for Twisted
Failed to build Twisted
也就是说是安装Twisted模块时出错了,那么我们可以选择手动下载Twisted模块并安装。python的各种库有很多下载地,不少人可能会下载到 Twisted-xx.x.x.tar.bz2 ,解压后进行安装,发现会出现同样的错误。此时我们仔细观察之前安装scrapy时的信息,就会发现,pip指令自动安装时其实也是采用的下载 bz2 文件,解压,运行解压出的setup.py文件,所以这与我们上述的手动安装过程并没有任何区别。
笔者推荐一个网站https://www.lfd.uci.edu/~gohlke/pythonlibs,此网站中包含几乎所有常用的python库。例如我们此次需要下载Twisted库,那么我们在网页中搜索Twisted,然后下载自己对应位数和python版本的Twisted库。然后在Twisted下载位置运行cmd,执行如下命令(记得替换为自己下载的文件名)
pip install Twisted-xx.x.x-cpxx-cpxxm-win_amd64.whl
然后我们只需要等待其运行完成安装,至此我们安装好了scrapy必须的Twisted库,然后我们重新执行
pip install scrapy
安装成功!
在安装过程中,我们可以看到它为我们下载了许多辅助库,这使得scrapy成为了一个完整的成体系的爬虫框架,这些框架极大地简化了我们的编程难度,降低了学习成本。
scrapy是基于requests库搭建的,所以我们还需要执行以下命令
pip install requests
至此,我们已经完成了scrapy爬虫框架的安装。
scrapy爬虫模板介绍
scrapy是一个系统的框架,使用前的准备工作与其他一些爬虫库相比略显复杂,但这有限的几步,能够极大地降低我们后续编程的难度。
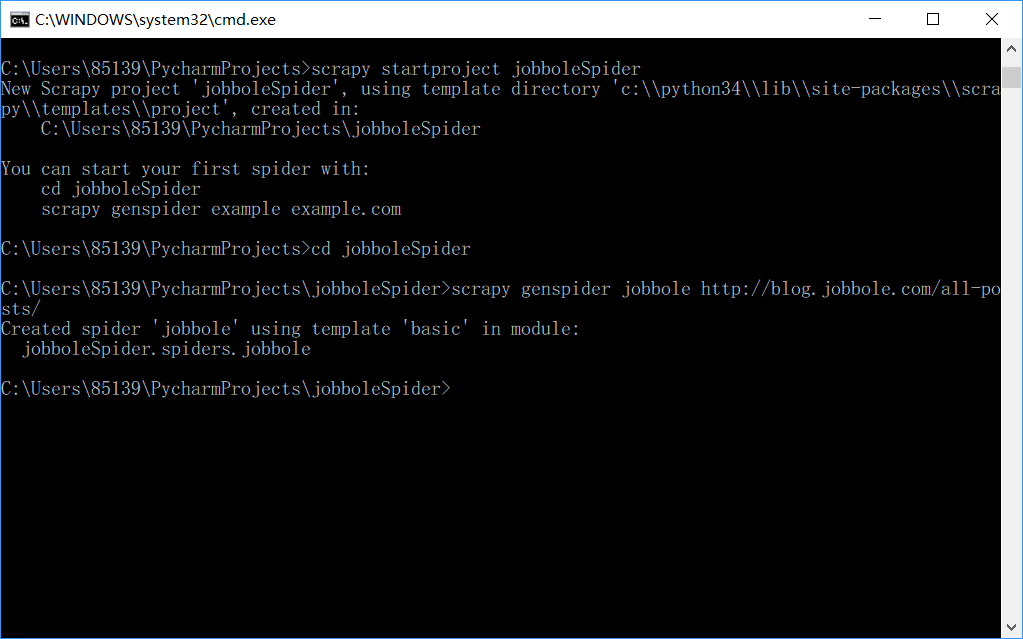
由于我们现在对scrapy框架还不熟悉,所以我们使用scrapy自带的命令来生成scrapy的模板。此次我们以爬取jobbole为例。
如上图,首先,我们使用如下命令
scrapy startproject jobboleSpider
这样我们就能在当前路径下创建了一个scrapy爬虫项目,但这个项目此时还不完整,所以我们根据它的提示使用以下命令创建一个scrapy自带的模板
cd jobboleSpider
scrapy genspider jobbole http://blog.jobbole.com/all-posts/
根据提示信息,我们知道了我们使用了scrapy的"basic"模板成功创建了一个scrapy项目并构建了基本的结构。那么接下来我们打开IDE来了解一下我们创建的模板。
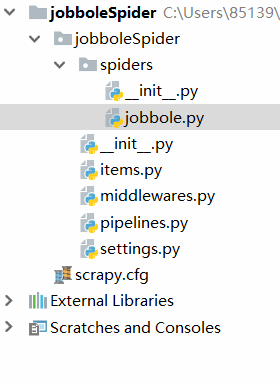
其中scrapy.cfg使我们的全局配置文件,包含我们的设置文件路径,项目名称等。
jobbole.py是我们以后实现爬虫逻辑的主要文件。
items.py是我们的定义数据储存结构的文件。
middlewares.py包含了大量中间件,例如下载中间件,重定向中间件,是scrapy引擎与其他部分代码之间发送信息的重要通道。
pipelines.py正如其名,是一个管道,主要用于将我们获得的数据储存到数据库中。
setteings.py则由大量关于scrapy的设置,例如是否遵循robot协议等。
结语
至此我们已经实现了scrapy的安装和基本框架的实现,但还没有进行具体的编程,接下来笔者将会带着大家首先实现对jobbole“最新文章”的所有文章的爬取,以初步体验到scrapy爬虫的乐趣。然后逐步深入到模拟登陆,突破反爬虫限制等。
我会尽量详细的说明我的每一步操作,以实现一个“小白教程”。后面的教程中我们会使用到xpath和正则表达式,限于篇幅,笔者对这两个知识点只会进行一些基本的教学,如果大家想要熟练运用的话,最好能够查阅其他一些资料进行更深入的学习。
python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍的更多相关文章
- python爬虫---js加密和混淆,scrapy框架的使用.
python爬虫---js加密和混淆,scrapy框架的使用. 一丶js加密和js混淆 js加密 对js源码进行加密,从而保护js代码不被黑客窃取.(一般加密和解密的方法都在前端) http:// ...
- 小白学 Python 爬虫(28):自动化测试框架 Selenium 从入门到放弃(下)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- python爬虫入门(七)Scrapy框架之Spider类
Spider类 Spider类定义了如何爬取某个(或某些)网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item). 换句话说,Spider就是您定义爬取的动作 ...
- python爬虫入门(八)Scrapy框架之CrawlSpider类
CrawlSpider类 通过下面的命令可以快速创建 CrawlSpider模板 的代码: scrapy genspider -t crawl tencent tencent.com CrawSpid ...
- python爬虫入门(九)Scrapy框架之数据库保存
豆瓣电影TOP 250爬取-->>>数据保存到MongoDB 豆瓣电影TOP 250网址 要求: 1.爬取豆瓣top 250电影名字.演员列表.评分和简介 2.设置随机UserAge ...
- Python爬虫【实战篇】scrapy 框架爬取某招聘网存入mongodb
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.p ...
- python爬虫入门(3)----- scrapy
scrapy 简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网络 ...
- Python 爬虫(四):Selenium 框架
Selenium 是一个用于测试 Web 应用程序的框架,该框架测试直接在浏览器中运行,就像真实用户操作一样.它支持多种平台:Windows.Linux.Mac,支持多种语言:Python.Perl. ...
- 小白学 Python 爬虫(27):自动化测试框架 Selenium 从入门到放弃(上)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- SQL Server -- 回忆笔记(二):增删改查,修改表结构,约束,关键字使用,函数,多表联合查询
SQL Server知识点回忆篇(二):增删改查,修改表结构,约束,关键字使用,函数,多表联合查询 1. insert 如果sql server设置的排序规则不是简体中文,必须在简体中文字符串前加N, ...
- 使用GDB调试gp(转载)
使用 gdb 调试 postgres greenplum zalax3030人评论715人阅读2012-07-11 10:07:15 错误信息的获取途径有几种 : 1. 最简单的就是看Postg ...
- Django 2.1.3 文档
https://blog.csdn.net/lengfengyuyu/article/details/83342553#3_23
- Linux进程调度器概述--Linux进程的管理与调度(十五)
调度器面对的情形就是这样, 其任务是在程序之间共享CPU时间, 创造并行执行的错觉, 该任务分为两个不同的部分, 其中一个涉及调度策略, 另外一个涉及上下文切换. 1 背景知识 1.1 什么是调度器 ...
- AI学习---数据读取&神经网络
AI学习---数据读取&神经网络 fa
- 小程序request封装
我们知道,一个项目开发时,有许多环境,如:开发环境,测试环境,预生产环境,生成环境,若项目上线时要每个接口的域名改一遍,这是效率很低的做法.另外,许多接口都有前缀,例如 /api/ /wxapi/ ...
- 【FJWC 2019】 森林
[FJWC 2019] 森林 样例输入 0 5 1 0 0 2 样例输出 1 2 3 3 我们发现,答案就是直径加上直径上某个点出发,不经过其他直径上的点的最长链.这里的直径可以是任意一条直径. 首先 ...
- Linux之文件属性
文件属性是什么? [root@luffy_boy-001 /]# ls -lhi /etc/hosts 129822 -rw-r--r--. 2 root root 198 Jan 11 2019 / ...
- 5.02-requests_proxy
import requests # 1.请求url url = 'http://www.baidu.com' headers = { 'User-Agent': 'Mozilla/5.0 (Macin ...
- [matlab] 19.matlab 基础几何学
polyshape 函数可创建由二维顶点定义的多边形,并返回具有描述其顶点.实心区域和孔的各种属性的 polyshape 对象.例如,pgon = polyshape([0 0 1 1],[1 0 ...